
王竹峰,去哪儿网数据库总监,擅长数据库开发、数据库管理及维护,一直致力于MySQL数据库源码的研究与探索,对数据库原理及实现有深刻的理解。曾就职于达梦数据库,从事多年数据库内核开发工作,后转战人人网,任职高级数据库工程师,目前在去哪儿网负责MySQL源码研究与运维、数据库管理和自动化运维平台设计开发及实践工作,是Inception开源项目及《MySQL运维内参》的作者,MySQL方向的 Oracle ACE。
一、数据库开发
2011年从华中科技大学数据库与多媒体研究所毕业之后,免试被达梦数据库录取。其实真正进入达梦数据库的时间是 2009 年,当时是以实习的身份进入的。那时达梦数据库的主流产品还是 DM6 ,我在里面的工作内容是看 DM6 的源代码,当时第一次接触到了语法分析、yacc.yy、REDO、UNDO 以及执行器等概念,并在代码中验证了这些概念,从此走上了数据库开发的道路,打开了一个新的认知世界。
到 2010 年年中,我从武汉去了上海,因为达梦在上海有一个新的宏伟目标,即从头写一个数据库-DM7,我有幸见证了这个过程。“从头写”,所言非虚,我加入到开发工作中的时候,已经具备了一个简单的建表功能了,B 树相关的分裂及合并等还正在进行中,此后所有的工作,就像是在建一座大楼,一块块的砖砌在上面,到 2012 年,数据库已经可以用了,常用的功能都已经很完善了。我在其中,做了不少工作,包括 Job 模块、兼容 Oracle 的包的实现、pl/SQL 的部分实现、调试 pl/SQL 的调试器 dmgdb 的实现、dm 列存储的存储引擎的实现以及 Oracle 同义词 synonym 的实现等功能。
在开发 DM7 的过程中,我成长得非常快,作为一名数据库从业者,能参与开发一个大型数据库,非常幸运,通过实现 pl/SQL 的功能,对达梦的执行器理解非常深入,对执行栈及指令生成跳转理解深刻,这为后来开发 dmgdb 以及进一步理解 gcc 的 gdb 非常有意义,并且我还记得,dmgdb 的功能、命令、使用方式,和 gcc 的 gdb 非常相像,这里面学到的最核心的理念是“旁路干预”,即用另一个活动连接或者线程去控制主线程,从而实现了可以在任何一个指令暂停、继续、断点设置等功能。这个理念其实和现在我们 MySQL 从业者都很熟悉的 MySQL 插件很类似,比如半同步、审计、MGR 等功能。
同时还实现过两个版本的列存储存储引擎,我在2011年就写过一篇文章,关于 DM7 的行列融合的功能(百度可以搜到,搜索词:行列融合),现在想来,当时已经是非常超前了,这也为后来从事 MySQL 运维及开发,打下了坚实的基础。
在达梦的三年时间,让我认识到了数据库的未来之好,数据库的技术门槛之高,作为写过达梦数据库代码的我,到现在都觉得,达梦数据库的技术,绝对可以称得上是先进,优秀,现在在分布式领域里面出现的一些设计方案,在2011 左右的达梦身上,已经实现过了,比如 MPP 的数据分片路由,任何一个节点都是路由节点,而且在某一个节点发现分片数据不在本地的话,可以将本地生成的执行计划打包,直接发送到对应节点来执行这个计划,而不是重新生成计划,这有赖于它强大的指令集,生成的指令有点类似C语言编译之后的执行码,或者汇编指令。
就现在看,这些也是非常先进的,这样设计出来的数据库,兼容及扩展无疑都是非常容易的事情,所以这也是为什么现在去 Oracle 方案中,达梦可以做到让业务不需要改代码就可以直接迁移到达梦上的缘故。
二、初入运维
做了三年的数据库开发后,我开始感觉工作有点枯燥,看不到正向回馈,工作的内容都是一个个的功能实现,实现完一个又一个,需求就是功能,实现就是代码,与外界接触太少,没有机会了解真正的需求是什么,实现之后,也没有机会了解对方使用得如何,所以决定离开。
当时已经在工作之余看了一部分 MySQL 代码,对比之下,MySQL 的代码,当时感觉不太像一个数据库,没有什么设计,数据插入用一个mysql_insert 的函数就搞定了?不应该分阶段吗?比如语法分析、语义分析、执行计划优化、生成、执行这样的步骤。熟悉之后,也慢慢接受了,但这种设计,肯定是不优美的,对于兼容性、扩展性,是没办法很好的保证的,现在想来,确实会经常出现一些牵一发而动全身的问题。
2013 年,我进入了现在所在的去哪儿网。做了运维才发现,工作内容与开发数据库的工作,简直天壤之别。首先面对的对象不一样,运维面对的是线上一个个活生生的 MySQL 实例,你做任何事情,首先得保证它们的可服务性,才能谈别的;其次,面对的人也不一样,运维面对的是真正的需求者,比如业务开发,他的需求是使用数据库以及更丝滑的使用数据库,更具体一些,就是如何能保证他这个数据库的可服务率。相比之前开发数据库的工作,需求更明确了。实现方式,那就看个人能力了,能力好,反馈就有保证,能力不好的话,经常出问题,那就自然会给你很多负面的反馈了。
三、如何提升效率
2013 年进入 MySQL 运维行业之后,我开始关注的内容不一样了,工作时所面对的对象也不一样了。DBA 通常都是一对多的服务,必须要保证公司的数据库有足够的可用性才行,这考验的是 DBA 的多方面能力,包括抗压能力、问题应急处理能力、解决问题的能力、学习能力、沟通能力等等,总结下来更多的是一个综合能力,在这种状态下,工作效率是必须要提升的,不然 DBA 就会无休止地在低效的工作内容中,不断地循环往复,这种状态,我一般称之为——旧式的 DBA 生产力。
旧式的 DBA 生产力,每个 DBA 的工作时间,都被这种低效的工作所占据,没有更多的时间做提效的事情,所以造成的结果是,频繁加班、熬夜、士气越来越低、头发越来越少,而数据库的可服务率很低。在这种情况下,必须要有人去打破这个恶性循环,去做一些提效的事情,进而实现不断的螺旋式的上升,而不是原地打转。这里讲如何提效,我想可以从以下几个方面入手:
我们技术工作者,很容易出现的一个现象是,对自己所涉及的技术或者产品,或者业务等都可以提出来很多需求,或者整天在吐糟各种问题,比如一些不方便的点,低效的现象等等之类的,但很少有人能自己动手去解决这些自己发现并提出来的需求。
而反过来,这些技术及产品的开发者,他们的开发能力很强,却不是这些产品的用户,做出来的东西经常很反人类,或者干脆自我感觉良好,觉得自己已经把产品做到无可挑剔的地步了,不接受反驳,不接受新需求,或者即使有新需求,但需要需求方和开发者反复沟通,其中也可能会出现一些偏差,或者由于排期迟缓,或者周期太长等种种原因,最终没有下文。
其实在我看来,在某些时候,如果考虑二者能相互融合一下的话,比如自己的需求自己解决,这样结果会好很多,此时可能进入一种全新的状态,即产品里面,开发能力最高的,而开发里面,产品能力是最好的,如此有下面几个好处:
设计的产品可能是真正能解决用户需求的,也是用户真正想要的样子。
提需求的人,不需要等待开发去排期,自己就直接做了,不需要看别人脸色,不受制于人。
效率是最高的,不需要来回沟通需求,等排期。
个人成长明显,相对可以做到不被淘汰。
在 DBA 行业里面,这点更加明显,纯运维将来能走的路非常有限,需要有代码能力的支撑。
DBA 需要对自己所管理的资源,做到系统中有数据,而不是心中有数。因为随着系统越来越多,靠人的记忆去运维是非常不靠谱的,我们必须要有对应的系统去支撑,才能做到持续地,稳定地提供服务,有如下几方面原因:
人的记忆不具有传递性,如果人离职了,那相应的记忆也离职了。
人的记忆不能保证准确性,容易出现问题。
靠人的记忆去做的话,在合作场景下,顿时失灵,存在数据不一致的问题。
数据化管理效率高,准确。
数据化管理,可以实现数据共享,合作无缝衔接。
有了基础数据之后,就可以在其基础上实现自动化了,只要有点自动化,就比人肉强,这有如下几个原因:
效率方面,自动化相比人肉,效率提升是可见的。
准确性方面,人为操作是最容易出问题的环节,自动化可以保证准确性,不需要因为频繁的操作失误而被动工作。
人非常不擅长重复性工作的,相反,机器很适合做这类型的工作。
自动化可以实现操作的规范化,标准化,智能化。
自动化可以解放 DBA,让 DBA 腾出双手,提更多的需求,DBA 再把这些需求实现掉,进一步提升效率,进入良性循环。
让 DBA 做更有价值的事情,DBA的耻辱是,一天审核了 1000 个上线 SQL 语句。
说起资源,每个人都不陌生,对于 DBA 而言,资源通常可能包括机器、同事、朋友、经验、认知、大脑、书籍、网络、系统、平台等等之类的。这里所举的例子,都是客观独立存在的,会不会与你发生关系,这取决于你是不是要利用他,只有利用了,这些资源才会与你形成一个关系网,从而让你的工作更加高效,并且在你利用之后,你自己本人,也会在这个过程中,形成赋能效应,让你的能力变得更强。但如果你没有利用他,或者不知道如何利用,更甚者,根本就没有意识到他的存在,这样的话,他们的客观存在,并不会对你产生任何影响,而你的能力,极大可能会保持原地不动,因为我们所有现在所处的境地,都是由我们的认识决定的,或者说我们大部分吃过的亏,产生的损失,都是由认识决定的。
在意识到上面所讲的资源的存在之后,要不断地去利用他们,这样做事情的效率,自己的能力才会不断的提升。
另外,还有一种资源,我们也要学会利用,通常情况下,当你学会使用这种资源之后,你会发现,解决难度相 比之前,不可同日而语,这种资源就是——你的领导。
当你发现有些事情推进非常缓慢,或者解决起来各种阻力,所有你身边常用的资源都用了,就是很难解决,不断 delay,可能已经陷入僵局。这种情况下,你不妨把目光放在你的领导身上,也许在他的层次及角度上,解决起来,不费吹灰之力,另外,此时你可以关注一下他的解决方式,你会发现,他的解决方法正是你现在所看到的——学会利用自己的资源。
四、DBA应该尽可能聚焦
聚焦,对于我们技术工作者来讲都是需要的,这是一种工作和学习的方式,也是一种快速提升自己的方式,有以下几个方面,来保证我们可以做到聚焦:
技术工作者,经常会犯的错误是,一个项目在规划阶段,规划的非常完美,动不动就来一个五年计划,实现方案考虑的非常周全,各种边界情况都考虑到了,为了解决这些边界情况,会把问题放大,导致解决方案放大无数倍,这样的做事方式是不可取的,所以在设计项目或者方案的时候,需要考虑以下一些问题:
大项目要拆分成多个子项目,或者分期完成,要把不同模块划分出来,一个个实现,并且这些模块可以阶段性地使用起来,而不是等到最后一刻和其它模块组合起来,才能被使用。
要想清楚做这个项目的初衷是什么,不要把项目方案放大,最终搞成一个宏伟的目标,这样可能永远也实现不了了。
根据项目初衷,设计一个能解决这个初衷的方案即可,不要因为解决一个小问题,而“创造”一个更大的问题出来。
开发者,也要定期向上反馈成果,不要让领导觉得项目是遥遥无期的。
就像上面所说的,掌握技术,或者精通技术,作为一个技术工作者是非常有必要的,但技术人员很容易陷入一种陶醉的状态,进入这种状态之后,就会处于一种只见技术不见初衷的局面了。
技术工作者,需要时不时地跳出来,从上帝视角去观察自己,现在做的事情是不是有意义的,是不是合理。如果不跳出来去审视自己的话,可能出现的局面就是——我们走的太远,已经不知道为什么而出发。这样的后果,通常可能出现的局面就是南辕北辙,做的东西并不是对方想要的,或者做完了,发现做的东西并没有解决问题,从而导致自己长期没有成就感,没有被领导及同事认同等等之类的问题。
技术工作者,还要避免的问题是,非常执着地追求“新技术”,新技术固然有吸引力,但我们还是要理性地去看待这个问题,关于新技术,有以下几方面的想法:
新技术,是相对旧技术而言的,通常会出现与旧技术不一样的表现形式,最常见的就是兼容性,带来的问题是,我们需要维护非常多的版本,老的下不掉,“新技术”的版本不断上线,久而久之,维护成本非常高,DBA及平台,需要处理各种新特性的兼容问题,处理不及时,就会导致出现故障之类的问题,吃力不讨好,所以面对新技术,我们扪心自问一下,旧技术是不是够用了?够用就好,这点在 MySQL 上面,我觉得够用的,但PG由于种种原因,会出现各种新技术,如果不谨慎的话,就容易出现上面的问题。
现在流行新技术 docker/k8s,有人经常问到我,你们 MySQL 用 docker 了吗?我通常是用两个成语回复,分别是隔靴搔痒,作茧自缚。你想上k8s,是为了解决什么问题?编排部署安装找资源的问题?MySQL 是一个有状态的大型通用数据库,这么重存储的服务,找资源安装,问题很大吗?又说是资源隔离的问题,资源隔离的需求很紧迫吗?单机单实例就不说了,即使在单机多实例的情况下,也没几个实例,并且 MySQL 本身内部就是多线程的,均衡问题也比较好,同一台机器上一个实例影响其它实例的案例少之又少,所以这需求有那么紧迫吗?而且对于使用 MySQL 没有上到一定量级的情况下,非 k8s 的自动化平台就可以很好的解决资源部署安装编排的问题,为了解决这个问题,创造一个上 k8s 的大问题,这样就有点和初衷背道而驰了。同时 k8s 是一个新的技术栈,支撑它上线,是需要另一个专业团队来做的,投入产出比非常低。我反过来再问一下, MySQL 本身的问题你解决完了吗?慢查询有没有好的工具去优化?主从切换能不能不影响业务?机器挂了能不能不丢数据?数据库服务能不能做到不同机房的多活?自动化 SQL 审核可以自助服务了吗?如果哪个没做到,那就先放弃 k8s 吧。再者,我们专业的 MySQL 运维技术人员,非要作茧自缚,给 MySQL 套一个壳,出了问题,是壳的问题?还是 MySQL 本身的问题?当引入一个变量的时候,可服务率肯定就会有一定程度的下降,因为 99.99%*99.99% 的结果是 99.98%。
DBA 这个职业,是非常适合聚焦 的一个职业,为什么?因为几十年以来,变化非常小,作为从业者,有足够的时间去学习,去钻研,并且有足够的机会,让你变成这个行业的专家。何谓专家,就是对某一个方向,有足够的经验,有足够的思考,有足够的总结,这三个因素中,总结是最容易的,也是最重要的,因为只有总结了,才可以把思考,经验变为自己的财富:
在相对稳定的变化不大的行业中,总结出来的知识,有利于循环利用,有利于进一步提升。
总结,不是做到心里默念一下,感觉会了就表示总结完了。
总结一定要从心里默念,转换到笔记里面去,或者转化到可发表的文章中去,任何有疑问的地方,要有自己的思考并能解释清楚。
总结,在转化为文字之后,要求再高一些的话,就是可以把相应的内容转换为ppt,在公司或者社会上讲出来,好处不言而喻。
如果做到了这些,恭喜你,你已经正在向通往专家的道路上前进了。
五、DBA应该做什么事情
我们有幸从事了 DBA 这份职业,上面已经说了,相对变化不大,有足够的时间让你成为专家,那在成为专家的道路上,你应该做哪些事情呢?
这里我想引用一下贝壳找房一直说的一句话:做难而正确的事情。
我认为,难的事情,可能是业界难题,也可能是一个具体案例,举例来讲,差不多 8 年前,SQL 语句审核肯定是难的事情,属于业界难题,当时开发了 Inception,就很好的解决了这个问题,直到现在,应该还是 MySQL 运维中的必备工具。业界难题还包括慢查询的评估,如何定义一个慢查询的影响?之前没有人做过,去哪儿网在 2021年做了这个事情。我想还有很多,需要我们不断地去发现,去解决。
提升效率的事情肯定是正确的,节约成本的事情也肯定是正确的。
我认为,不管是业余开发者,还是专业开发者,都需要尽量去保持一个产品化思维,如果拥有了,那么在一定程度上可以做到“我好,你好,大家好”。产品化思维一般包括几个点,比如不要让用户产品困惑,能适应更多场景,适度考虑边界情况,耦合度要低等等,可以具体问题具体讨论。
DBA是服务人员,一般都是别人提很多需求,DBA来服务,其实不只是DBA,不管任何行业,需求可以随便提,可以天马行空,可以摊大饼,但实现需求的人,一定要认真评估这些需求是不是合理,是不是正确,是不是应该去实现,这些如果不提前做好认真评估的话,会产生很大的问题,可能的问题包括:
长期以往,自己所实现的服务或者产品,会变为一个垃圾场,八面玲珑,样样不行,最终都会走上“重构”的道路。
是不是可以换一种思路去解决?这考验的是需求实现者的判断力。
接受在普适场景下的定制化,而不能为了解决1%的需求,创造一种新的架构或者服务,还是之前说过的原则,不要因为解决一个小问题,进而创造出来一个更大的问题。
不是所有的需求都需要满足。
如果不是一个经验用十年的话,那就恭喜你了。
六、打破规则
规则存在的意义,就是要去打破的,旧的规则被打破了,新的规则才能建立起来,正所谓不破不立。
我们是技术从业者,在工作中也会遇到各种各样的规则,有些规则存在的意义,说不清,道不明,对于这种规则,我们就需要对其打个大大的问号,因为建立规则时,一定是有他当时的时代背景、条件环境的,时过境迁之后,这些条件可能已经不成立了,此时如果不打破规则,那可能出现的局面就是固步自封、因循守旧、墨守成规、循规蹈矩等等之类了,所以规则,有时候必须要打破,只有打破了,才有可能创新,有可能创造。
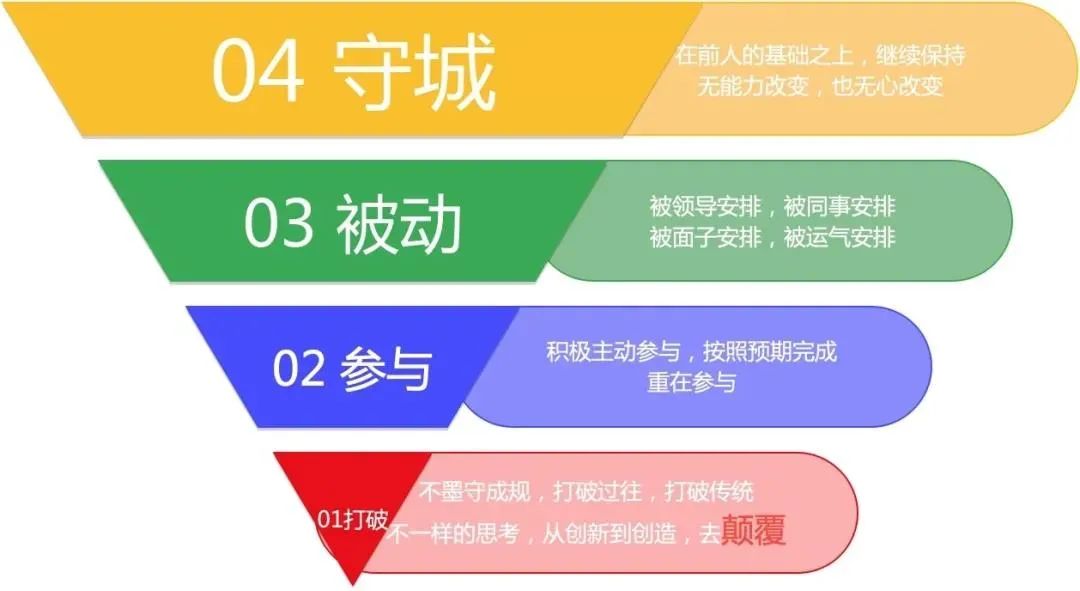
如上图漏斗所示,我们技术从业者,可以分为四个大类:
守城型,这种类型的人是最多的,他们可以站在巨人的肩膀上,过得比较安稳,可以继续保持前人留下来的工作,但让他们去改变的话,非常难,难在两方面,一方面是能力不足,另一方面就是心力不足了。
被动型,这种类型的人,相对守城者,会稍微少一些,他们的能力是可以的,不过主题词是一个“被”字,工作被动,生活被动,在我们运维行业中,一个集中表现就是,整天“被”各种故障、问题所累,状态也不好。
参与型,这种类型的人会更少,他们的态度非常积极,很乐观,做事情可以按照预期,甚至超出预期完成,但他们的成就感可能更多地来源于重在参与,很少可以主动去改变现状,去思考面临的问题等等。
打破型:这种类型的人,非常之少,通常不会按照既定陈规出牌,对过去的传统都会产生疑问,和其它三种有不一样的思考方式,他们的出现,通常会石破天惊,会颠覆某一个规则,甚至某一个行业,拥有这样特质的人,可以参考乔布斯、马斯克这样的人。
上面说了四种人,形成了明显的对比,我想说的是,我们从事 MySQL DBA 的人,不用也不可能和乔布斯、马斯克这种斯字辈儿的人看齐,古人都说了,穷则独善其身,达则兼剂天下,我们可以在自己领域里面,向他们学习,就已经足够了,对现在你所遵守的规则,打几个问号,可能也就足够了,有时候,我们打破了一个规则,或者一堵墙,可能看到的是炫彩斑斓的新世界。
七、工作模式的转变
DBA 这个职业,一般被认为是属于服务行业,但DBA 的存在感,一般只有在两种情况下比较突出:
数据库出故障了。
有人对你有需求。
其它情况下,可能并不能感觉到 DBA 的存在,这样对 DBA 的固有印象,已经持续多年,很难改变,因为这涉及到的是一种工作模式的问题,我在这里可以列一下,是一种什么样子的工作模式:
各种权限、数据库、SQL 审核等的审批工作以及执行工作。
各种合作伙伴的咨询问题,需要承担客服的角色。
各种问题的追踪、调试、找原因,需要面对各种相关人员的询问以及好奇心,查不清楚或者没有结果,是不可以的。
到处救火,工作时间被安排,没有办法保证。
这样的状态持续久了,团队情绪低落,士气不高。
各种重复的,繁复的日常工作需要处理,效率很低。
等等之类的。
这是一种什么模式呢?很明显,这样的工作状态,非常被动,就像上面说过的,一切都是被安排的状态,这里的主题词,其实就是一个“被”字,过去的十年,已经过去了,以这种状态的工作方式工作了十年,有了足够的教训以及经验,如果能意识到这些问题,这种状态,那我想现在是应该做出改变的时候了,我们应该尽可能的把被动的工作状态,改变为“主动”,包括如下好处:
团队人员的时间,可以自由支配,而不会被突如其来的事件所干扰。
是不是可以想办法在故障发生之前,能将故障解决掉,或者破坏掉,故障没了,大家相安无事。
故障变少之后,上面所说的“数据库出故障了”的存在感就会消失,整体上得到的评价不会因为故障而不断降低。
相比所有被动处理的局面,变为主动之后,工作量可能会更少,可以做到有条不紊。
能把被动,变为主动,团队的能力提升肯定是非常大的,这样人员情绪高涨,一举多得。
这样的主动,是一种什么样的概念呢?其实很简单,可能包括如下几个方面:
做了一件事情,能有效地提前避免将来的问题,即是主动。
有效地发现潜在的问题,能主动找到当事人并通知到,即是主动。
能有效地发现数据库的风险,能尽快地解决问题,从而避免问题的发生,即是主动。
能综合过去各种迹象,从整体来评估一个数据库的健康状况,如果风险相对比较高,做出相应措施,即是主动。
能通过事件触发,在关键时刻可以留存一些重要信息,在解决问题的时候能用得上,即是主动。
足够完善的监控系统,日志分析及抓取系统,保存足够的重要数据,即是主动。
能精确地找到资源浪费,使用不合理,空闲等问题,并且能够处理掉,即是主动。
主动做的事情,可以有很多,列举出来的可能只是常见的一些情况,和自动化是一样的,只要做了,就会有成果,但这种成果不一定能立即体现出来,比如解决了一个高风险的问题,后来确实没出故障,但不解决这个,就一定出故障吗?似乎也不一定,但这是一个思路,这也是我们做为 DBA 的职责,有风险就得解决,那如何检验我们的努力和故障少是正相关的呢?这个很好办,可以长时间观察,做一个环比,通过故障率来衡量,比如去年一年出现的故障,与今年一年相比,是降低了还是上升了,这样去衡量的话,就可以说明问题了。
至于可能有些人会问,是不是因为今年运气好没出现问题,而并不是你的这些努力所得到的成果呢?这个是证明不了的,也无需证明,一是因为你属于钻牛角尖,另一方面,你想想,你的目标是什么?是不是要降低故障率,现在达到了,不就可以了吗?或者检验时间还是不够长,如果环比两年,三年来看呢?我想你的运气不可能那么好,以至于你不做这些工作的话,还可以做到故障一年比一年的少。
此时再想想,如果我们能把工作模式成功转变了,那存在感就可以非常强了,这种存在感,再也不是只有故障的时候才想到你,也不是只有需求的时候才想到你,而是你总会以主动的形式出现在他们的面前,比如在你评估之后,一个数据库需要拆分了,或者需要迁移了,或者有很多慢查询需要解决了,或者某个表占了很大空间但没有使用了,等等之类的情况,你都会以预言家的姿态出现在他们面前,而这背后,靠的都是你的辛苦付出,靠得都是技术支撑。
八、我们具体应该做哪些事?
讲了这么多,可能都是方法论,可能有些人就想知道,对于我们传统 DBA 来讲,应该做哪些事儿呢?其实我的思路还是一样,要想着转换工作思路,工作模式,将“老旧”的“被动”的 DBA 工作模式抛弃掉,换一种思路,去做一名新时代的 DBA ,我本人从2012年开始做 DBA,到现在 2021 年年底,正好十年,所以过去的十年,可以将其抛之脑后,从2022年开始,迎接新的工作模式,我们可以给自己起一个名字,叫:New DBA。
那我们到底应该做些什么事情呢?我可以举一些例子:
报警系统,做为数据库运维来讲,是必不可少的,有问题全靠报警来主动发现,但有一些问题我们是需要解决的:
阈值低报警太多的话,就会将非常重要的信息,淹没在报警的海洋之中,导致报警失效,因为我们根本不能及时发现;
阈值高报警太少的话,就有可能在报出来的时候,已经晚了,还是不能及时发现;
如果不同对象设置不同阈值的话,维护起来又非常不方便,因为报警阈值这种底层配置一般都是本地配置文件,维护困难;
本地个性化配置阈值的话,迁移之后这些配置也得跟随,也是有问题的;
不管报警多,还是少,总是有些不管三七二十一都需要必须马上处理的报警,对于这种及时发现还是个问题。
报警屏蔽,报出来,都会有延迟,经常出现错乱,不知道是延迟导致的还是新出来的报警。
等等如此之类的问题,我们在给 MySQL 上容器之前,这些必须是要先解决掉的。如何解决呢?我们之前发过文章讲过这个事情,这里可以大概说一下我们现在已经做到的以及将来的一些改进:
我们现在重要的报警可以在一分钟之内直接打电话给相关人员,电话肯定可以接到。
我们所有报警对象的本地配置,阈值设置的都很低,在智能报警模块去做判断及过滤是不是要报出来。
我们针对没有报警出来的,会做综合分析,然后统计出来,通过对象维度定期去集中解决某类型的报警。
我们现在对报警的管理没有任何延迟,因为做在了智能报警模块中。
我们将来做的一个重要事情是,把报警想象成一个事件,这个事件在报出来的时候,会动态触发新的事件,可能去收集当时数据库或者机器的状态,用来在真正出问题的时候,查问题之用,智能自动化诊断之用。
(相关技术细节请参考往期文章:小成本改造范例:去哪儿网数据库告警系统演进实践)
之前我们也发过文章讲这个事情,我们是通过抓包实现了这样的全日志功能,抓包率可以达到 95% 以上,但我们的目标是要不断达到 100%,为什么呢?因为我们要达到一个目标,就是要可以肯定地说,我们的全日志系统的日志是可信的,而不是模棱两可地说,有可能丢包了没抓到云云之类的。
这里讲一下全日志的好处:
可以精准掌握资源利用的信息,包括某一个对象是不是还在被使用,哪个是僵尸账号等等,用来回收浪费资源。
某个 SQL 语句什么时候访问了数据库,每一时刻的访问频率是什么,可以用来定位问题及查故障原因。
可以与慢查询日志做联动,能得到慢查询日志中不存在的信息。
用来做安全审计。
用来打通数据库与应用程序之间的技术栈。
用来精确地找到某一个表或者库的使用者,更好的推动业务及数据库的配合事务。
可以做“主动”的工作,做精准通知。
可以发现异常使用及风险相关的问题。
可以肯定地说,New DBA 可以在这个事情的基础之上,做很多有意义的事情,有价值的工作,所以这项工作是必不可少的。
这是我们今年做的一个事情,也是体现我们“主动”运维的重要一环,慢查询是不可避免的,并且是不断变化的,老的被干掉了,新的又不断涌现出来。它是故障原因的常客,因为慢查询的影响足够大,当多个因素包括执行时间、扫描行数、频次都上来之后,它们的执行非常容易相互影响以至于将整个集群或者实例打爆,所以我们必须要有一个评估方案能准确找到真正“慢”的查询,这里的慢表示的是影响程度。
为了应用及数据库健康,降低故障风险,相关人员的慢查询解决意愿其实是有的,只不过由于这些慢查询都在系统里面,他们并不知道哪些是应该优先解决,哪些是需要重点解决的,最终的结果可能就是不解决,等出了问题再解决,这样的话,工作模式又进入到了“被动”模式中,此时我们能做的事情就是,使用这个模型,将风险用量化的数据表示出来,辅助相关人员去找到什么样的慢查询应该优先解决,让解决慢查询的工作变得高效、有的放矢,把有限的时间花在真正需要的工作上面,而不是想当然地盲目地去解决。
如何有效地推进呢?这个问题可以定几个规则,比如定期发邮件给相关应用,给他列出来需要解决的 Top-N 的慢查询,我们需要具体跟踪每一个慢查询的解决进度吗?我想是不需要的,如果是这样的话,那工作量就会增加好多倍,相应的DBA人员也要增加不少,这不是我们想要的,那如何检验慢查询优化的状态?可以从整体上看所有慢查询的P95,P50,P99 等等之类的统计值,如果是在降低,那说明是有辅助效果的(也可能有人对此有疑问,此时想想你的目标是什么?目标不就是要降低P95之类的值吗?目标达成了,那至于是不是因为风险指数的作用,这个和上面说到的故障问题是一样的,是你运气好?还是检验时间不够长?),推动方式可以和相关 TL 沟通好,要根据邮件信息主动推进,并且还可以将数据化的推进情况发给相关 TL 来综合检验,比如发邮件次数最多的 TOP10 的慢查询,也就是一直发但没有解决的。
至于肯定还会存在的一些情况,比如邮件是通知了,但对方就是不主动解决,这样的情况肯定也是不少的,或者说很普遍,那不解决怎么办?对于这种情况,我们可以回头想一下,这个风险指数的意义是什么?不就是辅助相关人员去判断哪些应该优先解决吗?所以如果他不主动去解决,除了被统计发给其 TL 推动之外,我们可以忽略不计,就像你在路上立一个路牌,告诉他“此路不通”,但他就是不信,不听,还是过去了,你需要把他怎么样吗?不需要的。
在做 MySQL 的容器化之前,先考虑一下,你管理的数据库是不是已经做到了高水准的 HA?可以达到几个9?正常 switch-over 是不是会影响业务?影响时间是多少?重要业务做这个操作的话,是不是需要晚上?还是随时都可以?DBA因为HA的问题是不是心理还会承受很大的压力,需要不停地夜战?
failover 的情况下,是不是还存在丢数据的问题,切换的时候需要多少时间?是不是还在使用 VIP?是不是还在使用单点监控?最近有没有发生误切?
如果没有做好的话,就先把份内之事搞定再说,有闲功夫后再去做 MySQL 的容器化吧。
至于 Redis 集群来讲,HA 方便又是如何,上面的事情是不是可以保证,一个更有挑战的事情是,你的扩容和缩容,是不是做到了对业务无影响?是不是随时可以在无感知的情况下干这些事情?是不是在业务不知道的情况下,发现他们存在资源浪费的问题,即可直接给他们缩容了呢?而在内存报警的时候,是不是可以直接自动给他们扩容节点数呢?
如果没有做到,先想想办法看,然后再做容器化的事情吧,HA 的问题,肯定比容器化能带来的资源隔离,以及任务编排更重要。
你是不是还记得,由于你的一个命令,导致出了一次故障,或者由于某一次疏忽,导致配置错误?
其实通过这一次次的经验教训,可以总结出来的是,很多故障都是人为操作导致的,人的操作是最不可靠的,原因很明显,人工操作有很多不可靠的因素,包括情绪、状态、熟练程度、能力、认知、时间、是不是认真负责等等,这些因素结合起来,如果能够成功实现某一个变更,或者操作一个任务,那简直是运气爆棚,不成功才是正常的。
我们也吃了不少这方面的亏,记得 2019 年一年,人为操作出现的故障就大概有十起左右,历历在目。
这如何防治呢?在防治之前,我们选择先搞明白原因,其实就是操作的随意性,不规范,不标准,想当然,试试看。我们一直强调,在你不能确定这个命令的影响是啥的话,那就别执行,但强调是没用的,能力,状态,熟练程度就摆在那里,强调实在是苍白无力。
在确定的事情面前,人为操作的成功率就是比不上机器去执行的成功率,因为机器执行的话,可以在既定的步骤上面,按部就班地执行,没有其它影响因子,执行过程很规范,很标准,很统一,执行一遍和执行一千遍的结果是一样的,在这样的前提下,那就要尽可能地避免人为操作。
吸取 2019 年的教训之后,在 2020 年,我们实现了可以自定义编排任务的自动化迁移系统,把很多操作任务拆分成原子动作,然后按照提前编排的操作流程,实现最终的迁移目标,最终我们能在两个月内成功地将 100 套 3M 架构的数据库迁移为 PXC 架构,最难的是,我们实现了零故障迁移,这在过去是不可想象的,因为从 3M 到 PXC 的迁移,还需要联系这 100 套数据库的所有业务去改连接方式,那如何在2个月去完成呢?这个战绩是非常惊人的。
同时还可以看出,不仅仅是零故障,效率也是非常值得称赞的,所以我们要做一个 New DBA 的话,一定要自动化,自动化可以解放你的双手,解放你的时间,为你成功地转变工作模式而助力。
九、总结
我们要做一个新时代的 DBA,成为一名 New DBA ,除了上面举例说明的一些重要事情之外,还有很多值得做的事情,而这些正是通往 New DBA 的必经之路,那究竟 New DBA 具有哪些特征呢?我想应该有以下几点:
高效率:低效率的事情都让机器去干。
自动化:让机器去做重复低效的事情。
主动性:具有一定程度上的预言特质,可以把问题提前发现并解决。
覆盖面广:解决一个问题,就可以解决一类问题,从一个点上升到一个线,进一步上升到面儿。
自由支配:事情安排不受制于其它因素,任何时间,任何地点,都可以进行。
轻松愉快:自我成就感高,生活幸福指数高,时刻体现自己的价值。
这是我们的目标,我希望也是 DBA 的共同目标,未来十年,DBA 的路在何方?
如果是上述这样的话,我们已经在路上了。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721