
韩锋,建信金科数据库专家,dbaplus社群联合发起人,CCIA(中国计算机协会)常务理事、Oracle ACE,曾担任多家公司首席DBA、数据库架构师等职务。具有丰富的一线数据库架构、设计、开发经验,精通多种关系型数据库,包括Oracle、MySQL、GreenPlum、Informix等,对NoSQL及大数据相关技术也有实践经验。著有《SQL优化最佳实践》《数据库高效优化》等书籍。
数据库迁移,是个老生常谈的问题,之前也曾写过一篇文章。近期,针对这一课题,自己有了些新的思考,下面将具体展开谈谈。在这之前,我先谈谈数据库迁移的现实需求。这也算是目前行业发展的一个小总结。
背景:迁移之源,多变之秋
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
近些年来,信息数据呈快速增长态势。如下图所示,全球数据量总和,预计将从 2018 年的 33ZB 增至2025年的 175ZB。国内数据体量在未来 7年将实现复合增速 30%以上的快速增长,并在 2025年成为与欧洲、中东、非洲、亚太和美国等地区相比体量最大的区域。数据的爆发式增长,导致对数据存储容量、数据计算需求有个更好的要求,这也催生企业在基础设施层面不断革新,进而不断推动数据库向前进一步发展。

从数据库市场来看,也验证了这一趋势。整体市场呈现稳定的发展趋势,最近的数据表明,国内的数据库市场已经达到200亿规模。

开源数据库,其源代码具备全球共享、免费等特点,开发者可在其源码中修改或使用。在近一、二十年来,越来越多的企业将开源方案作为构建底层支持的可选答案。特别是随着互联网的兴起,大量互联网企业选择使用了开源数据库产品,也加速这些产品的成熟与发展。这其中MySQL、PostgreSQL、MongoDB 和 Redis 是当前开源数据库最为重要的参与者。
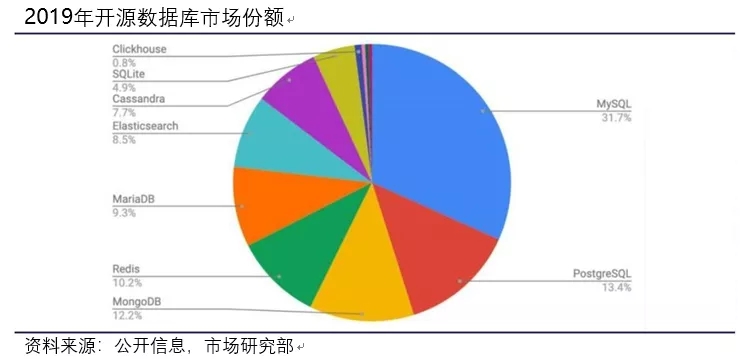
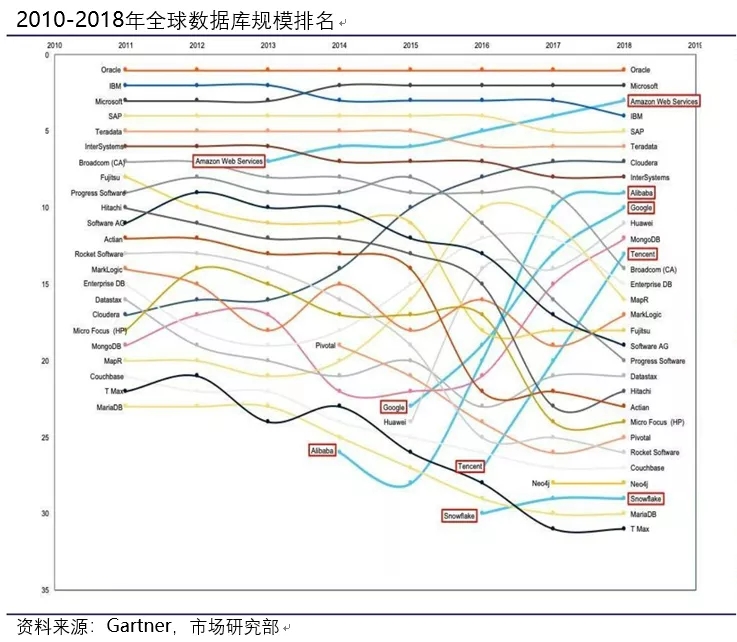
从2017至 2018年,整个数据库市场增长了 18.4%,其中云数据库增长贡献 68%。以AWS、Microsoft、Alibaba为代表的云厂商,取得了快速发展,极大地重塑了全球供应商格局。国内互联网科技巨头,纷纷布局数据库产业,借力云计算实现数据库等基础软件领域的迭代与超越。如下图的数据库规模排名,云数据库厂商均取得不俗的增长,最新数据则更是如此。甚至有机构预测,今明两年从数据库部署形态上看,云部署数据库会超过传统部署方式。
正如下图所示,国内数据库市场仍然为欧美垄断,但国产化趋势已非常明显。以国产自研或开源定制路线的厂商层出不求,从最新的调查结果来看,已经有130+的国产数据库厂商初选。
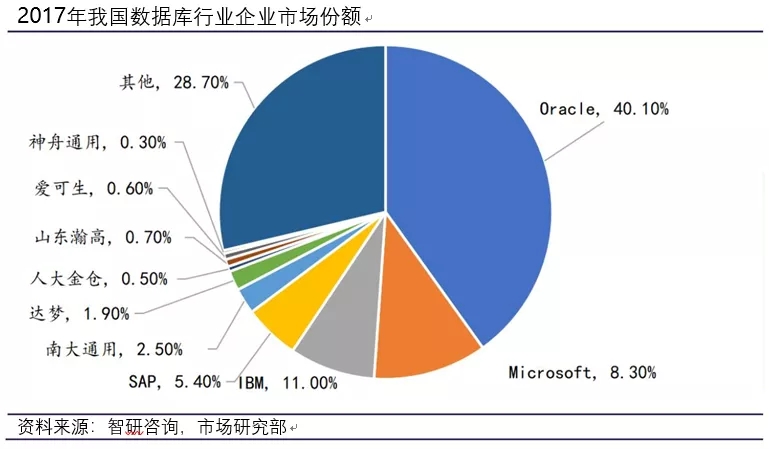
从一叶扁舟到百舸争流,传统国产数据库历经长时间艰难探索,已逐步崭露头角。国外大厂长期垄断国内数据库市场。Oracle、IBM 和 Microsoft 等老牌厂商凭借先发优势在市场份额中占据了有利地位。国产数据库起步较晚,但潜力巨大。正如下图可见,国产数据库占比正不断增加。
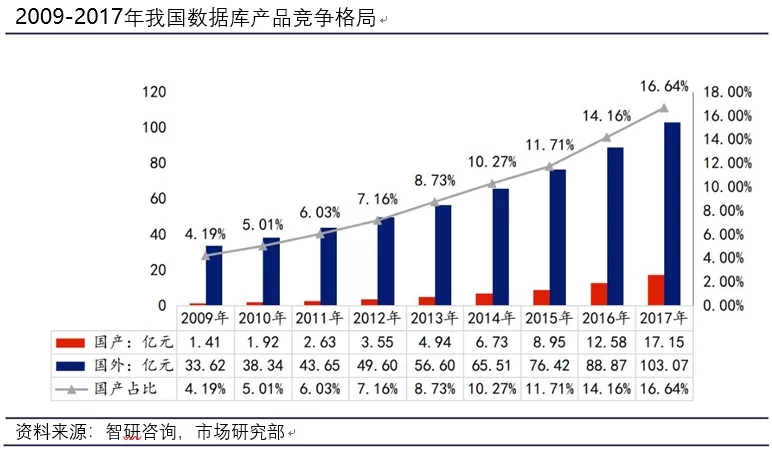
综上所述,从数据规模体量的增大,到开源商业的变化,再到云化趋势明显、国产化趋势加剧;而这些变化都带来同一个诉求,那就是数据库迁移。展开来说,是如何完成异构数据库迁移?完成体系架构完全不同的数据库之间的迁移(例如从单机到分布式)?完成从线下到云上的迁移?完成在线的、不终端业务的迁移?等等。诸多上述问题,对迁移提出了非常高的要求。本文下面尝试从迁移的多个阶段来阐述,需要哪些能力才能完成这一过程。
数据库迁移之路
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
在实际的迁移中,是一个比较复杂的过程,可根据阶段做个拆解。
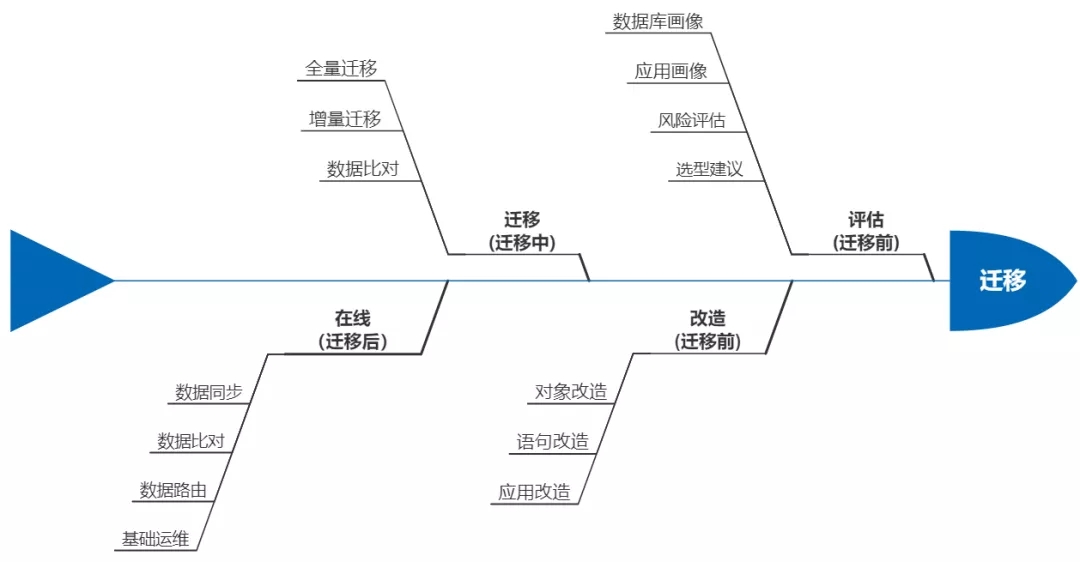
此阶段是完成迁移前的评估,为后续迁移改造、迁移过程做好铺垫工作
1)数据库画像
数据库画像结果,可为后续选型评估、架构规划提供依据。
系统级
收集系统级信息,包括但不限于硬件(CPU、MEM、NET、DISK)、操作系统(内核、参数、安全策略等)、性能(系统高峰期24小时负载)等。
实例级
收集实例级信息,包括但不限于架构(单机/集群、版本等)、参数(数据库参数等)、数据规模(表、索引等空间使用)、运行态信息(如QPS、TPS、会话、事务等)。
对象级
收集对象级信息,包括但不限于结构信息(表、分区、分片、索引、视图、序列等)、统计信息、访问特征(读写比、频率等)、预警类(如大表、复杂结构、DBLink等)。
语句级
收集语句级信息,包括但不限于SQL文本(全量)、执行特征(次数、响应时间等)、执行计划。
应用级
收集复杂应用信息,包括但不限于计算文本(如存储过程、触发器、函数等)、 执行特征(次数、响应时间等)。
2)应用画像
应用画像结果,为后面应用改造做好铺垫。
应用拓扑
收集应用架构、应用与DB关系、应用访问特征等。
3) 风险评估
针对上面收集的数据库、应用画像信息,针对重点风险点做出评估。
数据库架构
源库使用集群、分库分表等架构,做出提示。
数据库结构
源库使用复杂结构(如分区表)、不支持结构(LOB、可更新视图等),做出提示。
数据库语句
源库使用复杂SQL(如多表关联)、特殊语法或方言等给出提示。
数据库应用逻辑
源库大量使用存储过程、触发器、函数等。
应用架构
应用使用何种访问方式(如java、c、go等),对于某些旧有的方式予以提示。
性能维度
源库存在明显的性能访问高峰,明显的热点对象。
规模维度
源端数据库总体或单体对象规模较大的情况。
4) 选型建议
根据上面收集信息及风险评估内容,给出选型的建议。这里存在几个难点,一个是多目标数据库的基础能力抽象,一个是两者的适配评估。功能上包括两部分:
目标端建模
目标端在架构、结构、应用、性能指标等方面的基础抽象。
评估适配建议
根据源端和目标端情况,结合风险及性能要求给出适配选型建议。
1) 对象改造
这一阶段主要是通过结构映射及不兼容提示,来减少改造工作量。
映射规范
适配多目标端给出结构映射规范。
结构改造
基于给定输入,输出改造后结构。可能存在非一一对应的情况,可根据源与目标的差异,异构改造。
不兼容提示
对于不兼容的情况,给出文字提示,人工介入。
2) 语句改造
这一阶段主要通过语句改写,减少改造工作量;同时提供增强功能,满足语句改造后的测试等需求。
SQL改造
基于给定输入,给出改造后的语法。
不兼容提示
对于不兼容的情况,给出文字提示,人工介入。
增强-执行计划对比
可对比两边执行计划,方便研发优化语句写法。
增强-性能对比
可对比两边执行效率,方便研发优化。此处需保证同等测试环境。
增强-SQL自主优化
提供优化改写能力,而非基于简单规则。此处需注意,语义等价性问题。
3)应用改造
此处应用是指数据内置的计算能力(如存储过程等)。这一阶段主要是通过逻辑改写,减少人工工作量。在实现上,一般建议使用外部程序逻辑(如java)进行处理,而不是改造为目标端内部计算应用。原因是尽量减少数据库耦合。此处,存在较多难点,且需要人工检查改造后的语义是否正确。
应用改造
基于给定输入,给出改造后的实现(推荐java)。
不兼容提示
对于不兼容的情况,给出文字提示,人工介入。
应用校验
对比两侧的实现,验证处理逻辑是否一致。
1)全量/增量数据迁移
完成异构数据库间的数据迁移工作。主要难点是效率、准确性。
全量迁移
增量数据迁移
基于指定时间戳后的增量迁移能力
增强-分拆、合并能力
支持一拆多,多合一迁移能力。
增强-迁移计算能力
支持在迁移实时计算能力(如lookup)。
增强-通用异构适配能力
统一迁移能力,不依赖某种库。
增强-提供可配置UI
提供可配置同步界面,简化操作。
增强-数据转换能力
提供字符集、时区等转换能力。
2)数据对比
见后面说明
1)数据同步
在线运行时,需提供数据库端的异构同步能力,满足业务随时回迁的需求。
实时同步
提供异构数据库间数据实时同步能力,难点在于大吞吐、实时性。
增强-细粒度同步
支持库、用户、表同步能力。
增强-同步计算能力
支持在同步的实时计算能力(如lookup) ,难点在于效率。
2) 数据对比
数据对比,是用户对比双线运行的基本要求,需要满足实时对比并兼顾效率。
异构对比
提供异构数据源之间全量、增量数据对比能力。
增强-细粒度对比
支持库、用户、表、记录级别对比能力。
增强-数据补差
提供差异数据的双向补齐能力。
3)数据路由
数据路由,为业务提供统一数据库访问入口,并基于此提供双路控制能力,可做到按流量、按读写、按访问类别(生产、测试)等做数据访问路由。
4) 基础运维
此部分的能力比较多,本质就是同时提供异构数据库在线同步运维能力。例如包括统一变更、统一导入导出、统一授权、统一审计等。尽量从运维侧角度来看,后面是一套逻辑库。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721