
鉴于网上类似的文章较少,并且这种问题往往在代码中比较隐蔽,较难轻易发现,所以在这里做个分享。如果碰巧对其他做类似工作的人有所启发,本人将非常高兴。
一、背景介绍
这个客户多年来一直使用我司的数据库,目前打算升级到更高版本,但在对数据压缩功能的测试中发现,在某种情况下,在压缩过的数据表上做全表扫描(table scan)所花费的时间会随着并发的全表扫描任务数的增多而显著增加,而未经压缩过的数据表则没有这种现象。
数据压缩是我们团队多年前开发的一个功能,之前做过大量的代码优化,性能相对比较稳定,实在不应该会有这样的问题,这也因此引起了我极大的兴趣。
了解数据库的人都知道,影响数据库的性能的因素较多,比如服务器的硬件配置,数据库的参数设置,数据的磁盘分布等,当然,也不排除数据库自身代码的问题,不太容易一下定位到具体的原因。
一般情况下,如果能通过数据库调优解决问题,就没必要花费大量时间去调查数据库源代码,所以,在整个问题的调查研究过程中,我的原则是,先易后难,大胆猜想,逐项排除。
二、调查思路
客户属于金融行业,对数据安全有严格的规定,根本不可能让我访问他们的数据库系统去做分析,唯一的方法就是,先本地重现问题,然后调试。本地重现是个消耗体力和想象力的过程,索性经过很多次的沟通和尝试,终于重现了类似的现象。
1、数据库使用问题 vs 数据库代码问题
在一开始确定这个问题是非常必要的,它将决定接下来所花费的时间和精力的大小。
跟客户做了些沟通,发现他们对数据库没有比较深入的了解,所以,首先怀疑的是,有没有可能他们的数据库系统中的某些配置参数设置不合理,从而影响性能呢?
很快拿到了客户的数据库配置文件,逐一分析,并结合本地实验,发现并无明显的问题,唯一的一个问题是,某个跟数据压缩统计信息相关的配置参数打开了,这个参数主要是在分析问题的时候使用的,生产环境是不建议打开的,立即关闭了这个配置参数,在本地环境中重新测试了一下,发现性能有些改善。
立即建议客户也做同样的尝试,很快得到反馈,性能有所提升,但还未达到他们的预期。
看样子事情没那么简单,接下来开始倾向于认为,可能数据库代码哪里出了问题。
2、锁竞争 (lock contention)
在支持高并发的数据库系统中,为了同步不同任务对一些关键资源的访问,使用锁是一种常见的方式,如spinlock,mutex等,但是,一旦发生严重的锁竞争,将会极大影响数据库系统的性能。
虽然近些年lockless的呼声很高,但是一个数据库系统要完全做到lockless还是较难的,一般的策略是,对某些关键的,容易引起竞争的结构或者模块采用lockless的方式。所以,检查锁竞争是下一步的重点。
我司的这款数据库虽然全球市场份额不大,但也是深耕该行业的老品牌,在国外的金融领域有口皆碑,在无数次市场检验的过程中,为了更好地分析各种问题,工程师们在系统中加入了关键信息的统计功能。
通过分析一些系统关键资源的统计信息,并未发现明显的锁竞争,或者资源竞争,尤其是跟数据压缩相关的,所以,这个可能的原因排除掉。
3、CPU cache相关的问题
前两个可能都排除了,现在需要重新审视下客户的环境,寻找下一个可能的方向。
客户的数据库服务器有着不错的硬件配置,CPU core够多,内存够大,数据库中也配置了几十个引擎(engine),可以充分利用多CPU core提升并行任务的执行能力。
此数据库服务器是典型的NUMA(Non-Uniform Memory Access)架构,一个系统有多个CPU,每个CPU里面有多个core,每个CPU core有独享的L1和L2 cache,同一个CPU 的cores共享L3 cache(Last Level Cache,LLC)。
cache的访问延迟比主存要小很多,越靠近CPU,访问延迟越小,处理器会根据不同的策略(Inclusive Policy,Exclusive Policy等)把数据缓存在不同级别的cache中,从而加快CPU访问数据的速度,因为根据“数据局部性原理”,目前访问的数据或者其相邻数据很有可能在不久的将来会再次访问到。
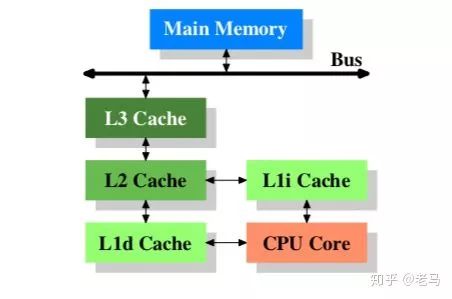
同时,cache的容量大小也比主存要小很多(如Interl处理器中的L1 data cache 大小为32k),如何优化代码使之有效利用cache提升系统性能一直一来都是个是热门的话题,也是本问题接下来重点关注的一个方向。
三、收集线索
Linux系统自带的perf工具是性能分析利器,熟悉系统性能分析的应该都不会陌生。接下来将介绍如何使用这个工具一步步分析问题,并最终找到原因,我的主要的思路是,由大到小,由面到点,关注热点。
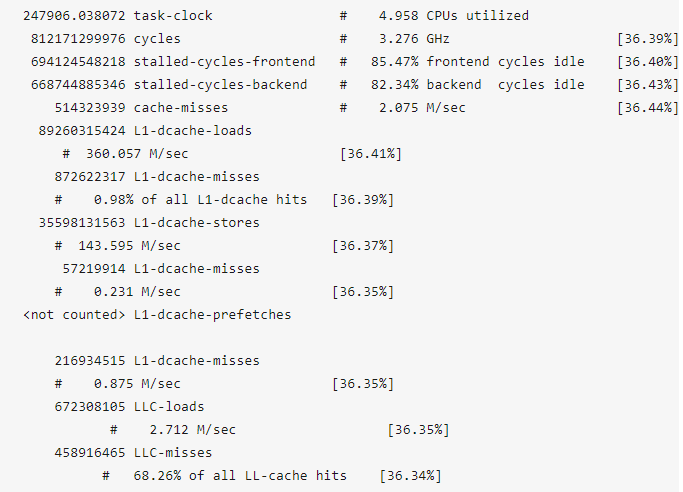
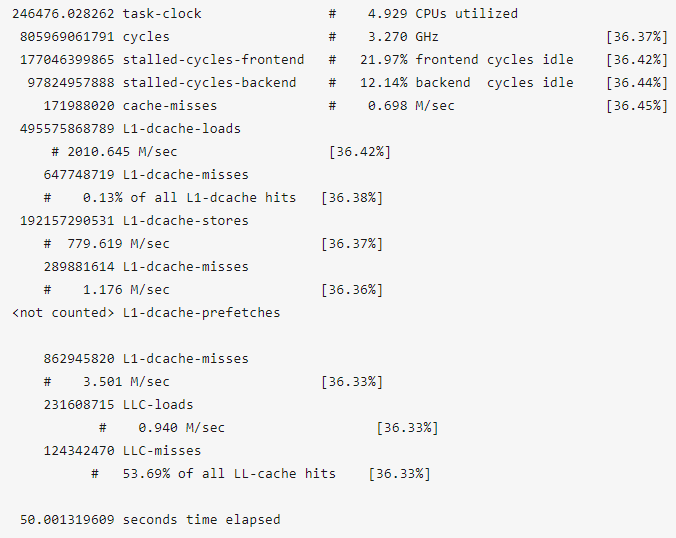
“perf stat“能够收集采样周期内关于某些事件(event)的统计信息并显示出来,通过这些信息可以大致了解程序的运行状况。这里重点关注的是CPU和data cache,当然,也可以根据个人需要指定其它事件进行监测。
输出里的一些数据比较有意思,需要重点关注的是,stalled CPU cycles超过了80%!
接下来运行“perf record“ 收集性能数据,并用“perf report“显示:
perf record -p 29261 -g sleep 50
perf report > perf_record.out
通过查看各个函数消耗CPU时间的情况,发现占比最高的前两个“热点“函数如下 (鉴于知识产权的原因,对函数名进行了一些修改,请勿对号入座):
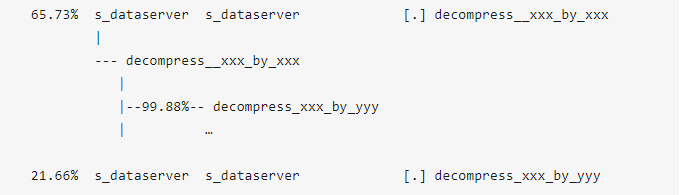
很明显,这是两个解压缩数据的函数,由于全表扫描需要解压缩所有数据行,检查每一行是否符合查询条件,所以解压缩的函数消耗大量CPU时间也合情合理,但是消耗的CPU时间的占比确实有点高(这里先打个问号)。
接下来使用“perf annotate“查看指定函数内代码行的CPU资源消耗情况:
有一条指令消耗了67.04%的CPU资源,(另一个热点函数也是类似的情况),非常可疑:

通过解析汇编指令和源代码比对,找到了这条可疑指令对应的源代码(由于知识产权的原因,对变量名进行了一些修改,请勿对号入座):
那条消耗CPU最多的汇编指令对应的源代码操作是:
看到这些,你可能会有诸多疑问:
这个decompressinfo是什么,有什么特别之处?
为什么如此简单的一行代码却消耗了了大量的CPU时间?
为什么如此简单的“数组“元素访问也成了问题?
四、分析原因
为了更好地说明问题,下面给出decompressinfo对应的数据结构,并稍微解释下与之相关的背景知识。
typedef struct xxx
{
/* Arrays of different types */
TYPEA *arrayA;
TYPEB *arrayB;
TYPEC *arrayC;
TYPED *arrayD;
/* Other variables */
short v1;
short v2;
int v3;
.................
} XXX;
该结构体大小是48字节(仅列出了部分结构体成员,已经足够帮助说明问题,请勿较真)。
该结构体存放的是解压缩数据需要的信息,这些信息在全表扫描过程中不会改变。
该结构体的内存来自于数据库内部的一个memory pool,解压缩的时候也会从这里分配内存,用于临时存放解压缩后的数据。
在构造decompressinfo的时候,首先会分配一块足够大小的连续内存,内存的前48个字节用来存放其结构体成员,然后,几个成员指针分别指向剩余连续内存的不同位置(具体位置取决于每个成员指针指向的“数组“的大小)。在本例中,其内存布局如下:

虽然了解了这些信息,还是感觉似乎一切看起来都很正常,并无明显不妥。
这里还需要再稍微提一下介于CPU和主存之间的cache,CPU访问某个虚拟内存地址处的数据时,会先尝试cache,如果未命中,便会把数据从主存加载到cache。
从虚拟内存地址到cache的映射有多种策略,如direct mapped,set associative,fully associative,硬件厂商使用较多的是set associative,这方面网上资料很多,本文不展开此话题。数据加载的最小单位为一个cache line,其大小随硬件厂商不同有差异,目前使用较多的是64字节。
这样一来,加载到cache中的数据大小可能会大于实际访问的数据,造成的结果是,如果两个并行任务工作在连续内存上的相邻区域,它们私有的数据可能会被加载到同一个cache line,虽然它们并无数据共享,这个现象叫做共享cache line。
结合上述知识,让我们把decompressinfo放到更大的内存空间,问题就变得稍微清楚些了:
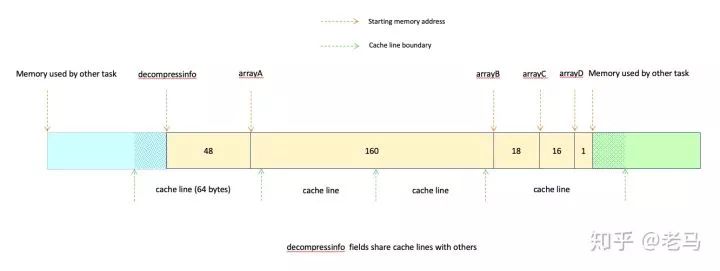
简单来讲有如下几点:
decompressinfo所在内存块的开始地址和结束地址未必正好在一个cache line的起始处。
arrayC距离整块内存的结束地址17字节,有较大可能跟后续连续的内存地址共享cache line。
如果后续连续的内存分配给了一个执行大量写操作的任务,每次写操作将会引起该cache line 在其它CPU core的copy失效,其它CPU core在下次读取该cache line的时候需要重新加载。这个现象称为cache line的“false sharing”,对并发任务的性能有较大影响。
五、验证结果
所有疑问似乎都有了合理的解释,不过目前这都还只是猜想,需要实践来检验。
立即优化了相关代码,调整了decompressinfo使用的内存块地址,使其cache line对齐,避免跟其它任务共享cache line。
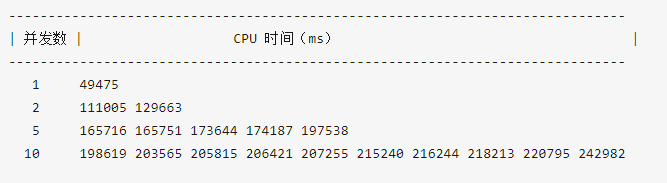
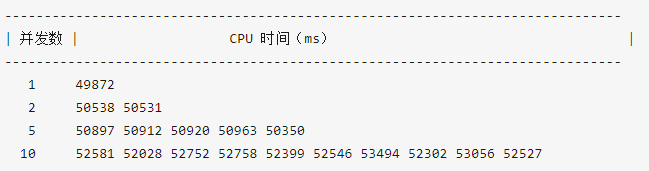
在本地环境测试后,之前的问题基本消失,部分测试结果如下,
优化前
优化后
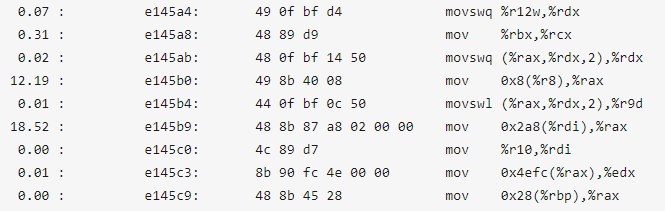
再次运行“perf annotate“,发现之前的问题行消耗的CPU已经大幅降低:
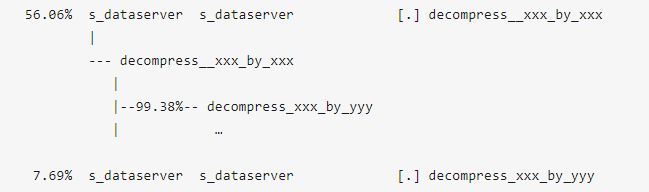
再次运行“perf record;perf report”,之前的两个热点函数消耗的CPU也有所下降:
再次运行“perf stat”,也有不少有意思的发现:
stalled CPU cycles大幅减少,说明CPU得到了有效利用。
L1-dcache-loads大幅增加,说明更多数据从延迟较低的L1 cache读取。
LLC-loads大幅减少,说明更少数据从延迟相对较高的L3 cache读取。
六、结束语
系统性能优化是个非常有挑战性的工作,是对一个人的全面考验,包括合适工具的使用,代码的熟悉程度,分析问题的能力,知识的广度,还有丰富的想象力,但同时也是个非常有意思的经历,你将深刻认识到细节的重要性,亲身感受到小小优化带来的大幅性能提升。
作者:殊途同归
来源:https://zhuanlan.zhihu.com/p/58881925
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721