

分享概要
一、关于架构思路和一些概念边界
二、从单机和数据维度推导架构策略
三、架构演进和案例分析
四、技术展望和小结
一、关于架构思路和一些概念边界

早期的数据库架构模式主要是单机模式。单机模式虽然也能满足我们早期一些业务需求,但是随着数据规模的扩大以及业务的快速增长,对单机数据库体系有了更高要求,从而延伸出以下几个发展方向:
2、概念边界
这些年来分布式数据库、云原生数据库的概念都很火热,同时分布式架构、微服务架构等在行业内也有大量的落地场景和最佳实践。我们通常所说的分布式数据库和数据库分布式架构还是有一定的区别的,但是又存在一定的关联,就好比如下的包含关系一样,是一种层级递进的关系。

3、通用架构能力
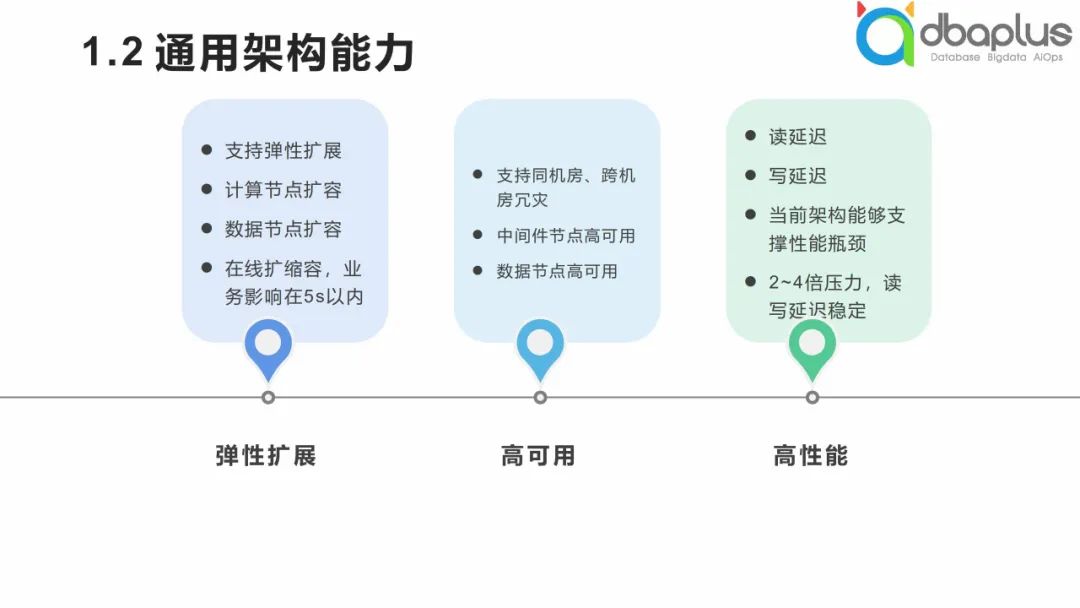
1)弹性扩展。原本的单机可能不够用,我们可以通过弹性扩展方式将原来的水平扩展演进为弹性扩展。
2)高可用。通过架构能力可以实现中间件节点高可用、数据节点高可用等整体的高可用。
3)高性能。架构能力可以在读写性能方面做到更高能力支撑。
二、从单机和数据维度推导架构策略
1、单机维度推导架构演进策略
单机模式下的分布式架构可以拆分为三个维度:系统配置、数据库配置和数据库相关服务管理。
1)系统配置
系统配置包括CPU、内存等,相对来说是一个固化的模式,对其进行扩展的难度较低,其成本也已经随着硬件的发展大幅度降低,简单来说,如果在成本可控范围内,花钱升级硬件就能解决。
2)数据库配置
数据库配置包括单库容量、单表容量、连接数和吞吐量等,其中单库容量扩展存在一定瓶颈。综合来看,对数据库配置做扩展会有些难度,但是这个时候有些复杂度,不是单纯升级硬件就能够解决的,比如我曾经管理过一张表,容量有1T,对于单机来说是需要相当谨慎的,这里的难度等级约为中等。
3)服务管理
服务管理包括负载管理、高可用管理、事务管理、运维管理等。在事务管理的复杂度方面,单机模式比分布式好一些。在管理模式上,单机模式使用了All In One模式,算是集中式管理,而分布式管理需要大量的自动化运维支撑。分布式管理在负载管理和高可用管理方面相比于单机管理有较大提升。在混合负载方面,原本的单机模式是整个服务的整体覆盖,但在分布式架构体系内要考虑整体负载能力的提升,不能因为单一节点的短板导致整个集群被拖垮,整体的难度相对较高。
2、数据维度推导架构演进策略
首先将数据分为以下三个维度:
1)流水型数据
流水型数据是无状态的,多笔业务之间没有关联,每次业务过来的时候都会产生新的单据,比如交易流水,支付流水,只要能插入新单据就能完成业务,特点是后面的数据不依赖前面的数据,所有的数据按时间流水进入数据库。
2)配置型数据
配置型数据即我们所说的配置中心字典,数据字典配置等。此类型数据数据量较小,而且结构简单,一般为静态数据,变化频率很低。
3)状态性数据
状态型数据是有状态的,多笔业务之间依赖于有状态的数据,而且要保证数据的准确性,例如账户余额,做充值时必须要拿到原来的余额才能支付成功,因此状态型数据整体的维护最复杂,是我们现在做分布式事务管理的核心部分。
基于以上数据类型分类我们可以延伸出三类表:字典表、日志表和状态表。
下面将对这三类表进行对比架构演进策略的解读。

① 数据量
字典表的数据量最小,日志表数据量极大,状态表的数据量大小与业务规模相关。
② 数据依赖
④ 架构策略
架构1.0策略
我们通常基于读写分离的模式对字典表做扩展改进。对于日志表,我们需要考虑提前做拆库、拆表,我们将这种模式称为周期表。对于状态表,我们可以通过读写分离的模式对读这部分的流量做缓解,但并不能从根本上解决问题。
架构2.0策略
对于字典表可以采用全局的分库分表方式。对日志表主要使用业务路由和数据库中间件。状态表相较于前两者更为复杂,其中一种方式是分库分表,另一种方式是基于分库分表模式做事务降维或整体的过程中直接做事务降维。事务降维包括两种方式,一种是在整个的过程中根据业务的特点不启用事务,另一种是在设计中将事务的维度或颗粒度降到最低,基于最小化的分片维度执行操作。
⑤ 系统优化策略
字典表的优化比较清晰,我们可以通过缓存模式进行优化,该方法可解决大部分问题。日志表在写入过程中,实时延迟不会很高,我们可以基于队列采用异步方式提升整个系统的吞吐量。状态表主要对读这部分的状态因数据做缓存。在系统优化策略维度,字典表和日志表比较容易进行优化,状态表的加工改造策略是重难点,而且整个过程中也无法彻底解决问题,对设计的整体要求也较高。
⑥ 建设目标
字典表适用于建设配置中心,日志表适用于建设账单存储平台,状态表适用于建设数据中台。
三、架构演进与案例分析

1、架构1.0阶段和案例
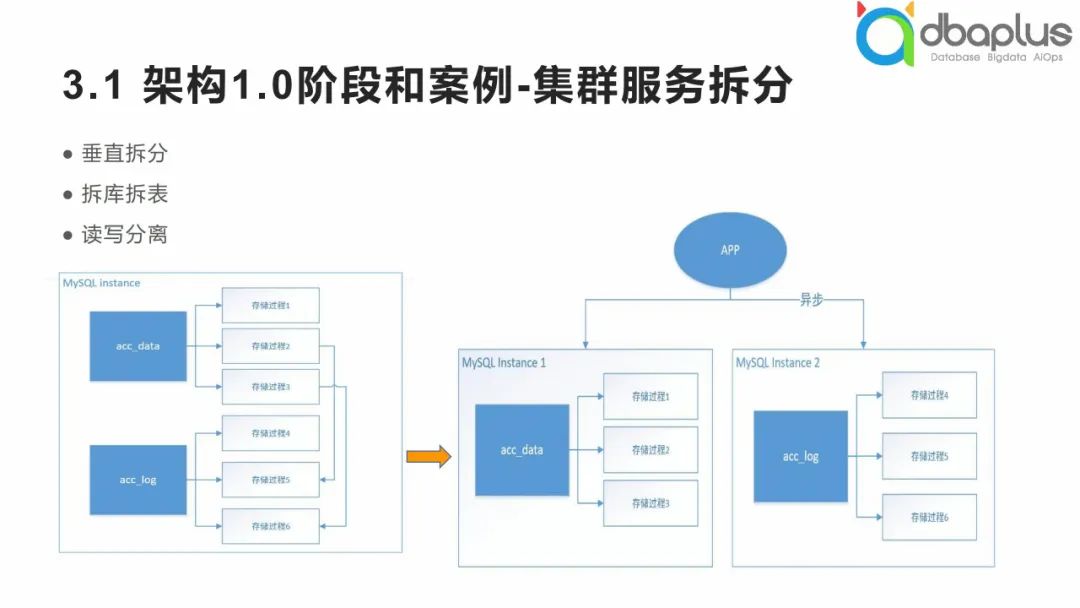
在这一阶段,我们采用了拆库拆表的方式将商业数据库迁移到MySQL中。原本我们可能处于单机模式,在整个单机模式下,我们通过拆库拆表方式将业务拆分到两个相对独立的服务器上,再实现日志数据的异步写入。对于状态型数据,我们可以做读写分离的改进。
在1.0阶段,我们通过拆分隔离将业务进行拆分,包括两种拆分方式:
1)将大的状态型业务拆分为两部分,一部分为全局型业务,另一部分为特定某个去向的业务。例如游戏公司有20款游戏,我们将这些游戏的公共属性数据拆分出来在平台层重组,再针对不同游戏的独特属性数据进行扩展。
2)在单机模式下将日志型数据和状态型数据进行拆分。日志型数据拆分难度较低,通过数据库中间件即可实现。拆分日志型数据的过程中,面对大量读的要求可以通过一主多从的方式进行读写分离的改进。
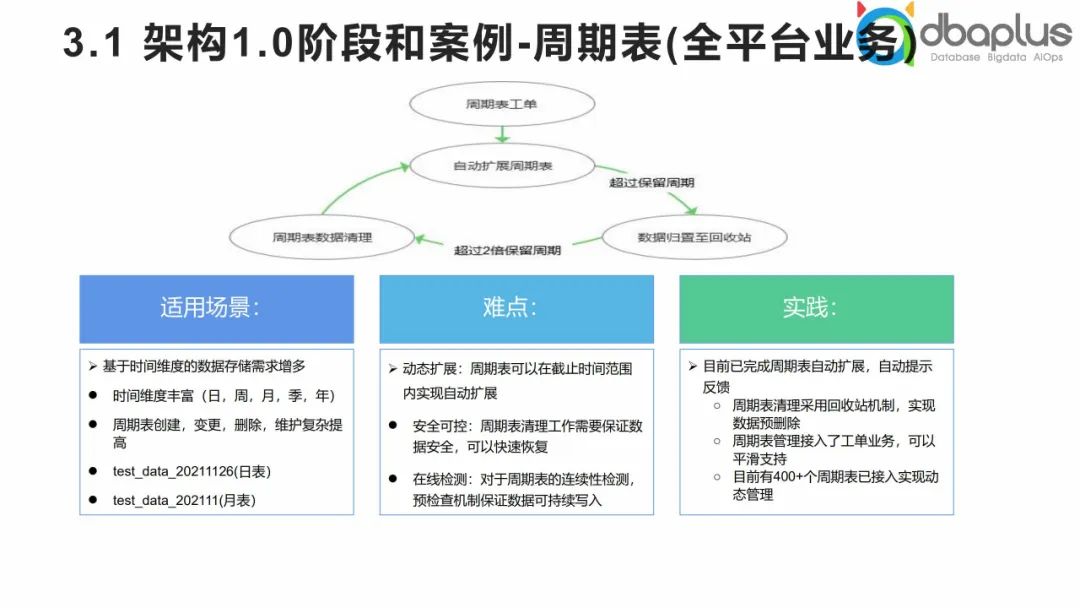
2、架构2.0演进和案例
1)消息业务路由改造
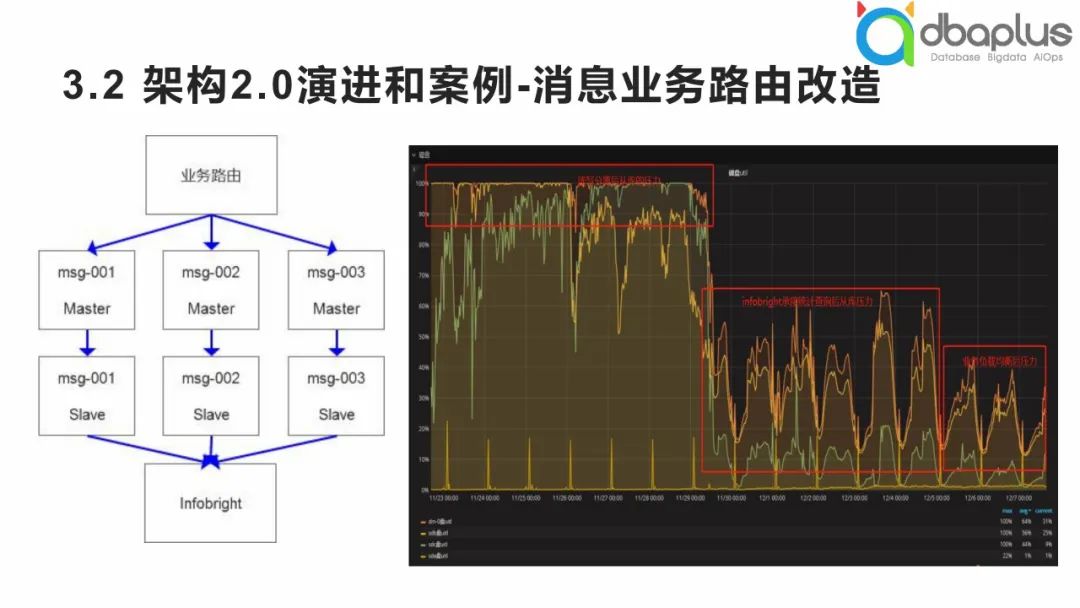
架构2.0阶段首先做业务路由的改造。早期我们做消息业务的改造,例如打开APP后的消息推送,整体的吞吐量较大。在早期的业务中,对于消息存储的数据统计要求较高,我们希望能够尽快将消息推送抵达用户并获得反馈,使得整个业务运营形成闭环。
如上图右侧所示,是数据库侧的I/O使用情况,在进行I/O优化的过程中,一个主节点难以承载负荷,所以我们将查询需求扩展到了从节点做了读写分离,后期发现仍不能满足要求,统计查询还是非常卡顿,I/O使用率还是被打满。我们进行了列式存储扩展,将统计查询迁移过去后提高了查询效率,算是解决了查询瓶颈问题,原服务的I/O使用率一下子降低了60%以上,再后来通过业务路由将一个节点动态扩展为三个节点,如上图左侧所示,性能又有了明显改善,提升了20%左右,整个过程是一个循序渐进的优化过程。
2)数据库中间件
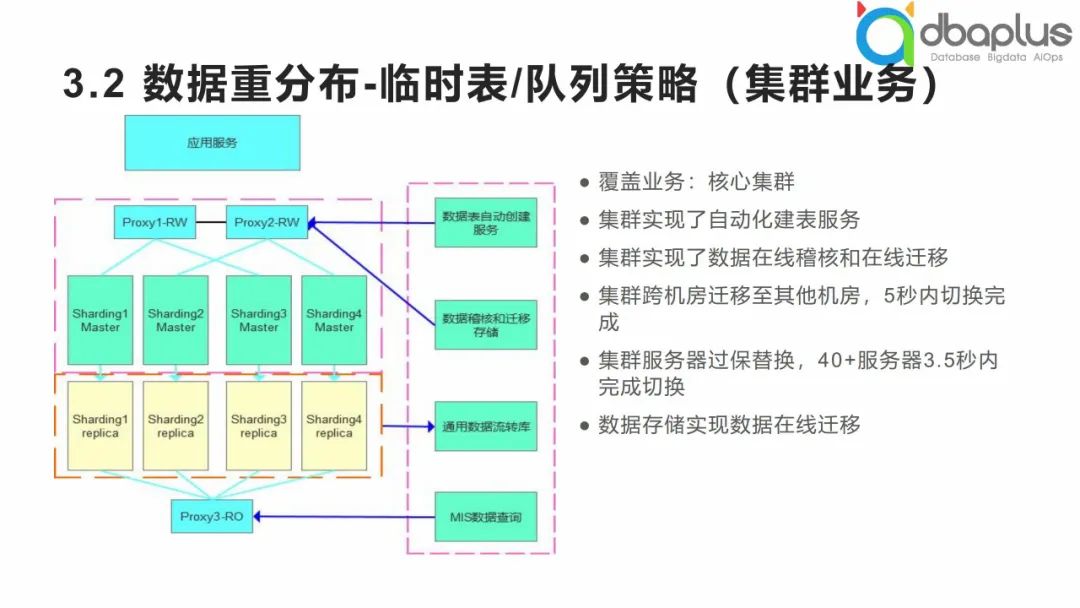
基于这种架构模式,我们也做了一些特色化的服务,主要有4点:
中间件负载均衡
数据库集群架构模式通过Consul服务把原来的三层结构改成了两层,实现了中间件层的负载均衡。
配置化建表
只读查询
① 数据重分布

第一个优势数据重分布,因为中间件架构优缺点并存,我们在实践过程中经历了很多考验,对于中间件架构来说,个人觉得它的一大特色就是拓扑结构的可扩展性。比如硬件服务器在多年后需要过保替换,逐个服务器替换还是会产生系统抖动,如果有几十个节点,这种替换其实会存在一定的风险,基于中间件架构可以快速实现拓扑结构扩展,如上图所示,可以补充一套从库节点,然后将中间件收缩,再将3层拓扑切换为两层,对于几十上百个节点的快速切换,这是一种很优雅的模式,整个切换过程在3.5秒左右,当业务服务具备重连机制,集群内部其实已经发生了质的变化。
② 优势分布式集群组/通用存储方案设计
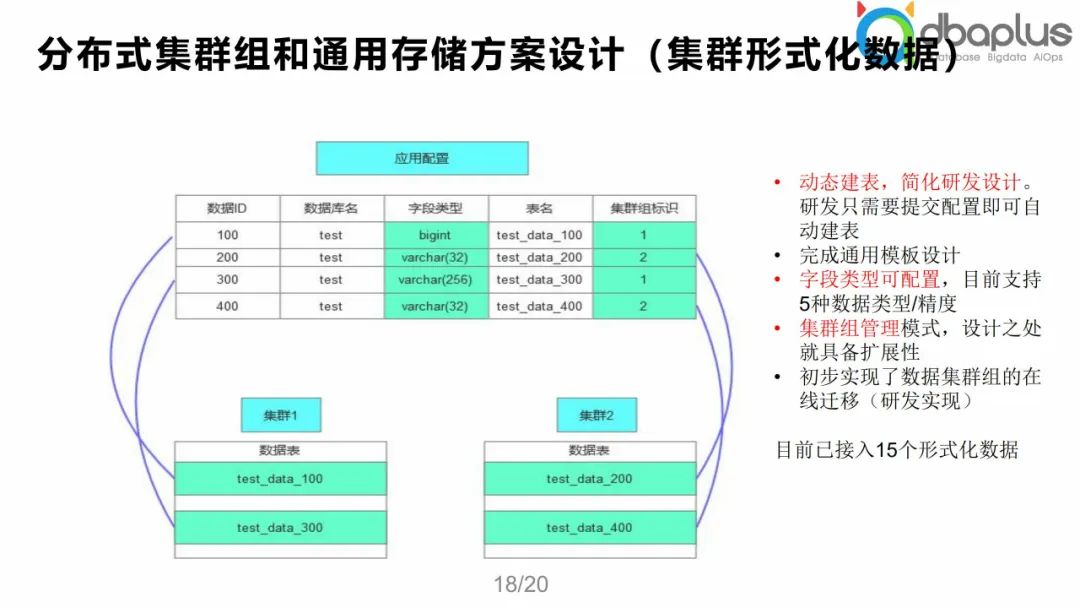
第二个优势分布式集群组/通用存储方案设计,比如我们所说的数据库分布式架构整体需要去满足业务需求,发现有很多数据表结构都是相似的,在这种情况下,我们就可以实现动态、灵活的存储管理模式。
主要分为两个维度:第一,通用存储意味着我们原来的一套集群不够,我们可以再补一套集群实现,这样就是集群组的模式。在这个层面上,我们就把集群下沉一层,在上层进行配置化的管理,在上层有一个全局配置;第二,我们通过全局配置可以快速灵活地生成一些定制化的表结构,比如有的业务对于数据的存储需求是varchar(32),而有的是varchar(256)或者bigint,这些都可以在集群组中动态配置,从而适配不同的模板,通过这种灵活的配置管理的方式实现整个集群组数据的存储管理。
3、架构3.0演进和技术分析
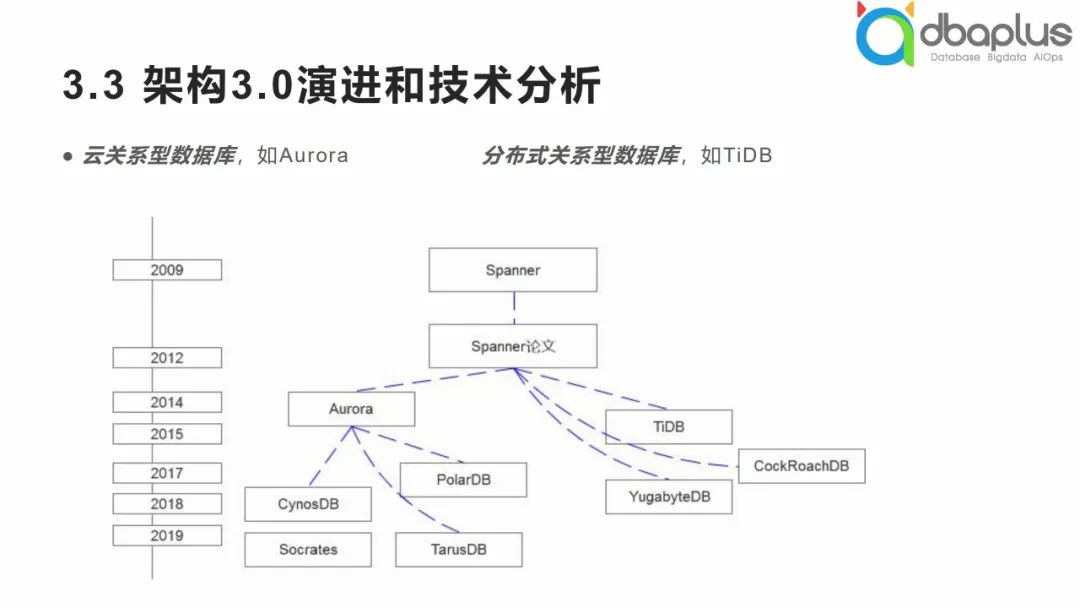
我们经常听到云关系型数据库和分布式关系型数据库等概念。
从整体上看,两大派别较大的差异在于Aurora等数据库与MySQL没有太大差异,整体采用了存算分离的架构,而另一派别的数据库是以NewSQL全新的设计体系,兼容MySQL协议的形式出现,两者属于不同的体系,在数据库分布式架构策略方面也有不同的实现,从早期的读写分离模式到周期表、中间件,后续还会有新型中间件等。
1)数据库分布式架构策略对比
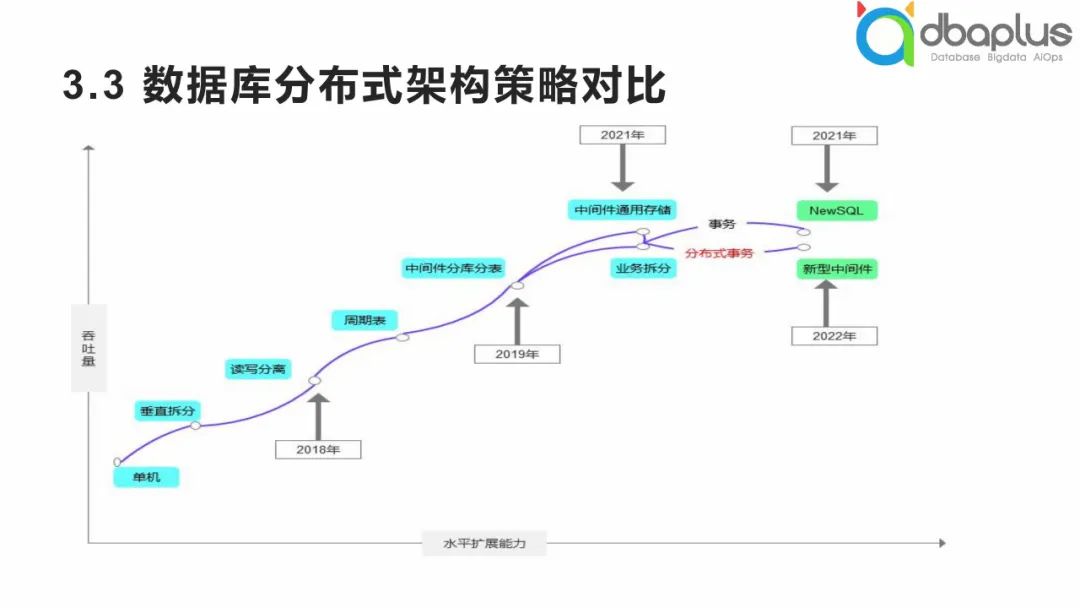
其实云原生数据库从某种概念上来说是弯道超车,云原生数据库中以Aurora为典型代表的数据库,其底层设计本质为读写分离模式,但核心技术是分布式共享存储,它是从读写分离的模式经历了大跨越的更新。
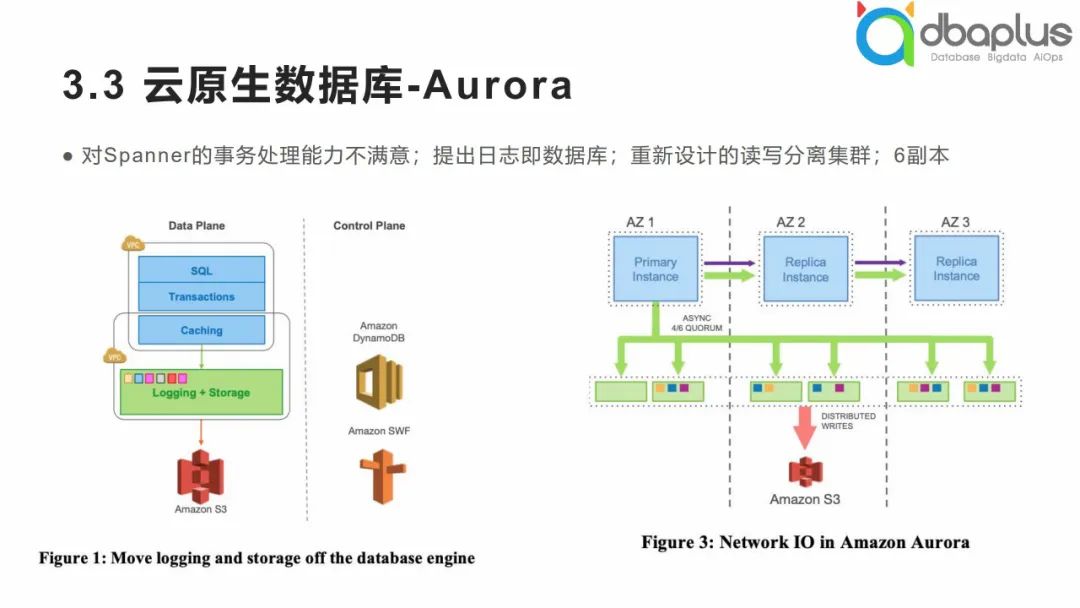
① 云原生数据库-Aurora
我们简单来看一下具有代表性的Aurora数据库,是AWS在MySQL的基础上进行了魔改,因为AWS对Spanner的事务处理能力不满意,提出日志即数据库,并重新设计读写分离集群,延伸出Aurora数据库,其整体为6副本,底层基于S3,整体采用读写分离模式。
② CynosDB,PolarDB
CynosDB和Aurora有一些差异,但其整体还是存储计算分离的结构,基于Raft,将redo下推至存储管理。PolarDB基于RDMA,没有将redo下推至存储,其本质还是基于存储计算分离的模式。
③ TiDB体系结构
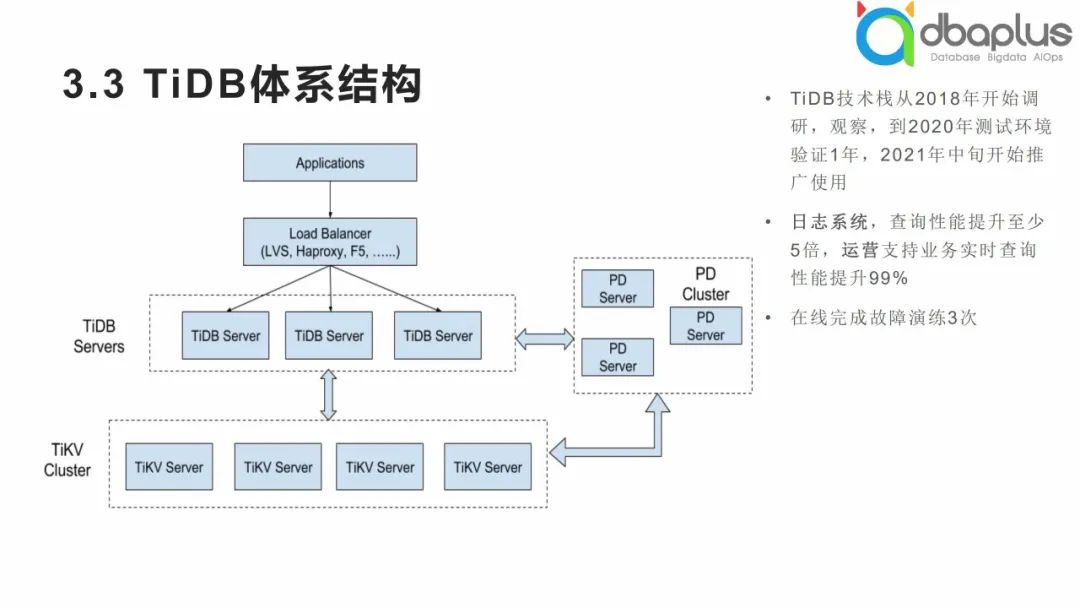
我们TiDB的调研时间较早,在早期也是在测试环境中沉淀了许久,然后逐步从日志型数据库改造开始,逐步引入更多的业务范围。
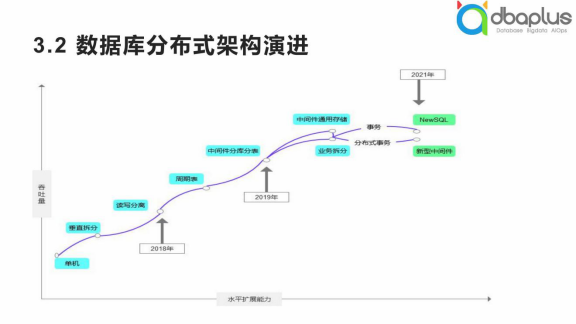
4、数据库分布式架构演进小结

四、技术展望和小结
1、数据库架构演进趋势分析
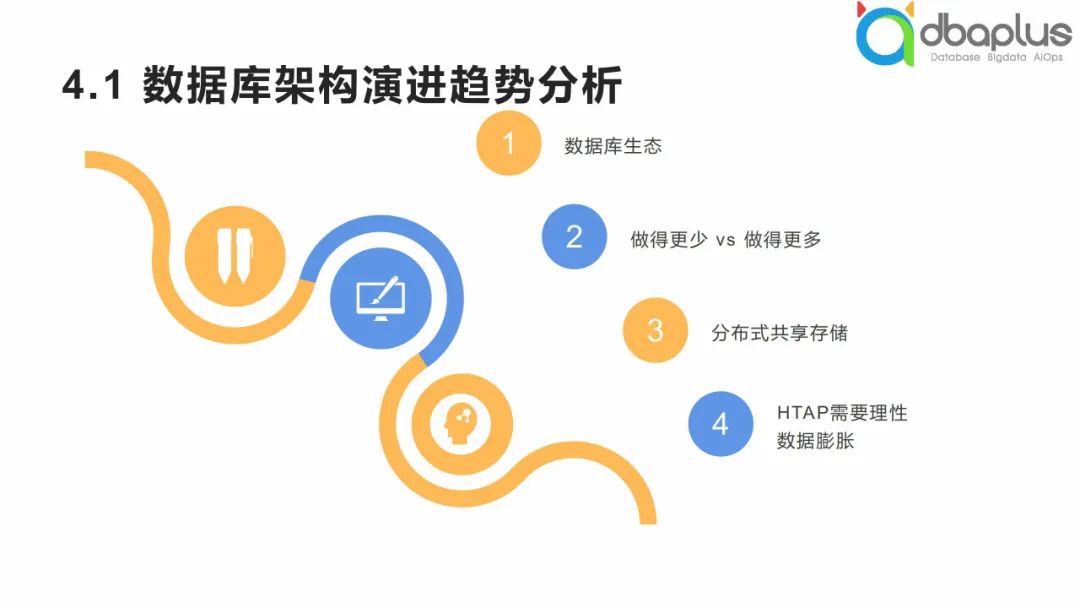
1)数据库生态之国产化
从整个数据库架构的演进过程来看,现在的数据库生态变得越来越多元化,同时也存在一定的差异化和风险,在此我想多提一下国产化数据库,因为这是生态中不可或缺的。
目前国内的数据库国产化程度还是比较高的,如果从近些年来研发技术和数据库的紧密结合来看,很明显研发方向是在降低对于数据库的重逻辑依赖,转而通过分布式技术架构来满足性能和扩展性等强烈需求,而互联网作为开源技术的试验田,提供了大量的业务场景使得开源软件能够不断成熟迭代。在功能实现上,国产数据库也更为贴合国内用户的使用需求和体验。从这个层面来看,国产化数据库通常都具有分布式的成长基因。
但是,在行业中也在短时间内产生了大量的数据库定制化产品,这些都是在核心组件和底层服务之外的偏个性化定制,使得用户在林林总总的国产化数据库中容易迷茫,另外国产数据库如果仅仅是为了对标和其他商业数据库的兼容度,个人感觉会受到过多束缚和限制,因为过多的泛应用化会让数据库技术的基础沉淀不够扎实,而过度迎合用户使用体验而在设计理念上妥协,会让数据库技术难以聚焦,限制更大的发挥潜力。
2)做得更少 vs 做得更多
在数据库分布式架构的改造中,做得更少对我来说是颠覆认知的收获。我们早期做分布式架构性能提升时希望做得更多,支撑更高的OPS,提供更高更强的性能,但我们做架构改造的过程中发现有些情况却恰恰相反,基于业务的视角去做一些架构优化反而能够取得更好的效果,最后发现原来支撑了几十万的OPS,经过优化几万OPS就足够了,从这个层面来说,数据库分布式架构的发展空间很大。
3)分布式共享存储
云原生数据库有共享存储的影子,例如Aurora是基于读写分离模式,它之所以在分布式方向实现弯道超车,是因为其核心部分是分布式共享存储技术,在云原生数据库中,原来看起来“土味的”共享存储模式其实玩出了新的花样。
4)HTAP需要理性
2、基于机器学习的数据库监控异常预测研究
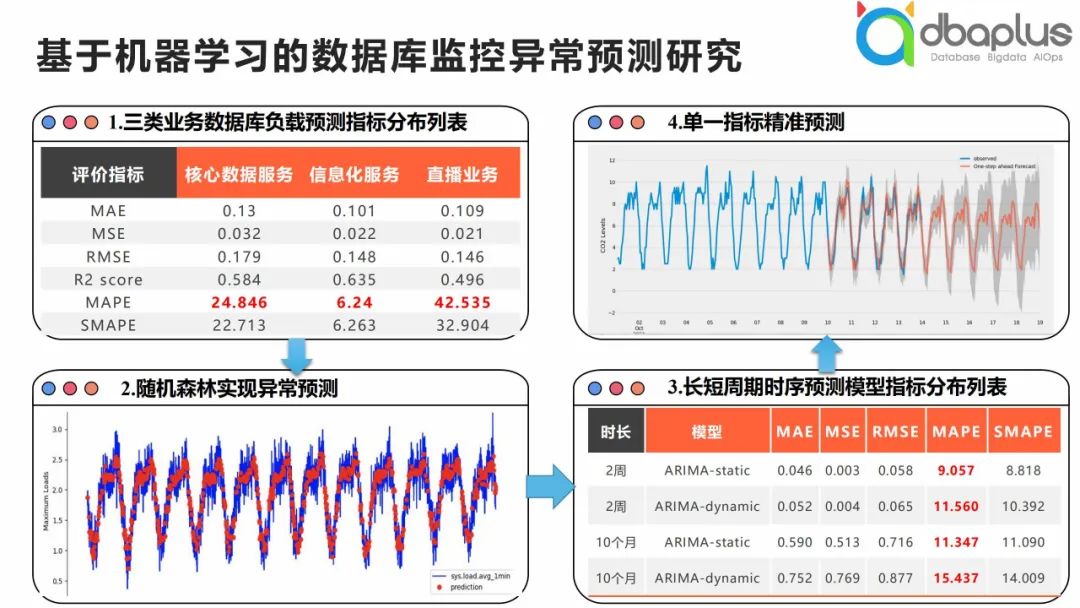
近些年来AIOps还是很火的,数据库也会搭上这辆便车。我前段时间进行了一些机器学习相关的研究,将成百上千的服务器通过机器学习的方式做相关监控数据的预测,如上图我们基于回归模型和时序模型进行了预测,整体上基本实现了对某些指标的周期性预测。
那么问题来了,机器学习异常预测与分布式架构有何关系呢?根据我的理解,原本数据库的负载预测是基于单机模式,而我们在考量集群分布式架构时,需要从更全局的集群角度看待,定位短板,和单机模式是有很大的差别。从这个层面来说,如果我们有一些分布式体系的异常预测模型,我们就可以在此基础上做更多工作。
Q&A

获取本期PPT,请添加群秘微信号:dbachen








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721