
本文根据DBAplus社群第132期线上分享整理而成。

主题大纲:
1、为什么选择Zabbix?
2、Zabbix二次开发有什么意义?
3、我们是怎么做的?
4、我们还利用Zabbix解决了什么问题?
5、我们将来要怎么做?
为什么要做监控?
运维的正确姿势肯定不是从处理故障开始,一定是从监控开始的。
从军事的角度出发,监控是一种积极防御战略,是未战之战,有效的监控可以拓宽战略纵深,可以更积极地保护我们的重点军事目标。以下是我们要求运维团队时时牢记的两句话:
出了任何故障,其它环节都可能有问题,唯独监控环节一定有问题。
海恩法则:每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。

IT服务成熟度模型中,监控手段是转被动运维为主动运维的必然“预防“和”度量“手段。因此,在这么多年的重大故障分析会议上,监控问题总是在会议前期和后期都拿出来重点讨论的,会议一开始就要问“为什么故障没有被监控出来”或者”在故障发生的前后都监控出来什么异样“。会议结束前的总结通常是“对于漏掉的监控项一定要被加入“或者是”对于监控到的指标或阀值一定要被优化“。
如果这四个问题都被很好地回答并改善,我想下次类似的故障是不可能出现的,因此,做监控需要有一个PDCA持续改进的过程,当然,改进的核心有且只有两个:“覆盖率“和”准确率”。
当然,对于一个更优秀的监控系统,它还可以有如下价值:
对组织:
全局监控帮助组织制定IT管理战略
从IT资源到组织业务的直接对接
制定IT资源、IT组织工作管理的基础
组织与内外部IT组织的沟通枢纽
对IT管理者:
IT管理者工作价值体现
帮助IT管理者全面了解IT现状
方便IT管理者管理IT组织的工作绩效
搞高IT部门的工作效率,减少企业成本
降低业务系统宕机风险
对IT操作者:
及时发现业务系统各个单元故障
深度定位系统的故障根源,及时解决
拉近IT操作者与组织业务的距离
直接体现具体IT操作者的工作业绩
帮助从IT的角度提高促进业务高效稳定
为什么是Zabbix?
前不久看到一则路边社报道,在中国有80%的企业在使用Zabbix做监控,不知道统计的方法和口径是怎样的,不过,80%这个数值也感性地传达了它的热度。
统计数据
在Zabbix的官网上找到一个清单,一堆国外知名公司都是它的合作伙伴,就最近的交流沟通中,但凡有计划做监控的组织无不试用Zabbix的,如果有网友有更值得参考的统计数据,可以回复本文,并注明数据来源。
目前,从IT Central Station的官网找到一份统计信息,这份统计数据是由加入这个网站的企业CIO反馈的信息实时得到,以下这份数据是2017年11月18日生成的。

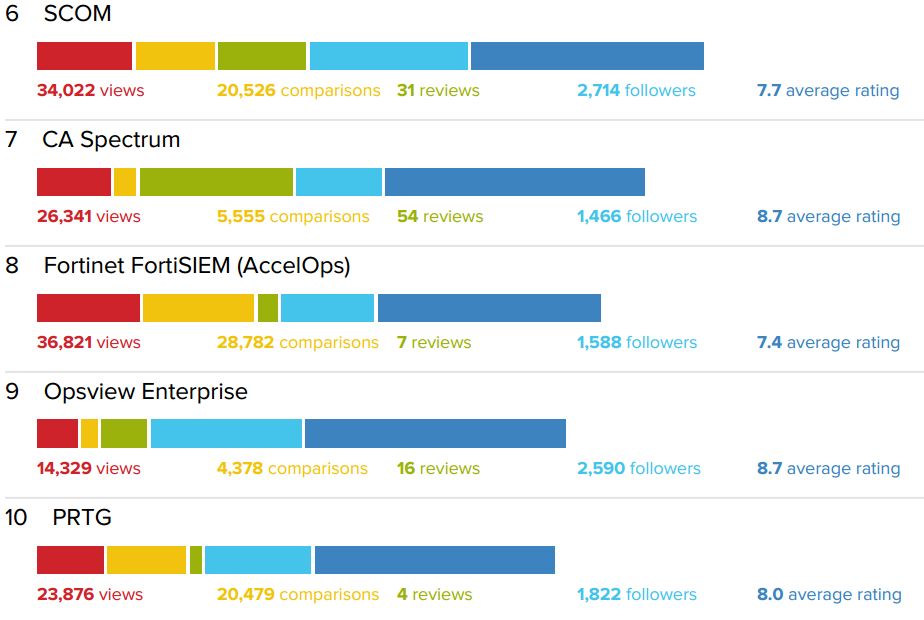

这份统计数据主要来自北美的参与者,在国内没有代表性,不过相信在国内的数据会比这个更高,国内对于免费和开源的被教育程度显然是更高,这个得益于红衣教主周鸿祎,以及一堆互联网公司的推高和强化,至于背后的商业伦理和其他成本问题姑且不论。
Zabbix的特点
Zabbix是一个基于WEB界面且提供分布式系统监控的开源解决方案,通过浏览器监视,做到告警分级处理、网络访问安全可控,该开源平台在全球有广泛的用户基础,它的特点:
开放性:源代码全公开,任何用户都可以编译和发布自己的版本。同时,社区和互联网可以找到大量的模板。
可扩展性:支持用户自定义监控项,只要能想得到的指标,基本都能监控的到。
数据采集:可用性和性能检测,自动发现,支持agent、SNMP、JMX、telnet等多种采集方式,支持主动和被动模式数据传输。
高可用:Server对设备性能要求低,支持Proxy分布式监控,分布式集中管理,开放式接口,扩展性强。
告警管理:支持多条件告警,支持多种告警方式。
模板能力:支持多组模板,模板继承。
告警设置:告警周期、告警级别、告警恢复通知、告警暂停,时段阈值、支持维护周期、支持单机停用。
历史数据:历史数据查询可配置,内置housekeeping数据清理机制。
安全审计:具备安全的用户审计日志、权限认证,用户可以限制允许维护的列表。
无商业版本:平台本身没有商业版和社区版本的区分,ZABBIX只对商业服务收费(如培训、定制开发、部署服务等)。
等等……
Zabbix的全栈监控能力:官网有一句非常“嚣张“的话,Monitor everything!


与其它商业产品对比
各个大厂都有提供相关监控产品,比如说微软的SCOM、IBM的Tivoli、华为的Esight、HP的BSM等,如果环境都是单一的某一家厂家的产品,用该厂家提供的监控工具肯定是合适的,笔者就曾经深度使用过SCOM,2005年还叫MOM,是System Center中的一个套件,这个产品对于微软周边的产品如AD、Exchange、Windows、SQL Server、SharePoint、Lync等监控非常深入,同时微软官方还提供了相关故障知识库,报表也做得非常不错,九一乐维团队甚至在2011年以前还拿SCOM做过定制开发。
但是,如果拿SCOM去监控Linux、AIX、Oracle或者网络通讯设备就非常不合适了。这里,Zabbix就能够很好地平衡监控的深度和广度,而且源于开源的力量,在全球用户的持续贡献下,它的深度和广度是在持续不断地延展的。
以下引用翔华兄(Shawn沙恩)的一张图说明Zabbix的深度和广度,见:https://www.jianshu.com/u/c7663d8c3fa8。

与其它开源项目对比
前文提到在IT Central Station中,Nagios X排在Zabbix的前面,我们团队在定技术方向时,也深刻对比过,两者简言之:Zabbix安装好后,做一些简单的设置基本上就可以用了,Nagios X部署完成后相当于只是一个平台,需要安装第三方插件才能起作用。详细对比如下:

当然,市面上还有诸如:Open-Falcon、Zenoss、Ganglia、Prometheus、Cacti等开源产品,简单分析如下:
Open-Falcon:小米开源,时间不长,成熟度有待提高,现在的版本是V1.0。
Zenoss:区分社区版和企业版本,资源消耗高,社区版本有些鸡肋。
Ganglia:适合监控系统性能,成熟度和完整度不高,如报警、消息系统,需要更多二次开发。
Prometheus:开源的业务监控和时序数据库,刚发布2.0,在稳定性、性能、文档上仍有很大提升空间,互联网上可用资料,案例还不丰富。
Cacti:通过 SNMPget来获取数据,使用 RRDtool绘画图形,画图功能强大,报警机制及相关功能不完善。
以上这些产品,笔者认为Prometheus会是个不错的方向,最根本是它的时序数据库,有兴趣的读者可以先行先试。
综合来讲,Zabbix是一个非常强大的监控平台,简单拿来完成监控一些Hosts,没有什么问题,而且目前国内大部分客户都是这么做的,基本上是安装完后,网上找到一些相关模板,配置后把Hosts监控起来就差不多了,当然也不乏像PPTV、携程、唯品会等这样优秀的互联网公司,做了深度定制和改造。
一个剥离的工具平台
Zabbix的所有监控对象都被认为是Host,包括主机、网络设备、中件间和数据库等,这样除了做监控,之后的运维管理工作就很不方便了,比如说配置管理、统计报表、权限、知识库、业务服务管理、CFIA等都会受影响。所以,原生的Zabbix仍然是一个原生的高度剥离的工具平台。

其它问题:
性能瓶颈,监控系统没有低估高峰期,具有持续性和周期性,机器量越大,数据的增大会使数据库的写入成为一定的瓶颈,每秒1万个指标(我们在项目实施过程中,达到过3万多个指标),据说4.0每秒40万个指标。
项目二次开发,需要分析MySQL表结构,表结构非常复杂,对开发能力有较高要求。
内置housekeeping在执行过程中会对数据库增加压力,需要对数据库进行优化。
图形功能较为单一、简陋。
使用有难度,要求操作人员的技术水平很丰富且全面,需要熟悉被监控对象,已经具备相当的开发能力。
API介绍比较粗糙,如果数据库表结构更改可能会影响API调用。
Zabbix 监控的模板比较复杂,没有一个比较简洁易懂监控模板创建的向导,使得模板配置比较困难。
Zabbix 的用户权限控制粒度不够。
Zabbix的交互界面还不美观,操作不人性化。
当然,还有那些你没有深入使用就永远也发现不了的坑。
显性化的需求
在界面展示上,目前使用较多的Grafana+Zabbix,能达到一定的展示效果,实施效果如下图:

也有58同城运维团队开源的Zatree插件,实施效果如下:
如果要求再高一些,就有些困难了,经常能看到希望可以用ECharts展示Zabbix数据的需求,甚至可以看到不少Zabbix数据与第三方商业显示插件的集成需求。
深度集成的需求
监控软件于信息化体系不是孤立存在的,把监控平台独立成一个信息孤岛,是不符合信息化初衷的,可能存在的集成系统列举如下:
其它运维工具:ITSM(也可能是独立的工单系统、服务台系统、CMDB或资产管理系统)、动环管理系统、APM系统、DevOps系统、自动化运维工具平台、日志平台、端对端拨测系统、安全系统、4A系统、审计系统私有云平台等。
消息通知:短信、微信、邮件、钉钉、内部IM系统等。
组织架构系统:组织架构、人员同步、权限系统、单点登录系统等。
统一展示:Portal系统、投屏、OA系统、微信公众号、业务数据统一呈现等。
其它:组织APP、企业知识库、音视频交互平台、大数据平台等。
信息系统的集成是信息化建设非常困难的一环,数据信任、源数据稳定、接口对接、例外处理,考验着信息化整合架构能力和信息系统质量。
业务保障的需要
监控的核心意义在于保障业务系统高可用性,尤其是核心业务系统的高可用性,而不只是监控那些Hosts,完成Host的监控只是完成了第一步,还需要做好三道必选题:
Hosts和业务系统存在怎样的关系?
业务系统出现故障时,哪些Hosts的状态和性能存在什么直接或间接影响?
当前Hosts的告警,到底对哪些其它Hosts或业务系统存在怎样的影响?
做监控源于我们早期做运维服务的必然需求,我们的愿望是基于Zabbix这个强大开源平台,结合实际一线运维工作的需要+ITIL等运维理论,做成类似MIUI一样的开发、易用、实用、人性和美观的全新监控平台。
架构设计
下图是我们的软件逻辑架构:
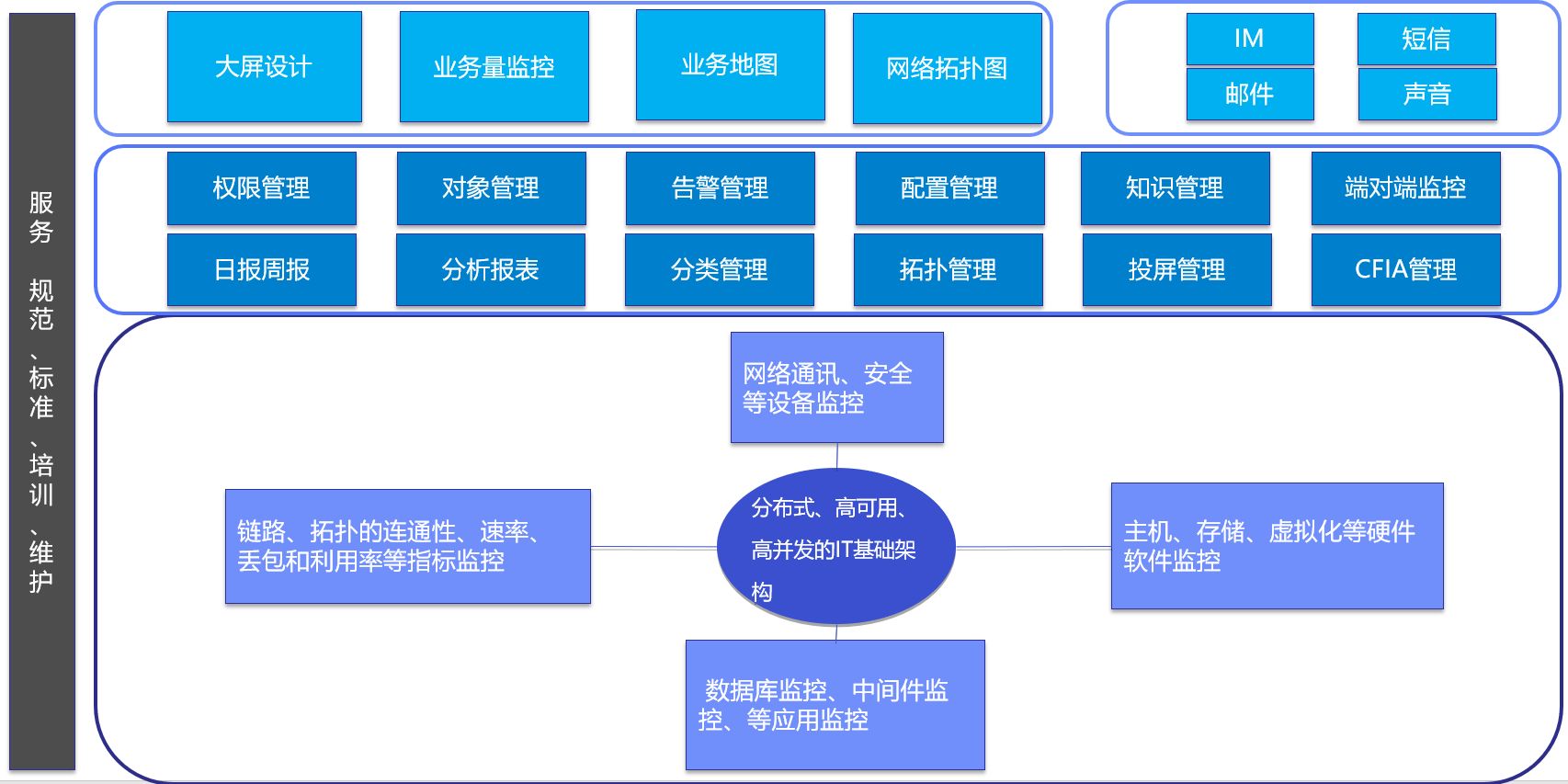
这个架构有两个最重要的基础:
将Hosts区分为主机、网络通讯设备、数据库、中件间、业务系统、虚拟机、硬件、链路等实体IT基础架构组件。
深度定制的基于Zabbix API实现,以PHP语言实现,把Zabbix原生页面保留在系统后台。
软件平台在功能逻辑上分为四层:
基础层:这一层以一个分布式、高可用、高并发的软件服务端为基础,构建以被驯服了的监控模板、指标和阀值为基础的底层监控体系,这一层纯粹是我们使用Zabbix的积累和经验。
功能层:基于Zabbix API实现的管理功能,这些功能抽取了大部企事业单位的监控需求的公约数。

展示层:监控效率的显性化表达,大屏设计,业务地图(CFIA的显性化),网络拓扑图,大部分客户都会需要业务量监控的显性化集成,业务量监控本身又是另外一个话题,当然这里的业务量核心在于源数据的获取,剩下的套路都基本一致,设计指标、设置阀值、触发告警通知等。
接口层:主要对接外部接口,如IM、短信、邮件、声音等。
在功能上最大的三个特点是结合生产实际,实现了拓扑的自动生成、自定制投屏和业务地图(CFIA,故障组件影响分析树),拉近了Zabbix和业务生产运维的实际需要。
前端交互
界面采用了Twitter开源的Bootstrap的前端框架,图表采用了Baidu开源的ECharts控件。
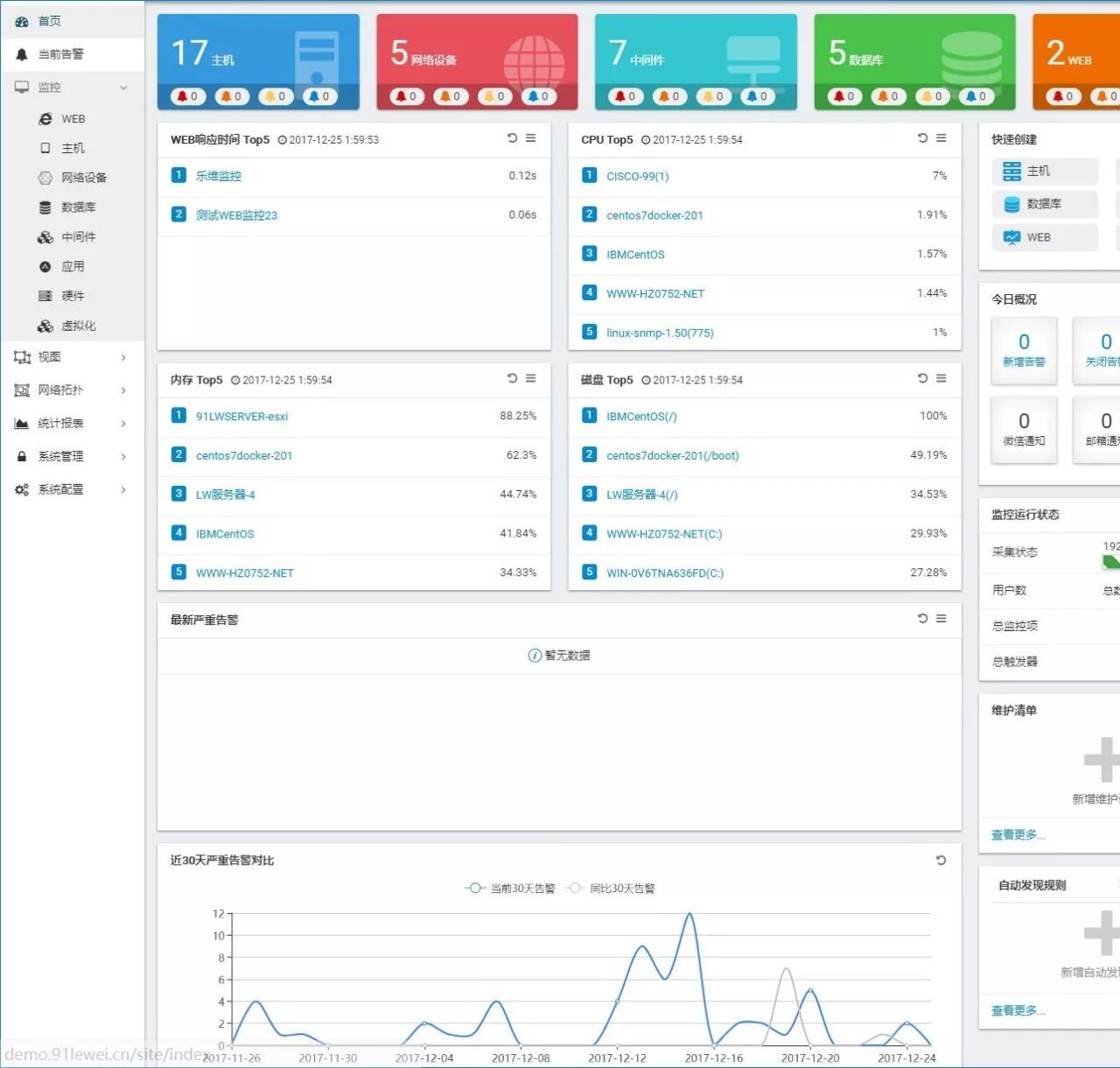
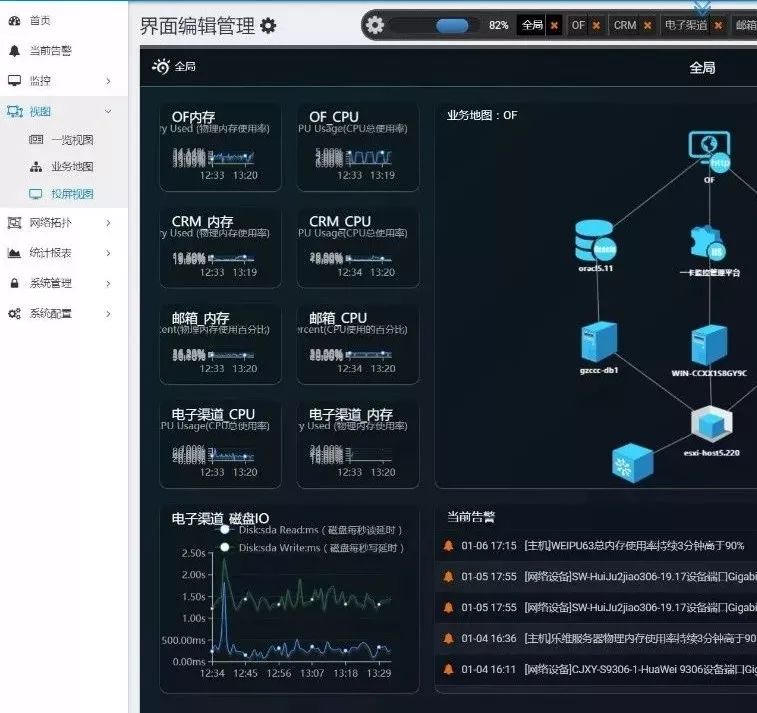
踩过的那些坑
从2011年开始玩Zabbix,踩过的坑着实不少,被研发的同事吐了无数槽,所谓“情到深处又爱又恨“。以下简述印象比较深刻的几个坑:
二次开发的方式:2011刚开始做的时候,我们直接修改Zabbix开源的源代码,实现了一些功能,自以为做得还不错,但后来Zabbix升级一个大版本,发现Zabbix做得比我们高明多了,所以之后我们都尽量不去改Zabbix的源码,动也只是做操作层面的改进,用户交互的改良。
模板:一开始我们想得很简单,网上收集一堆模板,这个事就算做完了,后来发现这只是个开始,默认模板考虑的深度还不够,需要持续改良和积累。
不必要的Item:在做IT基础架构监控尤其是网络监控的时候,对于Item的启用、对于指标收集的及时性和数据容量的控制至关重要,一开始我们几乎启用了所有Item,后来发现监控的效率和数据库日增量实在让人受不了,最后想办法压制了一些很少被用到的Item,改进的效果非常明显。
Oracle的监控:用原生的Orabbix监控Oracle时会有些问题,比如说常见的审计问题,需要DBA持续优化。
数据清理的问题:Zabbix默认配置了Housekeeping来清理数据,但根据我们的经验,在执行清理时除了影响数据库运行,还有约15%的系统资源的损耗,因此,我们默认关闭了这个功能,将这个功能脚本页面化了。
其它问题:
监控频率无法做到秒级别;
Web拨测只支持get和post,中文乱码;
脚本下发只支持Shell,并且搭配告警等触发,无法手动;
IPMI轮训存在延时;
告警有时会无法自动恢复;
SNMP监控请求一个监控项一个连接请求;
… …
常见优化的方向
以下简单列举我们常见优化的几个方向:
高可用部署:高可用部署依赖可预见的监控规模和组织,对监控系统的重视程度渐次加强,最简单的起码做到Web和DB的分离;其次,做到数据库层面的高可用;然后是分布式代理,甚至代理层的高可用;再是考虑Web层的负载,最后,有条件的可以加一层冷备。
数据库优化:Zabbix的数据库优化是被提到最多的,通常矛盾最突出的也是MySQL的性能,通常的解决办法是:表分区;优化Item;多采用主动方式采集;Housekeeper优化;优化触发器表达式;数据库主从,Proxy模式;Zabbix配置文件调优;分表;提高机器配置(SSD)。
在本文章要交付发表的时候,收到一则新闻:Zabbix 3.4.5 可能使用基于 Elasticsearch 的历史数据服务接口,不再受限于单机 MySQL 的容量和性能了。
数据库监控:上一节提到Oracle监控的坑,其它数据库也一样,多采用自己可控的监控方式。
链路监控:单独把链路监控提出来,对于一些有分支机构的组织来说显得尤其必要。
历史数据存档与清理:通常限定详细监控数据的保存时间,只保留趋势数据,转存或清理历史数据,我们采用脚本页面化的方式实现。
监控平台的自监控:监控Zabbix本身的状态
监控作为一个重要的管理手段,存在很多的使用场景,简单列举我们现在碰到的:
1、ITSM系统集成
事件管理流程集成;配置管理集成,自动CI获取,提高CMDB准确、实时性;知识库集成,提高知识库的可持续消费能力。
2、物联网设备监控
物联网设备底层基于Linux,可监控主要运行参数,提升为物联网监控。
3、视频监控集成
集成视频监控等社会监控资源,实现政府管理部署的应急指挥中心。
随着信息技术的不断更迭,以及监控本身广度和深度且的动态变化,Zabbix二次开发做起来无止境,计划赶不上变化,我们大概的规划如下:
增加监控对象的可视化,对标MIUI,提高监控界面的可视化、人性化、专业化;
提高各个组件对象的监控能力,持续提高深度和广度;
基于业务地图的故障回放;
简化迭代,开放社区版本;
自动化运维,基于业务地图的自动化;
自动化、智能化告警收敛;
运维大数据、AI,增强与更多成熟产品的集成经验。
做监控是一条不归路,做运维也是一条不归路,做产品、做企业更是一条不路,漫漫人生长路,与诸君共勉!
【问题1】用Zabbix怎么监控IBM的power服务器(硬件方面的)?
答:硬件监控,ipmi 和SNMP,带外管理口集成。
追问:ipmi获取数据有时候回拉不到是什么情况?
答:ipmi的监控在Zabbix低版本时的确轮询很差,有存在这个问题,Zabbix在升级版本中也一直对这块做了优化,建议尽量用高版本的Zabbix。
追问:ipmi 监控IBM服务器硬件的时候经常获取不到数据,监控效果很差。
答:是的,Zabbix的每个版本都有所优化,ipmi也有相应的配置参数,相对调整也可以加快轮询。
【问题2】业务监控怎么做的?
答:我们是分两层做的,一个业务本身可用性监控,一个是依赖监控,然后建立关系。
追问:业务数据怎么做?
答:业务数据需要单独做,我们通常是独立做一个应用再与我们的平台集成,集成主要在显示层。
【问题3】Oracle的监控,能详细说说吗?
答:我们让DBA独立写的监控脚本,放弃了orabbix。
【问题4】Zabbix案例中最多监控多少设备、实施?
答:看item。
【问题5】你们代码开源了吗?
答:我们研发了很久,投入很大,代码暂时不开源,计划明年开放一部分功能。
【问题6】老师你好,能讲讲Zabbix对Docker容器的监控方案吗?
答:
基本:运行状态数量、统计数量、版本、暂停状态数量、停止状态数量。
自动发现:IO读写操作字节数、容器状态、CPU使用率百分比、磁盘使用、内存限制值、内存使用率、网络收发字节、总缓存、交换分区、运行时间等等。
【问题7】Zabbix server作为监控处理中心,怎么做高可用?
答:WEB层、DB层、Proxy,层层实现,建议做一层冷备。
【问题8】请问,如何做预警?
答:3.0以上就已经有这个功能了,通过类似Forecast这样的函数实现。
追问:这些一般函数效果一般,有没有更好的办法?
答:原生的只要这些,可以结合多种表达式做优化。
【问题9】监控触发报警的阀值,能根据历史采样数据做到动态设置吗?
答:现在还不行,trigger还是静态的,需要做二次开发。
【问题10】如何把不同的磁盘分区报警发给不同的人,如WebLogic分区告警发给中间件管理员,Oracle分区报警发给数据库管理员?
答:通过告警和报表订阅实现,Zabbix原生还没有。
【问题11】容器上跑Zabbix-server的坑能讲讲吗?
答:我们2015年用Docker跑过,发现了一些问题,比如说JDBC当时没有提供,监控不了数据库,最近的版本还没有尝试。
【问题12】Zabbix-server的高可用,一般用什么组件实现?ZooKeeper?Keepalive?还是其它的?
答:我们用Keepalive。
【问题13】文中提到IBM的小机的带外管理口是指HMC管理口吗?
答:是的,拿Zabbix监控硬件需要掌握原厂的MIB库。
【问题14】请介绍下如何做告警收敛?
答:我们做了管理上的收敛,Zabbix原生可以配置告警依赖,另外触发器事件模式配置单重等,计划未来在实践不尝试去做告警的智能收敛,这个步骤我们会相对谨慎,宁可适当多发,也不漏发,避免影响监控的覆盖率和准确率。
追问:监控触发报警的阀值,能根据历史采样数据做到动态设置吗,有结合一些数据挖掘算法的案例吗?
答:需要二次开发。
【问题15】Zabbix和自动化部署工具,如Salt集成有这方面的经验吗?
答:做过一些测试,使用salt自动部署需要解决的问题。
rpm包的打包(这个问题不大,官方有提供)
rpm 安装(pkg模块)
配置文件调整(file模块)
服务自启动(service)
配置文件的适配(使用salt的pillar实现)
基本上涉及salt的pkg(包管理模块)、file(文件管理模块)、service(服务管理模块)、pillar模块这四个模块。
【问题16】Zabbix的版本升级有没有坑?
答:按官方提示操作,逐渐升级版本。不建议跨版本升级,因为版本间可能有表字段的变更,版本跨越太大可能导致系统无法运行;如果非要跨版本升级的话,建议将主机和模板导出,部署完再做导入;如果不是研究的话,版本升级不建议太激进。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721