
本文经平台同意授权转载
来源:论码农的自我修养 订阅号(ID:bit_tiger)
Facebook从成立之初作为一个小型区域型社交网站,到如今演变成为全球最大的社交网站,架构经历过几次重大的迭代。其中,Facebook的存储也从小变大,从单一变得更具有多样性,从而应对各种拓展性问题。
本文将首先从Facebook的升级转变开始,谈到数据存储能力提升对于公司Scalability的巨大影响,然后介绍Facebook在Canssandra和HBase之间的选择,从而引申出NoSQL将要解决的问题领域,最后集中介绍了NoSQL Pattern的基本组成。希望看完本文之后,大家可以对NoSQL要解决的问题,NoSQL的基本构成,以及NoSQL对于Facebook这样大型公司的重要性有一定的认识。
对于Facebook在数据处理能力上的进化,可以先列几个文章标题来直观感受一下:
New Facebook Chat Feature Scales To 70 Million Users Using Erlang, May 14, 2008.
Facebook's New Realtime Messaging System: HBase to Store 135+Billion Messages a Month Nov 16, 2010.
Facebook's New Realtime Analytics System: HBase to Process 20 Billion Events Per Day Mar 22, 2011
第一篇文章是和Chat功能相关,主要是讲通过选用Erlang来增加Server端的处理能力。后两篇讲的都是如何高效、稳定的存储大量数据来为Facebook的其他application服务。而其中反复出现的关键词——Canssandra,HBase,就是解决Facebook面对大量数据时Scale的基础。
如果比较Canssandra和HBase(可参考http://bit.ly/2akMsKo)以及他们的共同特点,就可以发现他们非常适合解决以下Scalability问题:
如何实现应用层“无状态”? 为了让应用层可拓展,需要分离数据层,就要让应用层处于“无状态”,也就是应用层不因为数据层的影响
数据层如何延伸? 这是包括Facebook很多公司公司都要面临的问题
如何将合适地划分数据在不同机器上,实现负载平衡
数据在多个机器上,如何处理机器坏掉的情况?
如何在机器之间备份数据?
在数据备份的时候,如何保持同步呢?
如何结合云计算,实现服务器数量的自动延伸? 也就是,任务量大的时候,就增加机器数量,任务量少的时候,就减少机器数量。
因为机器数量可变,当任务量变化导致机器数量变化的时候,又如何重新分配数据呢?
为了解决这些Scalability问题,NoSQL出现了,它成了一种解决大型数据存储问题的常用方案,Canssandra 和 HBase就是根据NoSQL概念而开发出来的具体产品。
于是,我们想要了解Facebook的架构知识,就细化成了了解Facebook如何处理大型数据,再而变成为Canssandra和Hbase如何处理数据,然后变成为:NoSQL通常意义上是如何解决Scalable数据存储问题的!
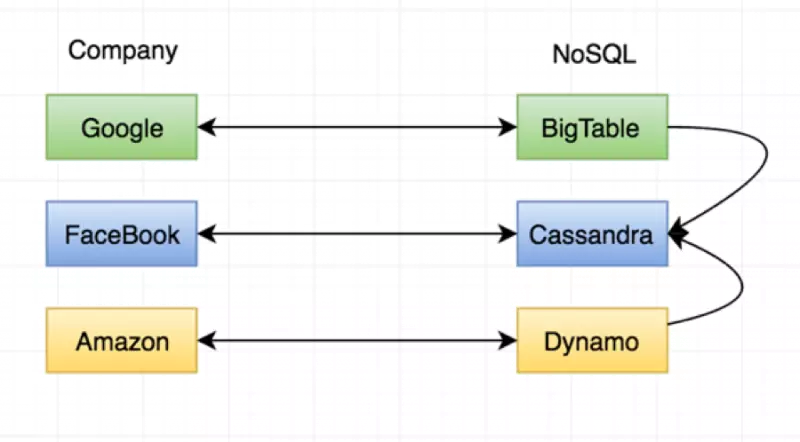
上面是三大巨头相对应的NoSQL解决方案,Google的Bigtable,还有Amazon的Dynamo可以参考这篇文章(http://bit.ly/29SEee6)。 Canssandra 是移植了Dynamo的分布式设计,加上BigTable的数据模型而开发出来的。
这三种产品的共同点是:
键-值存储
大量廉价主机上运行
数据在这些主机之间以划分和备份的形式存储(也就是Partition和Replica)
相对较弱的一致性要求(关于一致性的概念可以参考这个剪短说明:http://bit.ly/29SFPR0)
NoSQL的结构和主要技术构成由下图可以表示:
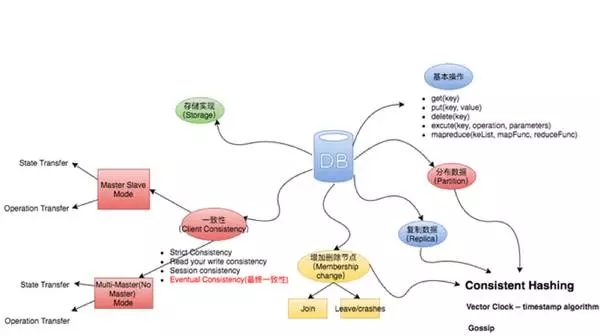
A. API Model (DB操作)
对于数据库的常见操作:读、写、修改。
B. NoSQL底层架构
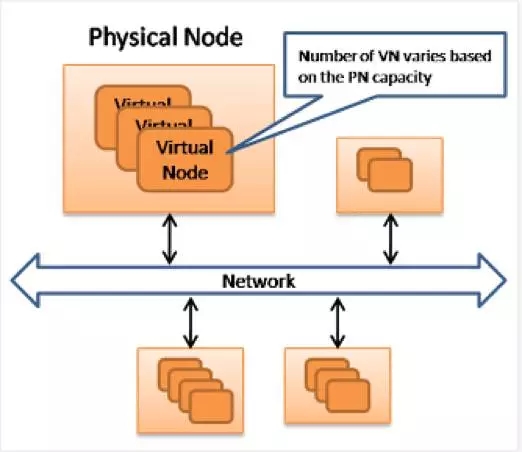
底层架构由上百或上千台计算机组成,每个计算机是一个物理节点(Physical Node),这些物理节点的configuration,CPU, 硬盘大小都不尽相同。在每一个物理节点上,又可以分成若干个虚拟节点(Virtual Node):
C. Partition
因为整体的hashtable是要分布在VNs 上的,所以需要找到一个方法,把key和相应的VN结合起来。
(1)partition = key mod (total_VN)
这样的缺点在于,如果VN的数量改变的话,会引起大量现存的key map改变,从而所有的数据重新分布,这样效率显然非常低。
(2)Consistent Hashing
这里的Key Space是有限大小的,一般是将0到2^32-1数字头尾相连,就结合成一个闭合的环形。将VN映射到环中,以顺时针的方向计算,key的归属节点是它遇到的第一个节点。
所以只有在相邻节点崩溃的情况下,数据才会重新分布,其他所有key依然存在各自的VN之中。
D. 数据复制(Replica)
复制数据的好处:
提升可靠性能
将工作量分散到有相同备份的其他节点上面(balance workload)
E. Node的变化(Membership Changes)
为了可以根据workload增删节点,使资源利用效率最大,或者是因为节点错误而导致crash,这些情况下都需要根据Consitent hashing来设计相应的节点处理办法。
(1)新加入一个节点
将新节点存在向其他节点传播;
左右相邻节点开始同步地改变各自keys,replicas;
新加入节点开始从相邻节点copy data;
新加入的节点信息开始传播到其他节点;
Case1:如果在节点新加入的时候,远离这个node的其他node的membership view还没有更新,所以在这个时候,request还是会指向old node;但是因为new node的相邻节点信息已经更新,他们会将request指向new node。
Case2:如果新加入节点还处于data的更新状态中,还没有准备处理request;就需要用到vector clock来表明自身状态,client就会去访问其他replica。
(2) 节点离开或者崩溃
Crashed node不会再回应neighbors’的gossip 信息。
Neighbor会更新membership信息,并开始asynchronously copy crashed node data。

上面涉及到的节点都是VN,虚拟节点。在实际中还要将VN和PN联系起来。分配VN的时候,原则是尽量避免VN 的 replicas存在相同的PN上面。最简单的实现方式就是,将VN随机分配到PN上面,只要确保PN上不含有相同key range的VN即可。
当PN崩溃的时候,多个VN都会同时崩溃,但是因为VN的replicas随机分布在不同PN上面,这样因为crash引起的workload就会分布到多个PN上面。
F. Client Consistency(一致性)
当有了数据的很多备份之后,需要关心的问题就是如何在机器之间同步让用户有一个consistent view of the data。
一致性模型有:
Strict Consistency(one copy serializability)。
Read your write consistency: 用户可以立马看到自己的update,但无法看到其他用 户的更新。
Session Consistency: 当用户的request处于一个session scope(一个server)上时,提供read your write consistency。
Monotonic read consistency: 保证用户只会看到最新更新的data。
Eventual Consistency:(最终一致性)在更新进行中时,用户会看到不一致的update。这个model的使用情况是,对一个数据的concurrent修改基本不会发生,用户需要等一段时间才能看到之前的update。
在确定Consistency Model之后,NoSQL大部分的底层构建就已经完成。有了硬件部分,有了硬件之间抽象的架构,可是在具体使用中,还需要给出数据流动的方法。
要根据具体情况来选择如何实现下面两个问题:
用户的request如何到达replicas(副本)
副本之间如何传播update
Master Slave Model(Single Master)
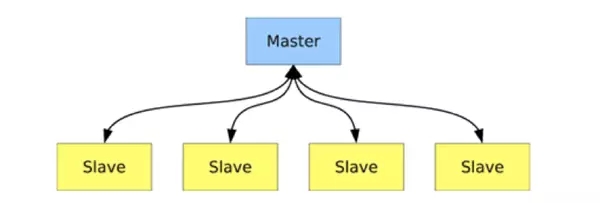
每一个PN都会有一些VN作为分布的master,而其他VN作为slaves。
所有的请求都会经过Master来处理。假如Master在data 更新的传输过程中crash的话,有可能造成数据丢失。当Master crashed之后,最新更新的slave(VN)会被提升为新的master。
读操作可以分到各个replicas上面。
Single Master Model适用于有很多read操作的app;当update操作是平均分布在key range之内时,这个模型也可以胜任。
然而假如在键的范围内之内,有一块区域十分流行导致有很多次的write操作的话,这个model就无法将workload平均分配。针对这种情况,就要引入新的model。
Multi-Master Model(No Master)
没有master的情况下,如何保证consistency呢?一种方法是,用传统的2PC protocol,在每次update的时候,将所有副本的状态都更新一次。在这种方法中,需要有一个coordinator来沟通各个副本,询问每个副本是否ready,如果ready,coordinator需要命令所有副本执行commit操作,副本在完成操作之后要将结果写入log file。
上面这种更新所有副本的方法,最大的问题是,coordinator没有scalability,它需要在等待各个副本确认状态之后才能进行下一步指令,会经历大量的网络roundtrip以及disk I/O的延迟。如果有一个副本失败的话,更新就失败。当有大量机器存在的时候,这种情况会经常发生。
更高效的方式就是用Quorum Based 2PC(PAXOS)
在这种model中,coordinator只需要更新W个副本(而不是全部的N个),coordinator依然可以向所有N个副本写操作,只要得到任意W个副本回复确认即可。从概率的角度上,这样的方式更有效率。
因为不是所有的副本都被更新(W),所以在读取数据的时候,不是读取一个副本,而是要读取R个,然后选取其中timestamp最新的那个。

Quorum Based 2PC 当W=N, R=1的时候,就变成了传统的2PC更新方式。而W和R的参数选择,则取决于设计者对一致性的要求程度。
而在read操作中,如何得到副本的timestamp信息,以及如何比较timestamp,就需要用到vector clock 这个技术了。
Gossip
如果用户可以接受更加弱的一致性的话,除了Quorum Based 2PC之外,还可以使用Gossip 这种protocol来在各个replicas之间传递信息。
它常用于P2P的通信协议,这个协议就是模拟人类中传播谣言的行为而来。简单的描述下这个协议,首先要传播谣言就要有种子节点。种子节点每秒都会随机向其他节点发送自己所拥有的节点列表,以及需要传播的消息。任何新加入的节点,就在这种传播方式下很快地被全网所知道。这个协议的神奇就在于它从设计开始就没想到信息一定要传递给所有的节点,但是随着时间的增长,在最终的某一时刻,全网会得到相同的信息。

G. 存储的具体实现
一种实现方式是让数据的存储pluggable,MySQL,Filesystem,或者一个巨大的Hashtable都可以用作存储的机制。
另一种方式是,采用高可扩展性的存储。具体的细节可以继续阅读CouchDB 还有 Google BigTable 的相关文献,在这里就简单介绍一个在实现存储中用到的技术。
Copy-on-modifed approach:
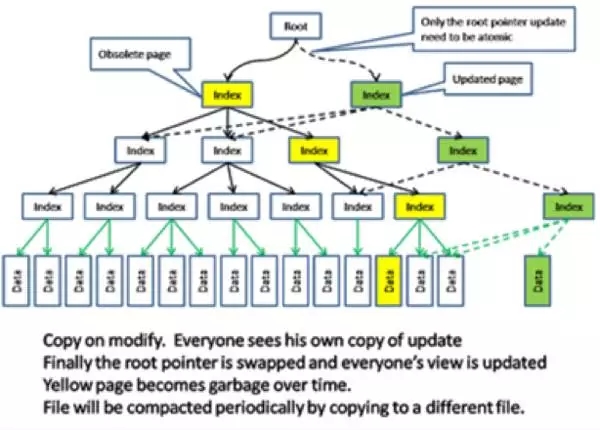
任何一个更新都会产生一个备份,进而影响其索引导致索引被修改后然后索引也会产生一个备份,这样一直往复下去直到根索引。
其实NoSQL的概念很大,不是所有RDBMS的存储系统都可以叫做NoSQL。上面介绍的NoSQL主要是为了应对Scalability而产生的一种解决方案。在阅读完这篇文章之后,对于如何解决2中的问题,也就有了方法和步骤:
Partition Data,将data存在不同的机器上,balance work load(consistent hashing)
万一其中有机器坏掉怎么办?how to handle failure(copy to neighbors)
如何在机器之间备份数据,做replica(Master or NoMaster model)
在数据备份的时候,如何保持同步呢?Synchronization(PAXOS, Gossip)
因为机器数量可变,当任务量变化导致机器数量变化的时候,又如何重新分配数据呢(VN的加入和离开)
以上就是NoSQL的一些基本概念,在掌握这些之后,阅读Dynamo或Canssandra时,就会更有方向感,也就会明白这种技术为什么对于像Facebook这样大型公司的成功至关重要了。
参考资料:
http://horicky.blogspot.com/2009/11/nosql-patterns.html
http://horicky.blogspot.com/2010/10/bigtable-model-with-cassandra-and-hbase.html
http://www.oracle.com/technetwork/cn/articles/cloudcomp/berkeleydb-nosql-323570-zhs.html
https://www.quora.com/What-is-the-difference-between-gossip-and-Paxos-protocols
http://blog.csdn.net/cloudresearch/article/details/23127985
https://www.quora.com/Why-use-Vector-Clocks-in-a-distributed-database
技术分享:[线上1-50期] [北京站] [上海站] [广州站] [杭州站] [济南站] [Gdevops杭州站] [Gdevops北京站] [DAMS 2016]
专家专栏:[杨志洪] [杨建荣] [陈能技] [丁俊] [卢钧轶] [李海翔] [魏兴华] [邹德裕] [周正中] [高强] [白鳝] [卢飞] [王佩]
热门话题:[Oracle] [MySQL] [DB2] [大数据] [PostgreSQL] [云计算] [DevOps] [职场心路] [其他]
近期活动:
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721