
平台主要包括分布式数据访问中间件(SDK、Proxy)、平滑扩容、数据集成、管控平台等四部分。
一、分布式数据访问中间件
数据拆分后,分散在多个库与表中,但应用开发时怎样才能准确访问数据库,换言之,如何才能拿到准确的数据库连接,拼接出正确的sql(主要是实际表名),然后执行返回结果集呢?
为了尽可能减少业务侵入性,应用少做改造,往往都会抽象出一个数据访问层负责上述功能。数据访问层按实现方式不同,可分为应用自定义、数据中间件、分布式数据库三种方式,在我们项目中采用的是中间件方式,其技术架构如下:
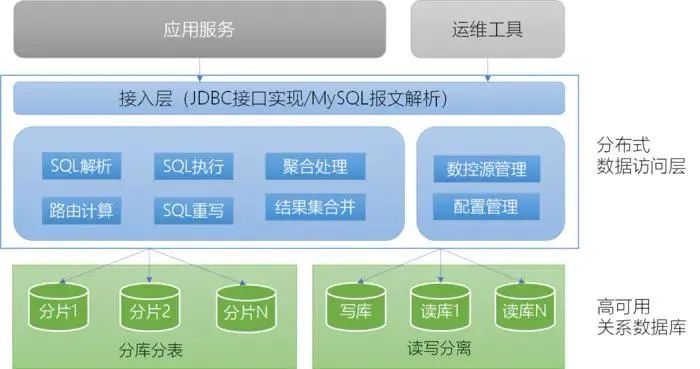
分布式数据访问层
按照接入方式不同,数据访问中间件可以分为SDK、Proxy(云原生架构下可能还会有sidecar方式)。
一个典型的分库分表中间件由JDBC接口实现(SDK模式)、MySQL报文解析(Proxy、Sider模式)、SQL解析器,路由计算、SQL重写, SQL执行、聚合处理、结果集合并、数据源管理、配置管理等部分构成。
JDBC接口实现起来并不太难,数据库连接池都是基于此实现,本质上就是一种装饰器模式,主要就是java.sql与javax.sql包下DataSource、Connection、Statement,PreparedStatement,ResultSet、DatabaseMetaData、ResultSetMetaData等接口。这些接口也并不是都需要实现,不常用的接口可在集成一些框架时根据需要再实现。
MySQL报文解析比JDBC接口复杂些,它包含了很多MySQL的命令,需要对照MySQL报文规范分别进行解析,另外由于proxy还要支持常见DBA工具接入,比如MySQL CLI、Navicat、Dbvisualizer、MySQL workbench等,这些工具甚至不同版本使用的MySQL报文都不完全一样,这块的兼容性也是一个繁琐的工作,考验对Mysql报文的支持的完整度。这部分像Sharding-Proxy、Mycat等都有实现,如果要自行研发或者扩展优化,可参考其实现细节。
MySQL报文规范:https://dev.mysql.com/doc/internals/en/client-server-protocol.html
SQL解析是个繁琐复杂的活儿,对应就是词法Lexer与语法分析Parser,因为要最大程度兼容各数据库厂商SQL,这块是需要不断的迭代增强的。开源的手写解析器有阿里开源的druid,也可以使用javacc、antlr等进行实现,相比手写解析器速度要慢些,但扩展定制化能力更好。这类解析器在使用方式上,多采用vistor设计模式,如果需要可以编写自己的vistor从而获取所需AST(Abstract Syntax Tree)中的各类值。
路由计算是根据SQL解析后AST,提取分库分表列值(提取规则是预先配置好的),然后根据应用指定的运算表达式或者函数进行计算,分别得到数据库与表对应的序号(一般就是一个整型数值,类似一个数组下标)或者是真正的物理表名。读写分离模式下,只涉及库路由,会根据一个负载均衡算法选取一个合适的物理库,如果写SQL则会选择主库,如果是读则会按照随机、轮询或者权重等算法选择一个从库。
SQL重写主要为表名添加后缀(应用写SQL时是逻辑表名,实际表名往往是逻辑表名+序号),根据路由计算环节得到的物理表名,替换原SQL中的逻辑表名。另外SQL中有聚合函数、多库表分页等操作时,也会涉及到对SQL的改写,这部分有的开源中间件里也叫做SQL优化。注意这里最好不要简单的用字符串匹配去替换表名,例如当存在列名与表名一样的情况下会出现问题。
SQL执行负责SQL的真正执行,对应的就是执行连接池或数据库驱动中Statement的execute、executeQuery、executeUpdate、executeBatch等方法。当然如果是涉及到多库多表的SQL,例如where条件不包含分库分表键,这时会涉及到库表扫描,则需要考虑是连接优先还是内存优先,即采用多少个并发数据库连接执行,连接数太大则会可能耗尽连接池,给内存以及数据库带来很大压力;但连接数太小则会拉长SQL执行时间,很有可能带来超时问题,所以一个强大的SQL执行器还会根据SQL类型、数据分布、连接数等因素生成一个到合适的执行计划。
数据源管理负责维护各数据库的连接,这块实现起来比较简单,一般维护一个数据库连接池DataSource对象的Map就可以,只要根据数据源下标或者名称可以拿到对应的数据库连接即可。
聚合处理负责对聚合类函数的处理,因为分库分表后,实际执行的SQL都是面向单库的,而对于max、min、sum、count、avg等聚合操作,需要将各单库返回的结果进行二次处理才能计算出准确的值,例如max、min、sum、count需要遍历个各库结果,然后分别取最大、最小、累加,对于avg操作,还需要将原SQL修改为select sum,count,然后分别累加,最后用累积后的sum除以累加后count才能得到准确值。另外对于多库表的分页操作,例如limit 1,10,则将单库SQL的起始页都修改为第一页即limit 0,10,然后再整体排序取出前10个才是正确的数据。
结果集合并负责将多个SQL执行单元返回的数据集进行合并,然后返回给调用客户端。一般当进行库表遍历、或者涉及多个库SQL(例如使用in时)会需要进行合并。当然并不一定需要把数据全部读到内存再合并,有时基于数据库驱动实现的ResultSet.next()函数,逐条从数据库获取数据即可满足要求。关于结果集合并,sharding-jdbc对此有一个更丰富的抽象与分类,支持流式归并、内存归并、分组归并等,具体可参见归并引擎。
归并引擎:https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/merge/
配置管理负责分库分表的规则以及数据源的定义,这块是面向应用开发者的,在使用体验上应当简单、易用、灵活。其中会涉及到物理数据源(参数跟连接池类似)、逻辑表、路由规则(库路由、表路由,库表分布,支持指定java函数或者groovy表达式),逻辑表->路由规则的映射关系。另外我们在实践时还包括了一些元数据信息,包括shardID->库表序号,这样做有个好处,业务在配置路由规则时只需要关注业务对象->shardID即可。配置管理在具体形式方面,可以支持xml、yaml、也支持在管控平台上在线进行配置,后者会通过将配置同步到配置中心,进而支持数据访问层进行编排(orchestration),例如在线扩容时需要动态增加数据源、修改路由规则、元数据信息等。
一个完整的分布式数据访问中间件,在架构上和数据库的计算层很像,尤其如果涉及到DB协议报文与SQL的解析,还是一个复杂和工作量较大的工程,因此一般应用团队建议还是采用开源成熟的方案,基于此做定制优化即可,没必要重复造轮子。
SDK和Proxy方式各有优缺点,在我们项目中分别用在不同的场景,简单总结如下:
联机交易 高频、高并发,查询带拆分键,数据量小,sdk方式;
运维 低频、查询条件灵活,数据量大,以查询为主 proxy方式;
批量 不携带分库分表列,数据量大,查询、更新、插入、删除都有,通过API指定库表方式。
接下来介绍下我们在开源中间件方面的实践,分为三个阶段:
第一阶段
早些年这类开源中间件还挺多,但其实都没有一个稳定的社区支持。2015年时我们基于一个类似TDDL的组件,对其事务、数据连接池、SQL解析等方面进行了优化,修复了数十个开发遇到的bug,实现SDK版本的数据访问中间件,暂就叫做DAL。
第二阶段
2017年,系统上线后发现,开发测试以及运维还需要一个执行分库分表SQL的平台,于是我们调研了Mycat,但当时1.6版本只支持单维度拆分(单库内分表或者只分库),因此我们重写了其后端SQL路由模块,结合原SDK版本数据组件,利用Mycat的报文解析实现了Proxy的数据访问层。
Proxy模式的数据访问层上线后,可以很好的应对带分库分表键的SQL操作,但在涉及到库表遍历时,由于并发连接太多,经常会导致连接数不够,但如果串行执行则经常导致执行时间太长,最后超时报错。针对这个问题,我们做了个新的优化:
在将这类库表遍历的查询在生成执行计划时,通过union all进行了改写,类似map-reduce,同一库上的不同表的sql通过union all合并,然后发到数据库执行,这样连接数=物理数据库总数,同时尽可能的利用了数据库的计算能力,在损耗较少连接数的前提下,大大提升了这类SQL的执行效率。(注意order by 和limit需要加在union all的最后,为了不影响主库,可以将这类查询在从库执行)。
例如user表拆分成1024表,分布在4个库,SQL拆分与合并示意图如下:

通过union all实现库表遍历
第三阶段
这两个中间件在运行3年左右后,也暴露出来了很多问题,例如SQL限制太多,兼容性太差,开源社区不活跃,部分核心代码设计结构不够清晰等,这给后续更复杂场景的使用带来了很多桎梏。因此在19年,我们决定对数据访问层进行升级重构,将底层分库分表组件与上层配置、编排进行剥离,改成插拔式设计,增加更加多元的分库分表组件。在那时开源社区已经涌现了一些优秀的分库分表项目,目前来看做的最好的就是shardingshpere(后面简称ss)了,ss的设计与使用手册其官网都有详细介绍,这里主要简单介绍下我们集成ss的一些实践。
shardingsphere整体设计架构清晰,内核各个引擎设计职责明确,jdbc 与proxy版本共享内核,接入端支持的多种实现方式。治理、事务、SQL解析器分别单独抽象出来,都可以hook方式进行集成,通过SPI进行扩展。这种灵活的设计也为我们定制带来了很大的方便,代码实现上比较优雅。我们在集成时开始是3.0.0版本,后来升级到4.0.0-RC1版本,目前ss已发布4.0.0的release版本。
1)配置兼容
因为要在上层应用无感知的情况下更换底层分库分表引擎,所以改造的第一个问题就是兼容以前的配置。基于此,也就无法直接使用sharding-jdbc的spring或者yaml配置方式,而改用API方式,将原配置都转换为sharding-jdbc的配置对象。这块工作量时改造里最大的,但如果项目之前并没有分库分表配置,则直接在sharding-jdbc提供的方式中选择一种即可。由于我们项目中需要支持规则链、读权重等ss不支持功能,所以我们是基于ComplexKeysShardingAlgorithm接口进行的实现。
更简洁的yaml配置形式:
ds:
master_0:
blockingTimeoutMillis: 5000
borrowConnectionTimeout: 30
connectionProperties: {}
idleTimeoutMinutes: 30
jdbcUrl: jdbc:mysql://localhost:3306/shard_0
logAbandoned: false
maintenanceInterval: 60
maxConn: 10
maxIdleTime: 61
minConn: 1
userName: root
password: 123456
queryTimeout: 30
testOnBorrow: false
testOnReturn: false
testQuery: null
testWhileIdle: true
timeBetweenEvictionRunsMillis: 60000
master_1:
jdbcUrl: jdbc:mysql://localhost:3306/shard_1
parent: master_0
groupRule: null
shardRule:
bindingTables:
- user,name
rules:
userTableRule:
dbIndexs: master_0,master_1
dataNodes: master_0.user_${['00','01']},master_1.user_${['02','03']}
dbRules:
- return test.dal.jdbc.shardingjdbc.YamlShardRuleParser.parserDbIndex(#user_id#)
- return test.dal.jdbc.shardingjdbc.YamlShardRuleParser.parserDbIndexByName(#name#,#address#)
tbRules:
- return test.dal.jdbc.shardingjdbc.YamlShardRuleParser.parserTbIndex(#user_id#)
- return test.dal.jdbc.shardingjdbc.YamlShardRuleParser.parserTbIndexByName(#name#,#address#)
tableRuleMap: {name: nameTableRule, user: userTableRule}
2)事务级别
sharding-jdbc的默认事务是local,即最大努力一阶段提交,或者叫链式提交,这种方式的好处是对应用透明,性能也还不错,互联网中使用较多。但这种方式可能会由于网络等原因导致部分提交成功,部分失败。虽然这种概率可能并不高,但一旦出现则会产生事务不一致的问题,这在金融关键场景下风险是很高的。所以我们在联机交易场景下禁止使用这种方式,而是要求必须严格单库事务,我们在先前SDK版本的数据访问中间件增加了校验,一旦跨库就直接抛异常。因此切换到sharding-jdbc,这种事务级别也要继续支持。实现代码片段:
/**
* Single DB Transaction Manager
* SPI: org.apache.shardingsphere.transaction.spi.ShardingTransactionManager
*/
@NoArgsConstructor
public class SingleDBTransactionManager implements ShardingTransactionManager {
private Map<String, DataSource> dataSources = new HashMap<String, DataSource>();
private ThreadLocal<String> targetDataSourceName = new ThreadLocal<String>() {
protected String initialValue() {
return null;
}
};
private ThreadLocal<Connection> connection = new ThreadLocal<Connection>() {
protected Connection initialValue() {
return null;
}
};
private ThreadLocal<Boolean> autoCommitted = new ThreadLocal<Boolean>() {
protected Boolean initialValue() {
return true;
}
};
@Override
public void close() throws Exception {
if (connection.get() != null) {
connection.get().close();
}
}
@Override
public void init(DatabaseType databaseType, Collection<ResourceDataSource> resourceDataSources) {
for (ResourceDataSource res : resourceDataSources) {
dataSources.put(res.getOriginalName(), res.getDataSource());
}
}
@Override
public TransactionType getTransactionType() {
return TransactionType.SINGLEDB;
}
@Override
public Connection getConnection(String dataSourceName) throws SQLException {
if (!ConditionChecker.getInstance().isMultiDbTxAllowed() && targetDataSourceName.get() != null
&& !targetDataSourceName.get().equals(dataSourceName)) {
throw new TransactionException(
"Don't allow multi-db transaction currently.previous dataSource key="
+ targetDataSourceName.get() + ", new dataSource key=" + dataSourceName);
}
targetDataSourceName.set(dataSourceName);
if (connection.get() == null) {
connection.set(dataSources.get(dataSourceName).getConnection());
}
return connection.get();
}
…
}
3)读库权重
虽然多个从库(一个主一般都要挂两个或者三个从,从库的数量由RPO、多活甚至监管要求等因素决定)可以提供读功能,但细分的话,这些从库其实是有“差别”的,这种差异性有可能是由于机器硬件配置,也可能是由于所在机房、网络原因导致,这种时候就会需要支持读权限的权重配置,例如我们项目中有单元化的设计,需要根据当前所在单元及权重配置路由到当前机房的从库。另外也可以通过调整权重,支持在线对数据库进行维护或者升级等运维操作。实现代码片段:
/**
* Weight based slave database load-balance algorithm.
* SPI: org.apache.shardingsphere.spi.masterslave.MasterSlaveLoadBalanceAlgorithm
*/
public final class WeightMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
public final static String TYPE = "WEIGHT";
protected DataSource dataSource;
public WeightMasterSlaveLoadBalanceAlgorithm(DataSource ds) {
this.dataSource = ds;
}
public WeightMasterSlaveLoadBalanceAlgorithm(){
}
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {
String selectReadDb = dataSource.getTableRuleContext().getGroupRule(name).selectReadDb();
return slaveDataSourceNames.contains(selectReadDb) ? selectReadDb : null;
}
@Override
public String getType() {
return TYPE;
}
4)SQL开关
SDK模式的数据访问中间件,主要用在联机交易中,在这类场景下,是没有DDL操作需求的,也是不允许的,但shading-jdbc作为一个通用的数据分片中间件。对此并没有相应的开关配置,因此我们增加开关功能,应用在默认情况下,对DDL、DCL等语句进行了校验,不允许执行该类SQL,在技术层面杜绝了应用的误用。实现代码片段:
//SPI: org.apache.shardingsphere.core.parse.hook.ParsingHook
public class AccessPrevilegeCheckHook implements ParsingHook {
@Override
public void start(String sql) {
}
@Override
public void finishSuccess(SQLStatement sqlStatement, ShardingTableMetaData shardingTableMetaData) {
ConditionChecker.getInstance().checkDdlAndDcl(sqlStatement);
}
…
}
//SPI:org.apache.shardingsphere.core.rewrite.hook.RewriteHook
@NoArgsConstructor
public class TableScanCheckHook implements RewriteHook {
private List<TableUnit> tableUnits = new LinkedList<TableUnit>();
@Override
public void start(TableUnit tableUnit) {
if(tableUnits.size() > 0 && !ConditionChecker.getInstance().isTableScanAllowed()){
throw new RouteException("Don't allow table scan.");
}
tableUnits.add(tableUnit);
}
…
}
public class ConditionChecker {
private static ThreadLocal<SQLType> sqlTypeSnapshot = new ThreadLocal<SQLType>();
private boolean defalutTableScanAllowed = true;
private boolean defalutMultiDbTxAllowed = true;
private boolean defalutDdlAndDclAllowed = true;
private static ConditionChecker checker = new ConditionChecker();
public static ConditionChecker getInstance() {
return checker;
}
private ConditionChecker() {
}
private ThreadLocal<Boolean> tableScanAllowed = new ThreadLocal<Boolean>() {
protected Boolean initialValue() {
return defalutTableScanAllowed;
}
};
private ThreadLocal<Boolean> multiDbTxAllowed = new ThreadLocal<Boolean>() {
protected Boolean initialValue() {
return defalutMultiDbTxAllowed;
}
};
private ThreadLocal<Boolean> ddlAndDclAllowed = new ThreadLocal<Boolean>() {
protected Boolean initialValue() {
return defalutDdlAndDclAllowed;
}
};
public void setDefaultCondtion(boolean tableScanAllowed, boolean multiDbTxAllowed, boolean ddlAndDclAllowed) {
defalutTableScanAllowed = tableScanAllowed;
defalutMultiDbTxAllowed = multiDbTxAllowed;
defalutDdlAndDclAllowed = ddlAndDclAllowed;
}
public boolean isTableScanAllowed() {
return tableScanAllowed.get();
}
public void setTableScanAllowed(boolean tableScanAllowed) {
this.tableScanAllowed.set(tableScanAllowed);
}
public boolean isMultiDbTxAllowed() {
return multiDbTxAllowed.get();
}
public void setMultiDbTxAllowed(boolean multiDbTxAllowed) {
this.multiDbTxAllowed.set(multiDbTxAllowed);
}
public boolean isDdlAndDclAllowed() {
return ddlAndDclAllowed.get();
}
public void setDdlAndDclAllowed(boolean ddlAllowed) {
this.ddlAndDclAllowed.set(ddlAllowed);
}
public SQLType getSqlTypeSnapshot() {
return sqlTypeSnapshot.get();
}
public void checkTableScan(boolean isTableScan) {
if (!isTableScanAllowed())
throw new ConditionCheckException("Don't allow table scan.");
}
public void checkDdlAndDcl(SQLStatement sqlStatement) {
sqlTypeSnapshot.set(sqlStatement.getType());
if (!isDdlAndDclAllowed()
&& (sqlStatement.getType().equals(SQLType.DDL) || sqlStatement.getType().equals(SQLType.DCL))) {
throw new ConditionCheckException("Don't allow DDL or DCL.");
}
}
public void checkMultiDbTx(Map<String, Connection> cachedConnections, String newDataSource) {
if (!isMultiDbTxAllowed() && cachedConnections.size() > 0 && !cachedConnections.containsKey(newDataSource)) {
throw new ConditionCheckException("Don't allow multi-db transaction currently.old connection key="
+ cachedConnections.keySet() + "new connection key=" + newDataSource);
}
}
}
5)路由规则链
在我们项目中,对于一张表,在不同场景下可能会使用不同的分库分表列,例如有的是账号、有的是客户号(这两列都可路由到同一库表中),这时候就需要路由模块可以依次匹配搭配多个规则,例如SQL中有账号则用account-rule,有客户号则用customer-rule,因此我们支持了规则链配置功能,但sharding-jdbc只支持配置一个路由规则,因此在自定义路由算法函数中,我们增加了对规则链的支持。实现代码片段:
public abstract class ChainedRuleShardingAlgorithm implements ComplexKeysShardingAlgorithm {
protected final DataSource dataSource;
public ChainedRuleShardingAlgorithm(DataSource ds) {
this.dataSource = ds;
}
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
List<String> targets = new ArrayList<String>();
Set<String> actualNames = HintManager.isDatabaseShardingOnly() ? getHintActualName(shardingValue)
: calculateActualNames(shardingValue);
for (String each : actualNames) {
if (availableTargetNames.contains(each)) {
targets.add(each);
}
}
clear();
return targets;
}
@SuppressWarnings({ "serial", "unchecked" })
protected Set<String> calculateActualNames(ComplexKeysShardingValue shardingValue) {
Set<String> target = new HashSet<String>();
Map<String/* table */, Map<String/* column */, Collection/* value */>> shardingMap = new HashMap<String, Map<String, Collection>>();
String logicalTableName = shardingValue.getLogicTableName();
Map<String, Collection> shardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
for (final Entry<String, Collection> entry : shardingValuesMap.entrySet()) {
if (shardingMap.containsKey(logicalTableName)) {
shardingMap.get(logicalTableName).put(entry.getKey(), entry.getValue());
} else {
shardingMap.put(logicalTableName, new HashMap<String, Collection>() {
{
put(entry.getKey(), entry.getValue());
}
});
}
}
// 遍历规则链,查询匹配规则
for (String tableName : shardingMap.keySet()) {
RuleChain ruleChain = dataSource.getTableRuleContext().getRuleChain(tableName);
for (GroovyListRuleEngine engine : getRuleEngine(ruleChain)) {
Set<String> parameters = engine.getParameters();
Map<String, Collection> columnValues = shardingMap.get(tableName);
Set<String> eval = eval(columnValues, parameters, engine, ruleChain);
if (eval.size() > 0) {// 匹配即中止
target.addAll(eval);
return target;
}
}
}
return target;
}
@SuppressWarnings("unchecked")
protected Set<String> eval(final Map<String, Collection> columnValues, Set<String> parameters,
GroovyListRuleEngine engine, RuleChain ruleChain) {
Set<String> targetNames = new HashSet<String>();
if (columnValues.keySet().containsAll(parameters)) {// 匹配
List<Set<Object>> list = new LinkedList<Set<Object>>();// 参数集合
List<String> columns = new LinkedList<String>();// 列名集合
for (final String requireParam : parameters) {
list.add(convertToSet(columnValues.get(requireParam)));
columns.add(requireParam);
}
Set<List<Object>> cartesianProduct = Sets.cartesianProduct(list);
for (List<Object> values : cartesianProduct) {
Map<String, Object> arugmentMap = createArugmentMap(values, columns);
int index = engine.evaluate(arugmentMap);
targetNames.add(getActualName(ruleChain, index));
}
}
return targetNames;
}
private Set<Object> convertToSet(final Collection<Object> values) {
return Sets.newLinkedHashSet(values);
}
private Map<String, Object> createArugmentMap(List<Object> values, List<String> columns) {
HashMap<String, Object> map = new HashMap<String, Object>();
for (int i = 0; i < columns.size(); i++) {
map.put(columns.get(i).toLowerCase(), values.get(i));
}
return map;
}
protected abstract List<GroovyListRuleEngine> getRuleEngine(RuleChain ruleChain);
protected abstract String getActualName(RuleChain ruleChain, int index);
}
/**
* 库路由算法
*/
public class ChainedRuleDbShardingAlgorithm extends ChainedRuleShardingAlgorithm {
public ChainedRuleDbShardingAlgorithm(DataSource ds) {
super(ds);
}
@Override
protected List<GroovyListRuleEngine> getRuleEngine(RuleChain ruleChain) {
return ruleChain.getDbRuleList();
}
@Override
protected String getActualName(RuleChain ruleChain,int index) {
//add mapping from shard metadata
String dbIndex = dataSource.getHintSupport().getShardingDb(String.valueOf(index));
if(StringUtils.isEmpty(dbIndex)){
return ruleChain.getTableRule().getDbIndexArray()[index];
}else{
return ruleChain.getTableRule().getDbIndexArray()[Integer.valueOf(dbIndex)];
}
}
}
/**
* 表路由算法
*/
public class ChainedRuleTableShardingAlgorithm extends ChainedRuleShardingAlgorithm {
public ChainedRuleTableShardingAlgorithm(DataSource ds) {
super(ds);
}
@Override
protected List<GroovyListRuleEngine> getRuleEngine(RuleChain ruleChain) {
return ruleChain.getTableRuleList();
}
@Override
protected String getActualName(RuleChain ruleChain, int index) {
//add mapping from shard metadata
String tbShardIndex = dataSource.getHintSupport().getShardingTable(String.valueOf(index));
int tbIndex = index;
if(!StringUtils.isEmpty(tbShardIndex)){
tbIndex = Integer.valueOf(tbShardIndex);
}
SuffixManager suffixManager = ruleChain.getTableRule().getSuffixManager();
if(suffixManager.isInlineExpression()){
return ruleChain.getTbIndexs()[tbIndex];
}else{
Suffix suffix = suffixManager.getSuffix(0);
return String.format("%s%s%0"+suffix.getTbSuffixWidth() +"d", ruleChain.getLogicTable(),suffix.getTbSuffixPadding(), suffix.getTbSuffixFrom() + tbIndex);
}
}
6)管控平台对接
我们提供了一个管控平台,支持分布式数据相关组件在线配置,这些通过配置中心统一下发到各应用,而且支持动态变更。不管是SDK模式还是Proxy模式的数据访问中间件都使用的是同一份分库分表配置,只是接入方式不同而已。因此在集成ss的时候,还需要增加从配置中心获取配置的功能,这块主要涉及的调用配置中心API获取配置,这里就不贴具体代码了。
数据访问中间件的发展演进方向,未来其将会是多种形态的混合存在。

分布式数据访问中间件的三种模式
二、平滑扩容
在设计篇中已经介绍了扩容的机制,简单的说,平滑扩容就是通过异步复制,等数据接近追平后禁写,修改路由,然后恢复业务。主要目的是自动化、以及尽可能缩短停机窗口,目前一些云产品比如阿里云DRDS、腾讯云TDSQL等的一键在线扩容本质上都是基于此机制。
但实践中这个过程需要多个步骤,数据库数量越多,操作风险越大,而且需要停机完成。为此我们与数据库团队一起设计与开发了平滑扩容功能。
我们将整个扩容环节,分为配置、迁移、校验、切换、清理五个大的步骤,每个步骤里又由多个任务构成。扩容任务在管控平台上建立,平滑扩容模块自动依次触发各个任务。
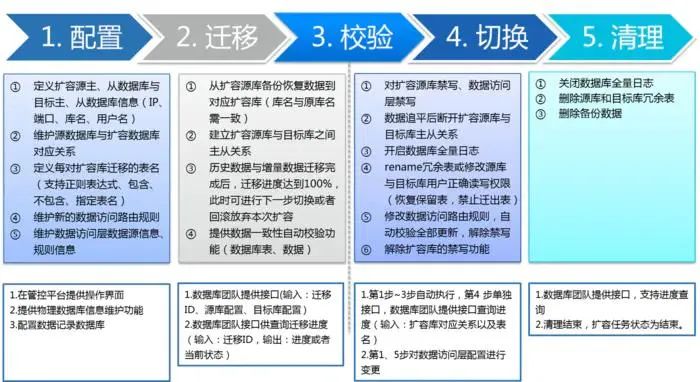
平滑扩容
配置环节,主要是应用系统方定义扩容后的分库分表配置;
迁移环节,依次自动完成从复制,同时进行数据校验;
切换环节,首先进行禁写,断开主从只从,然后修改路由规则,最后再解除扩容库禁写。整个过程应用无需停机,仅仅会有一段时间禁写,这个时间一般来说也就十来秒;
清理环节,清理环节是在后台异步处理,即清理数据库冗余表。
在分布式数据服务管控平台定义好扩容前后分库分表配置后,即可启动一键在线扩容。在扩容过程中可实时监控扩容进度,同时支持扩容中断恢复以及回滚。
三、数据集成
微服务架构下,有大量需要数据集成的场景:
业务系统之间,例如下订单后需要通知库存、商家,然后还要推送到大数据等下游系统;
分库分表后,为了应对其它维度查询,会需要建立异构索引,这样就需要数据传输到另外一套数据库中;
系统内应用与中间件之间,例如如果使用redis等缓存,在操作完数据库还要更新缓存,类似这类数据集成需求,最朴素的解决方式就是双写,但双写一个问题是增加了应用复杂性,另外当发生不一致的情况是难以处理。
这类问题本质上也属于分布式事务场景,一种简单的方式就是基于MQ可靠消息,即在应用端写消息表,然后通过MQ消费消息进行数据集成处理。但这导致应用代码耦合大量双写逻辑,给应用开发带来很多复杂度。
针对双写问题,业界一种更优雅、先进的设计是基于日志的集成架构,在OLTP场景下,可以通过解析数据库日志类似CDC,这种方式的好处是数据集成工作从应用代码中进行了剥离。
关于双写以及基于日志集成架构可参考Using logs to build a solid data infrastructure (or: why dual writes are a bad idea
双写以及基于日志集成架构参考:https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
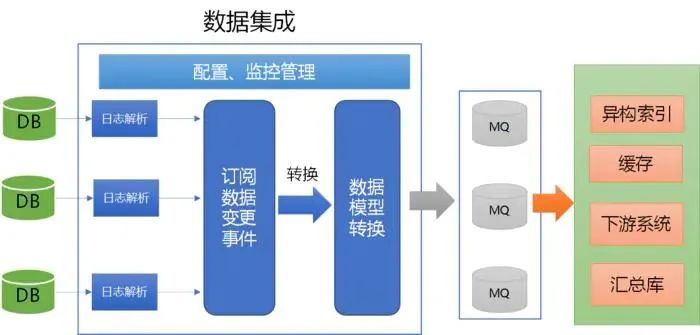
数据集成
这类CDC的开源软件,java类的有shyiko、canal、debezium等。这类项目的实现原理是主要模拟从库从主库异步获取日志事件,然后经过ETL发送到MQ或者其它下游系统。
如何模拟一个从库可参照MySQL复制协议:https://dev.mysql.com/doc/internals/en/replication-protocol.html
考虑功能完整性和社区活跃度,我们选择了基于canal构建数据集成中间件,具体工作原理这里就不介绍了,可参见canal github。这里主要介绍下我们对其做的一些定制和优化。
canal github:https://github.com/alibaba/canal
canal的配置非常繁杂,很容易配错,所以最先开始做的就是提供了一个更简单、易用的在线配置定义功能,用户是只需进行一些核心关键的配置,例如数据库的IP、用户、密码、订阅表、MQ地址,其它不常修改的配置通过模板形式提供,大大降低了配置复杂度和工作量,当然如果需要也完全支持自定义。
数据库binlog是有序的,但如果写MQ或者目标库,仍完全保证该顺序,那么则无法进行并发,这样同步的TPS是肯定上不去的,因此如何在保证一定顺序的前提下最大程度提高并发性能是一个需要结合业务场景解决的问题。
我们当时用的是canal1.1.3的版本,经过我们性能测试,数据写入kafka的TPS也就5000+,这对于结息等大量数据变更的场景是不能满足要求的。
另外canal写入MQ的并发维度是表的主键,但我们项目中表的主键都是自增列(这个是我们项目中数据库开发规范,主要目的是保证MySQL写性能),如果根据此列进行并发控制,那么则无法保证MQ写入时的业务顺序性。例如支付流水表,如根据主键(自增列)则无法保证同一账户流水的顺序性。
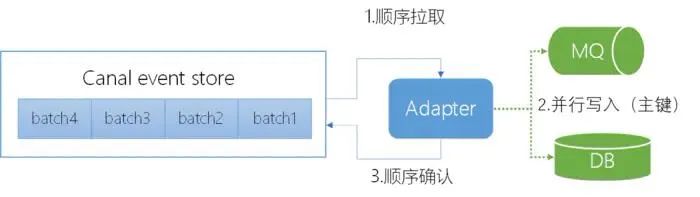
canal自身写入机制
针对此问题,我们对canal进行了改造,将原来只支持根据主键进行并发控制,修改为支持应用指定,例如我们项目采用业务唯一键;原来流程是顺序从canal server端读取binlog->写MQ->再确认->再读取下一binlog事件;调整后改为并发读取binlog,一旦在执行事件集中没有当前业务唯一键,就可直接写入MQ,后台开启一个线程,按照batchID依次进行ack,通过并行拉取binlog事件、分阶段无阻塞处理,单库数据同步kafak的TPS可以达到1.2W+,已可以满足结息等场景。

canal写入改造后机制
如果通过安装包部署,在用户配置完数据集成相关参数后,需要手工将canal server以及adapter包上传至服务器上。考虑到高可用,还得在备机上进行部署,在分库分表下,数据库拆分成多个,需要部署多个实列到多个服务器上(canal支持同个实例部署在统一server节点,但性能会受影响)。因此我们将canal server与adapter进行了容器化改造,然后部署到了统一的k8s集群中,这样用户在配置完后,点击“启动实列”按钮,即可在k8s环境中自动部署高可用的canal集群,从而实现了数据集成功能的serverless化。
通过数据集成中间件,可以在应用无侵入下解决分库分表后一个很典型的问题:多维度拆分与多库查询。例如将分库分表的数据再集中到一个汇总库,然后一些复杂的查询统计就可以放在汇总库上;还有一些多维度拆分场景,类似电商里的卖家库、商家库,需要创建“二级索引”,也可以通过数据中间件自动创建;另外也可以方便实现诸如小表广播等需要保证数据一致性的功能。
四、管控平台
前面提到的各种中间件,涉及到大量配置定义、实例管理、监控等功能,这些功能分散在各组件内部,缺少一个统一的视图,而且应用开发人员需要重复定义。因此我们设计开发了数据服务管控平台,将分库分表配置定义、在线扩容、运维、监控等功能统一集成,最大程度降低开发以及运维人员对数据拆分带来的复杂度。同时提供开放API,可以对接目前公司已有数据库以及云管理系统。
配置信息统一存放在配置中心,各中间件直接从配置中心拉取配置,在管控平台修改配置后,也可以实时通知各应用进行动态加载。管控平台相当于一个数据服务云管理平台,提供多租户,各应用无需自行部署,直接接入使用即可。在技术架构方面管控平台是个前后端分离架构,前端基于vue.js,后端按照功能模块拆分成微服务,都部署在k8s集群中。

管控平台
五、 感受
上面介绍了我们在数据服务平台建设中各技术组件的设计原理和实践,限于篇幅,更多实现细节就不展开介绍。
在企业软件这块,有两个不同的思路,一个是购买商业产品,一种是基于开源软件自行构建。在金融领域,早些年以前者为主,近些年后者则变成了趋势。开源软件有点是开放,因为有源码所以有自主掌控的可能与条件,缺点是不像商业产品功能完整,往往需要自行定制、优化、扩展。作为软件开发人员,我们更喜欢使用白盒而不是黑盒。
当然开源并不代表免费,有可能付出的成本比商业软件更高。一方面需要投入精力学习开源项目,只有熟悉源代码后才可能具备修改定制能力;另一方面要积极关注开源界技术的发展,与时俱进,要有开放的心态,吸取开源先进的设计的东西,大胆验证,谨慎使用。
作者介绍
温卫斌,就职于中国民生银行信息科技部,目前负责分布式技术平台设计与研发,主要关注分布式数据相关领域。
相关文章
《All in Cloud 时代,下一代云原生数据库技术与趋势》阿里巴巴集团副总裁/达摩院首席数据库科学家 李飞飞(飞刀)
《AI和云原生时代的数据库进化之路》腾讯数据库产品中心总经理 林晓斌(丁奇)
《ICBC的MySQL探索之路》工商银行软件开发中心 魏亚东
《金融行业MySQL高可用实践》爱可生技术总监 明溪源
《民生银行在SQL审核方面的探索和实践》民生银行 资深数据库专家 李宁宁
《OceanBase分布式数据库在西安银行的落地和实践》蚂蚁金服P9资深专家/OceanBase核心负责人 蒋志勇








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721