

笔者最早是作为MySQL DBA入行,从事了5年分布式数据库运维、自动化开发的工作,在大规模数据库集群的管理方面积累了经验;后来又先后从事云数据库售前解决方案和交付方案架构师的岗位,在于客户的研发和DBA交流合作的过程中,发现有不少同学被市面上玲琅满目的数据库品种,特别是分布式数据库搞得眼花缭乱,陷入选型困境。这里把自己在分布式数据库领域实际运维、架构和实施经验分享给大家,抛砖引玉,希望引起大家的共鸣。
主要从四个方面给大家做介绍:

一、数据库从集中式到分布式的演进
从狭义概念来讲,“数据库”就是OLTP场景的关系型单机数据库,诸如老牌的Oracle、DB2等商业数据库以及开源产品MySQL、PostgreSQL,主要解决两个业务问题:在线数据库的实时高效存取和事务保证。
传统单机数据库在基础能力之外,为满足特定业务场景,还支持诸多的数据库经典特性,如视图、触发器、外键约束、存储过程等等。坦率地说,传统单机数据库的容量和性能,足以满足绝大多数中小规模客户的需求;依托特定的软硬件条件,商业数据库甚至可以满足部分大规模客户的数据库使用需要。
但随着互联网时代的到来,业务数据呈暴发式增长,单机数据库在存储容量,和计算、吞吐上遇到了瓶颈。数据量的膨胀,拉高的不仅仅是存储成本,也提升了数据库运维难度和数据安全风险;高并发的业务场景,特别是高并发更新的场景,都需要充足的数据库计算资源和磁盘IO资源,单机数据库捉襟见肘。虽然可以通过业务对数据合理化拆分到多个数据库实例,来延缓单机资源见顶的时间,但需要不断付出高额的架构改造成本。
在这种情况下,分布式数据库作为一种解决方案应运而生,基本思路都是将多台物理机资源组织起来,作为一个数据库对应用提供服务,理想情况下,高并发场景下的计算、存储io、网络io压力在物理机之间均衡。同时要求其具备资源横向和扩展能力(scale out),充分满足业务未来增长需求。
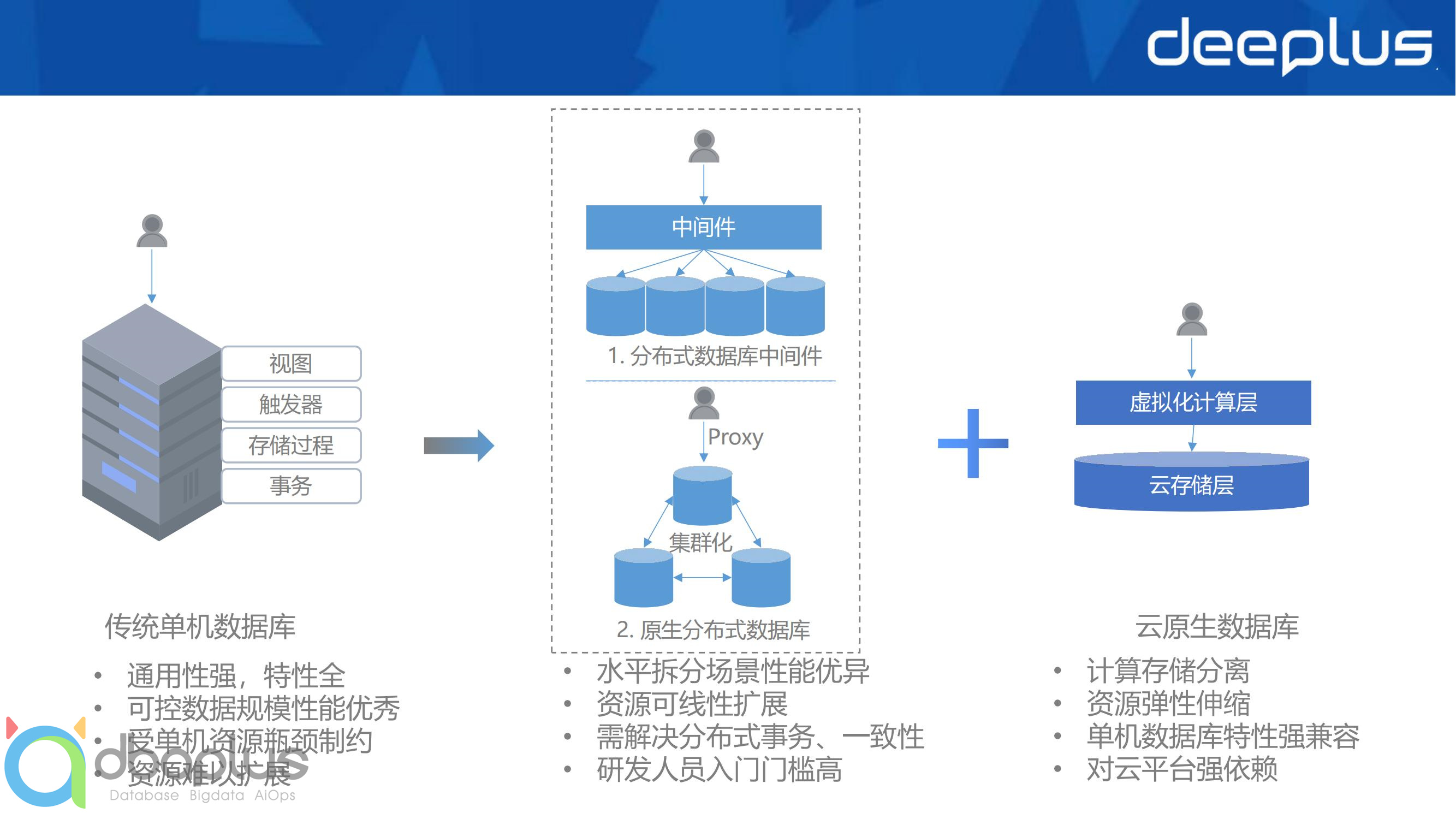
一般认为当前的分布式数据库可细分为分布式数据库中间件和原生分布式数据库两种类型,各大数据库厂商概莫能外。
分布式数据库中间件,架构为自下而上,即将单机数据库实例作为底层存储节点组合起来,求作为proxy层,将海量数据的分库分表逻辑对应用屏蔽起来(理想情况下,实践中,应用完全不清楚分布式逻辑很难做到sql优化设计)底层存储资源的扩容也让应用无感知,典型的ShareNothing架构。
原生分布式数据库,也就是前几年盛行一时的NewSQL数据库,架构是上下一体的,计算层和存储层耦合较为紧密,计算层OLTP数据库为SMP架构,分布式可实现负载均衡和高可用,OLAP数据库多位MPP架构,利用并行处理对复杂查询加速;存储层常采用ShareNothing架构对IO资源进行隔离,多副本之间采用分布式一致性算法在数据可用性和一致性之间做出平衡。因为计算层和存储层一体化设计,往往更容易兼容更多传统单机数据库的产品特性。
这是近几年来比较热门的一个数据库分类,常常与分布式数据库发生混淆,但二者之间天然存在差别。
云原生本质上是充分利用云计算基础设施的高性能、高可靠性和高弹性能力研发云上产品的一种方式。在专门以云计算资源为基础研发的数据库,才是云原生数据库,如AWS的aurora、阿里云的PolarDB,它们能带来近乎传统单机数据库的特性支持和使用体验,同时具备资源(计算、存储)快速弹性伸缩的能力,资源虽然是分布式的,但数据库架构的实质依然是scale up。
与云基础设施的强耦合,是云原生数据库区别于分布式数据库的最大特点。

一些业务场景下,往往不需要采用分布式数据库方案,避繁就简,有更轻量级的解决方法:
一些新闻、资源应用常有写少读多的特点,建议通过部署查询缓存和单机数据库读写分离的方式来应对,不建议升级分布式数据库。
一些电商应用会有高并发更新的特点,优先建议采用业务模块垂直拆分的方法,低成本解决业务负载高的问题。后续根据业务增长情况,针对高并发的模块单独升级分布式数据库。
一些全国级别的在线服务,就是会存储海量实时数据,同时应对高并发吞吐,这是采用分布式数据库的典型场景。
有些应用因为历史原因,以MySQL数据库为代表,单表内积累了上亿的数据量,单表数据文件达到GB级别,性能出现显著退化。此场景优先建议与业务协商,减小在线数据保留时间,上线数据归档方案;同时要考察是否索引不够完善,是否存在优化空间;分布式数据库是兜底方案。
对于OLAP场景,在不升级数据库架构的前提下,优先引入流计算、预计算等大数据处理方案和产品,成本较低;如还不能满足业务需求,则引入专门的OLAP数据库。
如今国产数据库改造是国内各行业IT转型的重要方向,对于之前选用传统商业数据库的客户,最需要的是高兼容数据库来控制改造迁移成本;而是否选用分布式,要考察客户业务场景是否符合上面提到的指征。
数据库容灾、异地多活的场景,原生分布式数据库具有天然优势,可根据基础资源、业务一致性要求和可用性要求,采用不同的部署架构满足,只需将精力集中在应用容灾和多活的研发上。
二、分布式数据库分类

从应用场景角度看,市面上的分布式数据库可分为OLTP、OLAP和、非机构&专有领域NOSQL三个大类,这也是大多数云厂商数据库产品页面的常用分类。
Mycat和PlarDB-X(之前的DRDS)系出同源,最早都是淘宝的数据库中间件TDDL,一个开源,一个是商业产品。
TiDB是非常成功的开源分布式数据库,生态非常活跃,有很多合作伙伴。
OceanBase是最早蚂蚁集团研发的分布式数据库,主要支撑了支付宝全业务,在金融行业有较多客户成功案例,进来已拥抱开源生态。
OLAP数据库往往要处理海量数据的复杂分析,采用MPP架构,天然需要分布式架构,数据分片,进行并行计算加速。
缓存领域,Codis类似TP数据库中间件的方案。
宽列数据库(bigtable)往往用于存储海量非机构化数据,需要高写入吞吐,天然需要分布式架构应对。
在时序数据库和图数据库领域,并非全部产品都是分布式的,但这两种场景涉及的数据量如果增长较快,分布式架构是其加分项。
三、关系型分布式数据库最佳实践

1)场景一
分布式数据库中间件使用的前提是,数据已经进行过充分合理的垂直拆分
最佳实践是,业务、数据具有天然水平拆分特点,如个人网盘,天然适合用户id拆分,电商买家库,天然适合买家id拆分,电子社保卡,天然适合卡号拆分
有高并发更新的大数据表,适合水平拆分,与他关联的小表做广播表,不许关联的单表不要拆分
2)场景二
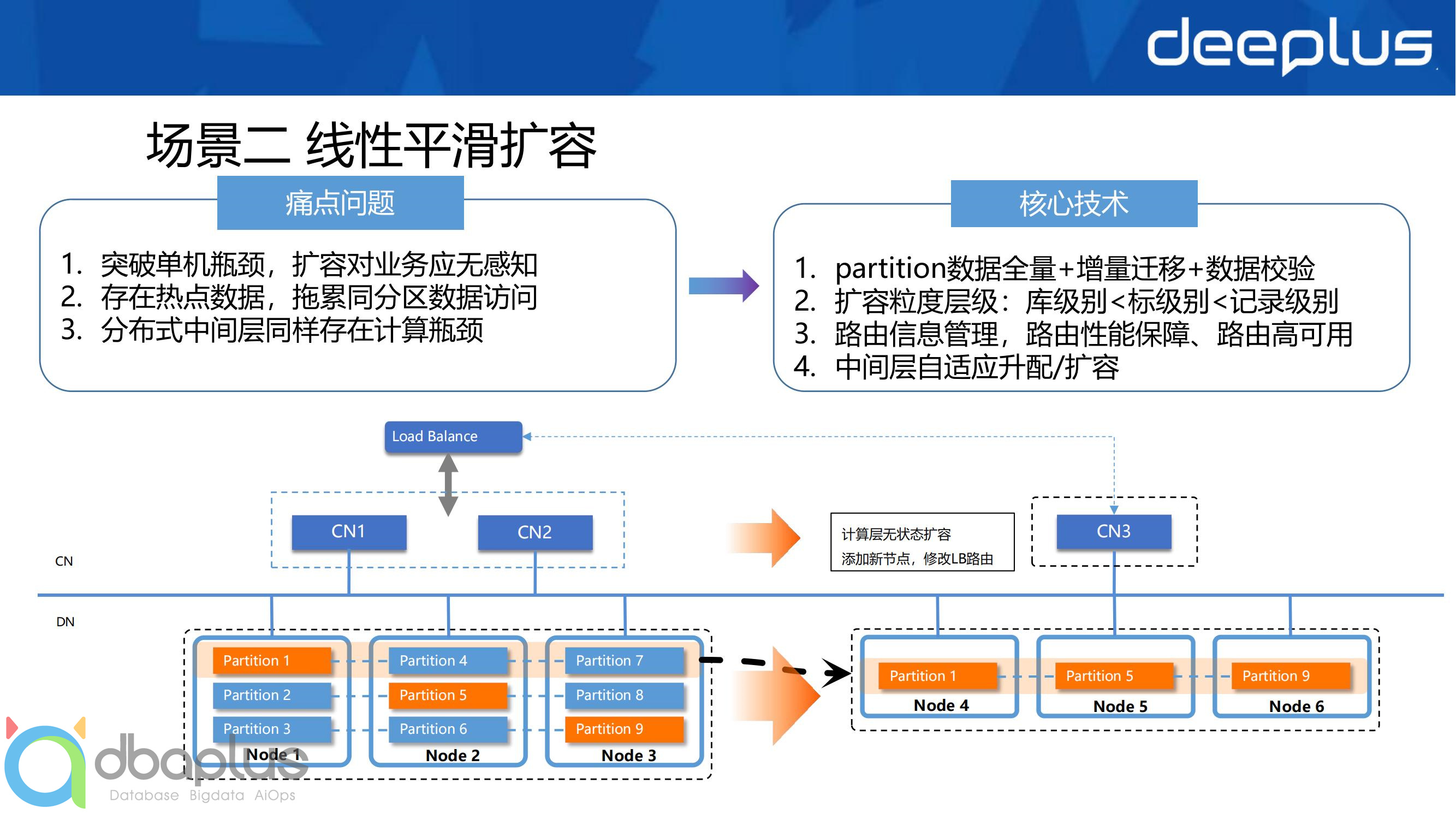
平滑扩容能力,是分布式中间件的核心技术竞争力,业务无感是最高境界,但很难真正做到
扩容时可操作的数据粒度是把双刃剑,业务灵活性和运维便利度,不可兼得
拆分键级别的数据迁移与扩容,是解决数据库热点问题的良药
扩容的最高境界,是底层数据节点和中间件计算层的自适应弹性伸缩,目前看来,与云原生数据库相结合是解决之道

3)场景三
此方案主要是对分布式数据库中间件路由灵活性的考验
访问实效性和频率允许条件下,归档库或归档存储甚至可以是冷设备,需要时可自动加电加载
可以为归档库的OLAP访问,配置专属MPP架构的中间件proxy层,既达到并行计算加速效果,又实现了资源与OLTP业务隔离,避免争抢

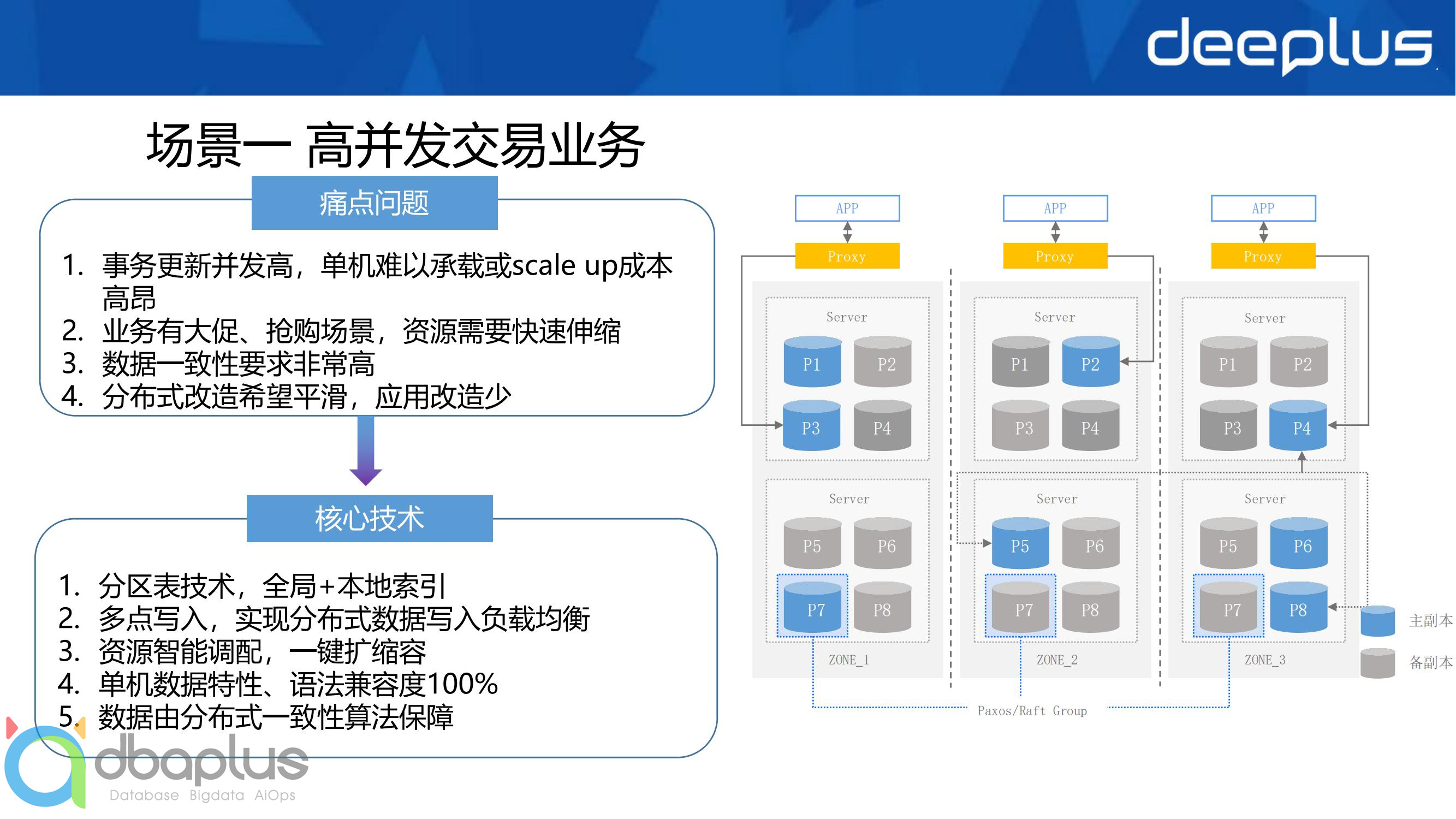
1)场景一
一大优势是资源自动化管理,将新机器加入资源池,在开启数据rebalance条件下,会自动进行迁移和均衡,这也是资源弹性伸缩能力的基础
以此架构为基础,上层理论上可以兼容各种数据库的接口,提供平滑的数据库迁移体验
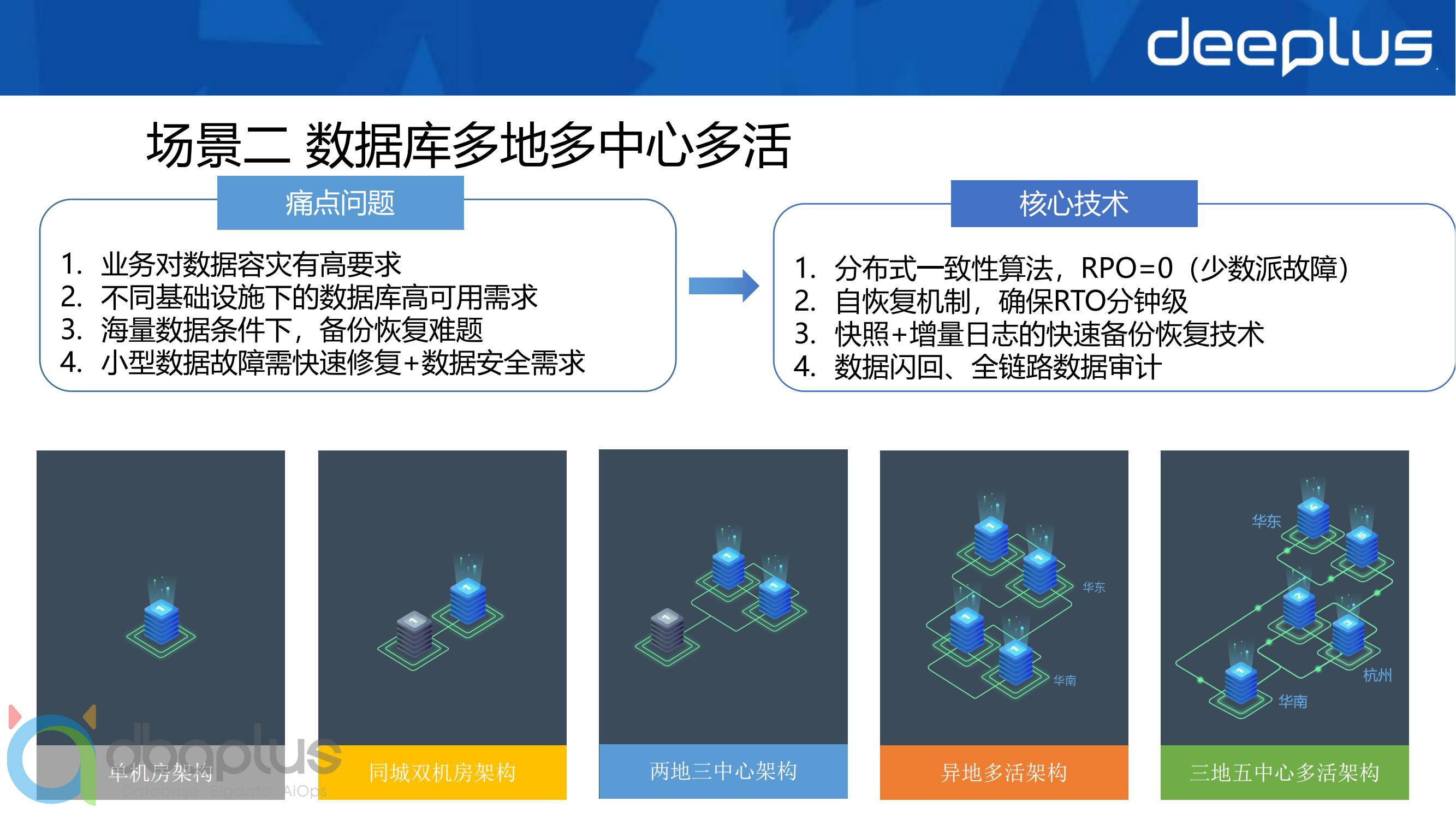
2)场景二
从单机房的机架位级别容灾,到两点三中心的机房级别容灾,如采用传统数据库的主从复制架构来做同步,都会遭遇一致性和可用性的两难问题,需要数据稽核、数据修复等多重保险机制,带来复杂的应用和数据库开发难度
原生分布式数据库通过集群化存储的分布式一致性算法,确保了强一致性和写入效率的同时,只要是少数派节点故障,也可确保数据库服务的可用性
多活架构不仅对数据库有要求,对应用多个分层也有流量纠错的严格要求,还需要数据库自身具备防写错能力,需要整体设计方案
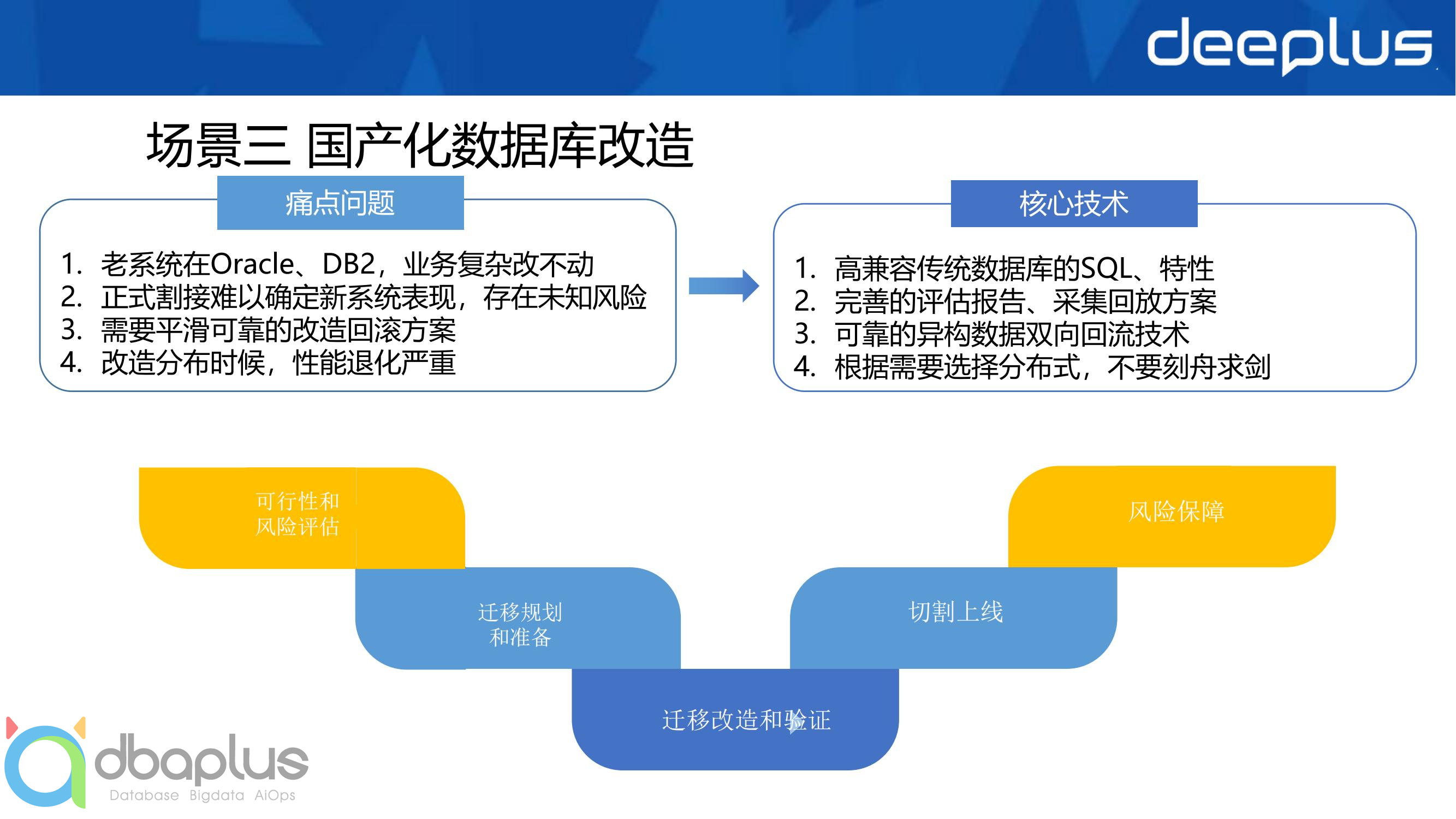
3)场景三
国产化数据库改造,不是必须选择分布式方案,但分布式往往是国产化数据库相对传统单机数据库弯道超车的优势所在,如果选用国产单机数据库,会陷入田忌赛马的被动局面
采集回放技术是这其中的关键一环,是迁移后数据库功能特性和性能不退化的有力保证
使用分布式数据库改造后,需要拆分的表,才进行分区表设计,不要“因为用了分布式,就都要分布式表”

四、关系型分布式数据库总结与展望

一句话总结:技术没有银弹,不存在最好的数据库产品、一劳永逸的分布式数据库架构方案,只有针对具体业务场景的最适合的方案。
分布式数据库中间件,特别适合数据具有天然分片特征的场景,但在SQL研发上有要求,避免非拆分键查询和分布式事务,不然吞吐会非常差。
原生分布式数据库,适合对资源弹性伸缩,可用性和强一致性要求高的场景,与传统数据库的兼容度好,但架构往往不典型,运维难度略高,使用上分布式执行计划的优化也需要技巧。
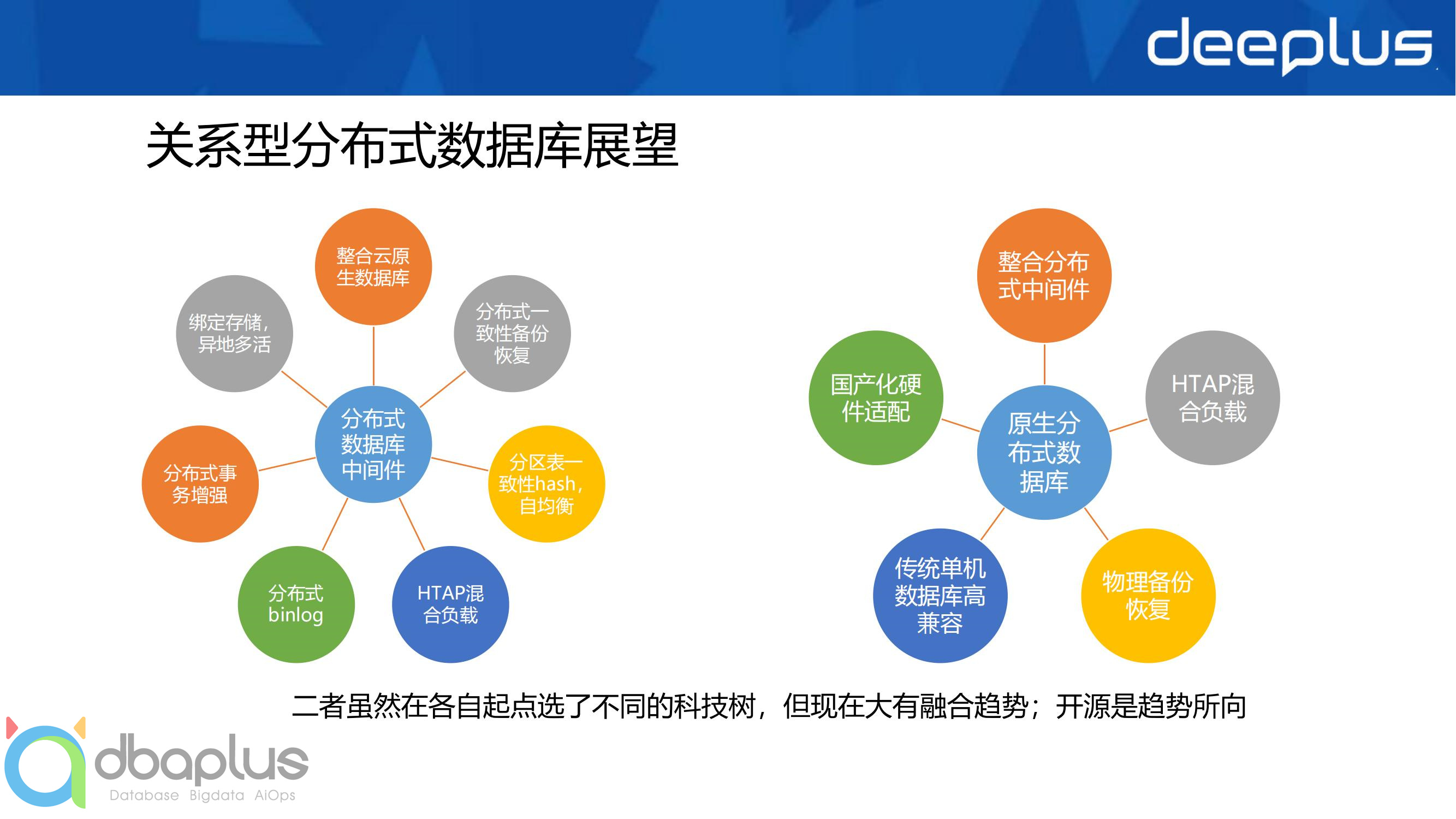
值得一说到的是,分布式中间件产品现在通过自适应分区表,数据一致性hash,统一binlog服务等新特性的研发,越来越像原生分布式数据库靠拢;原生分布式数据库同样,不能完全摆脱实现数据透明水平拆分的中间件方案,相信二者的边界未来会逐渐模糊。
运维原生分布式数据库的架构与传统数据库差异较大,需要相关人才的积累,使用经验的沉淀和分享,这也是其拥抱开源社区,努力发展技术生态的重要原因。
Q&A
Q2:中间件的分布式数据库,针对业务的一些复杂多条件查询,有一些经验可以分享一下吗?
获取本期PPT,请添加群秘微信号:dbachen
↓点这里可回看本期直播
阅读原文








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721