
本文根据洪烨老师在〖deeplus直播:金融业数据库转型与国产化改造〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)

随着数据井喷式增长,传统的集中式数据库已经难以承受负载,分布式数据库无疑能很好地解决这一问题。那么,银行到底需要怎样的分布式数据库?如何选择和改造最适合自身的数据库?核心场景应该要达到什么客观条件才适合上分布式数据库?这些问题成为了金融行业的普遍痛点。
本次分享,将会从五个方面去谈银行核心系统的数据库选型问题,并针对一致性、可用性、扩展性、生态等维度,给金融企业提供一些选型启发。
一、银行核心需要一个怎样的数据库?
首先,我们面临的第一个问题是:银行核心需要一个什么样的数据库?先给大家科普一下:银行核心系统的主要功能是处理账务信息,简单来说,它就是一个给大家管钱的系统。因此,银行核心系统对于数据的一致性、性能和系统的服务响应能力等都有严格的要求,对数据库的要求也最为严格。为此,我们将对数据库的要求进行提炼,总结出了40字标准:
账务不能错,数据不能丢
系统不能停,应用可逃生
联机不能慢,批量不能晚
数据易迁移,整体易运维
1)账务不能错,数据不能丢
银行账户里的钱不能有错;同时,如果账户里的数据(也就是大家的存款)丢了,那客户也是无法接受的。
2)系统不能停,应用可逃生
站在国产分布式数据库选型的角度来讨论:第一,系统不能停,因为对于整个银行核心来说,停机要付出很大的代价,所有的业务都进行不了,那客户肯定无法接受;而在过去,银行的核心基本都运行在一些国外的商业数据库和大型硬件上,如果切换到一些国内的分布式数据库上,谁也不敢保证完全没问题。那么,至少要有一个跟原来一致的情况来做最后的保障,这就是应用可逃生的意思。
3)联机不能慢,批量不能晚
联机就是大家日常的一些交易,比如存取款、查账等。尤其是在互联网时代,大家日常有很多的交易,包括在线支付、购物等。如果联机慢,就会影响整体的用户体验。
批量主要是指日终批量以及结息批量。因为银行每天晚上都要对账,如果时间太长,就会影响到第二天银行的开业,所以也不能晚。
4)数据易迁移,整体易运维
我们需要考虑:原来系统的数据要如何迁移到新的系统上,以及后期整体的运维成本。
基于这些原则,我们提炼了6个可以帮助实现落地的要点:
1)一致性
在任何情况下,都要能保证事务的强一致性,尤其是账务的一致性,不能给应用返回中间态结果。
2)高可用
满足7×24运行要求,数据不能丢失;并且,因为银行大多数都有同城以及异地部署的规范要求,所以一定要支持多机房、多中心部署。
3)高性能
高性能主要聚焦于三个方面:联机交易TPS、联机响应时间ART、批量整体时长。
4)可扩展
扩展并不单指“扩”,还有一部分是“缩。主要在两个方面:计划内并发扩展(计算、存储能力)以及在线扩缩容(例如硬件寿命到期的自然淘汰更换等)。
5)生态丰富
数据库不是单独的产品,它会涉及到许多与周边产品的兼容性问题,比如异构数据库的数据同步、SQL生态与周边产品兼容等。能否与生态周边产品兼容,对数据库产品后续的发展会有非常大的影响,因此也需要进行考量。
6)易维护
这一点是基于系统上线后的整体维护成本来进行的考量,是否具备可视化管理能力(切换、监控、告警等)以及管理整个集群的能力。
这些都是我们在前期就需要考虑的内容。
二、非功能考量项
接下来从第一项开始探讨:怎样能对数据库产品做一致性验证?
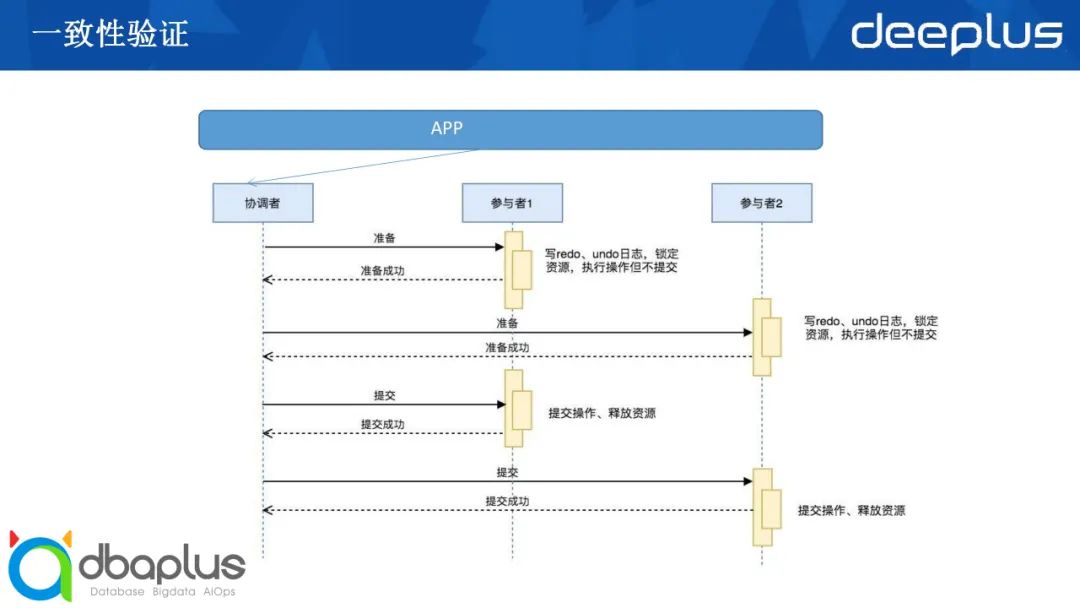
这里的一致性主要讲的是事务的一致性。从应用的角度来看,数据库返回的结果是不是一致的,也就是我们常说的ACID。在分布式数据库中,对于事务一致性的难点通常在锁隔离性、死锁的探测处理,以及二阶段提交过程中协调节点异常情况下的处理机制。
通常可以采用以下三种方式结合来验证分布式数据库的事务一致性:
1)演示或简单操作
这是最直观或者说最简单的方式,通过简单的案例,来验证各个隔离级别下增删改查是否支持;模拟死锁或锁等待的场景,查看产品的处理机制。
2)正常情况下一致性验证
在高并发场景下,通过对热点账户的增删改查,汇总流水明细,并与账户余额进行比对,验证高并发下的隔离性及死锁检测。
3)异常情况下一致性验证
在高并发场景下,对协调节点进行宕机等故障场景的模拟,汇总流水明细与账户余额进行比对,验证数据库能否保障事务一致性。
现在大部分数据库产品都是通过二阶段提交来实现分布式事务的。如果在准备阶段发生异常,整个事务就会发生回滚,这点大家比较容易理解。但如果是在提交阶段发生异常,很多产品会将交易提交。又因为大部分数据产品是应用直接连接协调者,所以,在这个过程中,尤其是在协调者故障的场景下,应用收到的其实是失败或者网络中断这种类型的返回。对于应用来讲,它认为这笔交易是失败的,这就会导致应用接收到的信息与数据库实际执行的信息不一致。
在进行一致性验证时,各个数据库产品怎样去应对处理?这是一个比较关键的点。我们通常会建议将这三种方法进行结合。
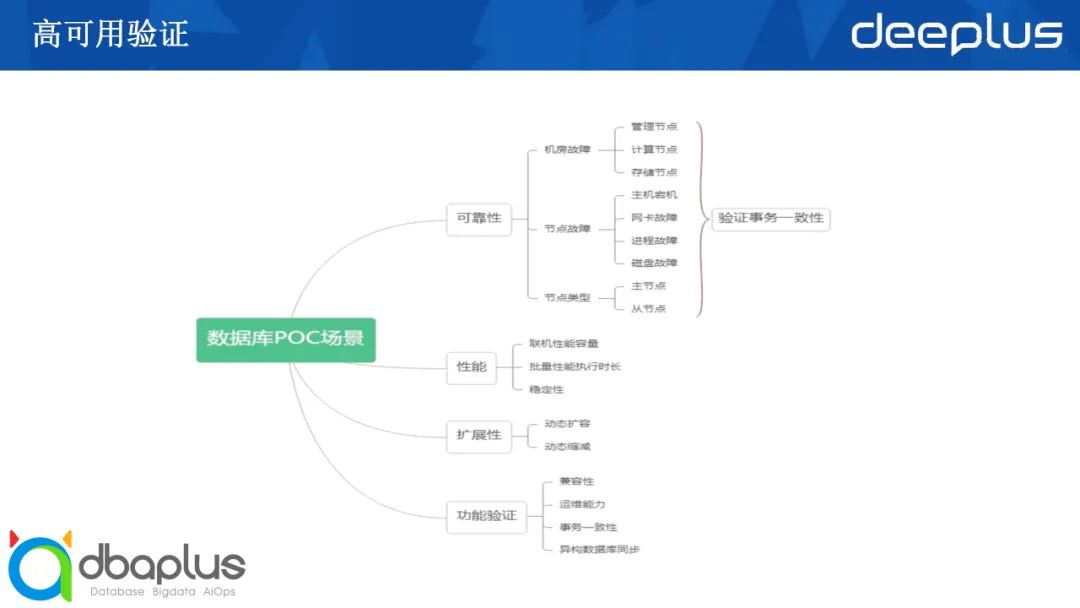
高可用主要是验证各个场景下的RTO与RPO,从场景上,可以粗略分为机房间故障与机房内故障:
1)多中心切换:
整体故障(中心整体切换)
中心间网络故障(网络抖动、网络中断、网络阻塞等)
2)中心内切换:
计算资源故障(服务器异常)
存储资源故障(磁盘异常)
网络资源故障(网络抖动、网络中断、网络阻塞等)
软件故障
NTP时间异常
进程异常(进程崩溃、进程挂起等)
文件异常(权限、误删除、文件系统满等)
1)性能验证
接下来是性能验证。性能验证主要分为两大类:联机场景、批量场景。
联机场景主要关注响应时间,一个是TPS。批量场景主要关注数据批量的导入导出、批量代发和批量结息,将它们在同样的数据量下的执行时间进行了一个对比。
2)扩展性验证
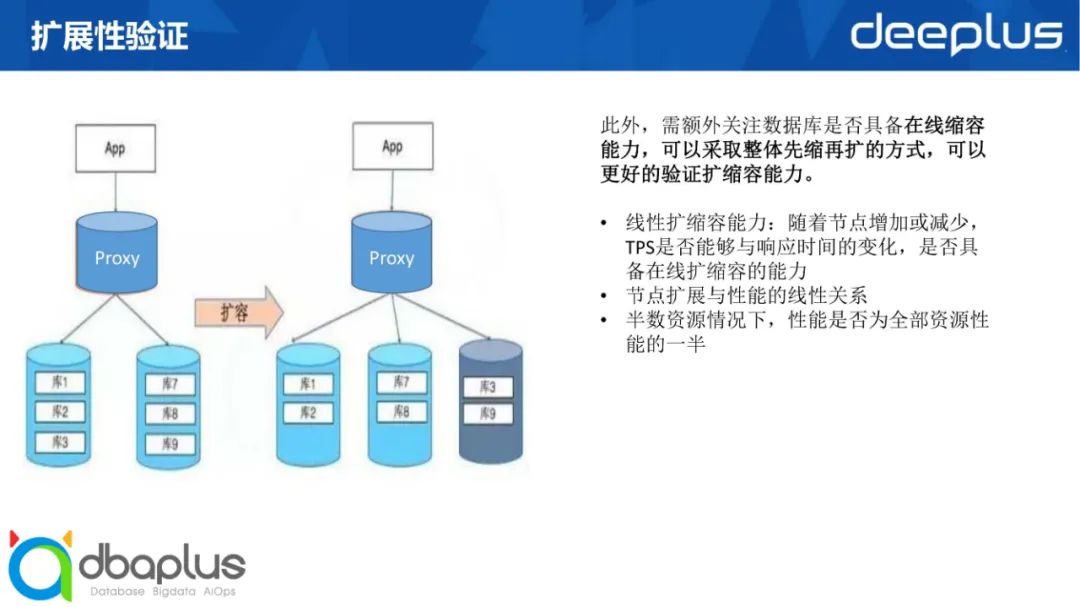
扩展性可以说是分布式数据库的主打特性,也是需要我们重点验证的一个特性。在这里我们采取整体先缩再扩的方式。
为什么要先缩呢?因为整体的硬件资源有限,先缩下来可以考验它的线性扩缩容能力:随着节点增加或减少,TPS是否能够与响应时间的变化,是否具备在线扩缩容的能力;第二要看缩容过程中,节点扩展与性能是否具有线性关系;以及在缩到一半配置的情况下,性能是否为全部资源性能的一半。做下来之后,我们会再去做扩容,将半数资源扩容到原来的全量,看看扩容后能否达到原来的性能,观察在扩容过程中性能是否是线性增长。
在分布式数据库下,由于每个产品对于表的筛定方式不一样,我们还需要去关注数据迁移的逻辑。这个数据库产品的分区表是哈希、范围、还是列表?它的迁移逻辑是怎样的?在迁移过程中对原有的应用的影响如何?这也是被纳入RPO的指标里的。
刚才提到的几项其实都属于非功能的验证,在这里我总结了一个主要关注指标的列表供大家进行参考:
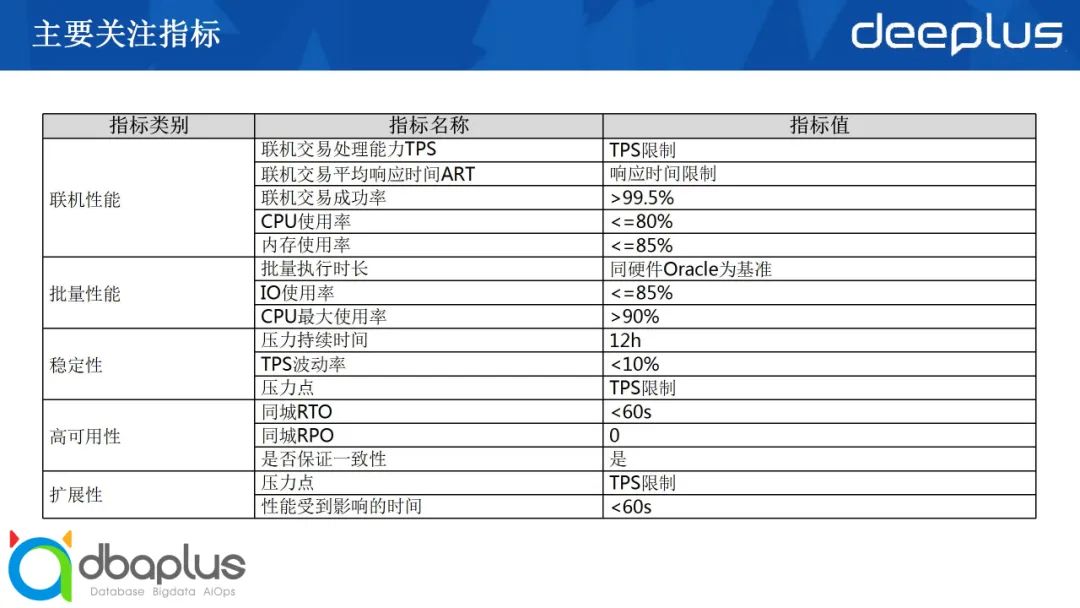
联机性能这部分首要关注的是TPS。当然,因为每个银行或者说应用,交易里面的SQL数量不一样,其实不太好作横向比较。最好依照各个企业或者系统设立指标,这样会比较客观;第二是平均响应时间,可以具体到每日交易的响应时间;第三是强制的,就是说交易的成功率必须大于99.5%,如果更严格一点可以定到99.9%;还有一个是 CPU和内存的使用率,因为联机需要承载大量的用户连接,要分配很多的线程去作为代理,受理前端的应用连接;还有一点是CPU的并发使用率,这两点是对它资源的消耗。
批量性能最关注执行的整体时长、lO使用率以及CPU资源使用率。
稳定性通常是指能否支持在一定的基准下做长时间运行,在这个过程中,我们要关注压力持续时间、TPS波动率以及压力点。
高可用性就是要保证RPO不能丢数、同城的RTO和RPO在60秒以内,做到秒级恢复。最重要的是,在高可用场景下,帐一定要平,也就是一定要保证整体事务的一致性。
最后一个是扩展性,用多大的压力去压,在扩展跟收缩过程中对交易整体的 TPS有什么样的影响?可以接受这个过程中出现一定程度上的中断,但中断时间也应该是秒级。
三、偏功能考量项
上文提到的指标主要是一些非功能的考量项。接下来我们来谈一些偏功能或者说偏主观的考量点。

最开始有提到,数据库的选择不仅仅是数据库软件产品本身,也涉及周围开发工具、数据同步工具、监控、备份等一系列生态,生态往往也会影响数据库产品本身的发展。目前主流的生态包含Oracle生态和开源生态(MySQL & PG):
1)Oracle生态
Oracle生态主要是由于原有系统大部分部署在Oracle上,具有Oracle的特性。但是在迁移过程中,也还是需要注意与原有生态的过渡,数据迁移过程中通常可依靠一些迁移工具,但应用迁移的过程中,分布式数据库的兼容性会带来SQL改造的工作量。
2)开源生态(MySQL & PG)
目前大部分联机事务系统主要还是以MySQL生态为主流,也有部分企业选择了PG生态,也基于此,目前市场上大部分产品都可以兼容MySQL或PG生态,对于各自生态的周边产品也都可以直接对接。
此外,在验证过程中也可以适当的考虑产品与云结合部署的能力,虽然目前重要系统大多数还是独立部署,但随着基础层及平台层的快速云化,上云能力也需要进行考量。
接下来是对于兼容性的考量。我们原有的数据库与分布式数据库的兼容性如何?我们从以下这些方面进行分析:
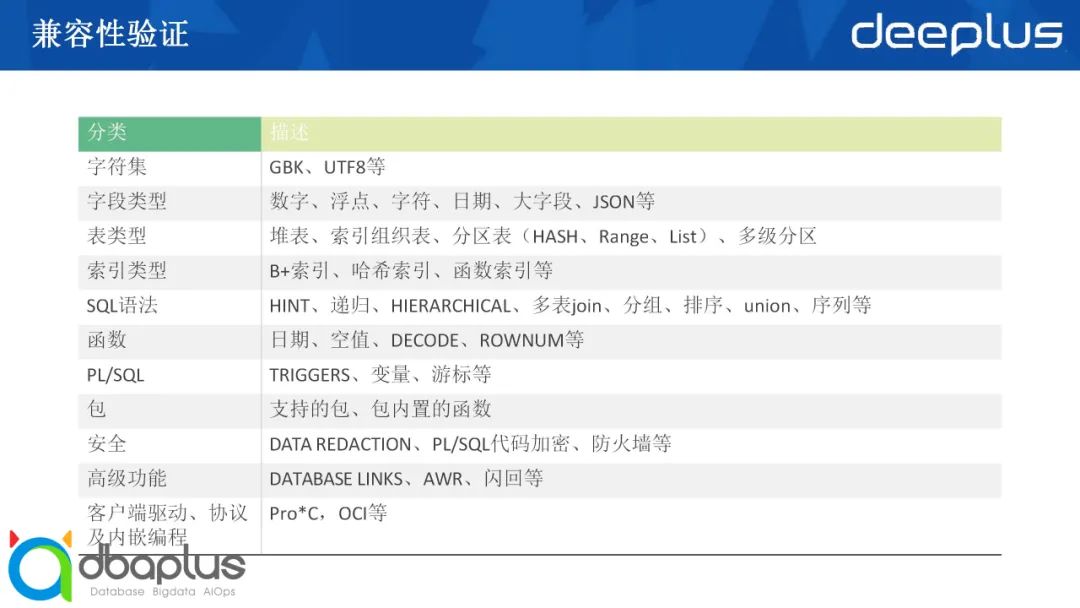
包括对字符集、字段类型、表类型等的支持,这里就不一一赘述了。大家可以看一下,应用一些工具来进行具体的分析对比。
接下来是易维护性的考量,主要分为三类:图形化、自动化和智能化,这其实也代表了整个运维的发展路线。
1)维护类操作的图形化
跟原来的商业数据库不太一样,原来的商业数据库节点数一般比较少,一个人还可以操作过来;但在分布式数据库场景下,节点可能是几十、几百,这个数量如果靠人工,出错的可能性和工作量都比较大,所以通常建议维护类的操作能够提供一些图形化的工具或者能力。这其中包含:
使用图形化界面进行数据库的安装部署
使用图形化界面进行数据库升级
使用图形化界面进行巡检及查看数据库健康状态
使用图形化界面进行备份恢复及定时任务
使用图形化界面进行数据导入导出及数据迁移
使用图形化界面进行数据同步及简单ETL
2)故障场景下的自愈能力
故障场景下的自愈能力也就是指自动化,主要包含以下内容:
数据库监控及信息采集能力
故障分析工具和手段
数据库应急管理手段
数据库告警通知策略
3)智能化诊断能力
容量检测及智能建议
智能故障分析及风险建议
智能参数推荐及索引建议
不良SQL的提示及拦截
四、数据库的演进及分类
上文讲了在整个数据库选型过程中,对于一些功能点以及非功能点的考量。数据库从1970年的关系型数据库一直到现在,有50年左右的发展历史。
在这个过程中,数据库一代代地从单机数据库、集群数据库、向现在越来越多的分布式架构做演进。目前市面上国产主流的数据库产品主要分为两类:基于Proxy的分布数据库及原生分布式数据库。
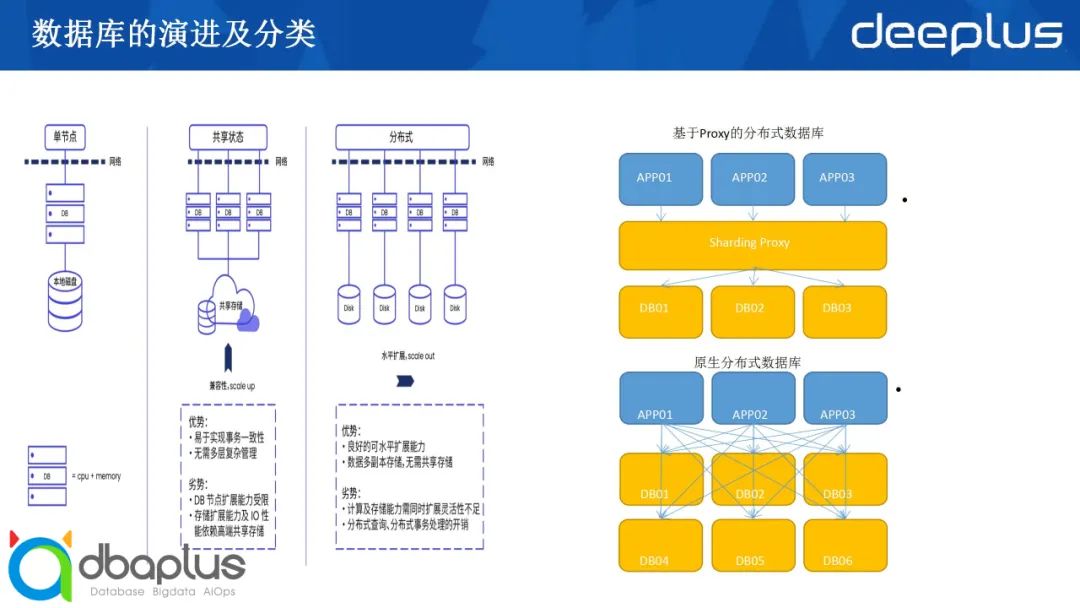
代表产品(GoldenDB、TDSQL),通过将传统单机数据库作为数据节点,通过数据路由层(Proxy)形成分片规则,将不同的请求发送给不同的数据库实例。Proxy层与DB层以SQL进行交互,分布式事务通常在Proxy层进行发起处理,包括负载均衡、SQL优化等工作。
代表产品(OceanBase、TiDB),具有无中心、扩展性好等特性,对业务感知较低或 无感知,与数据节点通过报文交互, 部分产品分布式事务可直接通过收到请求的数据节点进行协调,从而达到去中心化的能力,在扩展性方面具有一定的优势。
五、总结
我们在选型过程中,刚才提到两种主流类型的产品都有涉及。当然,每个产品之间实现的差异比较大,不能一概而论。我们在这里做一个整体对比,给大家做一些参考:
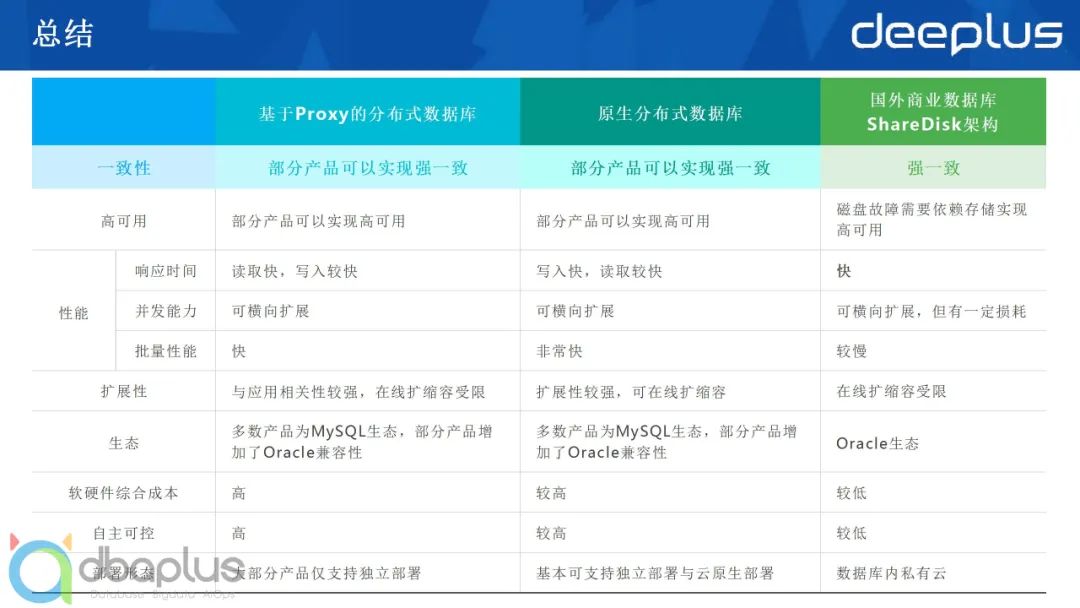
这里需要注意一下整体成本,也就是软硬件综合成本。可能跟大家理解的不太一样,现在很多国产的数据库产品会说:“我们的产品的成本比较低,去O可以为企业节约成本......”
但如果加上机房、硬件数量、人工、网络等各种开销,再加上后期的运维等,整体软硬件综合成本可能会比Oracle还略高一些。这也是大家需要去进行考量的。
在部署形态上,分布式数据库现在既有基于云原生的部署,也可以独立部署,但Oracle现在大多数其实还是独立部署,或是只能通过Oracle内部的私有云能力,也就是插拔式的数据库来做云的部署形态。
今天的分享就到这里,感谢各位!
Q&A
Q1:银行核心场景要达到什么客观条件才适合上分布式数据库,如何评估整体成本?
A1:这个其实没有太统一的标准,通过我们的验证,可以说一个大概的数字供大家进行简单参考。如果核心的数据量超过10T,Oracle的承载能力可能会受到一定的限制。也就是说,核心数据量在10T以上,一般就可以去考虑上分布式,或者说,这已经达到了一个迫切的程度。因为随着数据量的增长,可能在之后, Oracle这种单体的商业型数据库支撑起数据会越来越吃力。
而整体成本包含几个层面,最基础的是机房的成本,包括机柜的成本。很多数据中心其实都在一二线城市,机房或者说土地是相对来说成本比较高的。
除了机房的面积,还要再加上软件和硬件的成本,包括之后的应用改造、迁移以及后期运维。大概的成本主要是这些。
Q2:银行核心系统的分布式数据库选型中POC测试要关注哪些重要指标?
A2:这个问题在分享中其实已经提到了一些,比如在非功能的考量项中,我们需要关注联机的TPS响应时间、资源损耗、批量的执行时长、扩展性、稳定性等指标,具体大家可以参考文章中的表格。
而偏功能的指标,主要根据咱们系统的兼容性以及预期运维能力,通常是作为工作量或者成本的考量。大概是这两个方面。
获取本期PPT,请添加群秘微信号:dbachen
↓点这里可回看本期直播








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721