
陈东明,具有丰富的大规模系统构建和基础架构的研发经验,善于复杂业务需求下的大并发、分布式系统设计和持续优化。近年专注于分布式系统一致性的研究,常年坚持技术文章创作和社区分享。曾就职于饿了么、百度,主导开发饿了么key-value数据库,负责百度即时通讯产品的架构设计。个人微信公众号dongming_cdm。本文是本人新书《分布式系统与一致性》的一个章节,节选出来和大家分享、讨论。
GFS(Google File System)是Google公司开发的一种分布式文件系统。虽然GFS在Google公司内部被广泛使用,但是在相当长的一段时间里它并不为人所知。2003年,Google发表一篇论文[1]详细描述了GFS,人们才开始了解GFS。开源软件也开始模仿GFS,第3章讲解的HDFS就是GFS的模仿者。
一、GFS的外部接口和架构
让我们从GFS的接口设计和架构设计说起吧。
GFS采用了人们非常熟悉的接口,但是并没有实现POSIX的标准文件接口。GFS通常的操作包括:create, delete, open, close, read, write, record append等,这些接口非常类似于POSIX定义的标准文件接口,但是不完全一致。
create, delete, open, close这几个接口的语义和POSIX标准接口类似,这里就不逐一强调说明了。下面详细介绍write和record append这两个接口的语义。
write(随机写):可以将任意长度的数据写入指定文件的位置,这个文件位置也被称为偏移(offset)。
record append(尾部追加写):可以原子地将长度小于16MB的数据写入指定文件的末尾。GFS之所以设计这个接口,是因为record append不是简单地将offset取值设置为文件末尾的write操作,而是不同于write的一个操作,并且是具有原子性的操作(后面会解释原子性)。
write和record append都允许多个客户端并发操作一个文件,也就是允许一个文件被多个客户端同时打开和写入。
GFS的架构如图2.1所示:
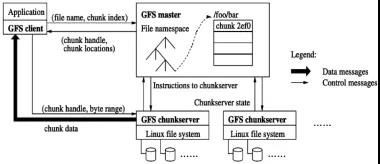
图2.1 GFS的架构(此图摘自GFS的论文[1])
GFS的主要架构组件有GFS client、GFS master和GFS chunkserver。一个GFS集群包括一个master和多个chunkserver,集群可以被多个GFS客户端访问。三个组件的详细说明如下:
GFS客户端(GFS client)是运行在应用(application)进程里的代码,通常以SDK形式存在。
GFS中的文件被分割成固定大小的块(chunk),每个chunk的长度固定为64MB。GFS chunkserver把这些chunk存储在本地的Linux文件系统中,也就是本地磁盘中。通常每个chunk会被保存三个副本(replica),也就是会被保存到三个chunkserver里。一个chunkserver会保存多个不同的chunk,每个chunk都会有一个标识,叫作块柄(chunk handle)。
GFS master维护文件系统的元数据(metadata),包括:
名字空间(namespace,也就是常规文件系统中的文件树)。
访问控制信息。
每个文件由哪些chunk构成。
每个chunk的副本都存储在哪些chunkserver上,也就是块位置(chunk location)。
在这样的架构下,几个组件之间有如下交互过程。
1)客户端与master的交互
客户端可以根据chunk大小(即固定的64MB)和要操作的offset,计算出操作发生在第几个chunk上,也就是chunk的块索引号(chunk index)。在文件操作的过程中,客户端向master发送要操作的文件名和chunk index,并从master中获取要操作的chunk的chunk handle和chunk location。
客户端获取到chunk handle和chunk location后,会向chunk location中记录的chunkserver发送请求,请求操作这个chunkserver上标识为chunk handle的chunk。
如果一次读取的数据量超过了一个chunk的边界,那么客户端可以从master获取到多个chunk handle和chunk location,并且把这次文件读取操作分解成多个chunk读取操作。
同样,如果一次写入的数据量超过了一个chunk的边界,那么这次文件写入操作也会被分解为多个chunk写入操作。当写满一个chunk后,客户端需要向master发送创建新chunk的指令。
2)客户端向chunkserver写数据
客户端向要写入的chunk所在的三个chunkserver发送数据,每个chunkserver收到数据后,都会将数据写入本地的文件系统中。客户端收到三个chunkserver写入成功的回复后,会发送请求给master,告知master这个chunk写入成功,同时告知application写入成功。
这个写流程是高度简化和抽象的,实际的写流程更复杂,要考虑写入类型(是随机写还是尾部追加写),还要考虑并发写入(后面的2.2节会详细描述写流程,解释GFS是如何处理不同的写入类型和并发写入的)。
3)客户端从chunkserver读数据
客户端向要读取的chunk所在的其中一个chunkserver发送请求,请求中包含chunk handle和要读取的字节范围(byte range)。chunkserver根据chunk handle和byte range,从本地的文件系统中读取数据返回给客户端。与前面讲的写流程相比,这个读流程未做太多的简化和抽象,但对实际的读流程还会做一些优化(相关优化和本书主题关系不大,就不展开介绍了)。
二、GFS的写流程细节
本节我们详细讲解在前面的写数据过程中未提及的几个细节。
在写流程中,当要创建新文件和将数据写入新chunk时,客户端都需要联系master来操作master上的名字空间。
创建新文件:在名字空间创建一个新对象,该对象代表这个文件。
将数据写入新chunk中:向master的元数据中创建新chunk相关信息。
如果有多个客户端同时进行写入操作,那么这些客户端也会同时向master发送创建文件或创建新chunk的指令。master在同一时间收到多个请求,它会通过加锁的方式,防止多个客户端同时修改同一个文件的元数据。
客户端需要向三个副本写入数据。在并发的情况下,也会有多个客户端同时向三个副本写入数据。GFS需要一条规则来管理这些数据的写入。简单来讲,这条规则就是每个chunk都只有一个副本来管理多个客户端的并发写入。也就是说,对于一个chunk,master会将一个块租约(chunk lease)授予其中一个副本,由具有租约的副本来管理所有要写入这个chunk的数据。这个具有租约的副本称为首要副本(primary replica)。首要副本之外的其他副本称为次要副本(secondary replica)。
对文件的写入称为变更(mutation)。首要副本管理所有客户端的并发请求,让所有的请求按照一定的顺序用到chunk上,这个顺序称为变更次序(mutation order)。变更包括两种,即前面讲过的write操作和record append操作。接下来介绍GFS基本变更流程,write操作就是按照这个基本变更流程进行的,而record append操作则在这个基本变更流程中多出一些特殊的处理。
1)基本变更流程:
图2.2描述了GFS基本变更流程:
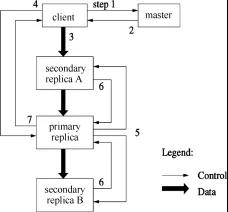
图2.2 GFS基本变更流程(此图摘自GFS的论文[1])
整个写入过程包括以下7个步骤。
①当客户端要进行一次写入时,它会询问master哪个chunkserver持有这个chunk的租约,以及其他副本的位置。如果没有副本持有这个chunk的租约,那么master会挑选一个副本,通知这个副本它持有租约。
②master回复客户端,告诉客户端首要副本的位置和所有次要副本的位置。客户端联系首要副本,如果首要副本无响应,或者回复客户端它不是首要副本,则客户端会重新联系master。
③客户端向所有的副本以任意的顺序推送数据。每个chunkserver都会将这些数据缓存在缓冲区中。
④当所有的副本都回复已经收到数据后,客户端会发送一个写入请求(write request)给首要副本,在这个请求中标识了之前写入的数据。首要副本收到写入请求后,会给这次写入分配一个连续串行的编号,然后它会按照这个编号的顺序,将数据写入本地磁盘中。
⑤首要副本将这个带有编号的写入请求转发给次要副本,次要副本也会按照编号的顺序,将数据写入本地,并且回复首要副本数据写入成功。
⑥当首要副本收到所有次要副本的回复后,说明这次写入操作成功。
⑦首要副本回复客户端写入成功。在任意一个副本上遇到的任意错误,都会告知客户端写入失败。
2)原子记录追加
record append这个接口在论文[1]中被称为原子记录追加(atomic record append),它也遵循基本变更流程,但有一些附加的逻辑。客户端把要写入的数据(这里称为记录,record)推送给所有的副本,如果record推送成功,则客户端会发送请求给首要副本。
首要副本收到写入请求后,会检查把这个record追加到尾部会不会超出chunk的边界,如果超出边界,那么它会把chunk剩余的空间填充满(这里填充什么并不重要,后面的2.4节会解释这个填充操作),并且让次要副本做相同的事情,然后再告知客户端这次写入应该在下一个chunk上重试。如果这个record适合chunk剩余的空间,那么首要副本会把它追加到尾部,并且告知次要副本写入record在同样的位置,最后通知客户端操作成功。
三、GFS的原子性
接下来我们分析GFS的一致性,首先从原子性开始分析。
前面讲过,如果一次写入的数据量超过了chunk的边界,那么这次写入会被分解成多个操作,write和record append在处理数据跨越边界时的行为是不同的。
下面我们举例来进行说明。
例子1:目前文件有两个chunk,分别是chunk1和chunk2。客户端1在54MB的位置写入20MB数据。同时,客户端2也在54MB的位置写入20MB的数据。两个客户端都写入成功。
前面讲过,chunk的大小是固定的64MB。客户端1的写入跨越了chunk的边界,因此要被分解成两个操作,其中第一个操作写入chunk1最后10MB数据;第二个操作写入chunk2开头10MB数据。
客户端2的写入也跨越了chunk的边界,因此也要被分解为两个操作,其中第一个操作(作为第三个操作)写入chunk1最后10MB数据;第二个操作(作为第四个操作)写入chunk2开头10MB数据。
两个客户端并发写入数据,因此第一个操作和第三个操作在chunk1上是并发执行的,第二个操作和第四个操作在chunk2上也是并发执行的。如果chunk1先执行第一个操作,后执行第三个操作;chunk2先执行第四个操作,后执行第二个操作,那么最后在chunk1上会保留客户端1写入的数据,在chunk2上会保留客户端2写入的数据。虽然客户端1和客户端2的写入都成功了,但最后的结果既不是客户端1想要的结果,也不是客户端2想要的结果,而是客户端1和客户端2写入的混合结果。对于客户端1和客户端2来说,它们的操作都不是原子的。
例子2:目前文件有两个chunk,分别是chunk1和chunk2。一个客户端在54MB的位置写入20MB数据,但这次写入失败了。
这次写入跨越了chunk的边界,因此要被分解成两个操作,其中第一个操作写入chunk1最后10MB数据;第二个操作写入chunk2开头10MB数据。chunk1执行第一个操作成功了,chunk2执行第二个操作失败了。也就是说,写入的这部分数据,一部分是成功的,一部分是失败的。这也不是原子操作。
例子3:目前文件有一个chunk,为chunk1。一个客户端在54MB的位置追加一个12MB的记录,最终写入成功。
由于这个record append操作最多能在chunk1中写入10MB数据,而要写入的数据量(12MB)超过chunk的剩余空间,剩余空间会被填充,GFS会新建一个chunk,为chunk2,这次写入操作会在chunk2上重试。这样就保证了record append操作只会在一个chunk上生效,从而避免了文件操作跨越边界被分解成多个chunk操作,也就避免了写入的数据一部分成功、一部分失败和并发写入的数据混在一起这两种非原子性的行为。
GFS中的一次写入,可能会被分解成分布在多个chunk上的多个操作,并且由于master的锁机制和chunk lease机制,如果写入操作发生在一个chunk上,则可以保护它是原子的。但是如果一些文件写入被分解成多个chunk写入操作,那么GFS并不能保证多个chunk写入要么同时成功、要么同时失败,会出现一部分chunk写入成功、一部分chunk写入失败的情况,所以不具有原子性。之所以称record append操作是原子的,是因为GFS保证record append操作不会被分解成多个chunk写入操作。如果write操作不跨越边界,那么write操作也满足GFS的原子性。
GFS中一个chunk的副本之间是不具有原子性的,不具有原子性的副本复制行为表现为:一个写入操作,如果成功,那么它在所有的副本上都成功;如果失败,则有可能是一部分副本成功,而另一部分副本失败。
在这样的行为下,失败会产生以下结果:
write在写入失败后,虽然客户端可以重试,直到写入成功,达到一致的状态,但是如果在重试成功以前,客户端出现宕机,那么就变成永久的不一致了。
record append在写入失败后,也会重试,但是与write的重试不同,它不是在原有的offset处重试,而是在失败的记录后面重试,这样record append留下的不一致是永久的,并且还会出现重复问题。如果一条记录在一部分副本上写入是成功的,在另外一部分副本上写入是失败的,那么这次record append就会将失败的结果告知客户端,并且让客户端重试。如果重试后成功,那么在某些副本上,这条记录就会被写入两次。
从以上结果可以得出结论:record append保证至少有一次原子操作(at least once atomic)。
四、GFS的松弛一致性
GFS把自己的一致性称为松弛的一致性模型(relaxed consistency model)。GFS的一致性分为元数据的一致性和文件数据的一致性,松弛一致性主要是指文件数据。
元数据的操作都是由单一的master处理的,并且操作通过锁来保护,所以保证了原子性,也保证了正确性。
在介绍松弛的一致性模型之前,我们先看松弛一致性模型中的两个概念。对于一个文件中的区域:
无论从哪个副本读取,所有客户端总是能看到相同的数据,这称为一致的(consistent)。
在一次数据变更后,这个文件的区域是一致的,并且客户端可以看到这次数据变更写入的所有数据,这称为界定的(defined)。
在GFS论文[1]中,总结了GFS的松弛一致性,如表2.1所示。

表2.1 GFS的松弛一致性
下面分别说明表中的几种情况:
在没有并发的情况下,写入不会相互干扰,成功的写入是界定的,那么也就是一致的。
在并发的情况下,成功的写入是一致的,但不是界定的。比如,在前面所举的“例子1”中,chunk1的各个副本是一致的,chunk2的各个副本也是一致的,但是chunk1和chunk2中包含的数据既不是客户端1写入的全部数据,也不是客户端2写入的全部数据。
如果写入失败,那么不管是write操作失败还是record append操作失败,副本之间会出现不一致性。比如,在前面所举的“例子2”中,当一些写入失败后,chunk的副本之间就可能出现不一致性。
record append能够保证区域是界定的,但是在界定的区域之间夹杂着一些不一致的区域。record append会填充数据,不管各个副本是否填充相同的数据,这部分区域都会被认为是不一致的。比如前面所举的“例子3”。
GFS的松弛一致性模型,实际上是一种不一致的模型,或者更准确地说,在一致的数据中间夹杂着不一致的数据。
这些夹杂在其中的不一致的数据,对应用来说是不可接受的。在这种一致性下,应该如何使用GFS呢?在GFS的论文[1]中,给出了几条使用GFS的建议:依赖追加(append)而不是依赖覆盖(overwrite)、设立检查点(checkpoint)、写入自校验(write self-validating)、自记录标识(self-identifying record)。下面我们用两个场景来说明这些方法。
场景1:在只有单个客户端写入的情况下,按从头到尾的方式生成文件。
方法1:先临时写入一个文件,在全部数据写入成功后,将文件改名为一个永久的名字,文件的读取方只能通过这个永久的文件名访问该文件。
方法2:写入方按一定的周期写入数据,在写入成功后,记录一个写入进度检查点,其信息包含应用级的校验数(checksum)。读取方只校验和处理检查点之前的数据。即便写入方出现宕机的情况,重启后的写入方或者新的写入方也会从检查点开始,继续写入数据,这样就修复了不一致的数据。
场景2:多个客户端并发向一个文件尾部追加数据,就像一个生产消费队列,多个生产者向一个文件尾部追加消息,消费者从文件中读取消息。
方法:使用record append接口,保证数据至少被成功写入一次。但是应用需要应对不一致的数据和重复数据。
为了校验不一致的数据,为每条记录添加校验数,读取方通过校验数识别出不一致的数据,并且丢弃不一致的数据。
对于重复数据,可以采用数据幂等处理。具体来说,可以采用两种方式处理。第一种,对于同一份数据处理多次,这并无负面影响;第二种,如果执行多次处理带来不同的结果,那么应用就需要过滤掉不一致的数据。写入方写入记录时额外写入一个唯一的标识(identifier),读取方读取数据后,通过标识辨别之前是否已经处理过该数据。
前面讲解了基于GFS的应用,需要通过一些特殊手段来应对GFS的松弛一致性模型带来的各种问题。对于使用者来说,GFS的一致性保证是非常不友好的,很多人第一次看到这样的一致性保证都是比较吃惊的。
GFS在架构上选择这样的设计,有它自己的设计哲学。GFS追求的是简单、够用的原则。GFS主要解决的问题是如何使用廉价的服务器存储海量的数据,且达到非常高的吞吐量(GFS非常好地做到了这两点,但这不是本书的主题,这里就不展开介绍了),并且文件系统本身要简单,能够快速地实现出来(GFS的开发者在开发完GFS之后,很快就去开发BigTable了[2])。
GFS很好地完成了这样的目标,但是留下了一致性问题,给使用者带来了负担。这个问题在GFS推广应用的初期阶段不明显,因为GFS的主要使用者(BigTable系统是GFS系统的主要调用方)就是GFS的开发者,他们深知应该如何使用GFS。这种不一致性在BigTable中被屏蔽掉(采用上面所说的方法),BigTable提供了很好的一致性保证。
但是随着GFS推广应用的不断深入,GFS简单、够用的架构开始带来很多问题,一致性问题仅仅是其中之一。Sean Quinlan作为Leader主导GFS的研发很长时间,在一次采访中,他详细说明了在GFS渡过推广应用的初期阶段之后,这种简单的架构带来的各种问题[2]。
在清晰地看到GFS的一致性模型给使用者带来的不便后,开源的HDFS(Hadoop分布式文件系统)坚定地摒弃了GFS的一致性模型,提供了更好的一致性保证(第3章将介绍HDFS的实现方式)。
注:以上是《分布式系统与一致性》书中的第二个章节,书中详细介绍了GFS、HDFS、BigTable、MongoDB、RabbitMQ、ZooKeeper、Spanner、CockroachDB系统与一致性有关的实现细节,以及非常重要的Paxos、Raft、Zab分布式算法;本书还介绍了事务一致性与隔离级别、顺序一致性、线性一致性与强一致性相关内容,以及架构设计中的权衡CAP理论等。点击文末【阅读原文】可入手本书,希望和大家一起探讨分布式一致性这个难题。
参考资料
[1] Ghemawat S, Gobioff H, Leung S T. The Google File System. ACM SIGOPS Operating Systems Review, 2003.
[2] Marshall, Kirk, McKusick, et al. GFS: Evolution on Fast-forward. Communications of the ACM, 2009.
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721