
一、监控系统功能划分
一个宿主机cpu的报警叫做监控;一个业务日志的报错叫做监控;一个APM条件的触发,也叫做监控。分布式系统错综复杂,随便做个统计指标的集合,也属于监控的范畴。
怎样做到通用化,理清其中的关系,是需要花点功夫的,否则揉成一团,就不好拆了。
我习惯性从以下两种类型对其进行划分,真正实施起来,系统还是按照数据象限分比较合理:
数据象限:从数据类型划分,大体可分为:日志(logs)、监控(metrics)、调用链(tracing)。
功能象限:从业务角度划分,可分为:基础监控、中间件监控、业务监控

不管什么样的监控系统,又涉及以下几个模块过程:
数据收集:如何在广度和效率上进行数据归并。
数据加工:数据的整理、传输和存储。
特称提取:大数据计算,中间结果生成存储。
数据展示:高颜值、多功能显示。

其中,特征提取只有数据量达到一定程度才会开启,因为它的开发和运维成本一般小公司是不会玩的。
二、典型实现
不同的监控模块,侧重于不同领域,有着不同的职责。我个人是倾向于 独立设计 的,但需要做一定程度的集成,主要还是使用方式上的集成和优化。
我将从几个典型解决方案说起,来说一下为什么要分开设计,而不是揉成一团。

系统监控用来收集宿主机的监控状况(网络、内存、CPU、磁盘、内核等),包括大部分数据库和中间件的敏感指标。这些metric的典型特点是结构固定、有限指标项,使用时序数据库进行存储是最合适的。
指标收集方面,支持多样化的组件将被优先下使用。比如telegraf,支持所有的系统指标收集和大部分中间件和DB的指标收集。
注:在这里特别推荐一下其中的jolokia2组件,可以很容易的实现JVM监控等功能。
指标收集以后,强烈建议使用kafka进行一次缓冲。除了其逆天的堆积能力,也可以方便的进行数据共享(比如将nginx日志推送给安全组)。
指标进入消息队列后,一份拷贝将会通过logstash的过滤和整理入库ES等NoSQL;另外一份拷贝,会经过流计算,统计一些指标(如QPS、平均相应时间、TP值等)。
可以有多种途径计算触发报警的聚合计算。回查、叠加统计都是常用的手段。在数据量特别大的情况下,先对指标数据进行预处理是必备的,否则,再牛的DB如influxdb也承受不住。
展现方面,grafana因其极高的颜值,首选,并支持通过iframe嵌入到其他系统。
其缺点也是显著的:支持类型有限(同比、环比、斜率都木有);报警功能不是很好用。
怎么?觉得这套技术栈过长?你其实是可以直接选择zabbix这种现成的解决方案组件的,它的插件也够多,小型公司用起来其实最爽不过了。
但组件毕竟太集中了,你不方便将其打散,发现问题也不能任性的替换它的模块,这在架构上,是一个致命硬伤。最后突然发现,实现成本居然增加了。这也是为什么上点规模的公司,都不在用它。
自己开发一个也是可行的,但不简单,要处理各种复杂的前端问题,也不是每个人都能够做漂亮。
说到日志部分,大家首先想到的肯定是ELKB啊。但我觉得ELKB的链路不稳定不完整,建议做以下改造:
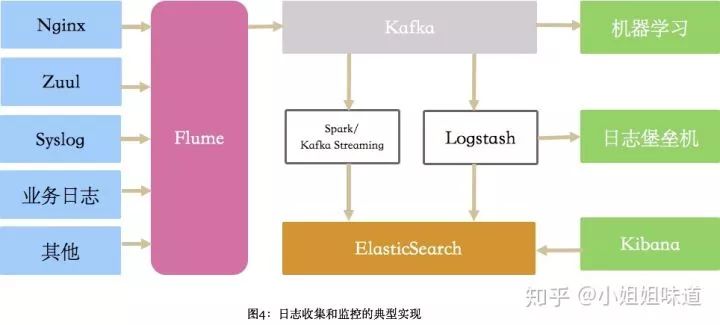
可以看到和系统监控的构造其实是差不多的,很多组件可以重用。区别就是数据量大,往往一不小心就把带宽占满了。日志的特点就是量大无规则(nginx算是良民了),SLA要求不会太高。
这时候收集部分就要用一些经的住考验的日志收集组件了。Logstash的资源控制不是太智能,为了避免争抢业务资源,flume、beats是更好的选择。
同样,一个消息队列的缓冲是必要的,否则大量Agent假死在业务端可不是闹着玩的。
关于日志落盘。很多日志是没必要入库的,比如研发同学开开心心打出来的DEBUG日志,所以要有日志规范。logstash根据这些规范进行过滤,落库到ES。日志量一般很大,按天建索引比较好。更久之前的日志呢,可以归集到日志堡垒机(就是非常非常大的磁盘),或者直接放HDFS里存档了。
那么怎么过滤业务日志的错误情况呢,比如有多少XXX异常触发报警。这种情况下可以写脚本,也可以接一份数据进行处理,然后生成监控项,抛给metrics收集器即可。

哈!又绕回去了。
相比较普通监控和日志,调用链APM等就复杂的多了。除了有大量的数据产生源,也要有相应的业务组件来支持调用链聚合和展示。其功能展示虽然简单,但却是监控体系里最复杂的模块。
Google 的论文
“Dapper, a Large-Scale Distributed Systems Tracing Infrastructure”
开启了调用链的流行。后续可以说是百家齐放,直到近几年才出现了OpenTracing这样的标准。
在数据处理和后续展示方面,它的技术点其实与监控技术是雷同的,复杂性主要体现在调用链数据的收集上。
目前的实现方式,有类似Pinpoint这种直接使用javaagent技术修改字节码的;也有类似于cat这种直接进行编码的。其各有优缺点,但都需要解决以下问题:
收集组件的异构化。开发语言可能有java,也可能有golang
组件的多样化。从前端埋点开始,nginx、中间件、db等链路都需要包含
技术难点的攻关。如异步、进程间上下文传递等
采样。尤其在海量调用时,既要保证准确性,也要保证效率
关于Tracing的数据结构,已经烂大街,在此就不多说了。各种实现也各自为政,协议上相互不兼容,做了很多重复的工作。
为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing( http://opentracing.io/ ) 规范。
说白了就是一套接口定义,主流的调用链服务端实现都兼容此规范,如zipkin、jaeger。也就是说你只要按照规范提供了数据,就能够被zipkin收集和展示。
OpenTracing大有一统天下的架势,它在其中融合Tracing、Log、Metrics的概念。我们还是看张图吧,等真正去做的时候去了解也不晚(来源于网络):
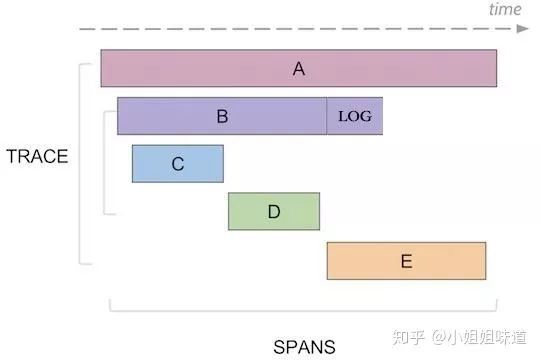
值得一提的是,SpringCloud对它的支持还是比较全面的(OpenTracing API Contributions),但依赖关系和版本搞的非常混乱。建议参考后自己开发,大体使用”spring boot starter”技术,可以很容易的写上一版。
至于”Spring Cloud 2”,更近一步,集成了micrometer这种神器,对prometheus集成也是非常的有好。业务metrics监控将省下不少力气。
以上谈了这么多,仅仅是聊了一下收集方面而已。标准这个思路是非常对的,否则每个公司都要写一遍海量的收集组件,多枯燥。至于国内大公司的产品,是否会主动向其靠拢,我们拭目以待。
服务端方面,我们以Uber的Jaeger为例,说明一下服务端需要的大体组件:
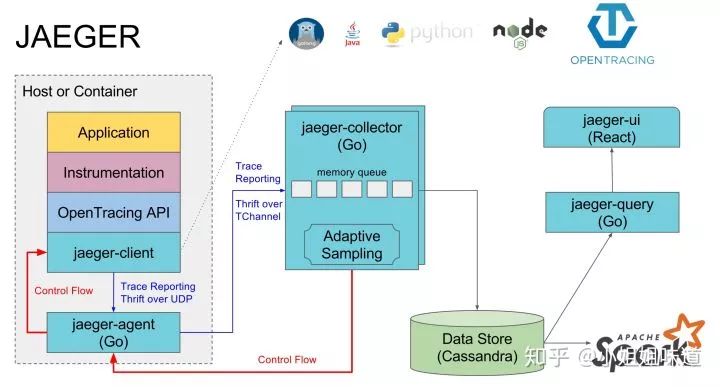
Jaeger Client:就是上面我们所谈的
Agent:监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector
Collector:接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。
Data Store:后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、ES
Query:接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示
是的,典型的无状态系统,对等节点当机无影响。
上面的状态图不止一次提到流计算,这也不用非要整个Spark Streaming,从kafka接收一份数据自己处理也叫流计算,选用最新的kafka stream也是不从的选择。重要的是聚合聚合聚合,重要的事情说三遍。
一般,算一些QPS,RT等,也就是纯粹的计数;或者斜率,也就是增长下降速度;复杂点的有TP值(有百分之多少的请求在XX秒内相应),还有调用链的服务拓扑图、日志异常的统计,都可以在这里进行计算。
幸运的是,流计算的API都比较简单,就是调试比较费劲。
分析后的数据属于加工数据,是要分开存储的,当然量小的话,也可以和原始数据混在一起。
分析后的数据量是可评估的,比如5秒一条数据,一天就固定的17280条,预警模块读的是分析后的数据(原始数据太大了),也会涉及大量的计算。
那么分析后的统计数据用来干什么用呢?一部分就是预警;另一部分就是展示。
拿我设计的一个原型来看,对一个metric的操作大体有以下内容:

在时间间隔内,某监控项触发阈值XX次
触发动作有:大于、小于、平均值大于、平均值小于、环比大于、环比小于、同比大于、同比小于、自定义表达式等
阈值为数字数组,支持多监控项相互作用
级别一般根据公司文化进行划分,6层足够了
聚合配置用来表明是阈值触发还是聚合触发,比如在时间跨度5分钟内发生5次,才算是处罚
报警触发后,会发邮件、打电话、发短信、发webhook等
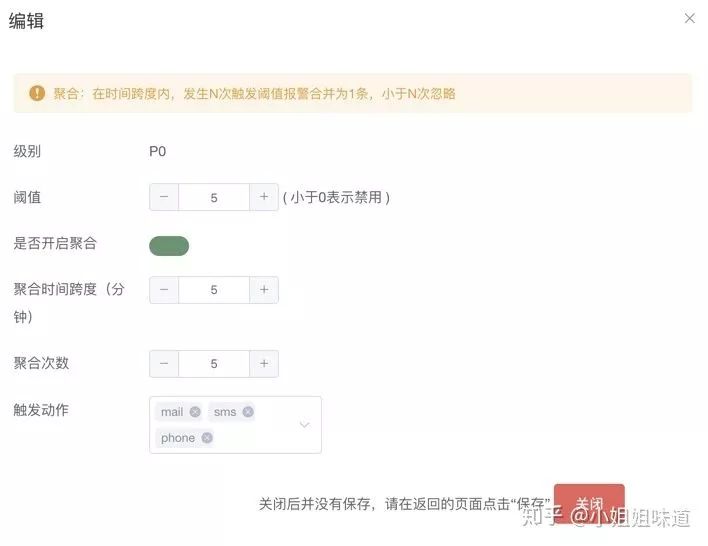
仅做参考,这只是配置的冰山一角。要把各种出发动作做一遍,你是要浪费很多脑细胞的。
有很多可视化js库,但工作量一般都很大。但没办法,简单的用grafana配置一下就可以了,复杂点的还需要亲自操刀。
我这里有两张简单的grafana图,可以参考一下:
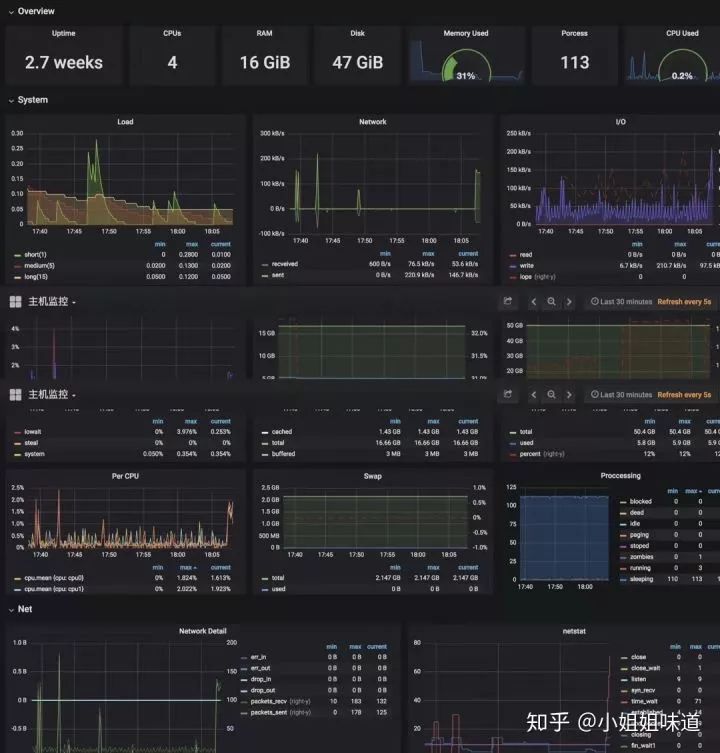
[系统监控]
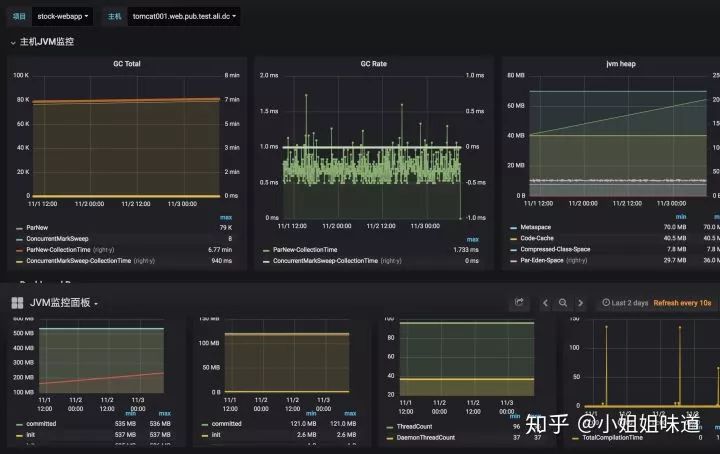
[jvm监控一部分]
整体来说,整个体系就是收集、处理、应用这大三类数据(logs、metrics、trace)。
其中有些组件的经验可以共用,但收集部分和应用部分相差很大。我尝试总结了一张图,但从中只能看到有哪些组件参与,只看图是临摹两可的。
具体的数据流转和处理,每种结构都不尽相同,这也是为什么我一直强调分而治之的原因。
但使用方式上,最好相差不要太大。无论后端的架构如何复杂,一个整体的外观将让产品变得更加清晰,你目前的工作,是不是也集中在此处呢?
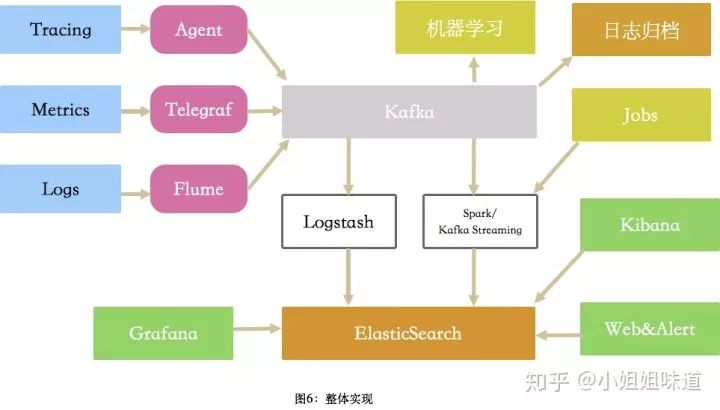
三、一些组件
通过了解上面的内容,可以了解到我们习惯性的将监控系统所有的模块进行了拆解,你可以很容易的对其中的组件进行替换。比如beat替换flume、cassandra替换ES…
下面我将列出一些常用的组件,如有遗漏,欢迎补充。
用来收集监控项,influxdata家族的一员,是一个用Go编写的代理程序,可收集系统和服务的统计数据,并写入到多种数据库。支持的类型可谓非常广泛。
主要用来收集日志类数据,apache家族。Flume-og和Flume-ng版本相差很大,是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Logstash是一个开源的日志收集管理工具,elastic家族成员。功能和flume类似,但占用资源非常的贪婪,建议使用时独立部署。功能丰富,支持ruby定义过滤条件。
node开发,使用udp协议传输,专门用来收集数据,收集完数据就发送到其他服务器进行处理。与telegraf类似。
collectd是一个守护(daemon)进程,用来定期收集系统和应用程序的性能指标,同时提供了机制,以不同的方式来存储这些指标值。
独立的可视化组件比较少,不过解决方案里一般都带一个web端,像grafana这么专注的,不太多。
专注展示,颜值很高,集成了非常丰富的数据源。通过简单的配置,即可得到非常专业的监控图。
有很多用的很少的,可以看这里:
Grafana Plugins - extend and customize your Grafana.
influx家族产品。Influxdb是一个开源的分布式时序、时间和指标数据库,使用go语言编写,无需外部依赖。支持的数据类型非常丰富,性能也很高。单节点使用时不收费的,但其集群要收费。
OpenTSDB是一个时间序列数据库。它其实并不是一个db,单独一个OpenTSDB无法存储任何数据,它只是一层数据读写的服务,更准确的说它只是建立在Hbase上的一层数据读写服务。能够承受海量的分布式数据。
能够存储监控项,也能够存储log,trace的关系也能够存储。支持丰富的聚合函数,能够实现非常复杂的功能。但时间跨度太大的话,设计的索引和分片过多,ES容易懵逼。
小米出品,它其实包含了agent、处理、存储等模块,并有自己的dashboard,算是一个解决方案,赞一下。
但目前用的较少,而且国内开源的东西尿性你也知道:公司内吹的高大上,社区用的却是半成品。
Graphite并不收集度量数据本身,而是像一个数据库,通过其后端接收度量数据,然后以实时方式查询、转换、组合这些度量数据。
Graphite支持内建的Web界面,它允许用户浏览度量数据和图。
最近发展很不错,经常和Collectd进行配对。grafana也默认集成其为数据源。
golang开发,发展态势良好。它启发于 Google 的 borgmon 监控系统,2015才正式发布,比较年轻。
prometheus目标宏大,从其名字就可以看出来—普罗米修斯。另外,SpringCloud对它的支持也很好。
图形还停留在使用AWT或者GD渲染上。总感觉这些东东处在淘汰的边缘呢。
使用占比特别大,大到我不需要做过多介绍。但随着节点的增多和服务的增多,大概在1k左右,你就会遇到瓶颈(包括开发定制瓶颈)。整体来说,小公司用的很爽,大公司用的很鸡肋。
也算是比较古老了,时间久客户多。其安装配置相对较为复杂。功能不全较专一,个人不是很喜欢。
Ganglia的核心包含gmond、gmetad以及一个Web前端。主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
这可是老掉牙了,和nagios配合的天衣无缝。你还在用么?
APM算是其中比较特殊的一个领域,也有很多实现。
附:支持OpenTracing的APM列表
其实美团的东西非常少,大部分拿点评的来充门面。CAT作为美团点评基础监控组件,它已经在中间件框架(MVC框架,RPC框架,数据库框架,缓存框架等)中得到广泛应用,为美团点评各业务线提供系统的性能指标、健康状况、基础告警等。
算是比较良心了,但侵入性很大,如果你的代码量庞大就是噩梦。技术实现比较老,但控制力强。
pinpoint是开源在github上的一款APM监控工具,它是用Java编写的,用于大规模分布式系统监控。安装agent是无侵入式的,也就是用了java的instrument技术,注定了是java系的。
带有华为标签,和pinpoint类似,使用探针收集数据,2015年作品,使用ES作为存储。进入Apache了哦,支持Opentracing。
哦,zipkin也是走的这条路,但zipkin支持opentracing协议,这样,你用的不爽可以替换它,非常大度。
golang开发,Uber产品,小巧玲珑,支持OpenTracing协议。它的Web端也非常漂亮,提供ES和Cassandra的后端存储。
这里提一个唯一收费的解决方案。为什么呢?因为它做的很漂亮。颜值控,没办法。另外,还良心的写了很多具体实现的代码和文档,质量很高。你要自己开发一套的话,不妨一读。
监控体系的复杂之处就在于杂,如何理清其中的关系,给用户一个合理的思考模式,才是最重要的,此所谓产品体验优先。
从整个的发展历程中可以看到,标准化是对技术最好的改进,但也要经历一个群魔乱舞的年代。
既得利益者会维护自己的壁垒,拒绝接纳和开放,然后猛然间发现,自己的东西已经落伍,跟不上时代的脚步了。
作者:小姐姐味道
来源:小姐姐味道订阅号(ID:xjjdog)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721