
何登成(花名:圭多),阿里云智能数据库产品事业部资深技术专家。从2005年开始一直坚守在数据库内核研发领域,先后在神州通用、网易和阿里从事数据库内核产品研发工作。
分布式事务是分布式数据库最难攻克的技术之一,分布式事务为分布式数据库提供一致性数据访问的支持,保证全局读写原子性和隔离性,提供一体化分布式数据库的用户体验。
本文主要分享分布式数据库中的时钟解决方案及分布式事务管理技术方案。混合逻辑时钟(HLC)可以实现本地获取,避免了中心时钟的性能瓶颈和单点故障,同时维护了跨实例的事务或事件的因果(happen before)关系。
本次的分享主要围绕以下两个方面:
时钟方案
分布式事务管理
一、时钟方案
数据库归根结底是为了将每一个事务进行排序。在单机上情况下,事务排序可以非常简单的实现,但是在分布式下如何进行事务排序?
数据库通过事务对外提供数据相关操作的ACID。数据库对事务顺序的标识决定了事务的原子性和隔离性。原子性指一个事务是完整的,既发生或不发生,代表每个事务都是独立的。隔离性指事务之间是相互隔离的。时钟有各种方式来标识一个事务的顺序,如Oracle每一个日志都有日志序列号LSN,事务ID,以及时间戳。
目前许多商业和开源数据库产品都支持MVCC,MVCC通过支持数据的多版本,允许读写相同数据,实现并发,在读多写少的场景下极大的提升了性能。
多版本出现之后,其本身就隐含了事务的顺序。当一个事务开始之后,需要确定哪个版本的数据是可见的和不可见的,所以这就涉及到了多体系,多版本和版本回收等问题。
一个很经典的场景,淘宝或天猫的购物场景,有一条商品记录,用户每买一个商品,就是对商品数量记录做一次扣减。商品记录版本会变的一个非常长,把所有的版本都保存起来是不合理的,否则整个存储容量就不断增加。那如何进行版本回收?在回收的时候也需要有顺序,确定应该回收哪些版本?
分布式数据库下的时钟和单机数据库下的时钟有什么区别?
首先,单机数据库的排序非常简单,通过日志序列号或事务ID就可以表示事务的顺序。在分布式数据库下,因为数据库运行在多台服务器上,每个数据库实例有独立的时钟或日志(LSN),每一个本地的时钟不能反映全局的顺序。
服务器之间会有时钟偏移,最理想情况是一个分布式数据库部署100个节点,100个节点的时钟是完全同步的。但实际情况下,在机房做越轨需要做时钟校对,因为服务器和服务器之间时钟点有快慢之差,所以分布式数据库下的时钟无法做全局设置的反映。
时钟解决方案有很多,如使用统一的中心节点,或者使用独立的服务器产生分布式时钟。
还有一种解决方案是逻辑时间,Lamport时钟是逻辑时钟。逻辑时钟指的是没有任何一个中心节点来产生时间,每一个节点都有自己本地的逻辑时间。
比如有十个Oracle数据库,每个节点有自己的LSN,如果节点的事务比较多,事务ID跑的就比较快。如果节点事务比较少,事务ID就跑得比较慢。
下图展示了目前主流的几种时钟解决方案,其中TIDB是国人的骄傲,TIDB使用的是中心时钟。除此之外,Postgres-XL使用了GTM,也属于中心时钟。Oracle使用的是逻辑时钟SCN。Cockraoch DB 是模仿Spanner做的分布式数据库,使用的是混合逻辑时钟。
还有最知名的Google Cloud Spanner,Spanner对硬件依赖比较高,使用的是Truetime。Truetime本质上是一个原子钟,通过原子钟授时确保两个服务器之间时钟偏移在很小的范围之内。
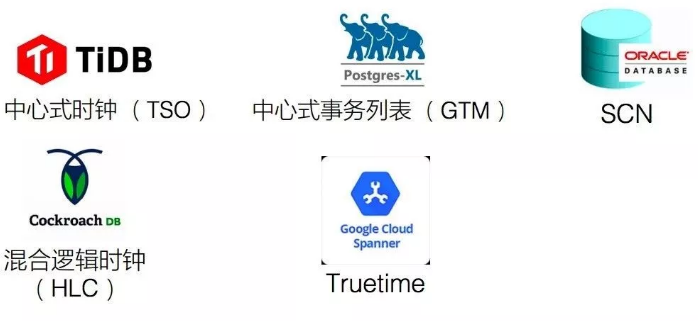
逻辑时钟在分布式环境下如何实现?如下图,有A、B和C,3个节点,每个节点会有自己的逻辑时间,逻辑时间可以简单的理解为单调递增的自然数,0、1、2、3...。事务开始后加1,新事务开再加1。
整个分布式环境下,三个节点完全独立,相互之间没有关系。如果事务跨多个节点,涉及到多个节点交互,产生一个事务的时候,本地时钟要加1。发message出去的时候,要把message的主体发出去,还要将本地的时间发给另一个节点。收到一个message节点后要处理这条消息,从收到的消息里面将对时间和本地的逻辑时间做一个取值,取最大的值设为本地时间。
如果A节点发布较快,第一个事务完成以后,要做第二个事务,这时与B节点有交流,A加1,然后将时钟带到B节点,B节点直接从0跳到2。如此就在两个时钟之间建立了联系,通过建立联系,将两个节点之间的逻辑时钟拉平,这时候就构建它们之间的happen before的关系,代表A节点的事务是在B节点的新事务开始之前完成的。
分布式数据库中,如果两个事务没有操作同样的节点,则两个事务是无关的事务。无关的事务可以认为是没有先后顺序的。但是当一个事务横跨多个节点的时候,将多个节点之间的关系建立起来,就变成有关系的事务,构建的是事务间的因果序。
所谓因果序,如果同样来了两个事务,一个事务操作AB节点,另外一个事务操作BC节点,因为它们在B节点上建立了一个联系。通过B节点的关系,将事务的顺序维护起来。
纯逻辑时钟可以起到因果一致性和因果序的能力。那逻辑时钟最大的问题是什么呢?
最极端的情况下,节点和节点之间永远不产生联系,两个节点之间的逻辑时钟的差距会越来越大。这时如果两个节点之间做查询或者备份,需要强制将它们建立关系,那么两节点之间的gap会变得非常大。
虽然机器和机器之间物理时钟有偏移,但如果有NTP校准或者Google的Truetime这种时钟服务器话,其物理时钟的差距是非常小的。
混合时钟把分布式下的时钟切成两部分,上半部分用物理时钟来填充,下半部分用逻辑时钟来填充。填充在一起变成了一个HLC时钟,既混合逻辑时钟。它既有物理时钟的部分,又有逻辑时钟的部分。由于物理时钟服务器之间的差距不会特别大,所以可以比较物理时钟大小。而物理时钟又有一定的偏差,在一定的偏差范围内,可以使用逻辑时钟做校准。
下图是混合逻辑时钟的一个示例。当发送一个消息的时候,首先应该把逻辑时钟的物理时钟部分与当前的时钟做一个比较。如果当前的物理时钟是4点,新事务产生后,因为物理时钟没变,新事务加在逻辑时钟的部分(加1)。
如果物理时钟从4点变成4:01,则将物理时钟推进。物理时钟如果不推进,就加逻辑时钟。如果物理时钟发生了变化就把物理时钟往上推进,将逻辑时钟部分置零。

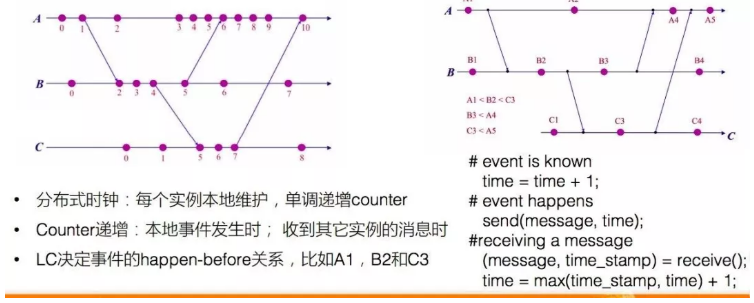
基于中心时钟的方案的时间是通过事务ID来判断的,从而为所以事物排序。分布式数据库中,需要消除中心节点。一种方法是纯逻辑时钟,但逻辑时钟之间无法比较大小。另一种方法是混合逻辑时钟(HLC),它为数据库定义了一类因果关系的事务。
混合逻辑时钟没有中心节点,用本地的物理时间加上逻辑时间。本地产生的事务不保序,但是如果事务跨了节点,其因果联系是有顺序的。
如下图T1,T2和T3代表提交时间,T1是一个分布式事务,T2是一个单机事务,T3是一个分布式事务。因为T1 是一个分布式事务,在数据库节点上进1是比进2先执行,所以在整个时钟里面,进1小于进2,进1也小于进3。通过这种方式,将有关系的事务的顺序排好。
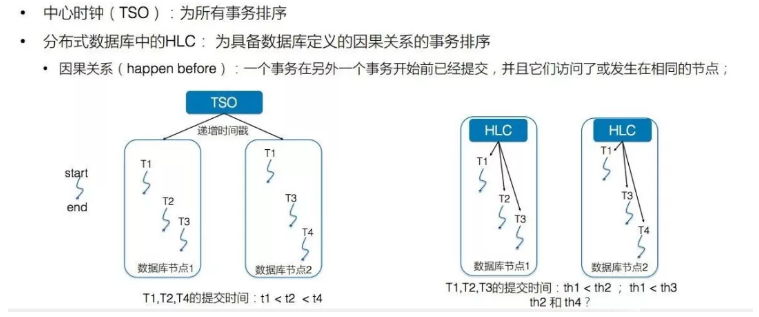
如下图,中心式时钟的优点一目了然,它可以保证全局一致的时间。
分布式数据库下的时钟的优点是无中心化的性能和无HA瓶颈,因为不需要中心的授时服务。分布式数据库下的时钟主要有两个能力,第一个能力是可以做到计算和存储的水平扩展。
另外,因为分布式数据库把一个业务的workload拆分到了不同的机器上,从而单点故障带来的影响减小了。把核心数据库拆成了几百份,任何一个单点数据库故障带来的整个系统可用性的下跌是非常小的。
这说明了为什么现在的分布式和互联网+结合在一起比较火,一个很重要的原因是分布式降低了单点故障对业务带来的的可用性的影响。
不仅仅是互联网公司,包括金融类的银行也想往分布式走,一个方面是为了解决容量和扩展性的问题,另外一方面也是为了解决高可用问题。
中心式的缺点是会有单点的single point of failure。分布式时钟虽然消除了单点的影响,但是时钟是不可以排序的,无法实现真正的外围一致性。外围一致性指的是每两个事务都可以排序。而分布式时钟只能对有关联的事务进行排序,实现因果顺序。
Google的Truetime的优点是保证全局一致时间,简化应用开发。缺点首先是需要专有的硬件,如果Truetime的原子钟授时的话,也会有一定的时钟偏差,这个时钟偏差物理上无法克服。Google Spanner的paper中可以发现每一个事务的提交都要等待一段时间,就是要等这段时钟偏差。
二、分布式事务管理
分布式事务管理是为了保证全局读写原子性和隔离性。一个事务要跨两个节点,这时候存在失败的可能性。假如一个节点成功一个节点失败,那么看到的结果就是不一致的,这丧失了事务的原子性。
还有一种是两个节点上都提交成功,但是因为两个节点本身的时间不一样,导致提交的时间也不一样。如果用MVCC去读这个事务,能看到一半,另一半可能看不到,这样就无法保证事务的原子性。
对于事务的原子性问题,目前相关技术已经非常成熟,既两阶段提交。如果要保证一个分布式事务成功或者失败,可以利用两个阶段提交技术,先做一个prepare事务,如果所有的prepare都可以,再做commit。
常见的分布式事务管理技术分为三类。
第一类是两个阶段提交技术,包含prepare阶段和commit阶段。
第二类基于MVOCC,其中FOUNDATION DB是苹果开源的分布式数据库,使用的是MVOCC,可以理解为OCC(optimistic concurrency control)。OCC指在事务提交时检查是否有冲突,基于冲突有设置冲突检测算法和权重算法,最后选择毁掉或者提交哪个事务。对于锁,在事前和在更新的时候加锁,提交的时候检查冲突。在冲突不剧烈的情况下,因为没有加锁开销,整个吞吐非常高。在冲突剧烈的情况下,大量的abort事务会反复回滚。
第三类技术主要针对确定性事务,如FAUNA技术。
美国的一位教授提出了确定性事务,并基于确定性事务模型创办了一家公司,创建了一个分布式数据库(FAUNA)。确定性事务指事务是完整的,而不是交互型的。
比如,在淘宝这种互联网企业处理的都是非确定性事务。非确定性事务只begin事务,select事务等,每个操作都是交互的,既APP需要跟DataBase做交互。
如果站在数据库的视角,数据库永远无法预测下一条语句,这类事物是非确定性的。确定性事务是把一个事务所有的逻辑一次性写好,然后发送给DataBase。DataBase收到事务的时候,清楚这个事务需要操作哪些表,读取哪些记录并进行哪些操作。从数据库的视角来说事务是完全确定的。拿到一个确定性事务,可以事先将这些事务排好序。两个事务之间如果操作相同的记录,就排个先后,如果不操作相同的记录,就并发的发出去。
使用这种方式可以做到既不用加锁,也不用在事后提交的时候做冲突检测。但是它的要求是事务不能是交互型的。
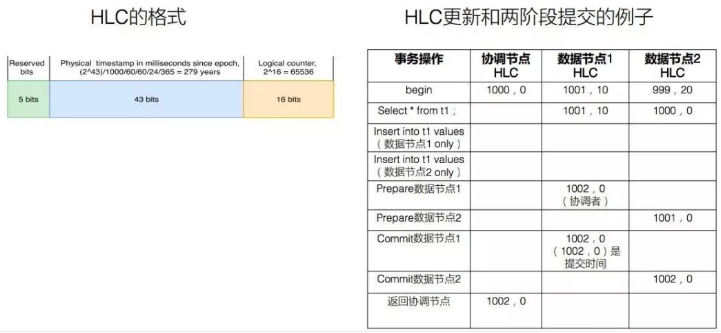
混合逻辑时钟(HLC)格式如下。如果有64个字节,首先预留5字节保证兼容性,在做系统设计的话,通常需要预留一些字节或以防出现一些问题时没东西可用。中间再留43字节做物理时钟。后面的16字节做逻辑时钟。如果时钟精确到毫秒级,43字节的物理时钟意味着279年,表示数据库不断运行,279年不挂,一般来说这不太可能。
如果物理时钟到天级,一天才能变一位,那物理时钟就失去了意义。16字节是65536,65536意味着一毫秒内可以发起65536个事务,。一般开始和结束的时候都要消耗两个时钟,除以二,既一毫秒内可处理3万多的事务,单节点一秒内可以做到3千多万事务。
HLC和事务的吞吐有关系,因为它有物理时钟,能够展示不同的节点之间的时钟差。如果真的出现了时钟偏移怎么办?
下图提供了一个简单的公式。没有偏差的情况下,理论上节点可以做到3千万的TPS,当然在工程上是做不到的。
如果两个节点时钟之间偏移量是5毫秒,那么在5毫秒之内只能通过逻辑时钟去弥补。如果原来6万个逻辑时钟在1毫秒内就能做完,现在则需要5毫秒,导致整个事务的吞吐下降了600万。所以时钟偏移会导致peakTPS大幅下降。
下图给出了几种解决方案。比较简单的是允许设置最大时钟偏移,如果整个机房或者集群中两个节点之间最大偏移超过了100毫秒,就把该异常节点清除。目前来看,机房都有NTP授时服务,所以发生如此大时钟偏移的概率非常小。另一种方式是不清除异常节点,但是可以允许逻辑时钟overflow到物理时钟部分,使逻辑时钟更大,这样可以允许更多的事务在当前时钟内发生。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721