
本文根据王磊老师在〖2018 Gdevops全球敏捷运维峰会-北京站〗现场演讲内容整理而成。

(点击“此处”可获取王磊演讲完整PPT)
讲师介绍
王磊,现任职光大银行科技部数据领域架构师,曾任职于IBM全球咨询服务部从事技术咨询工作,具有十余年数据领域研发及咨询经验。目前负责全行数据领域系统的日常架构管理、重点系统架构设计及内部研发等工作,对分布式数据库、Hadoop等基础架构研究有浓厚兴趣。
大家好,今天我想跟大家分享一下银行业的图数据库选型、分析与实践。因为这个题目还是相对比较小众一点,所以我先讲讲为什么我能有机会跟大家分享关于图数据库的话题。
其实就像上午沈剑老师说的,我们去研究一种新技术的时候,不是因为觉得这个技术很新,或者做这个东西会显得自己水平很高而去研究,是因为它服务于我们本身和业务。
比如像光大银行的业务我们碰到了一个挑战,就是这种业务场景下我们面临的数据是高连接的数据。对于银行来讲,资金流是一个很重要的场景,人之间的关系也是很重要的一个场景。当我们在一些典型的业务环节里面,比如发放贷款环节或是审计环节里,就会关注到人之间有什么样的关系、企业之间有什么样的关系、账户之间的资金是怎么流转的,后面就会有具体业务的展开。
但面临这些问题的时候就会发现,连接度很高的情况下,传统关系数据库最大的问题就是在性能上不能满足我们的要求,或者可以说它根本跑不出结果。要解决这个问题,就试着看图数据库是不是能够给我们一些帮助,所以我们在这方面做了一些研究,跟大家分享一下。
基本上我们会从三个部分来讲:
图的概念;
图数据库技术分析;
图数据库在光大银行的实践。
一、图的概念
首先看看图这部分是怎么引入进来的:
关于图,我们说的图肯定不是图片,我们指的是高连接的结构数据。其实图本身这种结构的使用,跟IT技术的发展可以分开来看。
下面这个是《人民的名义》人物关系图:
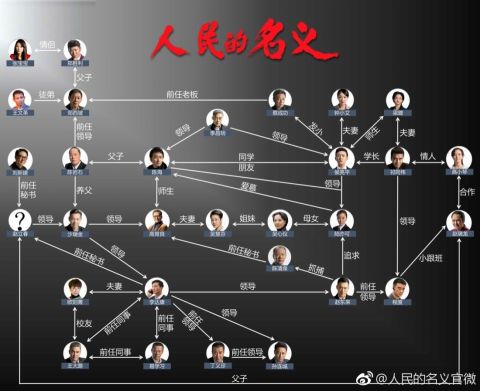
很多人接触图可能都是从类似这种方式,了解我们看的小说或者剧里面有什么样错综复杂的关系。
这个图的好处就是把整个人物关系一次性直接推给你,即使没看过这个剧,也可以一下就找到这里面哪些连接比较多,可能是主要人物;哪些是偏的;人物矛盾冲突会发生在哪些环节里。这种比我们只读文字性的内容,然后在脑海里构建这种关系显然更高效更直接。
在实际生活中,其实在很多方面大家都会用到:社交网络或者交通网络、通讯、资金,甚至我们去看地铁图等都会用到。以图的形式来组织和表达,会让我们更容易的接受和理解它。
以上我们说的这种图可以认为它是更加原始的,包括剧里人物关系,绘制的时候作者不需要有太多IT或者数学的背景就可以画出来。但是技术层面处理这个问题的时候,需要有一个严格的规约。这里会有一些跟数学方面的概念,也就是数学世界图的相关内容。
因为大家可能知道有“图论”这样一个更具体的研究领域来专门研究图的相关问题,我们这里面不会走的那么深,就为了便于后面的理解,只需要有一些基本概念就可以了。
图首先要清楚它的边分成有向边、无向边、平行边,实际组织数据的时候往往会是有向图的形式,也就是既有平行边又有环的形式。

节点之间的边如果是有向,那就是有向图;如果是无向,那就是无向图。在工程实践当中,其实我们多数出现的图是有向的多重图。
回到工业界使用的时候,虽然有数学这样的基本概念,但工业并不是零散地在用它,而是把它提炼形成一套模型,就好比我们在关系型数据库里用ER去描述一个关系型数据库怎么去建模。那ER本身其实就是对关系数据库建模方法的一种提炼。
比较遗憾的是,因为图数据库的发展在新兴阶段并没有形成规范的描述语言,所以我们这里以一些相对不那么严谨的描述语言来叙述,方便大家能有一个印象。
更具体来看一个更完整的结构,其实有三类在工业界中使用的图的形式:

常见的或者说会比较多被传播的就是RDF、属性图和超图,超图就是一条边可以连接多个顶点这样的形式,但是它使用比较少,我们侧重讲前两个:
第一个RDF已经有挺长的时间了,大家如果搜RDF相关的东西,可以搜出来。但是它有一个特点,因为它的来源实际上更多是学术界的研究,过程中服务的主要对象就是语义万维网,这是一个将互联网上所有知识来做连接使用的这样一个有宏大目标的事情。
后面包括现在比较热门的知识图谱,谷歌的知识图谱其实也在进一步发展。但是RDF这个方向的东西很容易让人头晕,因为它是一个偏学术上发展出来的东西,所以里面会有很多复杂的概念,我们这里面只讲简单的。这里面有一个基本的组织单位就是主谓宾,主谓宾其实就跟我们在语文上面的主语、谓语、宾语是一个概念。
第二个叫属性图,是为了解决高连接的数据怎样高效查询、使用、存储。属性图的节点和边是它构成的重点,或者我们可以称为是顶点不变。属性图最大的特点它的边和节点都是可以定义属性的,这样相对RDF有一个很大的突破,因为RDF本身是不能有属性的。
有了属性以后,它就变成了一个描述能力更强的结构,其实有点近似于我们定义一个结构体。在属性图里面,如果我们想进一步明确,还会引入新的概念,所以有了标签以后,属性图有的时候也会被描述成带标签的属性图,这样在实际使用中会更便捷。
下图是一个例子,从左到右三个图表达完全相同的语义:
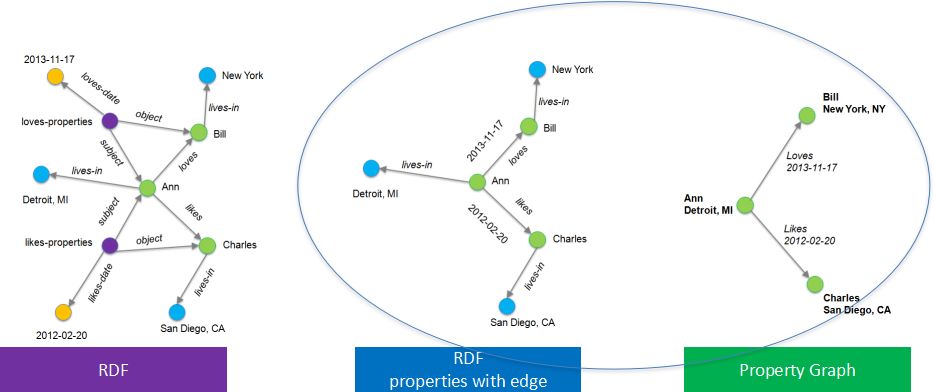
首先第三个最简单,这是属性图,就是说只表示三个人之间的关系,每个人就是一个节点,这个节点除了人名以外上面还挂了一个属性,就是他所居住的城市;边上面有两个东西,一是两个人之间的关系是什么样的,二是这个关系发生的时间在什么时间。
再看另外两个图,表现形式就不一样了:
最左边这个图就是我们说的RDF这种组织形式,RDF有一个特点就是它是没有属性的,所以它所有的信息要通过顶点和边的形式来出现,这里面就不是最左边出现三个绿色的点表示人,因为还要把相应的城市,相应的关系都表现成相关的节点和边,所以更复杂一点。
中间一种形式则是一种妥协,RDF也会在边上增加属性,相对左边这个已经简便很多了。
这里我们想解释一个容易被混淆的概念——知识图谱。这两年,知识图谱也是非常热的话题,但其实知识图谱跟图的存储以及图的展现是两个概念,或者说图的存储是知识图谱的关键技术之一,知识图谱还有些更复杂的内容,包括自然语言处理,机器学习等,它更大的输入来源于非结构化的数据,而我们今天讲的存储的技术,其实更多关注的是结构化的形式。
二、图数据库技术分析
下面具体来展开一些技术层面的话题。
下图是一个评估,给所有类型数据库做了一张图:
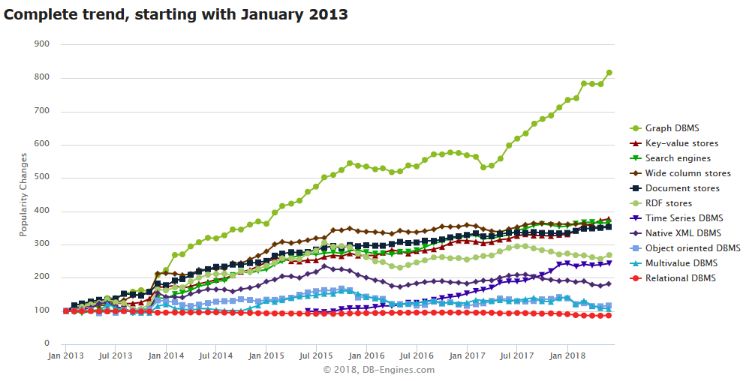
这张图经常会被用来说图数据库的发展形势。其中上面那条增长幅度最高的就是图数据库,一下子跟其他所有数据库都拉开了距离。这反映了图数据库的一个良好的发展趋势。
但是当我们2017年开始考虑这个问题的时候,在市场上转了一圈,发现真正能应用、真正能提供解决方案的非常少。也许在国外可能会稍微好一些,但是我个人感觉更多还是停留在谈一谈的阶段。甚至我觉得这两年随着社交网络的回归,大家谈的都会少一些。但是怎么说呢?它仍然表示了图数据库未来发展的可能性。
那么我们为什么要用图数据库?这里面更系统讲一下四个比较重要的使用价值:
最重要的就是它有一个很优秀的查询性能,可以避免基于关系的数据库来做反复的join。而图数据库的存储技术完全不同。
它具有更灵活的数据建模,图数据库底层的存储形式是一个Schema-less,对结构约束性更少一些。
易于理解,这种图数据的展现形式和组织形式是非常贴近的,所以也是较容易去理解的,不像关系这种,给业务人员讲的东西和最终实现的有比较大的差距,但是图这方面不太一样。
图算法的支撑,让我们摆脱了人直观感受来分析数据的局限性,可以更海量、更迅速地处理这个数据。
当然这里面四个价值其实是我们的一个理解,其实也并不是所有的图数据库都能体现这些价值,我们后面介绍不同类型的图数据库时,大家就会感受到。
看图数据库的时候也要找一些权威发布的产品,第一个还是把DB-Engines的东西拿出来,内容有很多,但是这里面真正具备使用价值的选择其实并没有那么多:

我们说几个重要的:
一个是FlockDB,因为这个数据库是推特开源的一个项目,提数据库的时候,我的第一反应是图数据库的图的这种形式跟现在比较热的社交网络有很紧密的关系,那么是不是说这种社交网络的公司也会有这方面的探索。
但很遗憾这些头部公司其实并没有提供真正有使用价值的开源项目,包括FlockDB这个项目,已经有好几年没有做过技术更新了,基本上已经死掉了。可能有一个原因是它不像大数据其他领域都有头部厂商的发展,所以在图数据库的发展上面相对来说还是比较滞后。
另一个是最上面的Neo4j。Neo4j基本是这个领域里最领先的企业。大家如果去找图数据库相关的东西,不管是去谷歌还是去百度搜,能看到的文章一半以上都是Neo4j相关专家来写的。包括市面上大家能够找到的书籍,基本都是在讲Neo4j数据库怎么用。
这是一家欧洲的咨询公司给出来的基于图数据库的一个分类:
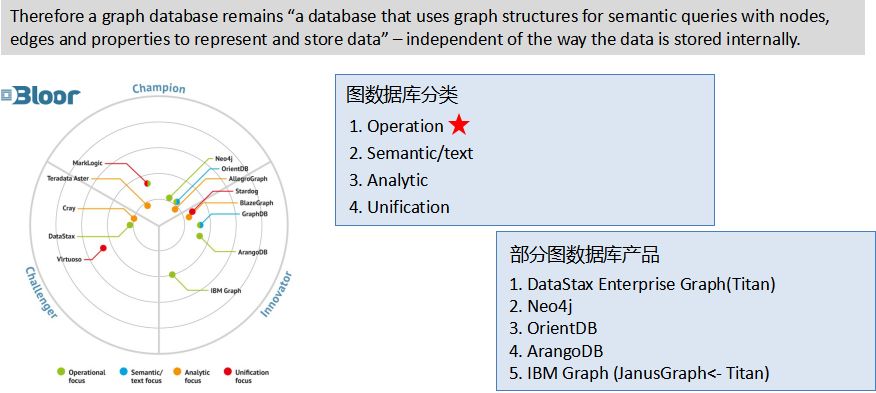
它把图数据库分成四类:
Operation
文本
分析型
混合性
我们更多关注的是operation这个分类,左下几个嵌套的圆环代表得分,离中心越近,分数越高。
这里面我们列了几个重要的产品,跟我们技术选型也有具体关系。一是Titan,Titan在2016年还是2015年的时候被收购了,收购之后Titan的项目结束了,就转向做闭源的产品。后来Fork了一个分支叫JanusGraph,跟IBM有比较大的关系,IBM也会在他的云服务上提供图数据库,包括在这张图上出现的IBM Graph其实就是JanusGraph。
我们下面来讲一些深入的内容,看看在架构上一个图数据库具体的构成是什么样的。
JanusGraph架构
这里面我们先看看JanusGraph,我们光大主要用的是Titan。Titan也好,JanusGraph也好,后台是同一个存储设计,都没有自己的存储,把数据存储在几个可选的外部存储方案上面。JanusGraph本身它支持的后端存储产品其实更多,它基于后端存储还提供了一个索引方案,整个后端实际上是一个开放的形式。
这是产品的结构:

可以看出它更偏向中间件的结构,如果去看现在流行的分布式数据库,MySQL也好,其他今天介绍的数据库也好,其实会有一个趋势就是把存储的东西跟上面计算组织的东西分开来看。
JanusGraph也是这样,只不过它选择的底层是第三方的,而不是自己做的东西。它这样一个结构的好处就在于存储剥离出来以后,存储本身的水平扩展完全不是问题。
但在这个架构里,前端的计算节点其实会稍微有一点局限,因为它仍然是个单点计算,这个单点计算并不是说它前面只有一台机器,它是可以水平去扩的,但是每一个点接到单个的任务没法儿再做拆分。还有一点是它是提供索引方案的,只不过这种方案效率并不是特别高。
Neo4j架构
我们再看一下Neo4j的架构:
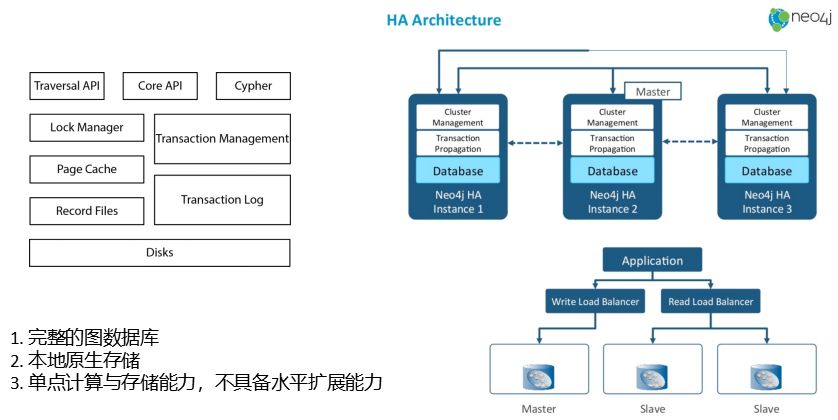
Neo4j能搞定所有的事情,所以它把自己的路线称之为原生存储。原生存储的好处显而易见,因为存储设计是一体化的,所以一定会做最大优化。在性能上面就单点而言,肯定会有明显优势。
我们看JanusGraph不是原生存储,是接受第三方的,Neo4j是自己搞定事情。Neo4j本身是开源的,开源版实际上是不支持集群的,当然它的单点的确有较强的处理能力。在商业版里面,提供的集群是靠主节点向从节点做同步。这样一个方式很显然它的整个存储实际上是拷贝出来的,也就意味着它的存储上线还是取决于master存储上线,这也就算是它的劣势——存的东西不能太多。
下面实际上是在把这个图数据库架构里面的一些重要的东西再拆分出来给大家介绍一下:
查询语言多样化
从外向里面去走,第一层看到的是交互形式,就是查询语言是怎么样的:

大家知道数据库是SQL,不管什么样的都要跟SQL进行交互。图数据库其实不太一样,这可能也是因为这方面体现了它的一个发展阶段——百花齐放,大家做出什么样接口的都有。历史最长的应该是第一个我们做的SPARQL,但是它更偏学术一点。
Gremlin——图灵完备语言
第二个Gremlin被很多数据库支持,另外还有其它的扩展标准:
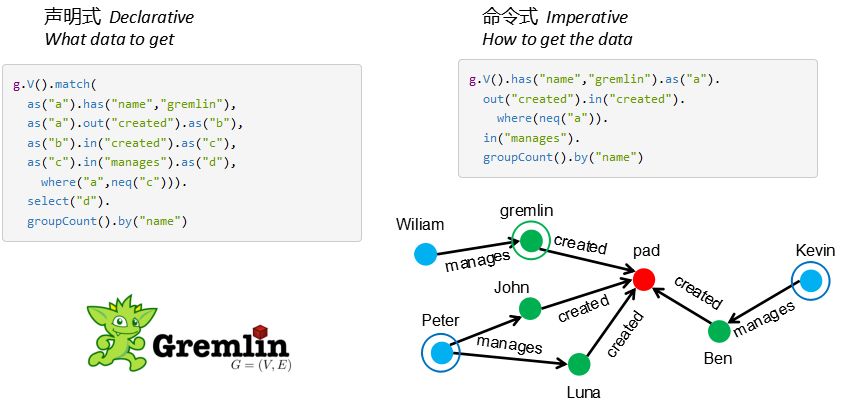
Gremlin同时支持声明式和命令式两种风格,它声称自己是图灵完备语言,这和支持命令式风格是有关的,因为可以进行细节操控。右下方有一个示意,就是体现出图数据库建语言的灵活性,通过蓝色节点找到其它蓝色节点,这里面有正向的查找也有反向的查找,大家可以尝试用SQL去实现这样一个结构查询,是非常复杂的。
剩下的我就不多说了,如图:

一种是关系数据库,一种是原生单机存储,一种是分布式存储,一种是原生分布式存储。
接下来一类图数据库,比如SQL Server 2017。它支持一些图数据库特性,但依然是关系数据库的后端存储,决定了有一些灵活性它是不具备的,因为数据还是存在表里的,与这类似的基于PG做的图数据库,它的灵活性相对好一点:

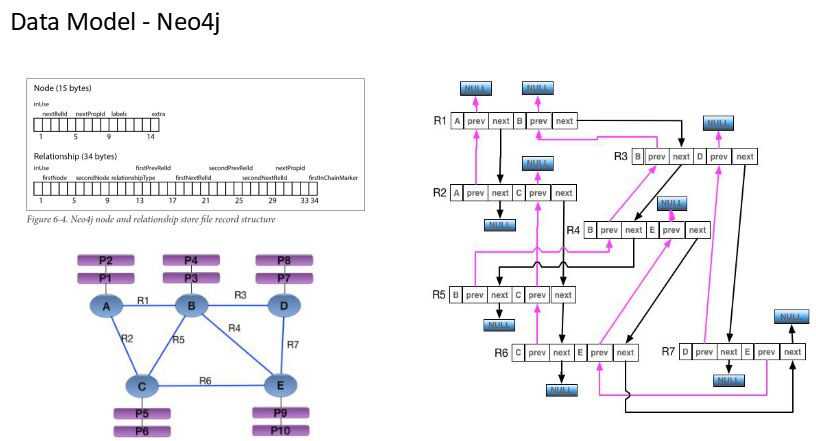
下图是Neo4j结构,时间关系就不介绍了:
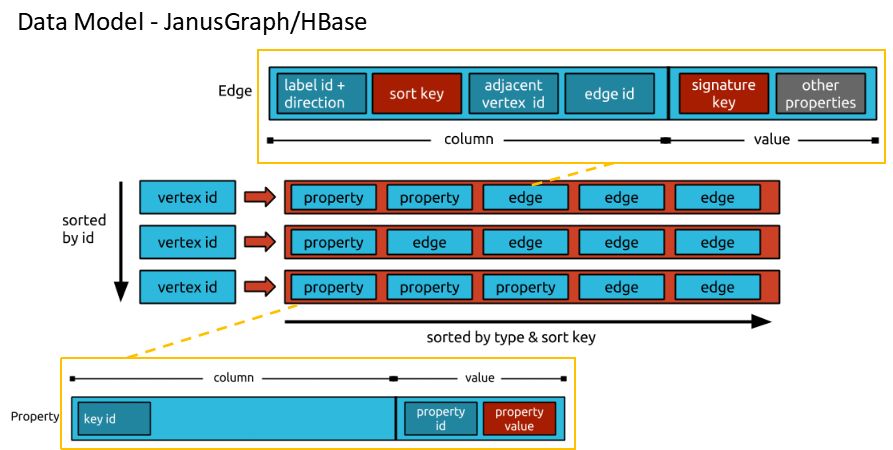
这是JanusGraph,它是基于存储在HBase上面来做的:
还有一个比较关键的概念就是在谈图数据库的时候,包括图数据库本身的定义有一个很大的争议。一种观点是说,图数据库是以邻接索引的方式来做的,这是Neo4j提出来的观点,但其它厂商不太同意这种观点,认为有其他的方案也可以获得很好的性能,如下图:
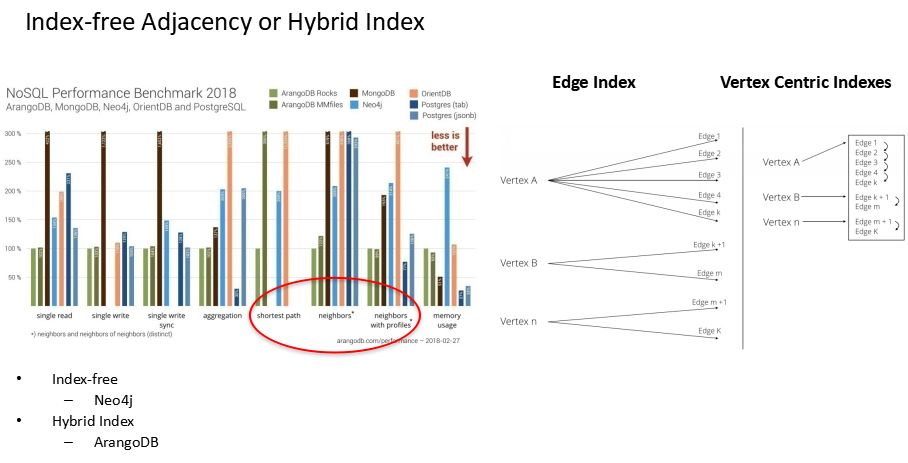
此外,还有一个是关于不同存储引擎的影响,在性能上有较大提升,在存储引擎部分引入了一个新的模型WiscKey,相对于传统的HBase、RocksDB等LSM-Tree来讲有一定的差别。
我们再讲讲算法。因为我们不太可能这么大量的数据都让人来看,一个剧里面最多可能就是几十个人物,但是我们面临数据是几亿甚至几十亿,这时候依据一些算法会得到更好的效果。
比较典型的算法PageRank:

在整张图里面可以看到4号节点是焦点最多的,而6号节点虽然不是连接点多,但它的PageRank值是第二位,这代表什么意义?其中一个场景就是在一个犯罪网络里面,6号节点更有可能是这个组织的首脑,而4号节点可能是军师或者执行者的角色,由他联络这个团伙里面的其他人,这样可以很好的把这个算法映射到实际问题的解决上。
另外是社区发现算法,其中比较简单的是标签传播,解决我们怎么样才能分不同的子图,然后缩小分析的范围的问题:
商业化产品异军突起
接下来我们讲讲国内外的形势,图数据库发展的并没有那么理想和成熟,但是在2017年是一个很神奇的时间点,很多图数据库都涌现了出来:

比较典型的几个大厂的产品,包括亚马逊、华为、阿里,都在推他们自己的图数据库产品,而且在图数据库整个架构上面又有了一些新的演进和变化。
开源数据库的Github Star
我们把github上所有开源的图数据库的“星星”数量做了一个统计:
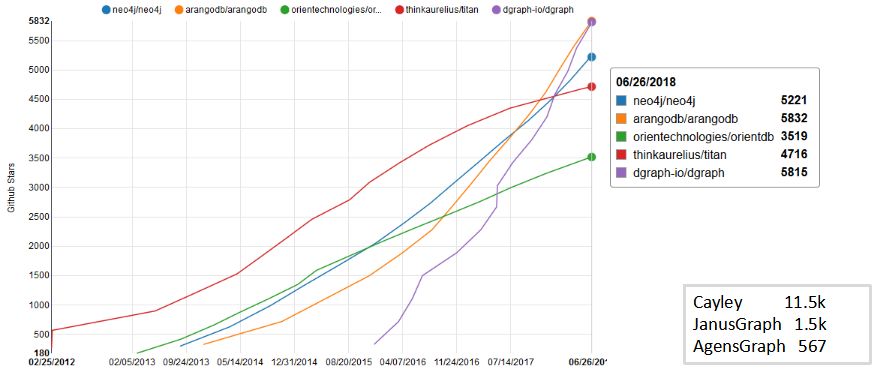
这里面可以看到我们刚才说到的Dgraph和ArangoDB都有一个好的趋势,另外也是一个前谷歌员工开发Cayley,但并不是谷歌来做的,一开始初期的时候数量就很高,但是后期的增长下来了。
技术发展趋势
其实从整个图数据库这么多产品的发展来看,基本上可以分成三个阶段,一些图数据库厂商自己也会对它的发展做一些定义:1.0、2.0、3.0。不过这里面没有一个权威定义,我们根据我们的理解也把它做了一个细分:

最早是单机、存储和计算,然后是可以做并行计算,这种就像一些更多去做离线计算的系统,但是这种并行计算是不能满足交互能力的。更新一些的产品可以到3.0,也就是计算能力和存储能力都变成可扩展了,而且有些产品里面可以做到计算的并行,就是说接到任务的那个点可以把它再分出去,多点协同来做计算。
三、图数据库在光大银行的实践
这是我们在光大里面做的一些典型的场景:

比如在信贷审批业务过程当中,因为信贷审批是一个风险控制的环节,那么一个企业做贷款的时候我们就会关注你的控股是哪些、你控股了哪些公司,这样一个复杂的结构里面就应该给你做一些比如说贷款额度上的限制,因为你的风险会传导。
像反洗钱,还有亲属回避,亲属回避实际上是内审,就是说要确认这个企业跟你当前要去审计贷款的员工会不会有千丝万缕的联系。
审计分析业务(简化)逻辑数据模型
我们简单把这里面会出现一些要素画一张图来显示:
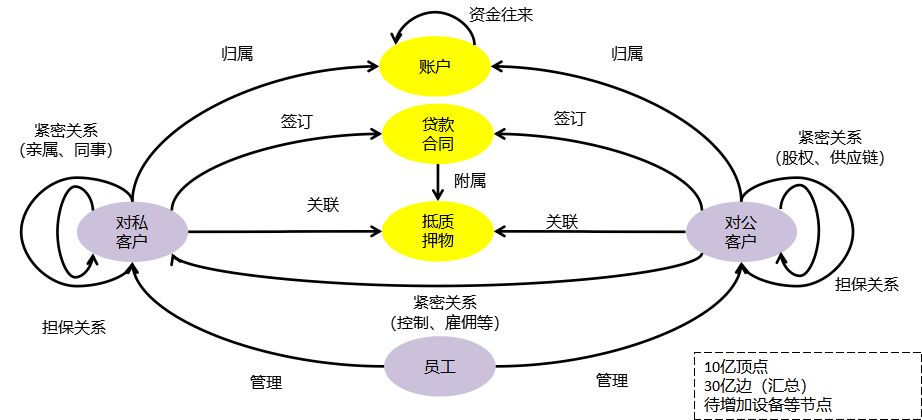
这其实只是个示意。但是图数据库本身的数据量还是蛮高的,用于实际场景,因为每一条边都反映交易的话,量就会很大。这个不同于前面说的RDF的产品,RDF的量相对来讲还是小一些。
比如之前被谷歌收购的Freebase做个知识图谱,它的最高的量就是30几亿,但是如果做实际业务量,这个数字很容易被突破。实际上服务工业界,数据库面临的挑战跟传统的RDF存储还是有区别的。
这是简单的架构层次的表示:
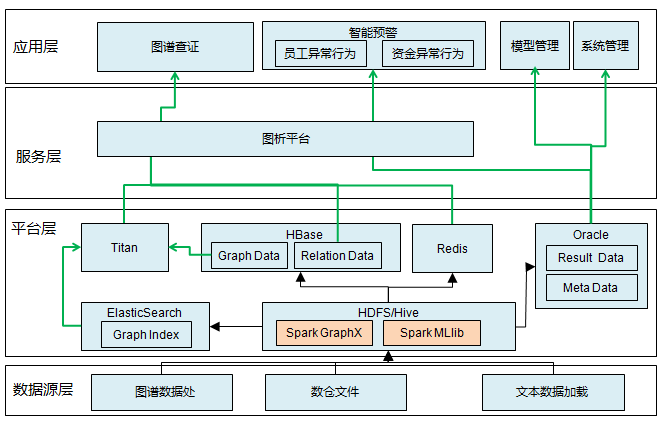
我主要的内容就是这些。如果大家有兴趣的话可以留言与我沟通!
Q:如果我们的数量级多达几十亿条边、几十亿节点的情况下,在算最短路径的时候,对性能可能比较在意。在图数据库选型上您有什么建议吗?我们之前也看了Dgraph但是还没实际测,您觉得Dgraph符合我们数据量及性能的要求吗?
A:对于几十亿的点和边,其实我们之前去看的数据量,我个人感觉因为我们当时跟Neo4j也做过沟通,Neo4j相对成熟度比较高,我们跟他做一些了解的时候,Neo4j官方的解释是说觉得在这个量完全它可以撑得住,我说的是单机版,因为几十亿对数据量来讲还不是太大一个量。
我们选择产品的另一个考虑不是量级的问题,而是生态的问题,要确保不管是自己的能力还是知识厂商的能力能对它有一个支持才行。Neo4j最大的问题就是没有在国内落地,它本身如果你有足够的能力去控制它的话还好,但是如果没有能力,像厂商来做,国内公司现在基本不太具备实际的支撑能力,这是一个潜在的风险。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721