
作者介绍
林堂辉,哔哩哔哩资深开发工程师,2016年加入B站,作为核心开发亲历了B站从单体架构到微服务的架构改造,后续又负责消息队列、服务发现、数据传输等微服务中间件的开发。目前负责NoSQL存储,从零到一搭建了分布式KV存储系统,为全站业务提供了高性能稳定可靠的存储服务。
业务高速发展,B站的存储系统如何演进以支撑指数增长的流量洪峰?随着流量进一步暴增,如何设计一套稳定可靠易拓展的系统,来满足未来进一步增长的业务诉求?同时,面对更高的可用性诉求,KV是如何通过异地多活为应用提供更高的可用性保障?文章的最后,会介绍一些典型业务在KV存储的应用实践。
全文将围绕下面4点展开:
一、存储演进
二、设计实现
三、场景&问题
四、总结思考
一、存储演进
首先介绍一下B站早期的存储演进。

针对不同的场景,早期的KV存储包括Redix/Memcache,Redis+MySQL,HBASE。
但是随着B站数据量的高速增长,这种存储选型会面临一些问题:
首先,MySQL是单机存储,一些场景数据量已经超过 10 T,单机无法放下。当时也考虑了使用TiDB,TiDB是一种关系型数据库,对于播放历史这种没有强关系的数据并不适合。
其次,是Redis Cluster的规模瓶颈,因为redis采用的是Gossip协议来通信传递信息,集群规模越大,节点间的通信开销越大,并且节点之间状态不一致的存留时间也会越长,很难再进行横向扩展。
另外,HBase存在严重长尾和缓存内存成本高的问题。
基于这些问题,我们对KV存储提出了如下要求:
易拓展:100x横向扩容;
高性能:低延时,高QPS;
高可用:长尾稳定,故障自愈;
低成本:对比缓存;
高可靠:数据不丢。
二、设计实现
接下来介绍我们是如何基于上述要求进行具体实现的。
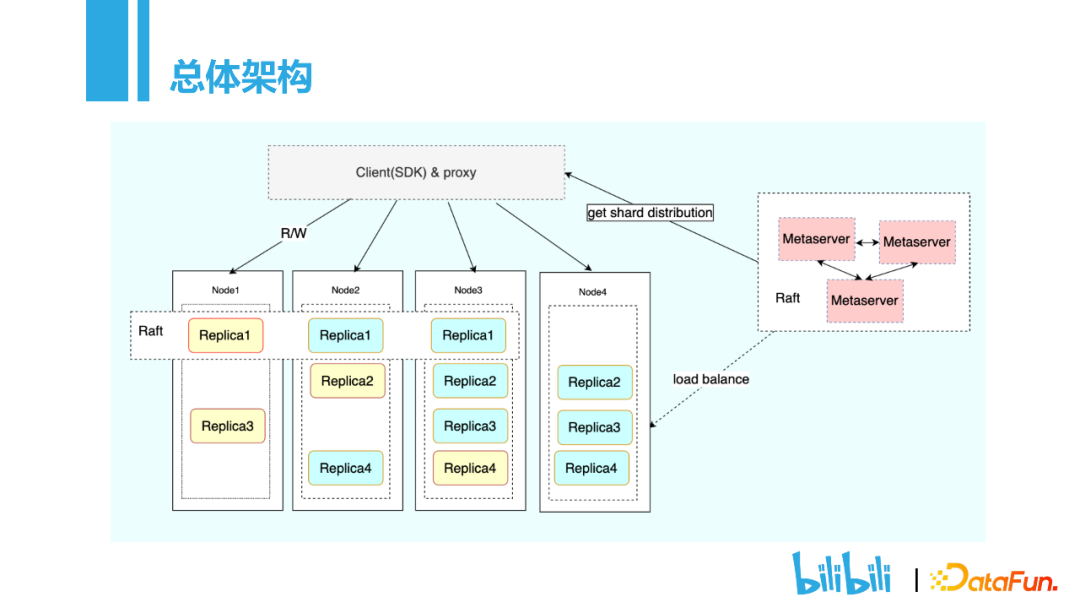
总体架构共分为三个部分Client,Node,Metaserver。Client是用户接入端,确定了用户的接入方式,用户可以采用SDK的方式进行接入。Metaserver主要是存储表的元数据信息,表分为了哪些分片,这些分片位于哪些node之上。用户在读写操作的时候,只需要put、get方法,无需关注分布式实现的技术细节。Node的核心点就是Replica,每一张表会有多个分片,而每个分片会有多个Replica副本,通过Raft实现副本之间的同步复制,保证高可用。
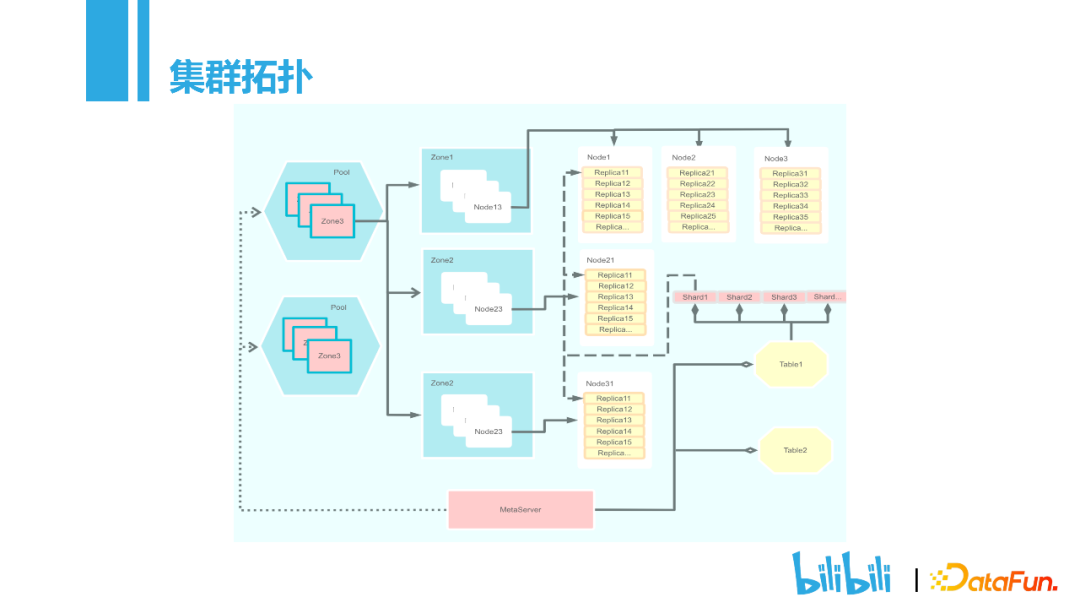
Pool:资源池。根据不同的业务划分,分为在线资源池和离线资源池。
Zone:可用区。主要用于故障隔离,保证每个切片的副本分布在不同的zone。
Node:存储节点,可包含多个磁盘,存储着Replica。
Shard:一张表数据量过大的时候可以拆分为多个Shard。拆分策略有Range,Hash。
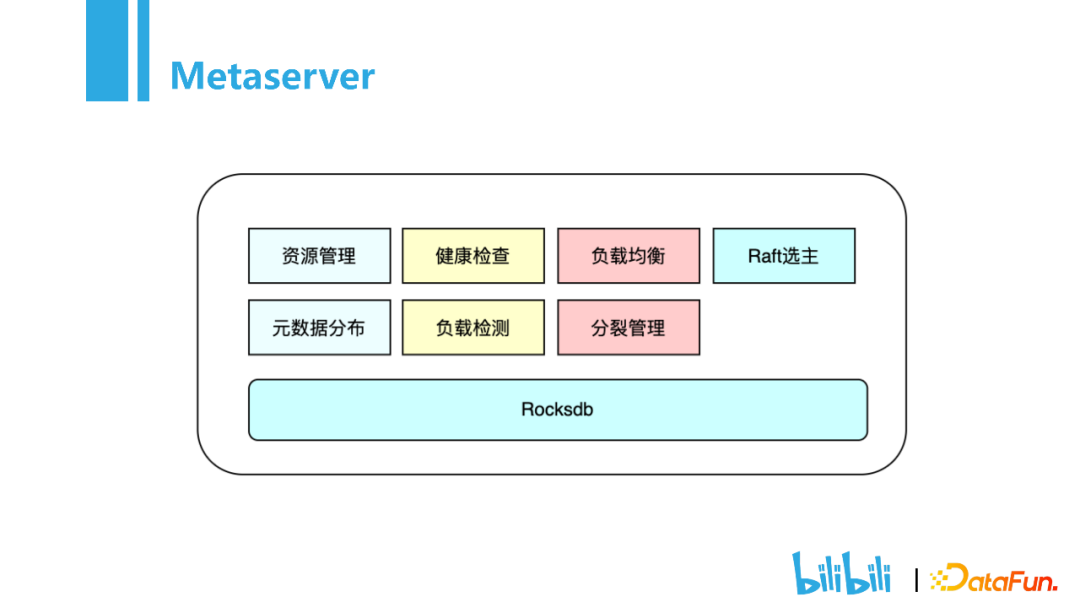
资源管理:主要记录集群的资源信息,包括有哪些资源池,可用区,多少个节点。当创建表的时候,每个分片都会记录这样的映射关系。
元数据分布:记录分片位于哪台节点之上。
健康检查:注册所有的node信息,检查当前node是否正常,是否有磁盘损坏。基于这些信息可以做到故障自愈。
负载检测:记录磁盘使用率,CPU使用率,内存使用率。
负载均衡:设置阈值,当达到阈值时会进行数据的重新分配。
分裂管理:数据量增大时,进行横向扩展。
Raft选主:当有一个Metaserver挂掉的时候,可进行故障自愈。
Rocksdb:元数据信息持久化存储。
作为存储模块,主要包含后台线程,RPC接入,抽象引擎层三个部分。
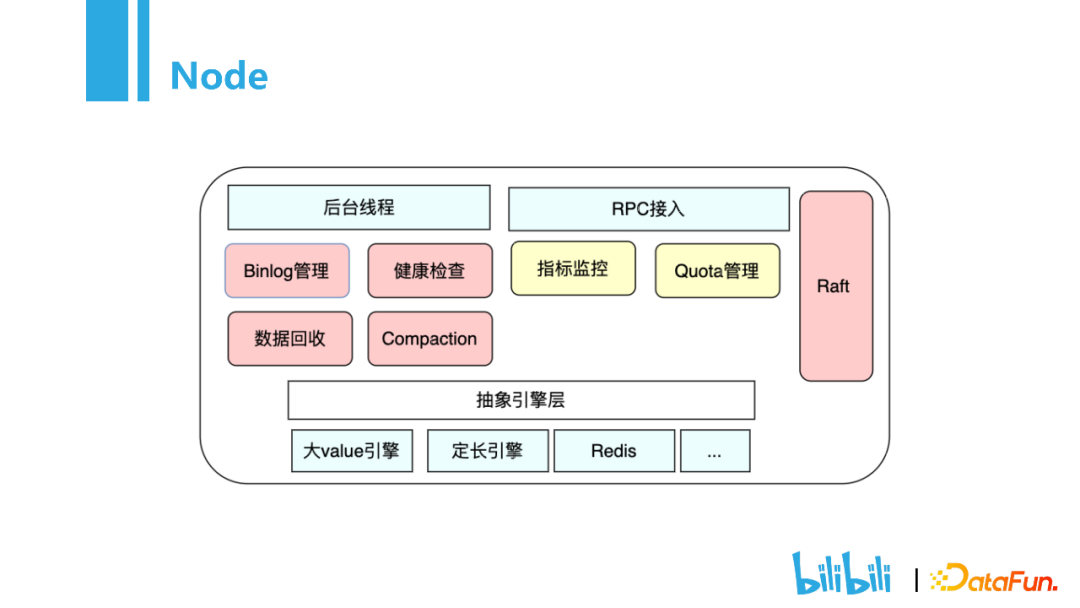
1)后台线程
Binlog管理,当用户进行写操作的时候,会记录一条binlog日志,当发生故障的时候可以对数据进行恢复。因为本地的存储空间有限,所以Binlog管理会将一些冷数据存放在S3,热门的数据存放在本地。数据回收功能主要是用来防止误删数据。当用户进行删除操作,并不会真正的把数据删除,通常是设置一个时间,比如一天,一天之后数据才会被回收。如果是误删数据,就可以使用数据回收模块对数据进行恢复。健康检查会检查节点的健康状态,比如磁盘信息,内存是否异常,再上报给Metaserver。Compaction模块主要是用来数据回收管理。存储引擎Rocksdb,以LSM实现,其特点在于写入时是append only的形式。
2)RPC接入
当集群达到一定规模后,如果没有自动化运维,那么人工运维的成本是很高的。所以在RPC模块加入了指标监控,包括QPS、吞吐量、延时时间等,当出现问题时,会很方便排查。不同的业务的吞吐量是不同的,如何做到多用户隔离?通过Quota管理,在业务接入的时候会申请配额,比如一张表申请了10K的QPS,当超过这个值得时候,会对用户进行限流。不同的业务等级,会进行不同的Quota管理。
3)抽象引擎层
主要是为了应对不同的业务场景。比如大value引擎,因为LSM存在写放大的问题,如果数据的value特别大,频繁的写入会导致数据的有效写入非常低。这些不同的引擎对于上层来说是透明的,在运行时通过选择不同的参数就可以了。
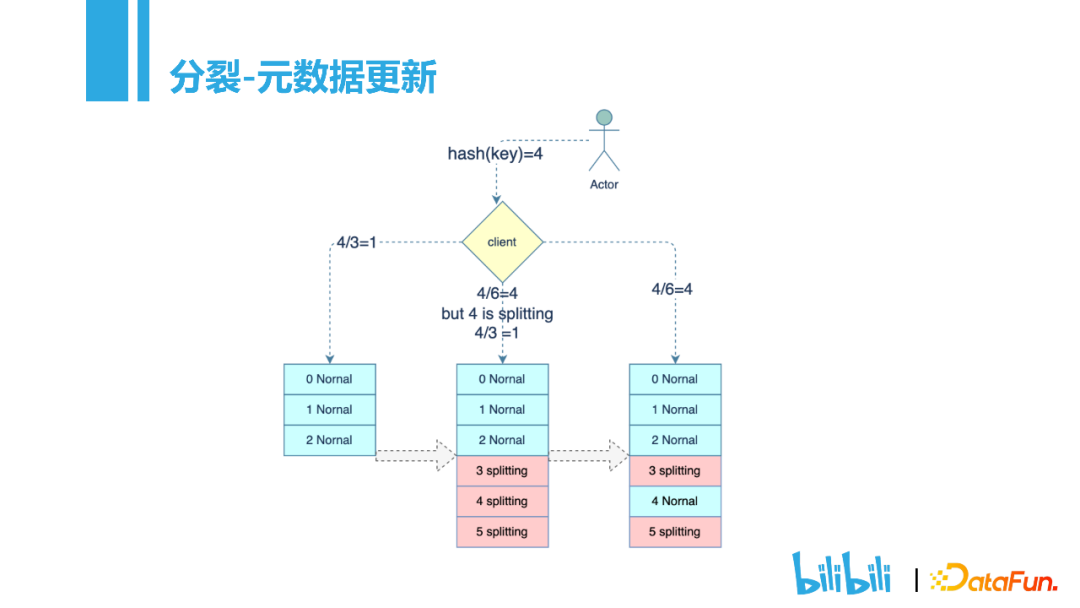
在KV存储的时候,刚开始会根据业务规模划分不同的分片,默认情况下单个分片是24G的大小。随着业务数据量的增长,单个分片的数据放不下,就会对数据进行分裂。分裂的方式有两种,rang和hash。这里我们以hash为例展开介绍:
假设一张表最开始设计了3个分片,当数据4到来,根据hash取余,应该保存在分片1中。随着数据的增长,3个分片放不下,则需要进行分裂,3个分片会分裂成6个分片。这个时候数据4来访问,根据Hash会分配到分片4,如果分片4正处于分裂状态,Metaserver会对访问进行重定向,还是访问到原来的分片1。当分片完成,状态变为normal,就可以正常接收访问,这一过程,用户是无感知的。
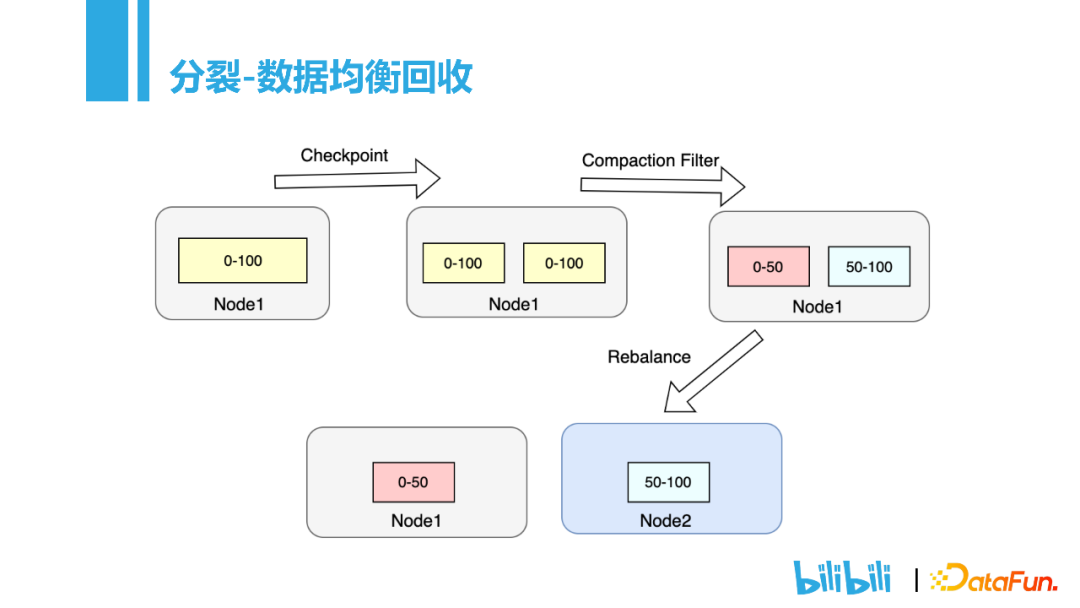
首先需要先将数据分裂,可以理解为本地做一个checkpoint,Rocksdb的checkpoint相当于是做了一个硬链接,通常1ms就可以完成数据的分裂。分裂完成后,Metaserver会同步更新元数据信息,比如0-100的数据,分裂之后,分片1的50-100的数据其实是不需要的,就可以通过Compaction Filter对数据进行回收。最后将分裂后的数据分配到不同的节点上。因为整个过程都是对一批数据进行操作,而不是像redis那样主从复制的时候一条一条复制,得益于这样的实现,整个分裂过程都在毫秒级别。
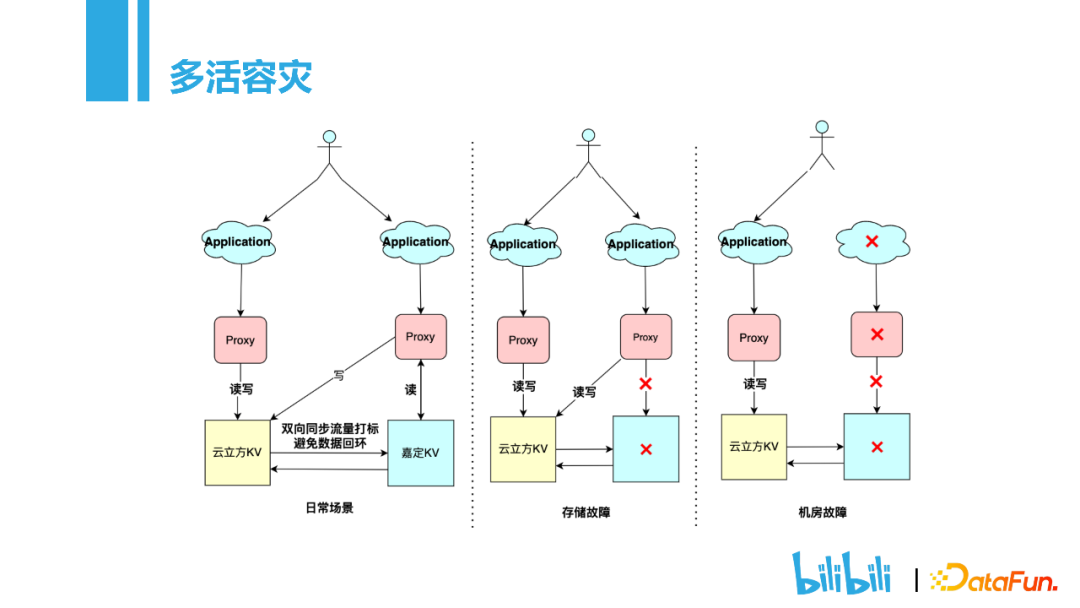
前面提到的分裂和Metaserver来保证高可用,对某些场景仍不能满足需求。比如整个机房的集群挂掉,这在业界多是采用多活来解决。我们KV存储的多活也是基于Binlog来实现,比如在云立方的机房写入一条数据,会通过Binlog同步到嘉定的机房。假如位于嘉定的机房的存储部分挂了以后,proxy模块会自动将流量切到云立方的机房进行读写操作。最极端的情况,整个机房挂掉了,就会将所有的用户访问集中到里一个机房,保证可用性。
三、场景&问题
接下来介绍KV在B站应用的典型场景以及遇到的问题。

最典型的场景就是用户画像,比如推荐,就是通过用户画像来完成的。其他还有动态、追番、对象存储、弹幕等都是通过KV来存储。

基于抽象实现,可以很方便地支持不同的业务场景,并对一些特定的业务场景进行优化。
Bulkload全量导入的场景主要是用于动态推荐以及用户画像。用户画像主要是T+1的数据,在没有使用Bulkload以前,主要是通过Hive来逐条写入,数据链路很长,每天全量导入10亿条数据大概需要6、7个小时。使用Bulkload之后,只需要在hive离线平台把数据构建成一个rocksdb引擎,hive离线平台再把数据上传到对象存储。上传完成之后通知KV来进行拉取,拉取完成后就可以进行本地的Bulkload,时间可以缩短到10分钟以内。
另一个场景就是定长list。大家可能发现你的播放历史只有3000条,动态也只有3000条。因为历史记录是非常大的,不能无限存储。最早是通过一个脚本,对历史数据进行删除,为了解决这个问题,我们开发了一个定制化引擎,保存一个定长的list,用户只需要往里面写入,当超过定长的长度时,引擎会自动删除。
前面提到的compaction,在实际使用的过程中,也碰到了一些问题,主要是存储引擎和raft方面的问题。存储引擎方面主要是Rocksdb的问题。第一个就是数据淘汰,在数据写入的时候,会通过不同的Compaction往下推。我们的播放历史,会设置一个过期时间。超过了过期时间之后,假设数据现在位于L3层,在L3层没满的时候是不会触发Compaction的,数据也不会被删除。为了解决这个问题,我们就设置了一个定期的Compaction,在Compaction的时候回去检查这个Key是否过期,过期的话就会把这条数据删除。
另一个问题就是DEL导致SCAN慢查询的问题。因为LSM进行delete的时候要一条一条地扫,有很多key。比如20-40之间的key被删掉了,但是LSM删除数据的时候不会真正地进行物理删除,而是做一个delete的标识。删除之后做SCAN,会读到很多的脏数据,要把这些脏数据过滤掉,当delete非常多的时候,会导致SCAN非常慢。为了解决这个问题,主要用了两个方案。第一个就是设置删除阈值,超过阈值的时候,会强制触发Compaction,把这些delete标识的数据删除掉。但是这样也会产生写放大的问题,比如有L1层的数据进行了删除,删除的时候会触发一个Compaction,L1的文件会带上一整层的L2文件进行Compaction,这样会带来非常大的写放大的问题。为了解决写放大,我们加入了一个延时删除,在SCAN的时候,会统计一个指标,记录当前删除的数据占所有数据的比例,根据这个反馈值去触发Compaction。
第三个是大Value写入放大的问题,目前业内的解决办法都是通过KV存储分离来实现的。我们也是这样解决的。

Raft层面的问题有两个:
首先,我们的Raft是三副本,在一个副本挂掉的情况下,另外两个副本可以提供服务。但是在极端情况下,超过半数的副本挂掉,虽然概率很低,但是我们还是做了一些操作,在故障发生的时候,缩短系统恢复的时间。我们采用的方法就是降副本,比如三个副本挂了两个,会通过后台的一个脚本将集群自动降为单副本模式,这样依然可以正常提供服务。同时会在后台启动一个进程对副本进行恢复,恢复完成后重新设置为多副本模式,大大缩短了故障恢复时间。
另一个是日志刷盘问题。比如点赞、动态的场景,value其实非常小,但是吞吐量非常高,这种场景会带来很严重的写放大问题。我们用磁盘,默认都是4k写盘,如果每次的value都是几十个字节,这样会造成很大的磁盘浪费。基于这样的问题,我们会做一个聚合刷盘,首先会设置一个阈值,当写入多少条,或者写入量超过多少k,进行批量刷盘,这个批量刷盘可以使吞吐量提升2~3倍。
四、总结思考

应用方面,我们会做KV与缓存的融合。因为业务开发不太了解KV与缓存资源的情况,融合之后就不需要再去考虑是使用KV还是缓存。
另一个应用方面的改进是支持Sentinel模式,进一步降低副本成本。
运维方面,一个问题就是慢节点检测,我们可以检测到故障节点,但是慢节点怎么检测呢,目前在业界也是一个难题,也是我们今后要努力的方向。
另一个问题就是自动剔盘均衡,磁盘发生故障后,目前的方法是第二天看一些报警事项,再人工操作一下。我们希望做成一个自动化机制。
系统层面就是SPDK、DPDK方面的性能优化,通过这些优化,进一步提升KV进程的吞吐。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721