
雷孝龙,去哪儿网DBA,2019年8月加入去哪儿网,拥有丰富的数据库运维和优化经验,现负责公司的MySQL/Redis运维工作,及自动化方案的实施和落地。
一、概述
数据库迁移拆分是我们日常运维工作中不可避免的一环,本文主要分析数据库常用的迁移方案对应的使用场景以及优劣势,同时分享了 Quanr 数据库使用架构,以及架构演进过程中的实践经验。
二、迁移方案
通常,一个数据迁移方案的设计,取决于原本的数据架构和业务场景。最终目标都是尽可能的对业务友好,停服时间越短越好,甚至是不停服,同时还需要保证数据的一致性。
常见的在线数据迁移方式都是先建立主从,同步数据;等待业务低峰期进行割接,主要过程如下:
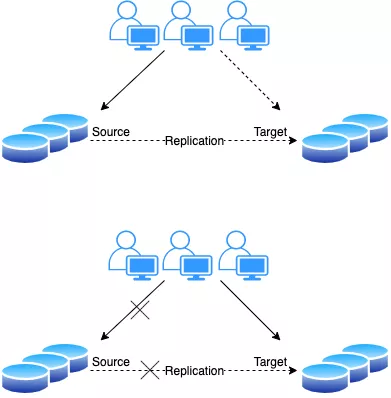
新老集群进行主从复制同步数据;
低峰期停止业务写入,检查主从同步数据一致性;
业务修改连接到新集群,发布程序;
验证迁移结果。
上述方法的优劣势显而易见。
优势:架构简单,对DBA来说很友好,只需要新建一套集群,确保主从同步和数据一致即可。
劣势:对业务来说比较不友好,需要在低峰期停止写入;如果集群涉及的业务多的话,必须在同一时间点停服,进行连接方式的变更发布;可能还会面临流量切换不完全,导致双写的情况。
借助 proxy 代理进行数据迁移,具体流程如下:
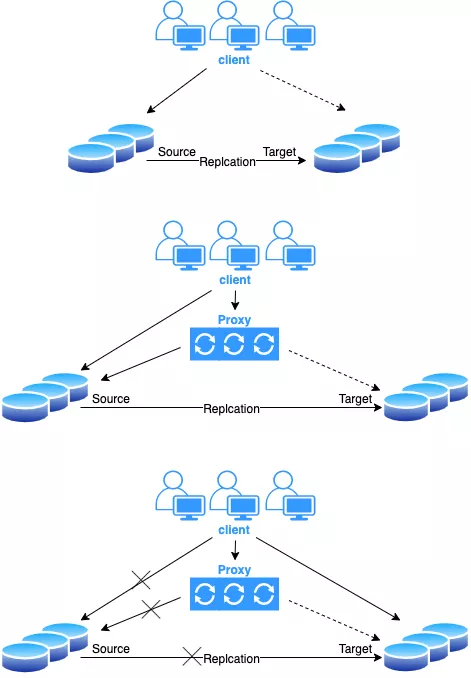
分为三个阶段:
1)建立主从复制,将原集群的数据复制到新集群。
2)在原集群上加一层 proxy,用于流量转发,通过 proxy 来控制流量分发到哪个集群;此时,通知业务开发,修改连接到 proxy(连接方式可以是虚 IP、域名、服务名等)。
3)接下来就是 DBA 的工作,观察流量,业务流量都切到 proxy 之后,切断 Source 到 Target 的主从复制,确保数据一致之后,使用代理,将流量打到目的端数据库。需要注意的是,在切流量和断复制时,要保证时间足够短,并且复制没有延时。最后通过切换虚拟 ip 或修改 DNS 解析等,下掉 proxy,最终程序直接访问目的端数据库。或者通知业务在修改一次连接方式,从 proxy 到目的端数据库。
总结一下迁移方案的优劣势。
优势:该方案的优势在于,加入 proxy 之后,可以由 DBA 来控制入口流量的分发。开发在发布程序修改连接方式时,支持滚动发布,两种访问方式并存,不需要停服;另一方面,DBA 和开发工作解藕,不需要在某个固定时间发布程序,进行割接,DBA 可以通过流量来源来判断业务通过哪种方式来访问数据库,确保流量是否切干净。
劣势:架构相对复杂,对 DBA 来说增加了运维成本和难度。业务中断时间取决于 proxy 重启时间,也就是将流量从 Source 集群切到 Target 集群的中断时间,不过一般来说非常快,可以控制在秒级以内。数据库连接会出现闪断,需要确保业务能够重连,同时还要保证主从数据的一致性。
对比上面的两种迁移方案,可以说各有千秋,有各自适用的场景,第一种方案比较适用于业务能够接受中断,数据库集群使用方比较明确,不存在多个业务混用情况,否则停机维护将会是一个巨大的工程。另一方面,需要业务方值得信赖。
这里信赖为什么要加粗显示呢?一定是有故事在其中。前面也说到,需要业务在特定的时间内,完成连接方式的修改,从老集群地址修改到访问新集群。流量切换干净与否完全取决于业务方,在停服期间,DBA 没有办法判断业务流量是否切换干净,是否还有残余的流量在老的集群中写入,只有业务启动之后才能判断。如果流量没有切干净,那一切都晚了,业务开始双写,数据不一致了,想想怎么回滚或者补数据去吧。但对于有“心机”的 DBA 来说,可能不那么信任业务,会悄悄的留一手,通过老集群设置只读、回收用户权限等方式,让业务没法再往老集群写入。通过损失业务的方式来保证数据一致性,这样下来,第二种方案优势就非常明显了。
第二种方案最核心的思想就在于让数据库可同时提供两种访问方式,两种访问方式同时指向一个数据库实例,可以让业务平滑的在两种方式之间过渡。业务开发和 DBA 工作解藕,有充足的时间去发布程序,DBA 也有相应的手段来判断业务流量是否切彻底,确保数据一致。
三、Qunar 集群架构
基于上述的第二种方案的思想,下面介绍 Qunar 内部架构升级迁移方案。先来了解下去哪儿网的数据库架构。
集群架构图如下:
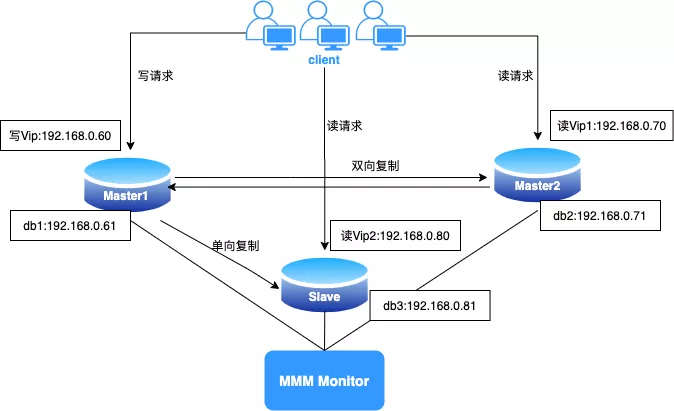
MMM(Master-Master replication manager for MySQL)是一套比较老的数据库高可用架构了,早期在 Qunar 内部使用比较广泛。采用 Monitor 和 Agent 来监控和管理 MySQL 的双向复制。业务同一时刻只允许对一个主进行写入,另一台备选主上只提供读服务,还可增加 Slave 节点,用于读负载均衡,使用虚拟IP对外提供服务,不受客户端的限制。
MMM 采用 VIP 漂移方式实现的故障转移,由于使用的是异步复制,无法完全的保证数据一致性,所以适用于对数据的一致性要求不是很高,但是又想最大程度的保证业务可用性的场景。对于那些对数据的一致性要求很高的业务,不建议采用 MMM 这种高可用架构,并且 MMM 不支持网络分区,无法实现跨机房部署。
详细介绍请移步到官网:https://mysql-mmm.org
Percona XtraDB Cluster (简称 PXC) 是 Percona 公司开源的实现 MySQL 高可用的解决方案。它将 Percona Server 和 Percona XtraBackup 与 Galera 库集成,以实现多主同步复制。和 MySQL 传统的异步复制相比,能够保证数据的强一致性,在任何时刻集群中任意节点上的数据状态都是完全一致的,并且整个架构实现了去中心化,所有节点都是对等的,即允许在任意节点上进行写入和读取,集群会把数据状态同步至其他所有节点。但目前 PXC 集群在使用上有较多限制,比如:只支持 InnoDB 存储引擎,事务大小限制等等,需要选择合适的应用场景。
详细介绍请移步到官网:http://www.percona.com/doc/percona-xtradb-cluster
Qunar 内部使用架构图如下:
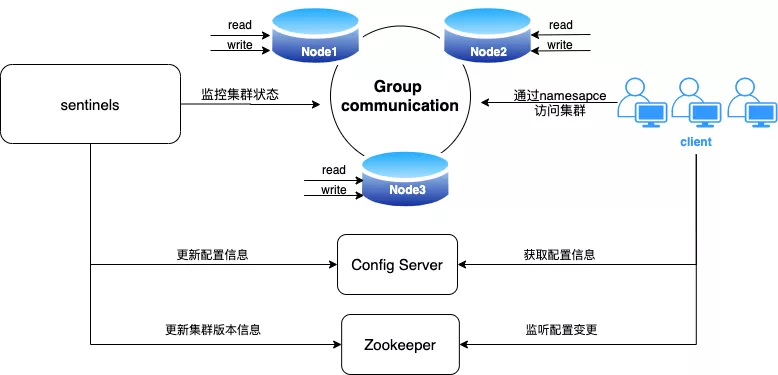
Qunar 内部使用的 PXC 集群一般为三节点,PXC 虽支持多点写入,但多点写入易导致数据冲突,会产生较大的额外开销,影响性能,所以在生产环境中,我们仍然只在一个节点写入,另外两节点提供读服务;只有在写节点切换时,会允许短暂的多点写入,以确保业务平滑的过渡到新的写节点。PXC 高可用切换不同于传统的主从切换,业务无需再忍受短暂的数据库只读和闪断。以 namespace 服务名的方式对外服务,对业务层屏蔽的数据库集群节点真实的 ip 和端口,客户端通过配置中心拿到集群的拓扑信息。
Sentinels:哨兵集群,用于监控 PXC 集群的运行状态和集群拓扑信息,类似于 Redis 的哨兵集群,解决了 MMM Monitor 单点的问题;当集群拓扑结构发生变化,哨兵会修改配置中心,进行下线故障节点,提升主节点等操作;同时修改 zookeeper 版本信息,触发客户端重建连接,重新获取集群配置信息。
Config Server:集群的配置中心,也是一套 PXC 集群,用于存储集群的 namespace 和节点信息(包括 ip,端口,读写角色,是否在线,变更信息等)。
Zookeeper:用于存储集群的版本信息,集群变更时会更改对应的版本信息并通知客户端;同时,客户端订阅 zk,主动获取变更消息。
client:去哪儿网订制的客户端,主要用于订阅 zookeeper 消息和获取配置中心信息,集群以 namespace 方式对客户端提供数据库服务,并实现了读写分离。目前已支持 java 和 python 语言。
四、Qunar 集群迁移
由于历史原因,Qunar 数据库内部还留存着较多 MMM 架构的集群,一些比较重要的“祖传”业务仍然在 MMM 上运行,背负着较大的风险,一直没出问题的,可以说是“运气好”。最初 DBA 难以推动业务进行架构迁移,一是 PXC 架构业内使用较少,没有足够的了解,因此没有信心;二是服务比较老且重要程度较高,不敢轻易变更。
经过 Qunar 多年的实践检验,PXC 架构已经被证明是一套优秀的数据库高可用解决方案。业务方开始有了一定的信任,加上今年疫情影响,我们开始“修炼内功”,借助这个机会,DBA 部门向公司推行了 MMM 架构迁移 PXC 集群计划。
如此浩大的工程,需要有一个完备的解决方案,首先要具备以下几点:
对业务友好,不停服,支持滚动发布;
支持回滚,业务发布一旦发现在 PXC 架构上运行有问题,可随时回滚;
迁移周期长,整个过程必须保证高可用;
业务发布不受时间限制,没有固定窗口期。
基于以上几点,方案一就无法满足了,因为老服务对数据库复用情况严重,没办法一次性地将地址修改完全,也不可能接受长时间的停服。第二种方案,加一层 proxy,将 proxy 的 ip、端口注册到 PXC 的配置中心,业务可以发布到 namespace,实际还是通过 proxy 访问老的集群,流量指向实际还是由 proxy 来控制,并且配置中心支持人为触发修改。
这样看来,似乎可以满足了上面的诉求。但问题也很明显,DBA 需要多维护一套 proxy,并且还要保证 proxy 的高可用。此外,还会多出很多资源,我们要迁移的 MMM 集群,共计120多套,维护成本和资源可想而知。
基于上述的迁移思想和 namespace 的特殊性,我们最终选择了原地升级的方案,丢弃了 proxy 的代理。大致流程如下:
1)首先将 MMM 的 VIP 作为 PXC 集群的访问地址,注册到配置中心和 zookeeper,提供可对外服务的 namespace。
2)通知业务发布到 PXC 的 namespace;当业务通过 namespace 访问数据库时,实际还是通过 VIP 去访问 MMM 集群节点。这个过程是支持随时回滚的,同时支持 VIP 和 namespace 的访问方式。具备高可用,对于 namespace 来说,下层是 VIP,会随着 MMM 的高可用切换,因此不存在单点故障问题。
3)观察业务流量切换情况,可通过 zk 连接进行判断。
4)业务发布完之后,逐个节点升级成 PXC 版本,部署哨兵完成完整 PXC 集群的构建,升级过程如下:
下线 MMM 的备选主节点 MASTER2,升级为 PXC 的第一个节点。
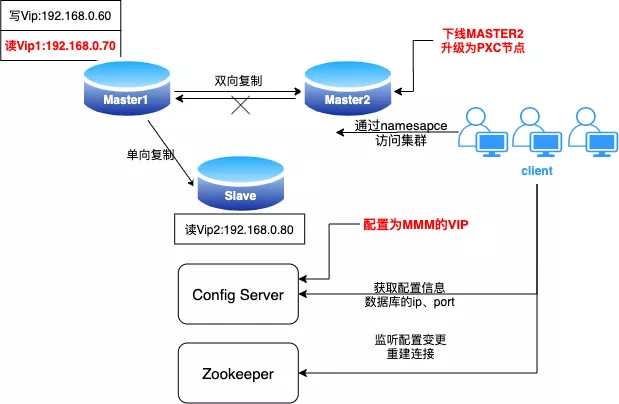
MASTER2 重新加入 MMM 集群并恢复备选主的读角色,进行读写角色切换,MASTER2 节点提升为主节点,对外提供服务(提供服务的节点为 PXC 版本,MMM 高可用依然有效,可以观察一段时间,如果业务由于 PXC 的限制出现了兼容性问题,可在这里进行读写切换,写角色切回到原先的普通版本)。
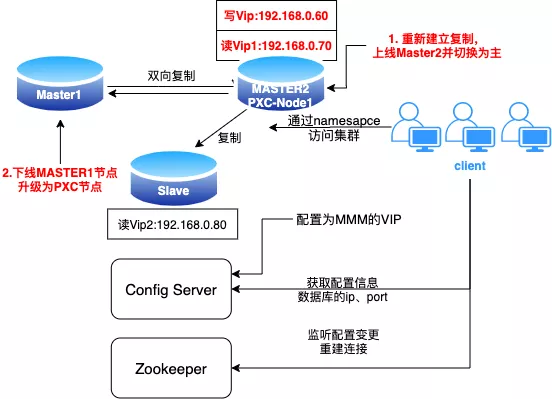
MMM 下线老的主节点 MASTER1(此时已作为备选主节点),并升级为 PXC 节点,以 MASTER2 作为 donor 组成2节点 PXC 集群(此处 MMM 集群的高可用已经被破坏,接下来的步骤需要连贯进行)。
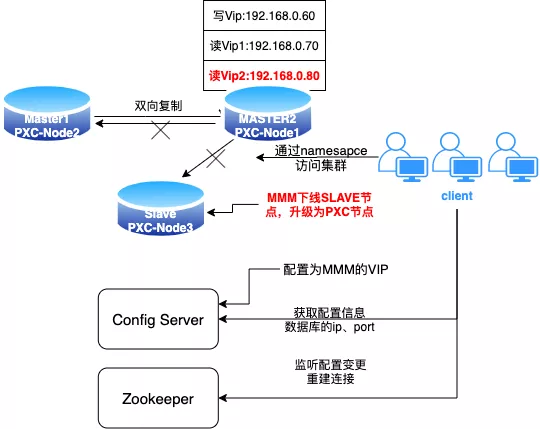
MMM 下线剩下的 SLAVE 节点,升级为 PXC 节点,加入到 MASTER1、MASTER2 组成的 PXC 集群;部署哨兵集群,修改配置中心 VIP 为实 IP,确认 VIP 没有流量访问,下线 VIP。

5)变更 zk 版本,通知客户端重连。至此,业务已经完全迁移为 PXC 架构。
6)收尾工作,检查监控、备份任务。
迁移过程需要注意的是,在逐个节点升级为 PXC 的过程中,升级到第二个节点之后,就已经破坏了 MMM 的高可用,而部署哨兵前 PXC 的高可用还未形成。所以到此环节时,需要快速而且连贯进行,我们使用自动化程序升级,确保操作的规范和高效,最大程度缩短了单点运行的时间和避免误操作。极端情况下,也能手动绑定 VIP 确保服务的可用性。
上面的迁移方案已经通过了实践的论证,并且得到开发同学的极力认可。目前去哪儿网内部已经完成超过70%的 MMM 集群升级,整个流程实现了自动化,虽然迁移周期很长,但实际上不需要太多的人为干预。
基于 MMM 原地升级 PXC 的思路,我们还可以应对很多迁移场景。现在业务有一个数据库拆分的需求:集群 A 为 MMM 集群,由于上面的 DB 很多,业务混用多,而且流量大,数据库已经不堪重负。现准备拆分一个比较重要的服务出来,对应实例里的某一个 DB;要求独立运行在新集群上,需要支持跨机房部署,且由于业务的特殊性,服务不能中断。
参考上述的迁移思路,我们来看看迁移架构图:
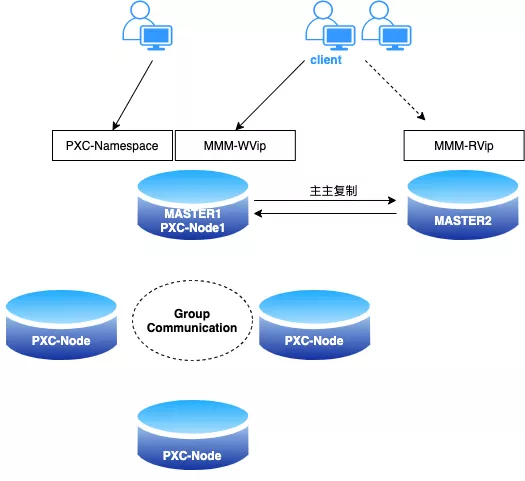
原始集群为 MMM 集群,由 MASTER1 和 MASTER2 两个节点构成,业务分别通过 WVip 和 RVip 进行访问。现在业务 A 需要迁移出去,大致操作过程如下:
MMM 集群的写节点,MASTER1 作为 PXC 集群的 donor 节点,搭建 PXC 集群(前提是 MASTER1 已经由普通的 MySQL 版本,升级为 PXC 版本)。
注册 MASTER1 的实 IP 到配置中心;此时,MASTER1 支持使用 MMM-WVIP 和 PXC 的 namespace 访问。
需要迁移的业务可以平滑的从 WVip 过渡到 namespace。
MMM 集群 offline MASTER1,将 MASTER1 从 MMM 集群脱离出来(此时 MMM 只有单点在提供服务,为确保可用性,可以提前增加从库,避免极端的情况发生)。
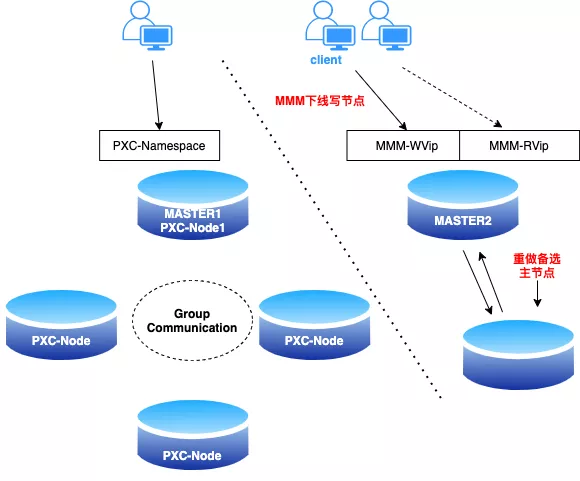
迁移出来的业务已经访问 PXC 集群,而剩下的服务仍然访问 MMM,剩下收尾工作就是把 MASTER1 从 PXC 集群中下线,恢复 MMM 的备选主节点。
五、总结
对于不同的数据库架构、业务场景,选择的迁移手段各有不同。除了同构数据库迁移外,往往还会面临各种异构数据库迁移,那么可能就需要借助第三方工具才能实现数据迁移。总而言之,没有最优秀的方案,只有最适合的方案。
本文主要阐述通过借助代理层,使得同一个数据库节点支持两种方式或两个地址访问数据库,让业务流量能够平滑的从老的连接方式过渡到新的连接方式,实现对业务最为友好的迁移方案。基于这种思想,我们可以应对多种迁移场景,不需要停服割接,并且将开发和 DBA 的工作解藕,很大程度上提升了工作效率。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721