

转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
Greenplum集群内部segment host因硬件(主板、硬盘、电源等)故障或是其他原因导致计算节点主机不可用情况下,以备用主机替代原segment host,快速恢复GP集群至正常状态,避免集群异常期间镜像节点主机因承载压力增加而产生新问题。
为保证完全兼容及GP集群整体性能,备用主机需与原主机在硬件配置、操作系统、文件系统、网卡及网卡模式、存储硬盘大小、IP及主机名称、主机参数等层面保持一致。
安装GPDB软件,版本与原集群保持一致,数据库参数设置与原segment host保持一致。
创建及配置gpadmin用户。
根据原segment host逻辑文件系统位置分布,在备用主机上以gpadmin逐级创建相应文件系统目录,各级目录位置和名称保持一致。
重新建立各节点间的ssh通信认证。
加备用主机进GP集群。
恢复备用主机上实例及同步数据。
验证集群状态。
A. 提前通知主机侧,修改备机内外IP、主机名与待替换节点主机保持一致,开放master主机与备机之间的安全加固,实现master与备机通过ssh直接访问,申请备机root口令使用权限。
B. 应用侧告知已停应用,即可通知主机侧断开待替换主机网络,使其脱离集群;并重启备机网卡,使已修改的IP与主机名等参数生效,让master可识别。
由于备机替换操作不定期遇到,期间数据库不间断运行导致部分系统表膨胀或是统计信息未及时更新,需执行vacuum analyze脚本,以便提高恢复实例同步数据过程中对系统表的检索速度。
A. 重启库,限制应用连接
启库命令:gpstart –R(该模式将使数据库进入Restricted模式,将只允许超级管理员可以连接数据库),请记住当数据库数据恢复正常后,请再次重启下数据库,使用常规命令(gpstart -a),重新起库,亦可以通过修改pg_hba.conf配置文件来限制用户登录。
B. 查询当前膨胀的系统表
通过视图gp_toolkit.gp_bloat_diag,查询当前膨胀的表,然后对单表执行vcauum full操作。例:
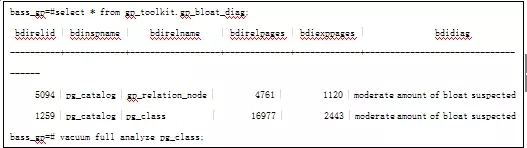
当上述步骤完成后,同时需要对系统表执行vacuum analyze操作,因为数据同步过程中,catalog膨胀,表记录多,会造成同步速率较慢,因此需要在同步数据之前,完成vacuum操作。
C. 执行vacuum脚本
脚本位置: master主机上:/home/gpadmin/shsnc/wangk
执行方式:sh ./vacuum
等待脚本执行结束。
为便于表达命令,假设原segment host在集群中主机名为sdw33
A. 在Master主机上使用root用户vi /root/.ssh/known_hosts ,删除文件中已存在的有关sdw33的认证,保存退出。
B. 重新建立master与sdw33通信认证

C. 执行 gpssh-exkeys命令,all_hosts_new为包含集群内所有主机的配置文件。

D. 切换用户,以gpadmin重复上述步骤(1)(2)(3)。

注意点:
i. 编辑原始文件前,请先备份原始文件,以免发生误修改不能回退。
ii. 原始known_hosts文件中,包含主机名sdw33和其IP对应的认证信息都需要删除。
iii. 实际操作中,因提前申请备机root权限及口令,可不对整个集群以root重新建互信,只需在master和备机之间重新建立一次。
A. 编辑一个tmp文件,只包含原segment host在集群中的主机名

B. 执行 gpseginstall命令

注意点:中途需要输入一次备机gpadmin用户的主机登陆口令
A. 切换至gpadmin用户

B. 执行gprecoverseg -p sdw33
......省略输出信息
注意:在批量recover出现速度异常慢等情况时,考虑分批次恢复备机实例,方式如下:
执行gprecoverseg -o /tmp/rec1命令,获得需要执行的恢复的节点信息,修改/tmp/rec1文件信息,只保留4个(可根据实际需要进行更改)需要恢复的节点,然后执行gprecoverseg -i /tmp/rec2命令。先从primary节点开始恢复,然后在恢复mirror节点。(由于在数据恢复过程中,catalog 表记录多,网络传输速度,磁盘切块读写等会造成系统性能瓶颈,所以每次只恢复4个,有助于提高恢复速率) 例:

当节点恢复一半以上后可以执行gprecoverseg -B 命令,恢复剩余的节点数据。例:当还有7个节点还没有恢复,可以执行gprecoverseg –B 7命令。

C. 执行gpstate命令检查所有实例是否都成功UP
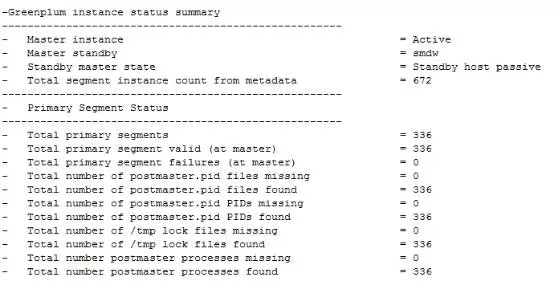
D. 耐心等待后台进程完成数据重同步,期间可以用gpstate –m/-e/-s等检查同步状态与完成进度;具体同步耗时根据数据量大小不等;
E. 待sdw33上所有实例完成数据同步,执行 gprecoverseg –r 命令,恢复异常期间primary和mirror角色互换至原始状态;
注意点:必须以所有实例全部处于同步状态为执行前提!
A. 执行gpstate –e命令
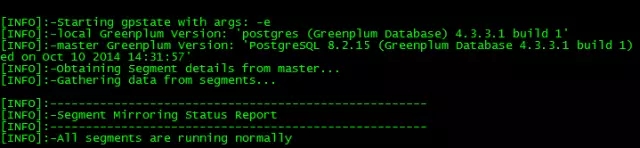
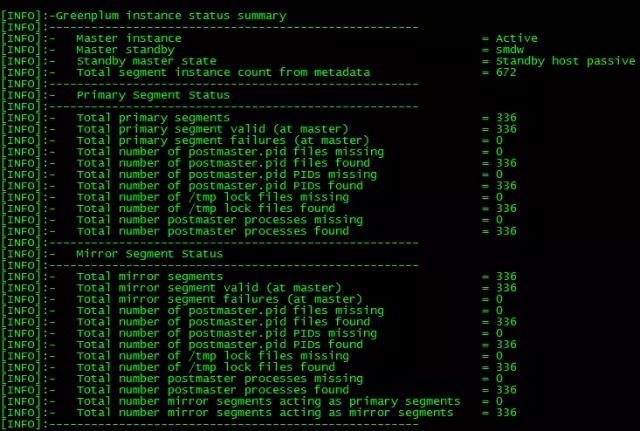
B. 执行gpstate命令
作者介绍:张玉朋
新炬网络高级技术专家;
5年以上电信行业运维经验;
擅长oracle架构规划,故障诊断、性能优化、shell编程等,对大型IT系统的oracle数据库运维有丰富的经验;
曾主导某省移动核心CRM、BOSS升级项目。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看杨德胜《Oracle故障日志采集“神助攻”—TFA工具详解》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看卢钧轶《揭秘Facebook数据库备份策略》;
回复019,看王佩《基于Docker的mysql mha 的集群环境构建实践》;
回复020,看王津银《互联网运维的整体理念与最佳实践》
DBA+社群是中国最大的涵盖各种架构师、数据库、中间件的微信社群!线上分享2次/周、线下沙龙1次/月,顶级峰会6次/年,直接受众10000+,间接影响50万+ITer。DBA+社群致力于搭建一个学习交流、专业人脉、跨界合作的公益平台,更多精彩请持续关注dbaplus微信订阅号!









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721