
许珣,新炬网络数据库运维专家,OCP。拥有五年的Oracle数据库运维经验,精通OGG技术相关应用。
一、需求来源
自从阿里喊出“去IOE”的口号,又经过2013年棱镜门事件,政府也将数据安全视为重中之重,逐渐在加强管控软、硬件的国产化之路。好吧,这跟我们今天要说的数据分发有什么关系呢?
众所周知,“去IOE”中的I和E相对比较容易被替代,而Oracle的替代则是一条漫长、艰辛的摸索之路。某省运营商的数据分发需求也是在此大背景下不得不选择的一条转型之路。在此之前,集团数据下发是通过小型机的存储底层复制技术,将整个生产库每天同步到异机启动,再通过创建一系列的对象和授权,从而将生产库的数据下发给地市查询使用。小型机停止使用之后,X86环境无法实现,则有了通过OGG来实现多源端数据库的数据集中分发方式。
二、场景构架

如图所示,源端有多个数据库,基于存储、网络的限制,无法做到打通所有源端到目标端的网络,源端也无法保证每个数据库服务器都能有足够大的容量来存放队列文件。
因此我们设立了一个大容量的分发中心,用于统一网络传输路径,并集中管理OGG产生的队列文件,使之能保存较长时间,并将源端的队列文件统一中转后传递至目标端,最后在目标端应用,从而实现数据的多源端到统一目标端的分发。
三、详情介绍
虽然知道读者们基本都是运维界的老鸟,不过也可能有不熟悉的朋友,下面介绍一下OGG的基本工作原理。以下摘自网络:
GoldenGate软件是一种基于日志的结构化数据复制软件,它通过解析源数据库在线日志或归档日志获得数据的增删改变化,再将这些变化应用到目标数据库,实现源数据库与目标数据库实时同步。
GoldenGate软件可以在异构的IT基础结构(包括几乎所有常用操作系统平台和数据库平台)之间实现大量数据亚秒一级的实时复制,其复制过程简图如下:
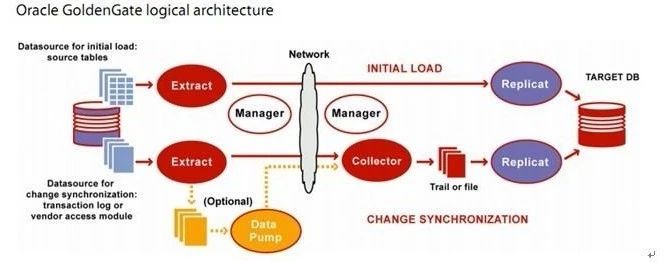
如上图所示,GoldenGate的数据复制过程如下:
利用捕捉进程(Capture Process)在源系统端读取Online Redo Log或Archive Log,然后进行解析,只提取其中数据的变化如增、删、改操作,并将相关信息转换为GoldenGate自定义的中间格式存放在队列文件(trail)中。
再利用传送进程将队列文件通过TCP/IP传送到目标系统。捕捉进程在每次读完log中的数据变化并在数据传送到目标系统后,会写检查点(checkpoint),记录当前完成捕捉的log位置,检查点的存在可以使捕捉进程在中止并恢复后可从检查点位置继续复制。
说白了OGG就是读取日志,然后转换成特定格式的文件,最后在目标端回放源端的操作,支持类似“断点续传”。
目前我们这边源端的数据库版本较多,以11.2.0.4的版本为主,分发中心OGG软件版本为当时的最新版12.2。整体环境已经运行了2年多,总体来说,运行较为平稳(这句话是假的,其实是踩坑踩过来的),现在已完全替代之前底层复制的方式来供各个地市查询数据。相比于底层复制技术,OGG无法做到像前者那样,将整个库都给复制过来,并且能保证数据的准确性;但OGG也有其优势,就是时效性以及对主库极小的压力。
Oracle数据库的数据类型那么多,OGG只能支持其中常用的一部分,虽然这么说看上去确实有兼容性方面的问题,不过我相信实际应用中,这“常用的一部分”数据类型已经基本覆盖了OLTP系统应用的需要,所以不需要太担心,如果真的有,可以尝试一部分特殊表用特殊方式来处理。
在时效性方面,OGG通常情况下不会让人觉得有什么延迟,几乎都是秒级或者官方吹牛的亚秒级同步。不过这种说法也仅限于通常情况,在某省运营商每个月出账后的时间,OGG的部分复制进程同步延迟经常达到十几个小时,这还是在目标端拆分了大量复制进程以后的情况。
毕竟不是所有的表都有主键,虽然Oracle宣称没有主键也可以,会将所有列合起来当成唯一约束或者主键,但实际应用中大批量Delete操作的性能问题确实令人难以忍受,而且一旦存在重复行的情况,OGG对于Update、Delete操作的同步可能还会有随机的不确定性(目前来说数据的准确性还是比较能保证)。
不过其实想想也正常,出账期间,物理备库基于数据块的同步都有延迟,更别说基于SQL同步的OGG了,再高的并行回放,依然不能与主库的高并发写相提并论。
由于OGG的抽取进程所做的仅是读取日志,并生成相应的队列文件,可能还有一部分写BR文件的操作,所以只需要很少的IO即可完成,这点IO对数据库的性能影响微乎及微。而存储底层复制的情况下,需要在2-3小时内完成20~30T存储的复制,这对网络、IO的压力可想而知。
不过虽然说OGG对IO的需求较少,但也不代表完全没有需求,本地环境中,一部分源端是在物理备库上使用ALO(archived log only)模式抽取,并且关闭了BR功能,否则每晚日账期间,OGG进程必定僵死,Oracle原厂也无法解释清楚问题原因。
我认为主要还是OGG软件对备库的支持不好,同样条件下,主库就没有这样的问题。除了僵死问题,备库抽取所能支持的抽取模式也仅有经典模式,这在Exadata一体机上是致命问题,所以除非逼不得已,不建议在备库抽取。
前面吐槽了这么多,那么实际应用反馈如何呢?答案是基本满足地市查询需求,仅部分表需特殊处理,偶尔有需要新增同步的表。
源端的所有数据库加起来,少说有10W张表,其中大部分为历史数据表,数据基本不变,主要查询的基础配置表和年月表都能正常同步,仅部分表因为应用会有频繁的DDL操作导致无法正常同步。对于这类无法正常同步的表,我们通过自动化的expdp/impdp脚本,每天将这部分表同步到目标端即可。
因为地市查询的具体需求也不要求这类表做到实时同步,之前底层存储复制的方式,数据也有一天的延迟,所以完全可以满足需求。如果有新增表同步的需求,也会有标准化的操作流程,对已同步的表不会造成大的影响。
对于SQL的性能,我们也做了一部分测试,大部分情况下的查询,因为目标端存储采用了闪存,查询速度都会比原有减配的小型机环境更快,但也有部分复杂SQL的执行计划变更,查询速度变慢,这属于性能优化的范畴了,在此不做讨论。
总之,OGG并不完美,但采用什么构架、技术也总是在现有的资源、环境、需求下做的妥协选择,至少做到满足当前需求,它还是做到了。
四、问题解决
OGG软件是向下兼容的,但实际使用过程中,我们发现在源端-中转端-目标端的传递链路上,需要源端的软件版本等于或低于中转端的版本,否则一旦源端的OGG抽取或投递进程状态有变更,就会导致中转端的投递进程abend,并且重启无法解决,需手工生成新的队列文件。
这一问题有待后续升级构架方案尝试解决,但目前我们只能采取OGG版本一致的策略。但这也带来了新的问题,那就是源端总是会有数据库迁移、升级的吧?那数据库上了18C、19C,OGG也必须使用新版本才能支持,这怎么办呢?
首当其冲想到的是中转端随之升级OGG版本,那中转端升级,目标端肯定也要升级啊,但是这需要充分的升级测试,目前来说,还没有十足的把握来保证升级成功,一旦升级失败,这上百T数据量的重新初始化真的够我们喝好几壶了……其实源端已经有了一套数据库上了18C,当前只能采取绕过中转端的方式,无奈之举。
谢天谢地,当前我们除了碰到压缩表不支持之外,几乎没有碰到其他类型的表不支持问题,而压缩表也基本都是很老的历史表,几乎无变更。所以对我们来说这点倒是不头疼。
BR的设计理念确实很好,可以防止OGG进程在异常后重复读取日志,并且仅需很小的IO和存储。奈何备库抽取的条件下,开了BR就会在段时间内事务量巨大的情况下导致进程僵死,遂在备库上均关闭BR,主库抽取时开启。
OGG其实是可以支持DDL复制的,但经典抽取模式需要开启全库级别的触发器,这对于生产库的性能影响肉眼可见,肯定是不建议使用的。目前我们碰到最多的是源端的表MOVE和rename,这也是前文所说的部分表无法正常同步的主要原因。集成模式倒是可以在不部署触发器的情况下同步DDL操作,这也是后续我们升级时重点测试项目之一。

正常情况下,OGG进程仅需很小的内存,但我们也碰到在一个服务器上,OGG抽取进程占用了上限的64G内存,导致服务器内存不足,我们只好加上限制内存的参数,防止OGG进程内存占用过大。
CACHEMGR CACHESIZE 16G
前文有提到,OGG软件对于备库的支持不好,所以如果抽取进程部署在备库,最好让抽取进程仅从归档抽取,就是下面这个参数:
TRANLOGOPTIONS ALTARCHIVELOGDEST
随之带来的问题就是,数据同步的时间永远会差一个归档的时间,就是必须得等源端的redo log写入归档并且传输到备库了,OGG进程才能开始读取。不过我想在时效性和可用性之间,应该都会选择可用性吧。
前面还提到过,每月出账时间,可能会有十几个小时的延迟,就算是物理备库,也经常会出现几个小时的延迟。主库可以配置归档的备份删除策略,让归档未在备库应用时不被删除,但OGG不行啊。所以我们改造了NBU的备份脚本,每次归档备份时,读取OGG进程当前读取到的归档sequence号,仅备份删除此sequence号之前的日志。
实际运维中,遇到的问题不仅仅是这些,篇幅问题,就不一一列举了,欢迎感兴趣的朋友可以在评论区留言交流OGG运维中的坑。
五、升级方向
虽然目前的构架、方案可以满足应用的需要,但技术更新、版本迭代不可避免,随着数据库版本的不断升级,当前环境势必会在日后会不满足需求,需要我们提供更好,更完善,更便于维护的方案。
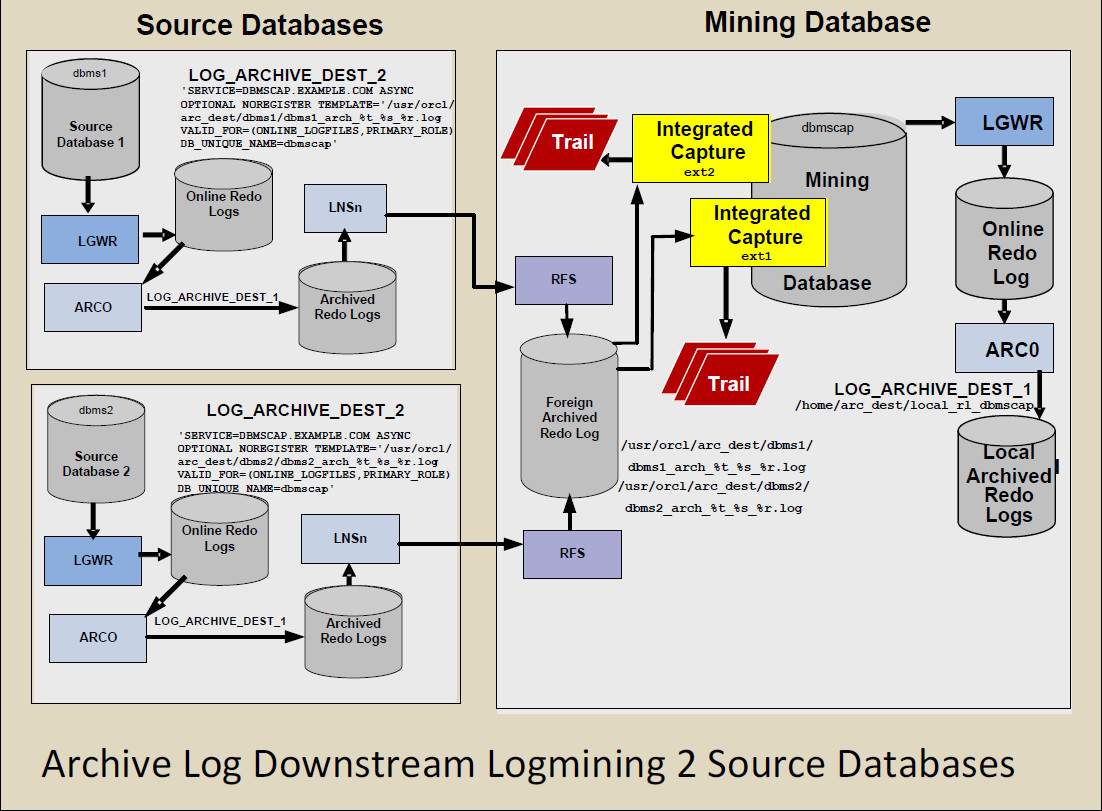
目前我们思考的升级方式是使用OGG Integrated Mode(downstream方式),建立一个mining database统一接收多源端的归档日志,并创建相对应的抽取进程,使之获得与在主库部署的集成模式(Integrated Mode)抽取进程一样的支持。
同时,mining database可以创建RAC,避免单点故障。这种构架还能解决一个非常棘手的问题,那就是源端的主备库切换。在现有构架中,源端一旦发生主备库切换,就有可能带来数据不一致的风险,而且必须要人工干预,有可能还会需要对部分表做重新初始化,这都是额外的工作量。
而使用downstream方式则不会有此问题,因为mining database只是接收源端的归档,至于抽取进程里配置的连接主库的TNS问题,通过域名就可以解决。我猜想最多在发生主备切换时,重启一下mining database上的抽取进程就可以了,那就高枕无忧了!当然,有待我们后续的测试验证,这点我也很期待……
好了,有了新的构架,我们还是绕不开源端数据库版本升级的问题,但至少我们把需要升级的服务器从“N源端+1中转+1目标端”减少为了“1 mining database+1目标端”,至少风险点看上去是减少了。但具体的实现,我们还需大量的测试验证,比如如果mining database的数据库版本高于源端,OGG还能不能正常工作,这就是测试的重中之重。
最后,放一张官方的构架图:
六、心得体会
在做这个项目的过程当中,虽然碰到过不少莫名其妙的坑,但也确实收获了很多经验教训,让我对OGG的实施运维有了很多新的认识。但是技术总是会不断更新,我们总得不断尝试,才能有所得,与诸君共勉。
《All in Cloud 时代,下一代云原生数据库技术与趋势》阿里巴巴集团副总裁/达摩院首席数据库科学家 李飞飞(飞刀)
《AI和云原生时代的数据库进化之路》腾讯数据库产品中心总经理 林晓斌(丁奇)
《ICBC的MySQL探索之路》工商银行软件开发中心 魏亚东
《金融行业MySQL高可用实践》爱可生技术总监 明溪源
《民生银行在SQL审核方面的探索和实践》民生银行 资深数据库专家 李宁宁
《OceanBase分布式数据库在西安银行的落地和实践》蚂蚁金服P9资深专家/OceanBase核心负责人 蒋志勇









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721