
一、分布式锁
为了效率(efficiency),协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其它的不良后果。比如重复发送了一封同样的 email(当然这取决于业务应用的容忍度)。
为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,订单重复,超卖或者其它严重的问题。
1)互斥(Mutual Exclusion),这是锁最基本的功能,同一时刻只能有一个客户端持有锁。
2)避免死锁(Dead lock free),如果某个客户端获得锁之后花了太长时间处理,或者客户端发生了故障,锁无法释放会导致整个处理流程无法进行下去,所以要避免死锁。
最常见的是通过设置一个 TTL(Time To Live,存活时间) 来避免死锁。
3)容错(Fault tolerance),为避免单点故障,锁服务需要具有一定容错性。大体有两种容错方式:
一是锁服务本身是一个集群,能够自动故障切换(ZooKeeper、etcd);
二是客户端向多个独立的锁服务发起请求,其中某个锁服务故障时仍然可以从其他锁服务读取到锁信息(Redlock),代价是一个客户端要获取多把锁,并且要求每台机器的时钟都是一样的,否则 TTL 会不一致,可能有的机器会提前释放锁,有的机器会太晚释放锁,导致出现问题。
Redis
MySQL
ZooKeeper
二、基于 Redis 的分布式锁
使用 Redis 的分布式锁,我们首先想到的是 setnx 命令,SET if Not Exists:
SETNX lockKey value EXPIRE lockKey 30
使用 jedis 的客户端代码如下:
if (jedis.setnx(lockKey, val) == 1) {jedis.expire(lockKey, timeout);}
虽然这两个命令和前面算法描述中的一个 SET 命令执行效果相同,但却不是原子的。如果客户端在执行完 SETNX 后崩溃了,那么就没有机会执行 EXPIRE 了,导致它一直持有这个锁。
加锁和设置超时两个操作是分开的,并非原子操作。假设加锁成功,但是设置锁超时失败,那么该 lockKey 永不失效。
问题 1:为什么这个锁必须要设置一个过期时间?
当一个客户端获取锁成功之后,假如它崩溃了,或者它忘记释放锁,或者由于发生了网络分割(network partition)导致它再也无法和 Redis 节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了
问题 2:这个锁的有效时间设置多长比较合适?
前面这个算法中出现的锁的有效时间(lock validity time),设置成多少合适呢?如果设置太短的话,锁就有可能在客户端完成对于共享资源的访问之前过期,从而失去保护;如果设置太长的话,一旦某个持有锁的客户端释放锁失败,那么就会导致所有其它客户端都无法获取锁,从而长时间内无法正常工作。看来真是个两难的问题。
Redis 客户端为了获取锁,向 Redis 节点发送如下命令:
SET lockKey requestId NX PX 30000
lockKey 是加锁的锁名;
requestId 是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的;(下面会分析它的作用)
NX 表示只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁;
PX 30000 设置过期时间,表示这个锁有一个 30 秒的自动过期时间。当然,这里 30 秒只是一个例子,客户端可以选择合适的过期时间。
在 Java 中使用 jedis 包的调用方法是:
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime)
问题:为什么要设置一个随机字符串 requestId?如果没有会出现什么问题?
下面释放锁的时候给出答案。
如果按照如下方式加锁:
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {return true;}return false;
加锁之后,每次都会到 expireTime 之后才会释放锁,哪怕业务使用完这把锁了。所以更合理的做法是:
1)加锁;
2)业务操作;
3)主动释放锁;
4)如果主动释放锁失败了,则达到超时时间,Redis 自动释放锁。
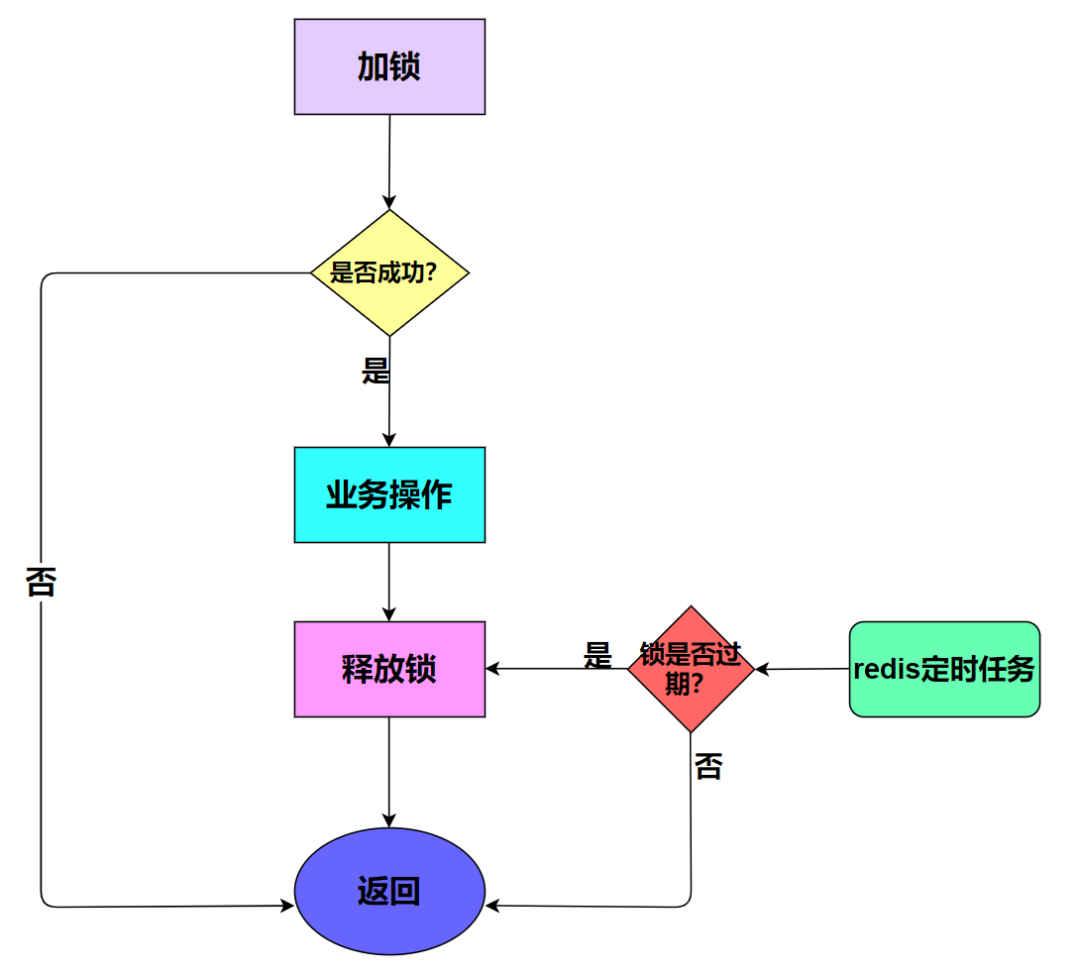
如何释放锁呢?Java 代码里在 finally 中释放锁,即无论代码执行成功或者失败,都要释放锁。
try{String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {return true;}return false;} finally {unlock(lockKey);}
上面那个 unlock(lockKey)代码释放锁有什么问题?可能会出现释放别人的锁的问题。
有的同学可能会反驳:线程 A 获取了锁之后,它要是没有释放锁,这个时候别的线程假如线程 B、C……根本不可能获取到锁,何来释放别人锁之说?

1)客户端 1 获取锁成功。
2)客户端 1 在某个操作上阻塞了很长时间。
3)过期时间到了,锁自动释放了。
4)客户端 2 获取到了对应同一个资源的锁。
5)客户端 1 从阻塞中恢复过来,释放掉了客户端 2 持有的锁。
6)另外线程客户端 3 此时可以成功请求到锁
如何解决这个问题:自己只能释放自己加的锁,不允许释放别人加的锁!
前面使用 set 命令加锁的时候,除了使用 lockKey 锁标识之外,还使用了一个 requestId,这个 requestId 的作用是什么呢?
requestId 是在释放锁的时候用的!!!
伪代码如下:
if (jedis.get(lockKey).equals(requestId)) {jedis.del(lockKey);return true;}return false;
所以在释放锁的时候,先要获取到该锁的值(就是每个加锁线程自己设置的 requestId),然后判断跟之前自己设置的值是否相同,如果相同才允许删除锁,返回成功,如果不同,直接返回失败。
问题:为什么要设置一个随机字符串 requestId?如果没有会出现什么问题?
设置一个随机字符串 requestId 是必要的,它保证了一个客户端释放的锁必须是自己持有的那个锁。假如获取锁时 SET 的不是一个随机字符串,而是一个固定值,那么可能导致释放别人的锁。所以要保证 requestId 全局唯一。
if (jedis.get(lockKey).equals(requestId)) {jedis.del(lockKey);return true;}return false;
显然,jedis.get(lockKey).equals(requestId) 这行代码包含了【获取该锁的值】,【判断是否是自己加的锁】,【删除锁】这三个操作,万一这三个操作中间的某个时刻出现阻塞。

1)客户端 1 获取锁成功。
2)客户端 1 进行业务操作。
3)客户端 1 为了释放锁,先执行’GET’操作获取随机字符串的值。
4)客户端 1 判断随机字符串的值,与预期的值相等。
5)客户端 1 由于某个原因阻塞住了很长时间。
6)过期时间到了,锁自动释放了。
7)客户端 2 获取到了对应同一个资源的锁。
8)客户端 1 从阻塞中恢复过来,执行 DEL 操纵,释放掉了客户端 2 持有的锁。
实际上,如果不是客户端 1 阻塞住了,而是出现了大的网络延迟,也有可能导致类似的执行序列发生。
问题的根源:锁的判断在客户端,但是锁的删除却在服务端!
正确的释放锁姿势——锁的判断和删除都在服务端(Redis),使用 lua 脚本保证原子性:
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0end
这段 Lua 脚本在执行的时候要把前面的 requestId 作为 ARGV[1]的值传进去,把 lockKey 作为 KEYS[1]的值传进去。
释放锁的操作为什么要使用 lua 脚本?
释放锁其实包含三步操作:‘GET’、判断和‘DEL’,用 Lua 脚本来实现能保证这三步的原子性。
如果客户端 1 请求锁成功了,但是由于业务处理、GC、操作系统等原因导致它处理时间过长,超过了锁的时间,这时候 Redis 会自动释放锁,这种情况可能导致问题:
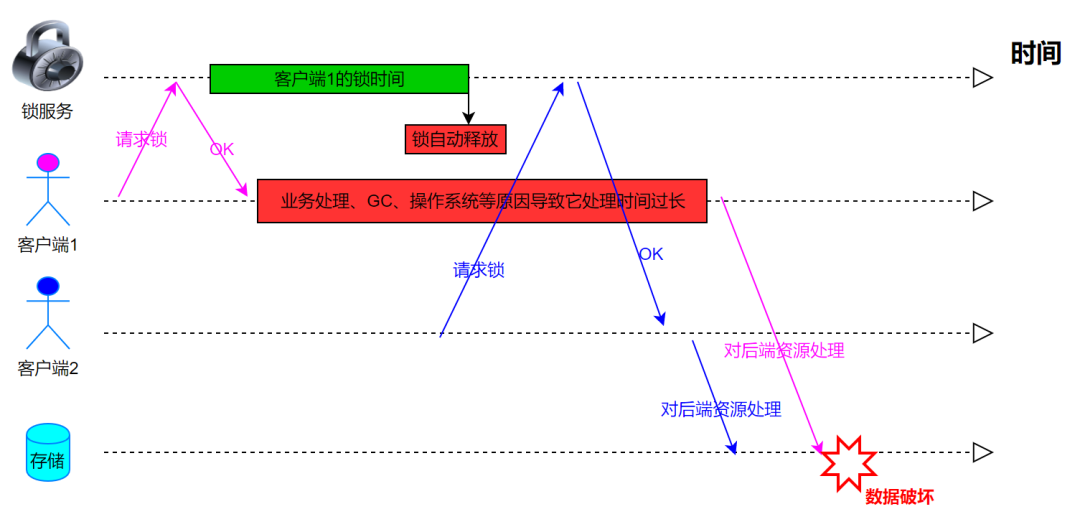
如何解决这种问题?——续期,Java 里我们可以使用 TimerTask 类来实现自动续期的功能,伪代码如下:
Timer timer = new Timer();timer.schedule(new TimerTask() {public void run(Timeout timeout) throws Exception {//自动续期逻辑








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721