
本文根据dbaplus社群第190期线上分享整理而成,文末还有好书送哦~
黄伟俊
百度数据库高级研发工程师
百度数据团队数据库高级研发工程师,入职后负责关系型数据库MySQL调优、SQL Server云产品建设。
目前主要负责CockroachDB的内核研发及高可用方案设计和实施。
具有丰富的数据库调优和平台化建设经验。
大家好,我是来自百度的高级研发工程师黄伟俊,很荣幸代表我们团队受邀参加dbaplus社群的线上分享。我自从2015年加入百度以来一直从事数据库研发工作,目前主要focus在CockroachDB内核研发和平台化建设。
从2015年开始我们团队就已经在关注NewSQL技术及CockroachDB项目。当时CockroachDB的项目是开源项目里面最受关注的NewSQL项目之一,从那时开始我们就积极投入到CockroachDB开源社区。今天我将分享的主题是「CockroachDB在百度的实践」,主要是围绕GEO-Partitioning功能可以解决什么场景进行实践演示和展开。
这次分享会从五个部分逐步介绍为什么选择Partitioning功能,Partitioning功能的实现原理,这个功能究竟能解决什么问题,有什么好处。希望能让大家对Partitioning功能有更直观、更全面的认识。
一、CockroachDB特性
自2017年5月CockroachDB release 1.0以来,CockroachDB迭代了5个大版本。从1.x版本支持分布式查询,Online schema change,滚动升级,import,dump到2.x版本支持GEO-Partitioning,备份恢复,支持多种数据类型,CBO,CDC再到更新版本号之后的19.1支持基于CBO的优化,静态加密等。
个人觉得2.x是CockroachDB变化最大的版本,2.x相比1.x的主要变化除了在性能上进一步优化,同时新引入的几个重要的特性,如GEO-Partitioning、支持备份恢复、CDC、Read From Follower等。
GEO Partitioning作为一个非常核心且有特色的功能,除了给CockroachDB提供全球化部署,还为高可用、冷热数据分离等场景提供更多的解决方案。
二、Partitioning介绍
Partitioning功能顾名思义就是表分区功能,CockroachDB允许用户定义表分区,从而达到行级别的数据分布控制,如存储数据的方式和位置。
就是如下表的数据,一个学生信息的表,有5列,分表是id主键、name名字、email、city城市、毕业时间。现在我们有个需求,由于某些原因,我们想要把学生信息切分成三个部分,分别存到不同系统上面。

没有partitioning之前,简单的想法可能是我们建三个表,1,2,3,每个表分表存到其中一个集群,这样分开管理。但是这样就有不好的地方,就是增加了运维的难度,而且不能保证数据的唯一性了,这样无形给业务层增加了很多工作量。
但是在CockroachDB就不需要这么麻烦,总所周知CockroachDB是分布式数据库,数据都是以一个range数据块为散列存储的,我们可以把9个节点的集群,每3个节点作为一个分组,从上到下我们称为1,2,3集群把,利用patitioning功能将小于2000的分布到1分组,大于2018小于4138的放在2分组,大于4138的放在3集群,这样对于业务层,表还是一个表,但是数据已经按照要求分开存储了,这无形中给业务层带来非常大的便利。
那Partitioning是怎么把在原来分散的数据自动迁移到指定的节点呢?
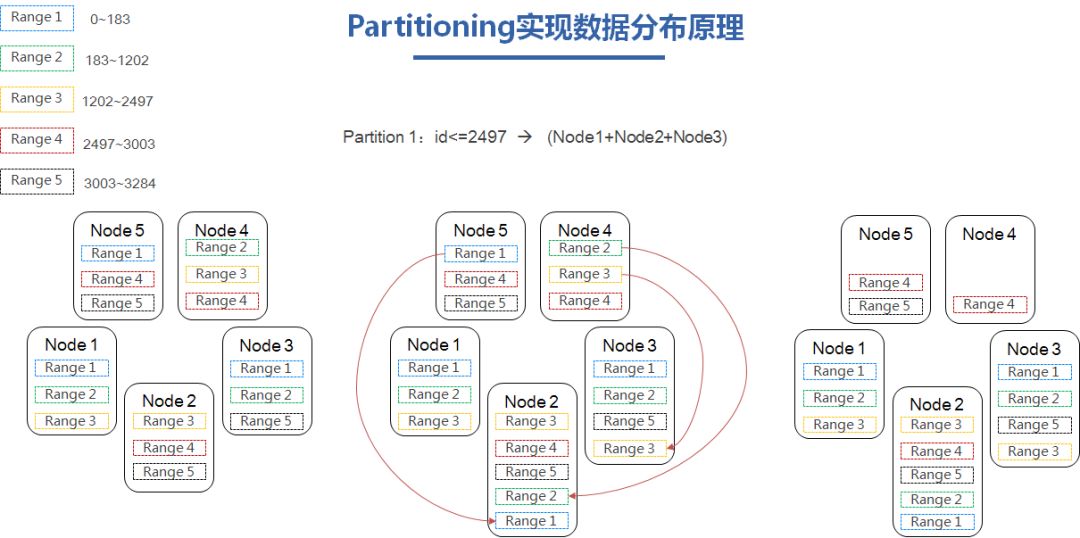
以id<=2497这些数据的迁移作为例子,我们看左上角,range1-5,range右边的范围代表range里面包含的id范围,而下面Node1-5代表5个节点的集群,而range1-5已3副本均匀分布在5个节点上面。
当我们需要配置partitioning让id小于等于2497的数据迁移到Node1,2,3上面时,我们可以看需要迁移的range是1,2,3,而不在Node1,2,3上面的range,有Node 5 上面的range 1,Node 4 上面的range 2,3。
基于三副本高可用的原则,相同的range不会部署在同一个node上面,range 1,2需要迁移到Node2,range 3需要迁移到Node 3。他们只需要在对应的节点创建一个副本,然后进行raft同步,最后删除掉Node 4,5上面的range,这样就基于partitioning实现了数据的动态迁移。效果如第三幅图。
这数据迁移的速度,是可以自定义的,而且对应用来说是透明的,这个非常友好。
其实传统数据库也有patitioning的功能,那CockroachDB的patitioning功能对比传统的实现有什么区别呢?
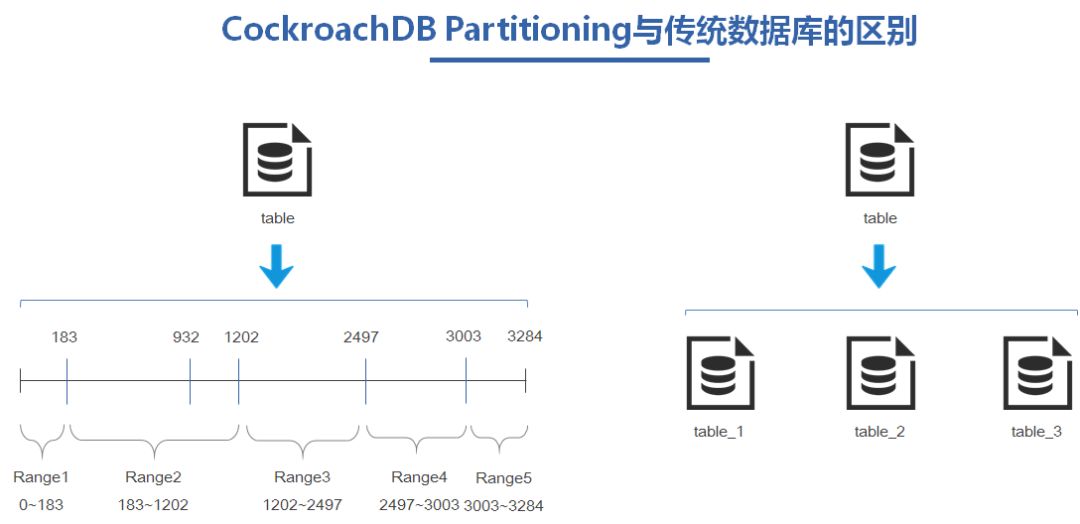
大部分传统数据实现的partitioning底层实际是通过创建多个实际的物理子表实现数据分区,创建完分区表之后按照分区键,数据写到对应的partitioning分区,这样就实现了对数据做分区了。
而CockroachDB的partitioning实现的是对数据的动态分布,没有所谓的子表的概念,通过定向的rebalance让数据按照partitioning的要求迁移到指定的节点。
对于CockroachDB这种实现的方式可以给用户带来什么优劣势呢?

我们先说优势把:
代价少:分区的变更只涉及元数据的修改,分区变更之后,数据迁移交给rebalance去处理,平滑对数据迁移,无需担心数据重新导入。
操作简单:只需要一个alter语句就可以对分区做调整变更。
灵活性高:由于CockroachDB每个节点有地理位置信息,存储介质信息,我们除了对数据做各个维度的分区,也可以指定分布到各个节点,存储介质。
这种便利性同时也带来一些缺陷。
由于实际还是一个总表,应用不可能做到对当个分区自定义的表结构的变更。
CockroachDB这种对数据分区,只是利用前缀匹配的方法做分区,所以分区键只能是主键,不能随意设置其他字段分区键。
同时,也不能对单个分区做导入导出的操作。
不过总的来说,分区表调整的便利性和对集群的负载相比于劣势来说还是很有优势的。
三、GEO Partitioning应用实践
知道CockroachDB的Partitioning是什么和它的实现原理,估计大家已经有了一种整体的概念了,下面我们会通过一个实际的案例背景看看Partitioning功能能解决用户什么样的场景和痛点问题。
业务方给我们提出的需求是这样的,数据规模接近PB,需要对三个月以前的数据进行归档,最近3个月的数据会进行增删改查,成本比较敏感,SQL接口。
我们可以算一下,假设一台服务器上2T的SSD,要存下1PB的数据,就需要500多台机器,对业务方来说是不可接受的,如果为成本考虑单纯使用SATA HDD盘可以满足存储要求,但是性能又达不到。
这其实就是一个非常之典型的冷热数据分离的场景。
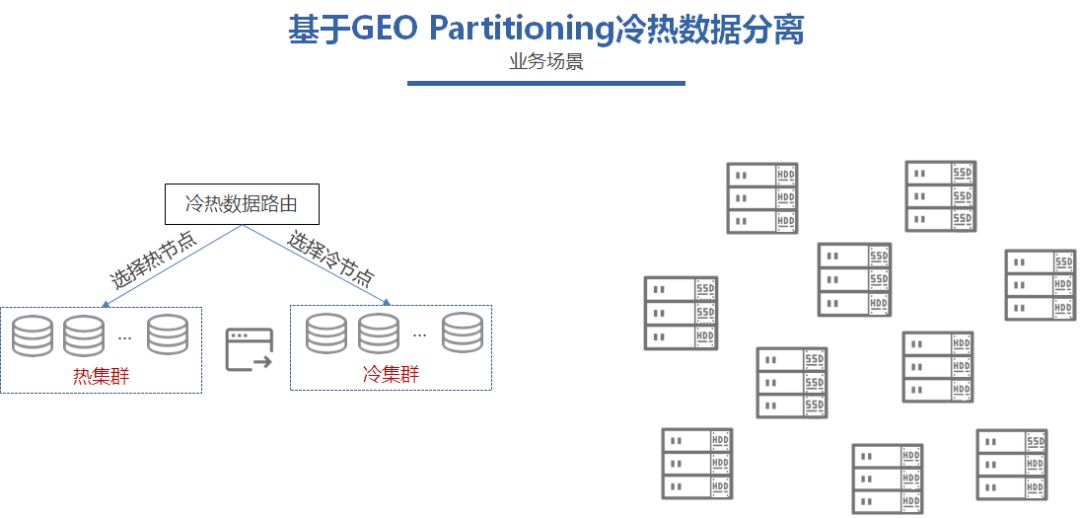
热数据就是最近3个月的数据需要进行频繁的增删改查,对时延非常敏感,对性能需求比较高,但是这部分数据又是占小部分的。
而业务的冷数据,就是超过3个月数据,这些数据不会做频繁的增删改查,只是用于归档,是实时性要求非常低。但是这部分数据会却是需要占用大量的存储空间。
热数据性能需求大,存储需求少,冷数据性能需求少,存储需求大。
面对这样的场景,需要在成本和性能之间提供一个最优的方案。根据用户数据存在冷热之分的特征,我们可以使用SSD和SATA HDD混合部署,利用CockroachDB的GEO-Partitioning特性,对用户数据基于时间维度做水平分区,三个月以内的数据放在SSD区域,三个月以前的归档到SATA HDD区域,这样可以有效地利用单台服务器计算和存储的资源,不至于二选一,造成资源浪费。
方案知道了,下面我会继续利用一个学生档案的例子介绍怎么操作配置实施这样的案例。
对于上面描述的场景,现在我们需要部署最简单的3个节点集群,raft协议决定了CockroachDB集群最少节点数为3个,Node1,Node2,Node3,命令如下:

其中有两个关键的配置参数,
1)Locality,这个表明了节点的所在的数据中心的位置,名字可以按照业务需求自定义,没有规定,除了可以配置region还可以配置,datacenter数据中心,rack机架信息。这里为了方便大家理解,只配置了region和databcenter信息。
目前3个节点都是出于同一个region。
2)store配置参数,就是每个节点存储的数据目录的位置,单个节点可以配置多个store,每个store参数可以标志该磁盘的熟悉,目前假设我们拥有的服务器都是一块ssd,一块hdd盘。
按照命令,我们就可以拉起三个节点,每个节点都处于DC1区域,混部使用了ssd和hdd两种类型的磁盘类型用户提供服务。
初始化好集群之后,按照需求,我们创建对应的DB,以2019-07-01年为分界线,划分已经毕业的学生资料和没有毕业的学生资料。

表结构字段还是之前的类型id主键,name名字,email,city城市,毕业时间,不同的是这次增加了Partitioning的信息,细心的同学可能会发现,主键已经改为以毕业时间+id,不是只有id作为主键,因为之前提到过,
Partitioning的key必须作为主键存储。我们如果要对毕业时间作为分区键,毕业时间必须是主键的前缀。
这里我们设置了两个分区, 2019-7-01以前毕业的学生数据命名为graduated分区,相反2019-7-01以后未毕业的学生数据命名为current分区。
现在我们搭建好集群,分区也配置好了,下面需要配置partitioning的规则了,让刚刚划分好的分区按照规则存储到指定的地方。

具体的语法是使用ALTER PARTITION … CONFIGURE ZONE创建zone的规则,应用到partition上面
这里我们可以看到第一个alter partitioning的语法,就是对graduated这个分区增加约束,上面的数据只存放到hdd的磁盘上面,第二个alter partitioning的语法就是对current分区增加约束,让这些数据只存储在ssd的磁盘上面。如果没有这个约束,即使配置了partition,数据会按照默认的规则,均匀分布在所有的节点。
按照这样配置之后,我们就实现了我们的方案,在同一个集群里面充分利用所有高性能和高存储磁盘,实现冷热数据分离,应用层不需要考虑数据迁移,也不需要考虑维护冷热集群的入口。由于CockroachDB集群所有节点的平等,无中心节点的特性,应用对每个节点都能实现对冷热数据的自由访问。

与此同时,如果需要调整冷热数据的接线,只要做一次alter table partitioning的操作就可以实现调整。在容量不足,或者性能不足,需要对ssd或者hdd做扩容也是极其简单。数据的迁移和调整全部交给rebalance自动负载均衡进行。
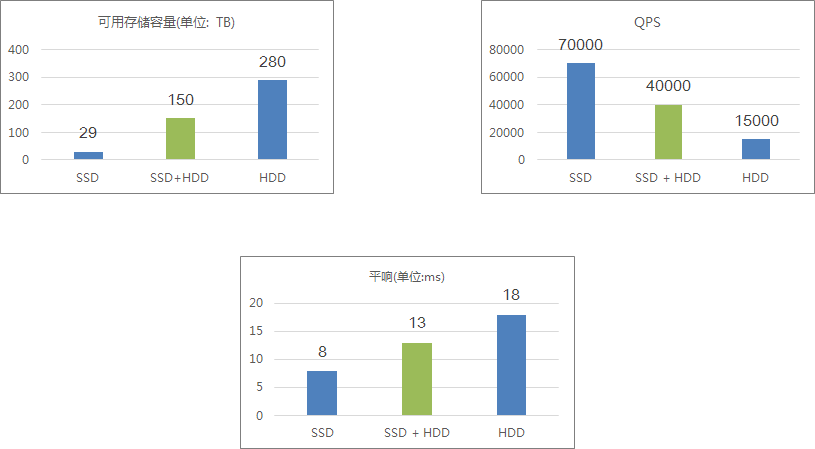
面对这样的部署方案,我们可以从直方图可以看出,面对纯ssd的高性能,高成本。纯hdd低性能,低成本。混合部署方案可以既能达到纯ssd一半qps,也能满足纯ssd一半的存储。而且这比例是可以动态配置的,正常的冷热数据的流量都遵循2,8原则,20%的数据承载了80%的流量,按照对应的配置,可以节省更多的资源。
到这里,其实混部冷热数据分离方案,只能满足业务的基本需求,对于更大型,对数据和集群可靠性要求更高的业务来说,单地域部署是不可能满足需求的。
一个原因是业务的的覆盖方位有可能是多地域的,华北,华南,华东。如果数据中心只有单地域,那么会造成跨地域的访问时延。
第二个原因是如果单地域部署有可能会面临单机房的故障,造成不可恢复的情况。
面对这样的情况,下面我们再把上面的单数据中心的方案再进行拓展,部署一个3地多中心的高可用方案。
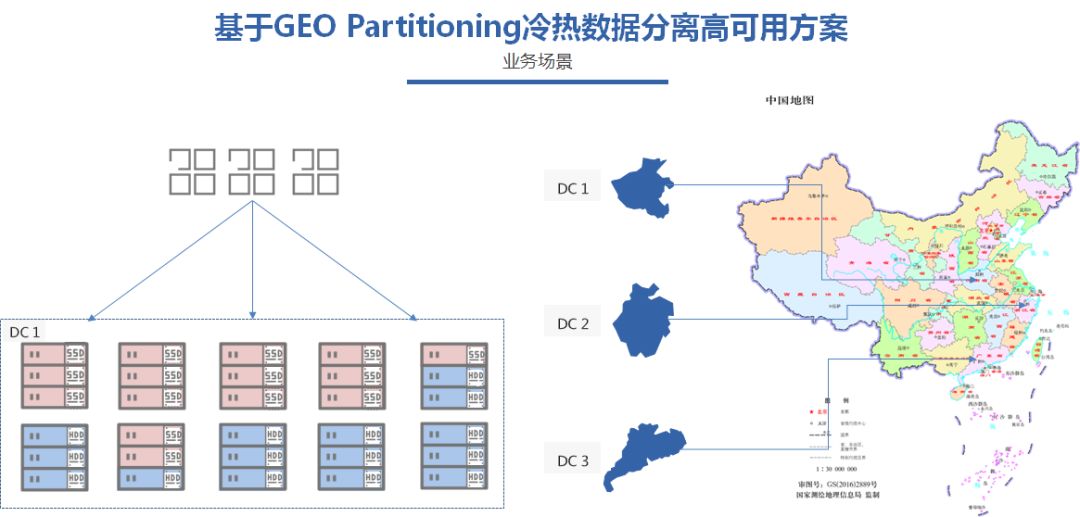
目的有三个:
满足各地的应用就近访问本地的数据,保持低延时;
避免单点数据中心的故障影响数据库服务的可用性;
减少运维的压力,统一一个集群管理所有数据。
要实现上面的的两个目的,优先需要扩容其他两地的服务节点,DC 2 扩容3个节点,Node 4-node6,分布在同地域的两个数据中心,sh和sz,实现同城双机房容灾

而同理,Node7-9,部署在DC 3的两个数据中心,gz和dg,同样实现了同城双机房容灾。
每个节点同样按照store的磁盘介质区分ssd,hdd的属性。这6个节点通过join参数可以动态扩容到原来的集群,形成一个3地多中心的分布式数据库集群。

完成集群的扩容之后,我们需要进一步对分区表的partition分区做调整,把原来只有单地域的时间分区扩展为地域加时间的分区。因此我们调整主键为city+毕业时间作为前缀,Partitioning已city划分为north,south,和east三个分区,再在每个分区里面划分已经毕业和当前的分区。
这样就达到了每个地域分区按照时间划分为已经毕业和没有毕业的数据。

完成了分区表的调整之后,我们需要调整的就是zone configure的配置参数,这次调整除了磁盘介质的约束,还需要增加地域的约束和每个地域副本的约束。分别就是+region=DC1,2,3。每个region后面分布2副本数据。
这里我们可以把通一个地域2副本更细化为两个数据中心各一个副本,这样就可以更可靠。
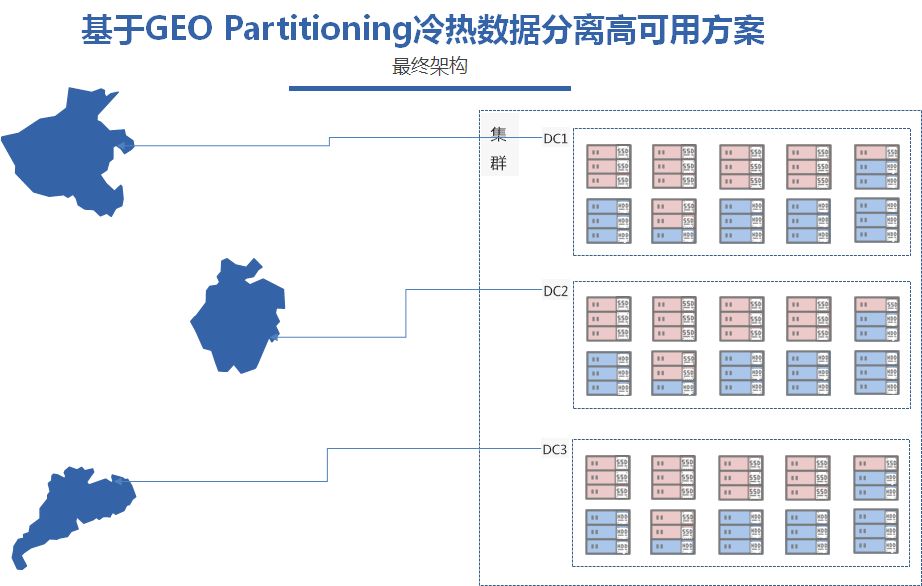
这样调整完之后,我们就可以实现我们冷热数据分离的高可用部署方案,3地多中心,各地域冷热数据分离,数据打通,同地域双机房,应用数据就近访问。
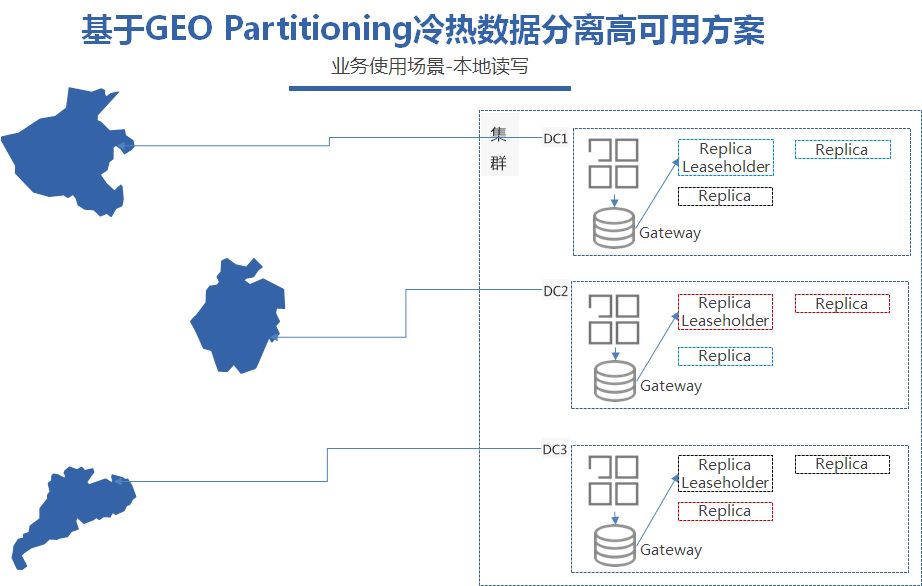
我们可以看到,当DC1的应用需要查询本地最近的学生数据的时候,CockroachDB会把请求的SQL路由到最近的Leaseholder上面,我们可以理解为提供读写查询的leader副本。
而当应用需要写入数据的时候,只需要完成大部分副本,三副本情况下的两个副本写成功之后,就可以返回写成功,DC2的副本异步同步就好了,这样就避免了跨地域部署下的写入延时。同时也能做到高可用,DC2和DC3 同理也是这样。
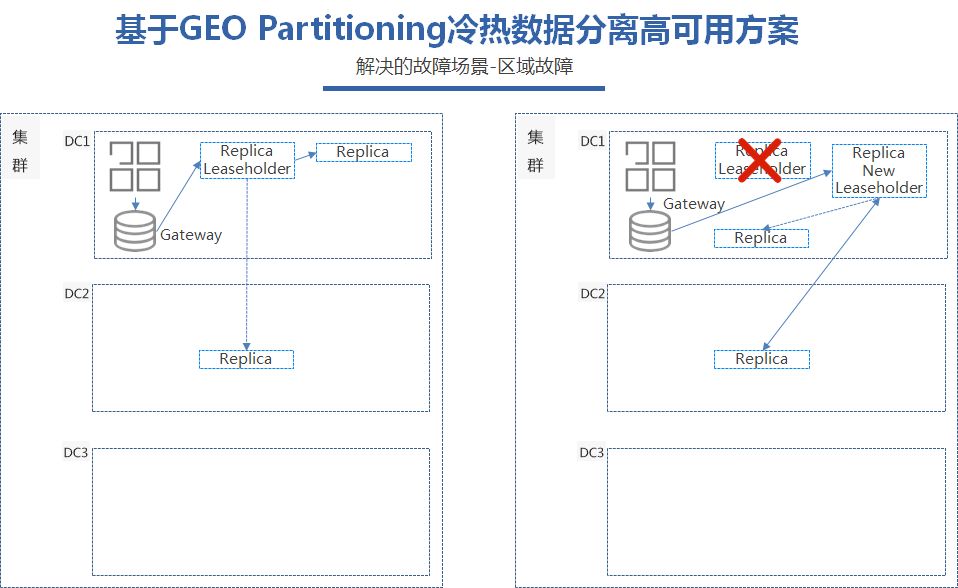
我们知道CockroachDB的raft协议的强一致性,在大部分副本存在的情况下是可以保证不影响服务的。
通过这样部署,CockroachDB的集群可以容忍单个地域一个数据中心的故障,当DC 1其中一个数据中心故障之后,还存活的两个副本可以继续提供服务,在第三个副本恢复之前,写入会出现跨地域的时延,但是可以保证集群服务的可用性。
同理,当DC2的其中一个数据中心的故障,对于DC1,和DC3两个地域来说,完全是没有影响的。
四、总结
总结一下, CockroachDB利用Partitioning的特性可以非常方便地为业务解决冷热数据分离场景下,资源利用不高,调整不灵活,数据迁移麻烦等问题,而且还可以按照业务的部署需求,带来全国性,或者全球范围的数据库服务。减少运维的成本和机器的成本,配合各厂商提供的云服务,更能拜托资源的限制,快速实现上线部署和动态扩缩容。
但是了解CockroachDB和细心的同学可能会发现Partitioning功能虽然能通过部署满足业务对高可用的需求,并且实现应用层的就近访问,但是3副本里面能提供查询和写入的只有leaseholder节点,对热数据的复杂查询势必会影响leaseholder的性能。那要怎么解决这些问题呢?其实目前有两种解决方案:
19.1已经提供的read from follower,就是除了leaseholder可以提供读服务之外,follower同样分摊leaseholder的读请求,减低他的压力;
read from learner,learner 角色相比于follower角色,他只会异步同步数据,不参与投票,大家都知道raft为了保证数据的强一致性,需要等待大部分节点写入才能成功。Learner不包含在这个大部分里面,因此不会增加同步多副本的耗时。从learner上面读取可以很好地分担读的流量,但是怎么保证强一致性是需要面临的问题。目前还在探索。
Q & A
Q1:现在有开源的在线物理备份工具吗?
A1:CockroachDB目前可以通过dump方式做全量备份,要做增量备份的话目前还没有开源工具。
Q2:一般在企业内多少数据量考虑上CockroachDB?需要到PB级吗?
A2:其实只要业务上TB级别,或者单表达到数百GB都可以考虑。
直播回放
https://m.qlchat.com/topic/details?topicId=2000005065911472
彩蛋来了
在本文微信订阅号(dbaplus)评论区留下足以引起共鸣的真知灼见,小编将在本文发布后的隔天中午12点根据留言精彩程度选出1位幸运读者,送出以下好书一本~
注:同一月份里,已获赠者将不可重复拿书。

特别鸣谢博文视点为活动提供图书赞助。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721