
一、背景
随着同程旅行业务和数据规模越来越大,原有的机房不足以支撑未来几年的扩容需求,同时老机房的保障优先级也低于新机房,为了不受限于机房的压力,公司决定进行机房迁移,为了尽快完成迁移,需要1个月内完成上百PB数据量的集群迁移,迁移过程不允许停止服务。
目前HADOOP集群主要有多个2.X集群版本,2019年升级到联邦模式,目前有近几十个namespace,80%的业务都与HDFS相关,资源调度层主要依赖YARN集群,上游支撑数仓建设、算法分析、机器学习等多个业务板块。
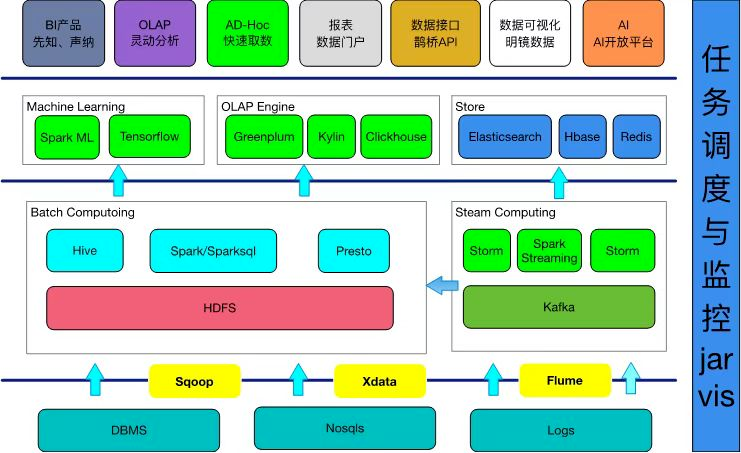
二、迁移方案
目前同程旅行有多套HDFS集群,在新机房搭建多套HDFS集群成本和数据同步都是不小的工作量,所以这个方案刚开始就被PASS,总体迁移方案规划是单集群扩缩容的方式进行迁移。
关于数据迁移有下面2个实现方案:

机房感知策略
副本选择节点策略
通过修改namenode核心代码,支持存储的多机房感知,增加节点的机房属性。
针对指定迁移的租户/目录做任务隔离搭建独立的yarn,迁移过程中充分利用HDFS本地性和减少跨机房产生的网络带宽。
按照目录/租户的方式进行迁移,方便控制进度和观察跨机房网络的稳定性
优点:可以细粒度的进行迁移;过程可控。
缺点:修改namenode核心代码,需要有一定时间来测试再上线;迁移周期相对比较久
通过策略控制新写入的数据写到使用率比较低的DN节点(新机房节点),从生产源头进行数据转移,对于历史的数据可以通过balance指定Iplist和集群迁移的方式来加快迁移
优点:可以不依赖具体的目录/租户来迁移,可以按照机架来迁移。
缺点:新的策略对于磁盘使用过低的datanode还是可能会出现一些热点问题,需要进行改进;balance速度比较慢,满足不了快速迁移需求;会产生大量的带宽压力,高峰期可能会集群造成额外的RPC压力。
最后我们选择方案B,理由是:我们需要尽快完成迁移,而且B方案迁移流程相对比较简单,不过需要对副本选择策略做源码改造,解决datanode的热点问题,同时对于balance可以进一步做性能优化,解决可能的RPC问题。
三、经验和教训
刚开始datanode下线的时候发现一组机架decommssion结束需要6H+,这个相对比较容易解决,需要做下参数优化,提高数据replication的速度,最后实现了一组机架下线时间从6个多小时到1个多小时,满足了迁移的需求。
<property><name>dfs.namenode.replication.max-streams</name><value>64</value></property><property><name>dfs.namenode.replication.max-streams-hard-limit</name><value>128</value></property><property><name>dfs.namenode.replication.work.multiplier.per.iteration</name><value>32</value></property>
采取扩缩容策略来进行迁移不可避免的会遇到DN节点下线后,存储压力会平摊到剩下的DN节点上,继而可能出现其他问题,下面是我们遇到的几个典型的问题。
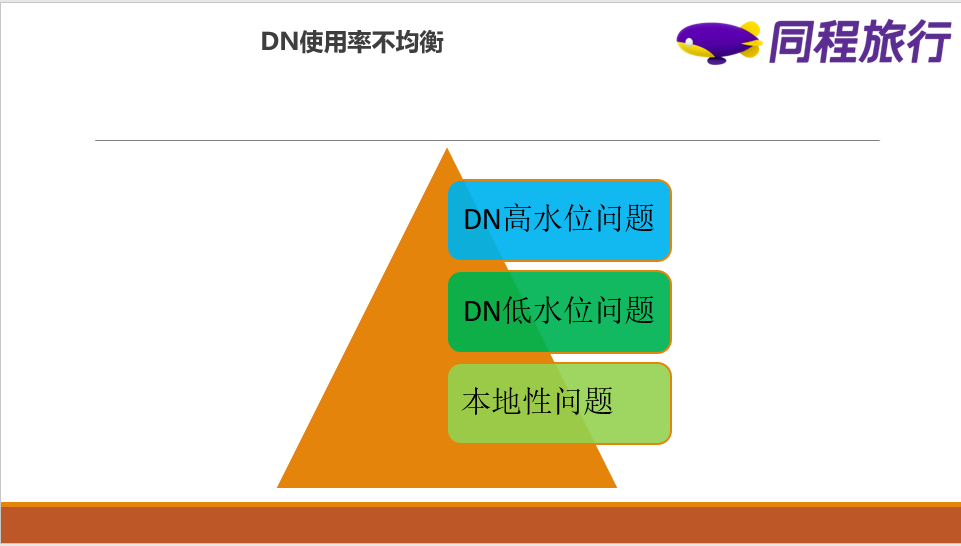
1)新写入的数据仍然会选择DN使用率比较高的节点
目前同程旅行的大数据服务基本都是标准部署模式,DN服务基本和NM服务进行了同节点部署,如果新写入的数据写到了使用率比较高的DN上,可能会引发下面两个问题。
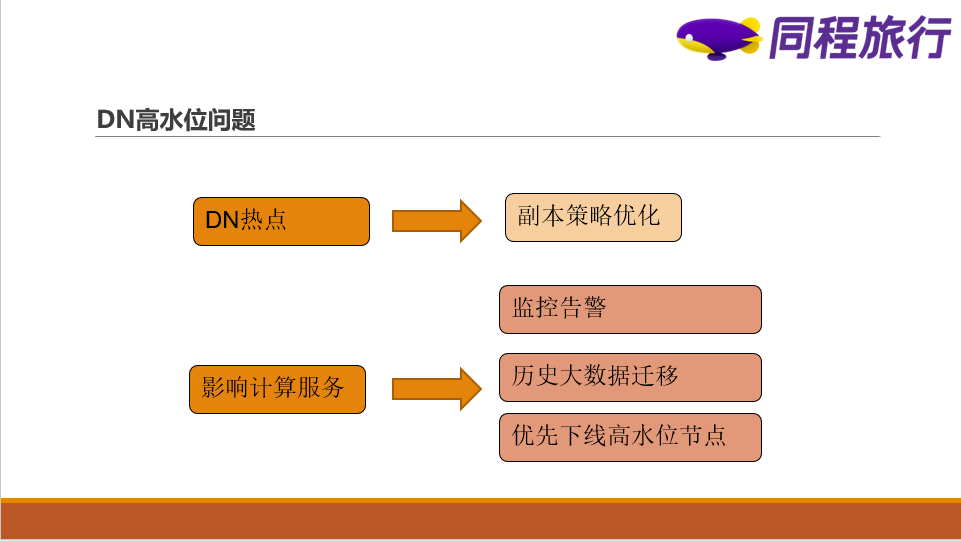
①产生DN热点,可能影响任务的读写
我们的磁盘SKU相差不大,使用率比较高的节点一般会有更多的数据,可能会有更多IO操作,导致硬件出现性能瓶颈,影响到数据的正常读写。
②NodeManager无法通过健康检测,会进入unhealthy状态
NM有磁盘空间检测项,一旦无法完成健康检测,服务将进入到UnHealthy状态,从可用服务列表中剔除,计算资源相应会减少。
为了解决这个问题,我们在hadoop2.5支持了基于空间策略的副本,这个策略的作用是让HDFS副本选择的时候优先考虑DN使用率比较低的DN节点(大多是新机房新上线的节点),这样数据在写入的时候就会写到新机房,减少了后续的迁移压力,不过低版本的策略有缺陷,存在出现空指针的场景,需要修复后才可以上线,同时我们也改进了源码中部分逻辑,并已贡献到hadoop社区,以便更合理的使用这个策略。
同时我们还通过数据迁移工具来加快迁移历史数据、通过优先下线高水位节点等手段有效控制了高水位节点的比例。
2)新写入的数据会大量选择DN使用率比较低的节点
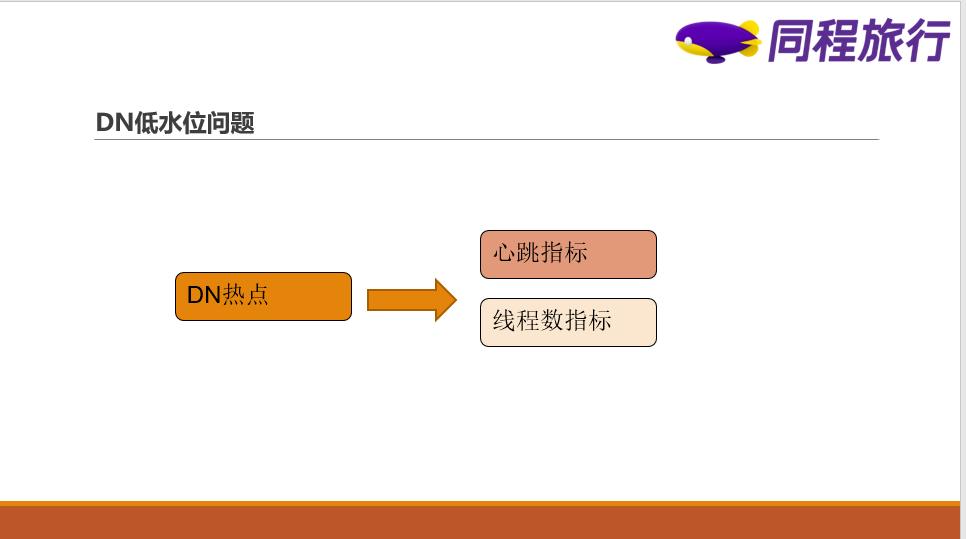
支持可用空间策略后,可以减少使用率过高的DN被写入,不过假设大量副本如果都选择到较低使用的DN,该DN有可能会成为新的“热点”,为此我们继续在源码上优化了此策略,副本选择的时候会参考DN的心跳汇报情况和线程数的情况,如果该DN过于繁忙,将不会被选择,基于新优化的可用空间策略既解决了数据过多写入到使用率比较高的DN上,也解决了数据过多写入到使用率过低的DN上引起的热点问题。
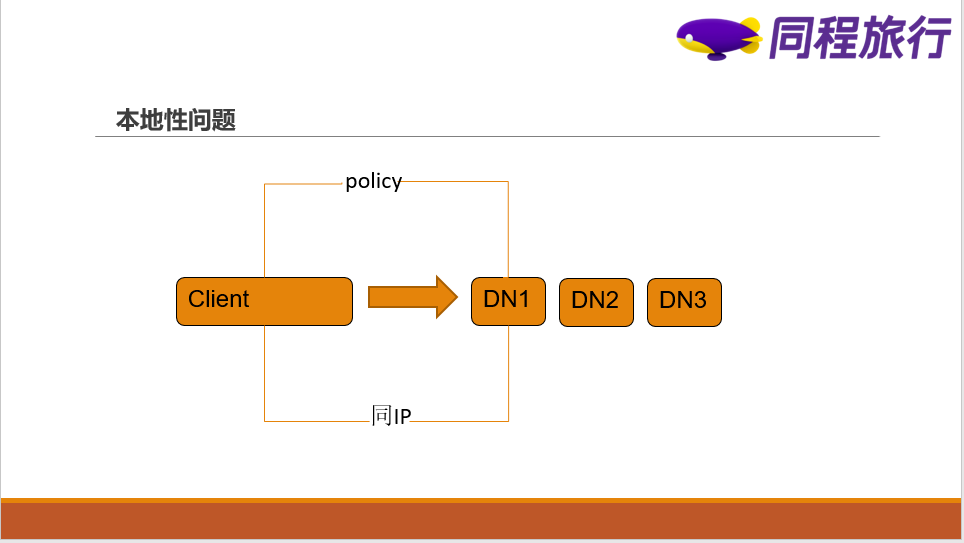
3)对于本地短路读的优化
短路读的开启充分利用了客户端和DN节点在同一个节点的优势,如果首选节点和客户端在同一个机器,那么pipeline很大可能会选择这个节点作为pipeline的第一个,数据写完本地后,然后按照副本选择策略去选择剩下的副本,我们在源码中改造了这块逻辑,在首选DN节点压力比较大时,可以不选择该DN节点,去选择更优的DN节点。
1)封装balance程序
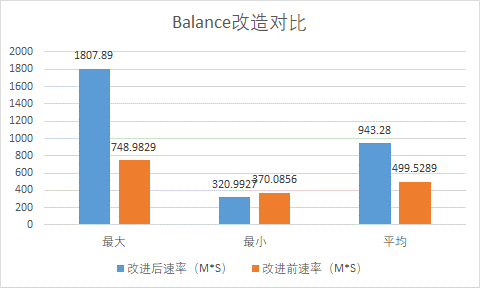
Balance程序默认会把所有节点纳入balance list,然后进行节点筛选,对不满足threshold的DN做balance,但是实际上我们更期望把一些使用率比较高的DN作为source,使用率比较低的DN作为destination,所以我们重新封装了Balance程序,支持按照指定IP的方式进行数据均衡,减少“无效”节点参与均衡占用宝贵的线程资源和RPC。
2)balance程序支持按照文件大小运行
同时过程中我们发现即使很少的文件都要占用一个线程和RPC去操作,这些比较小的文件对整体数据迁移起的作用不大,所以支持Balance过程中指定需要均衡的文件大小,优化后balance效率提升一倍,社区也在讨论默认balance的时候支持这种场景。
3)对balance进行监控
Balance是个好工具,不过同时也会产生大量的RPC请求,在夜间ETL压力比较大的时候,如果balance没有正常关闭的话可能会对ETL造成很大的影响,所以我们开发了一个监控小程序来24H监控balance是运行情况,保证balance在凌晨ETL时关闭,白天正常状态的时候开启。
另外我们对DN运行情况、网络带宽、RPC等也进行了监控,每天会分析下是否有指标是否达到性能瓶颈,同时给予告警。

四、跨集群迁移工具改造
Hadoop原生提供一个比较好用的跨集群迁移工具distcp,在集群迁移过程中为了进一步加快迁移速度,我们也在同步的做跨集群迁移,进一步减少需要迁移的数据,不过这个工具有下面几个使用限制:
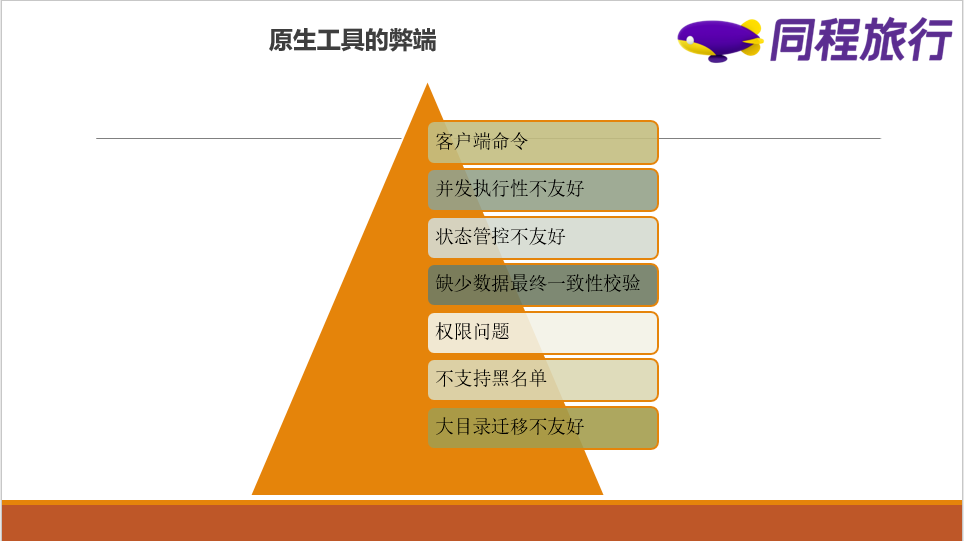
1)这是个客户端命令,需要有个客户端才好进行操作,不具有普遍操作性,放开使用有一定的权限风险。
2)并发执行性不友好,如果同时需要迁移100个大目录,需要额外的开发来满足并发的需求。
3)状态管控不友好,客户端执行命令后需要单线回收对应的结果,每次命令执行结束后需要单线等待结束状态。
4)缺少数据最终一致性校验,如果迁移过程中原始数据变更后,仍然可能会认为迁移成功,但是前后两个目录的大小等属性可能已经不一致。
5)权限不一致问题,distcp程序会保证迁移的最终文件的属性等保持一致,但是无法保证上层多级文件夹的权限,从而可能会导致后续写入权限的问题,需要人肉介入每次迁移进行检查。
6)不支持黑名单迁移,对于一些实时在变更的数据迁移场景可能会迁移失败,这类场景需要针对性的对于实时变更的目录做黑名单处理。
7)对于超大目录的迁移不友好,超大目录迁移需要更多的资源,不过程序只会起一个application,可能导致迁移失败,过大的目录需要在客户端也需要额外的MR参数调优才能够运行起来。
对此我们对distcp对了封装和改造,增加了如下的功能。

1)支持多人并发提交迁移job
可以多人24H随时选择迁移,不需要集群负责人配合执行迁移任务
2)多Job状态管理
多个任务并行执行,平台会记录每个Job的各个状态,方面掌握自己的迁移情况。
3)数据一致性校验
任务执行前后对会迁移的目录做数据统计,对于迁移前后数据不一致情况进行告警,及时关注数据情况。
4)目录权限智能匹配
目前既可以满足迁移前后权限等属性保持不变,也可以让迁移后的目录权限继承目标目录的父目录,特别是对于迁移集群同时进行租户梳理来说,这些都比较重要。
5)多Job进度管理
我们会定时自动刷新job的进度,通过平台可以看到迁移的进度。
6)模糊匹配
模糊匹配的功能可以用于多个层级,方面选择有一定特征的路径一起迁移,减少重复操作,比如可以按照库或者某个主体属性等一起迁移。
7)黑名单迁移
黑名单策略主要是应对部分实时数据变更的场景,数据迁移时可以自动过滤掉指定目录,减少实时数据和离线数据一起搬运,最后出现数据校验不一致的问题。
8)定时调度&宏变量迁移
对于一些每天都是变更的数据,可以通过调度指定宏变量来迁移指定日期的数据,不需要每天手动操作。
9)特殊文件自动处理
对于一些特殊文件,比如隐藏文件,本身文件之前是存在问题的,迁移过程中,我们也对这些可能有问题的文件进行自动处理,修复潜在的问题。
10)大任务智能拆解
对于一些单次搬运数据量比较大的任务,可以通过指定方式搬运,job会自动拆解为多个job,提高整个搬运的效率。
11)元数据一键更新
目前绝大多数的hdfs数据都有hive元数据,我们也支持了一键修改hive分区等元数据,方面数据和元数据一起完成迁移。
通过上述功能点的改造,基本满足了跨集群的各种数据迁移工作。
五、总结和未来展望
总结一下,本文主要介绍了同程旅行Hadoop集群跨机房的迁移实践,主要改造和优化如下:
支持并优化可用空间策略
针对短路读功能优化
针对DN热点的策略优化
集群迁移工具的功能加强
实现集群迁移多维度监控
后续我们期望对hadoop版本做下升级,统一目前的多版本现状,同时高版本的EC特性等可以很好的减少冷数据的存储成本,进一步实现降本增效。
参考资料
https://issues.apache.org/jira/browse/HDFS-8824
https://issues.apache.org/jira/browse/HDFS-9412
https://issues.apache.org/jira/browse/HDFS-13222
https://issues.apache.org/jira/browse/HDFS-13356
https://issues.apache.org/jira/browse/HDFS-10715
https://issues.apache.org/jira/browse/HDFS-14578
https://issues.apache.org/jira/browse/HDFS-8131








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721