
前段时间,笔者所负责的一个模块出现了访问 Redis 耗时较长的问题,在这个问题排查的过程中,对 Redis 的问题排查思路和压测、调优进行了一些系统的学习和沉淀,在这里分享给大家。
第一个重点:服务排障的基本方法
在岁月静好的一天,正当笔者准备下班工作的时候,突然,告警出现了!
嗯,又是一到下班就会告警!
仔细一看,原来是数据整体处理时间慢了。
既然慢了,就看看具体哪个链路慢了。
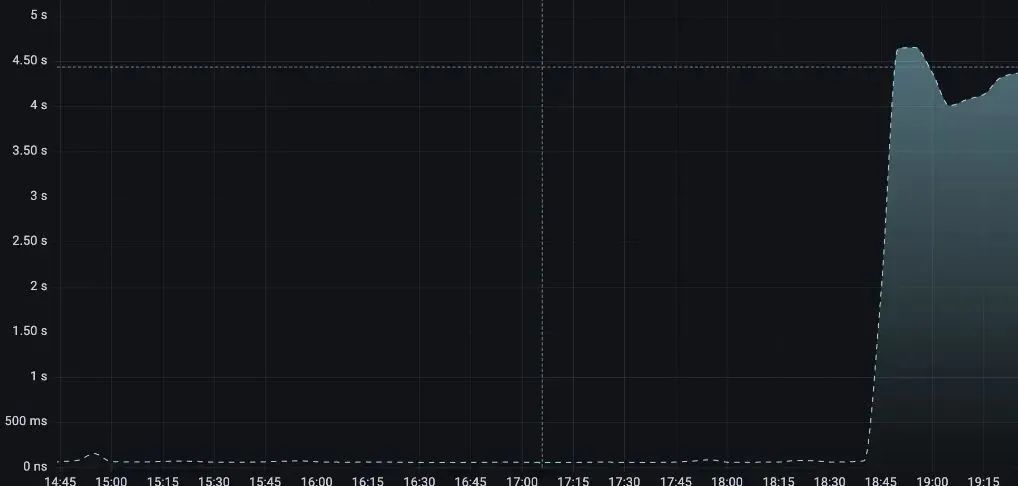
看来是 A 模块的 B 阶段的处理耗时突然慢了。
赶紧确认反向查询哪里出了问题,因为 B 阶段不是 A 模块的第一个阶段,所以基本排除是模块间的网络通信、带宽等问题。
那这里有两个思路:
排查这个 A 模块本身的问题;
排查数据量的问题。
这里的经验是,横向看基础指标,纵向看代码变更。
1)先看 A 模块服务的基础资源数据
内存正常:
CPU 正常:

2)再看所在 Node 节点的负载情况
Node 负载正常,而且一般 Node 有问题,不会单服务出现问题。
3)再看磁盘占用情况
存储节点一切正常。

看起来,CPU、内存、网络 IO、磁盘 IO 几个大的指标没有明显的变化。
4)那是不是最近发布出现的问题呢?
经项目成员对齐,A 模块近期也没有进行发布。
1)那再看看是不是数据量出现问题?
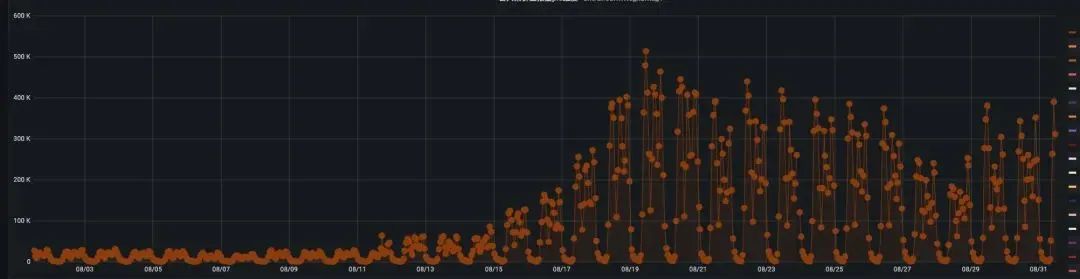
嗯,上报量确实增加了5倍,既然这样:扩容、限流、服务降级三板斧搞上,问题解决了!
舒服!下班!
然后,在一个寂寞无人的深夜里,笔者突然惊醒!
问题当时虽然解决了,但其实并没有真的确认根本原因,数据量也许只是一个引子,这里会不会有性能优化的点呢?
在降本增效的大背景,性能优化在服务端更是一个重要的目标。于是,笔者翻身起床,又进一步研究了一下。
既然,问题出在 A 模块的 B 阶段,那首先进行细化,到底哪个方法出现了这么就耗时,排查耗时这里也有两个思路:
业务打点进行排查;
性能分析工具排查。
一般来说,先用业务打点确认大概范围,然后通过性能分析工具精确确认问题点。之所以这样是因为有两个原因:
一是业务代码一般是造成问题的主要原因,在业务代码进行有效打点,可以更快地确认问题范围、变更范围、责任范围,从而可以有明确的责任人去跟进。
二是一般来说性能分析工具排查都会定位到一些组件函数、系统函数,所以可能有很多个调用者、先用耗时打点的方式确认范围,可能更小的范围确认调用者,也就是疑似点,这样组合起来会比较顺畅。
1)首先是修改了一下指标上报的代码,在监控面板上查看
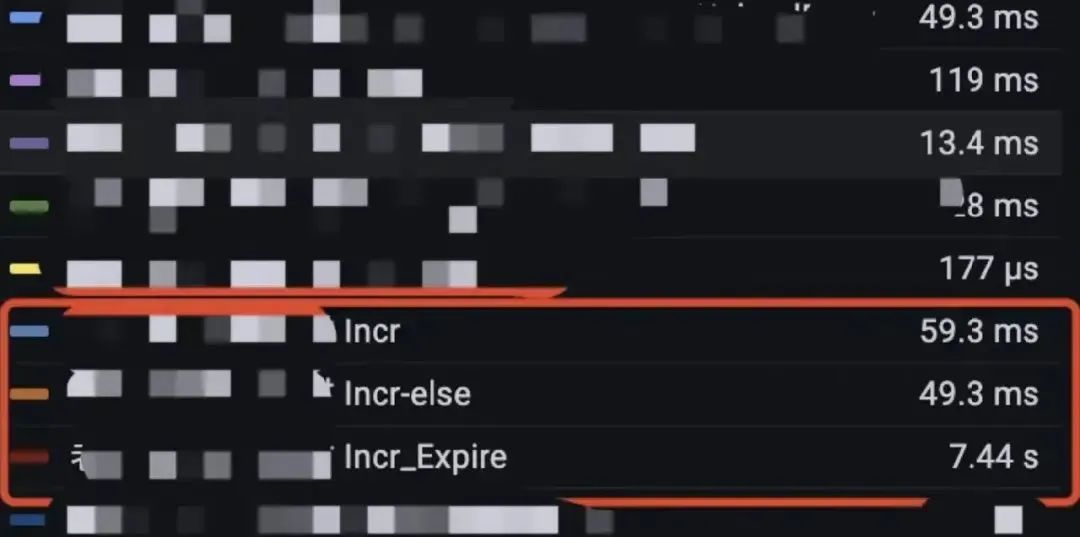
2)然后是在模块的日志中进行耗时采集和输出:

结果都基本上定位到函数是 Redis 的计数自增逻辑。
至于为什么采用两种方法进行确认,是因为,实际业务会比较复杂,很多函数并不是线性调用,获取正确且精确耗时并不容易,需要多种方案去确认。
这里主要用的 pprof 工具。
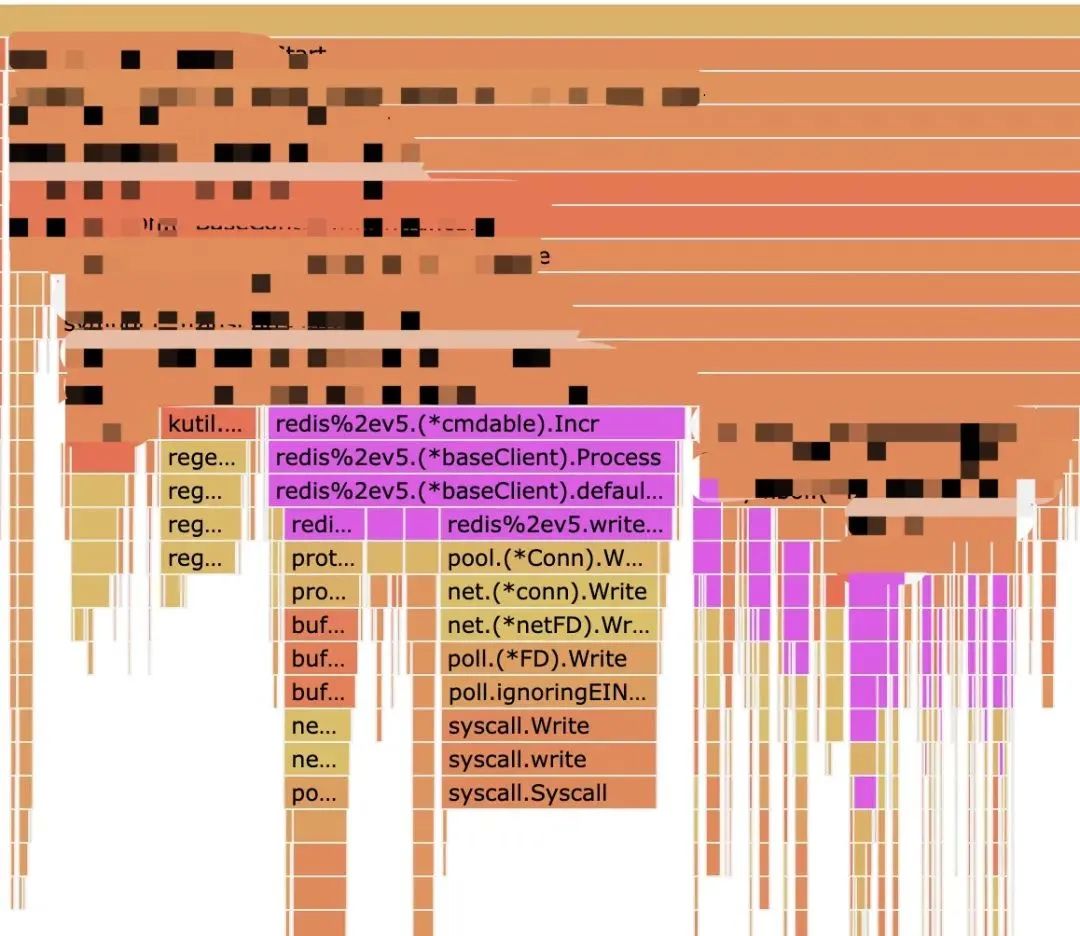
可以看到,紫色部分就是 Redis 相关命令的调用耗时,基本上占了总耗时的大头 Double check!
事实上,这里笔者只是拿了一个函数作为例子,在这个场景下,基本上所有的 Redis 相关的命令都慢到秒级,也就是说,Redis 可用性出现了问题。
你看,我就说这个班没有白加,我们把问题从“数据量突增”转换到“Redis 可用性”上来。嗯,这里我擅长!
毕竟,我们都喜欢把问题规约到以前解决的问题中(并没有)。
一位物理学家和一位数学家正坐在教职员休息室里。突然间,咖啡机着火了。物理学家抓起一个水桶,朝水槽跳跃,用水填满水桶,把火浇灭。第二天,同样的两个人坐在同一个休息室。咖啡机再次着火。这一次,数学家赶紧跳起来,抄起桶,递给了物理学家。(数学家擅长将问题规约到以前解决的问题中。)
第二个重点:Redis 服务排障的基本方法
既然是 Redis 的问题,我们就看看到底如何排查 Redis 服务。其实,这里有很多的总结和文章,笔者这里主要是结合一个实际的问题,对思路进行再次整理。
首先,我们的问题是:Redis 服务请求的回包慢。这里的思路是:Redis 服务本身问题——Redis 数据存储问题——请求 Redis 的问题。
一般来说业务出现问题的可能性>服务本身出现问题的可能性。但由于,业务模块没有太多变动,所以这次先查服务本身。
1)Redis 所在节点网路延迟问题确认
按照理论上来讲,应该首选确认是 Redis 服务本身的问题,还是节点网络的问题。这里引用 kevine 一篇文章的一段话:
服务器到 Redis 服务器之间的网络存在问题,例如网络线路质量不佳,网络数据包在传输时存在延迟、丢包等情况。
网络和通信导致的固有延迟:
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis,在 1 Gbit/s 网络下的延迟约为200 us,而 Unix 域 Socket 的延迟甚至可低至 30 us,这实际上取决于网络和系统硬件;在网络通信的基础之上,操作系统还会增加了一些额外的延迟(如线程调度、CPU 缓存、NUMA 等);并且在虚拟环境中,系统引起的延迟比在物理机上也要高得多。
结果就是,即使 Redis 在亚微秒的时间级别上能处理大多数命令,网络和系统相关的延迟仍然是不可避免的。
可以看到,事实上,即使到物理硬件层,网络的延迟还是有的但不大,但加上 Redis 所在机器上的带宽限制和网桥性能等问题,这个问题可能会到达不可忽略的地步。
事实上,在这个案例中,基本排除是节点网络的问题,一是,当数据量下降的时候,Redis 的回包耗时减少。
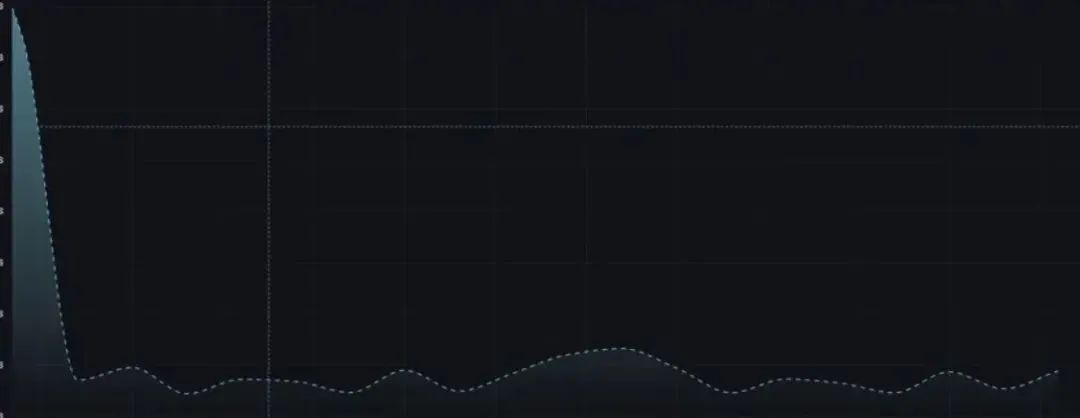
二是,Redis 服务是集群内服务,通过监控发现,内网带宽并没有突破限制。
2)Redis 自身服务网路延迟问题确认
对于单实例:这里有两个比较经典的命令。
①redis-cli -h 127.0.0.1 -p 6379 --intrinsic-latency 60。
即在 Redis server 上测试实例的响应延迟情况。

可以看到,响应还是挺快的。不过,这个是瞬时速度,需要现场抓,所以在复现问题上来说不是那么好用,所以可以稍微调整下命令。
②redis-cli -h 127.0.0.1 -p 6379 --latency-history -i 1。
查看一段时间内 Redis 的最小、最大、平均访问延迟:

可以看到,也没啥问题。
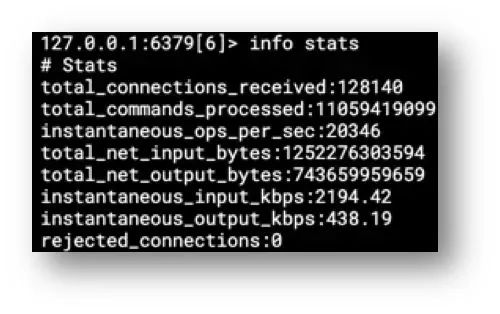
③吞吐量(使用info stats)
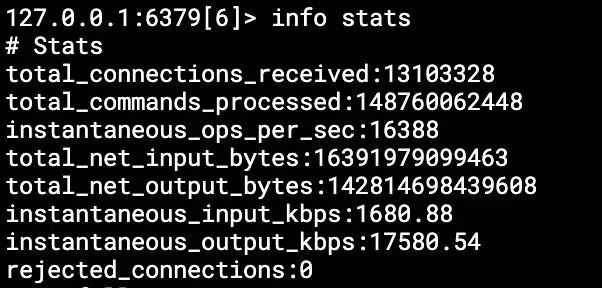
具体含义如下:
# 从Rdis上一次启动以来总计处理的命令数total_commands_processed:2255# 当前Redis实例的OPS,redis内部较实时的每秒执行的命令数instantaneous_ops_per_sec:12# 网络总入量total_net_input_bytes:34312# 网络总出量total_net_output_bytes:78215# 每秒输入量,单位是kb/sinstantaneous_input_kbps:1.20# 每秒输出量,单位是kb/sinstantaneous_output_kbps:2.62
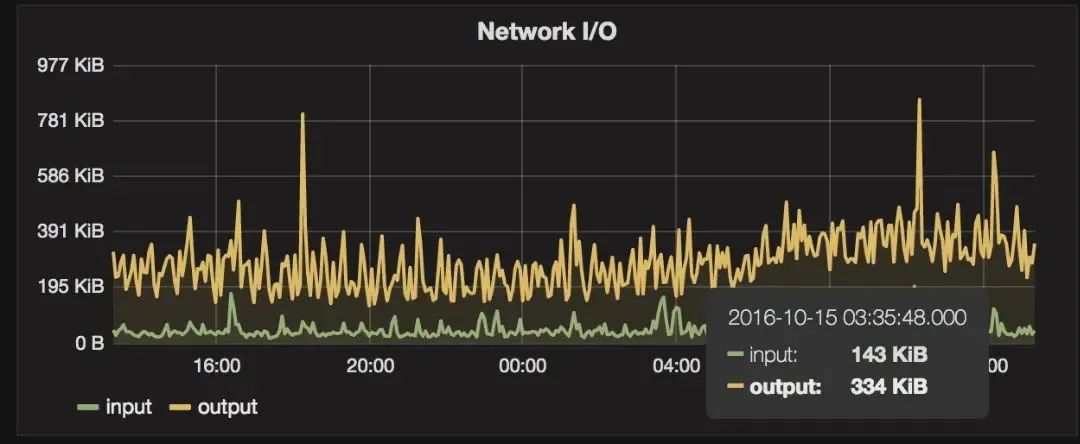
其实看到这里,相信很多同学会发现,这个吞吐量要是有时序图好了,嗯,事实上,这也就是为啥很多服务要配置 Prometheus 的原因:
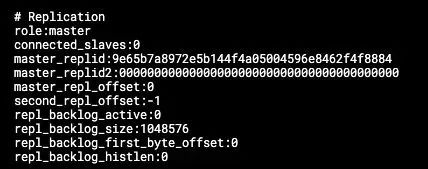
对于多实例:还要考虑主从同步的问题。主要关注:master_link_down_since_seconds、master_last_io_seconds_ago、master_link_status 等指标。
使用 info Replication 命令:
不过一般用上了主从同步这一套,基本上业务就会比较重了,运维同学也会在早期建立起监控。
回到问题,这里服务没有用主从同步的方式,所以,这里的疑似点排除。
3)CPU、Memory、磁盘 IO
其实从前面排障可知:内存、CPU、IO、磁盘应该是最基本的指标,这里之所以先查网络 IO,是因为 IO 的疑点最大,其他的基本上可以通过 info memory;info CPU;info Persistence 命令来查看,这里有一个详细的表格供大家参考,回到问题,查看的信息如下:
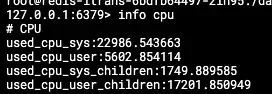

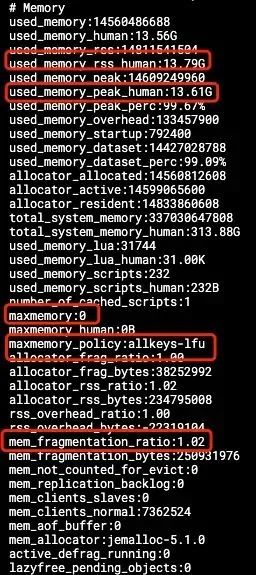
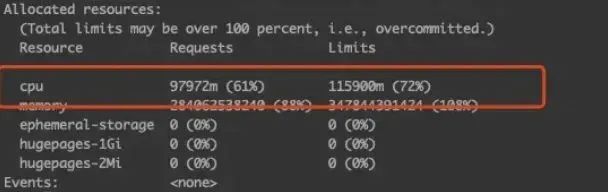
可以看到 CPU 比较高,快到了90%。这里补充一个知识点:CPU 这里,除了上面的内容外:
还有一个场景绑定固定 CPU 核心的设置,在 Redis6.0 上有。
memory 这里,主要关注三个指标:
used_memory_rss_human:表示目前的内存实际占用——表示当前的内存情况。
used_memory_peak_human:表示内存峰值占用——表示曾经的内存情况(主要是用来抓不到现场的时候查问题用的)。
mem_fragmentation_ratio:这里引用kevine一篇文章的一段话。
内存碎片率( mem_fragmentation_ratio )指标给出了操作系统( used_memory_rss )使用的内存与 Redis( used_memory )分配的内存的比率 mem_fragmentation_ratio = used_memory_rss / used_memory 操作系统负责为每个进程分配物理内存,而操作系统中的虚拟内存管理器保管着由内存分配器分配的实际内存映射。
那么如果我们的 Redis 实例的内存使用量为1 GB,内存分配器将首先尝试找到一个连续的内存段来存储数据;如果找不到连续的段,则分配器必须将进程的数据分成多个段,从而导致内存开销增加,具体的相关解释可参考这篇文章:Redis 内存碎片的产生与清理。
内存碎片率大于1表示正在发生碎片,内存碎片率超过1.5表示碎片过多,Redis 实例消耗了其实际申请的物理内存的150%的内存;另一方面,如果内存碎片率低于1,则表示Redis需要的内存多于系统上的可用内存,这会导致 swap 操作。内存交换到磁盘将导致延迟显著增加 理想情况下,操作系统将在物理内存中分配一个连续的段,Redis 的内存碎片率等于1或略大于1。
这里其实隐含了一个知识点:作为内存型数据库,磁盘也是一个关键点:这里包含了两个方面(1.持久化 2.内存交换)。
持久化是一个比较容易忽略的问题,但其实在集群模式下,持久化可能也会从侧面发现问题,这里可以关注如下几个点:

查询的信息有这几个:

还有一个比较特殊:latest_fork_usec,这个基本上是跟宿主机的关系比较大,如果耗时较久,一般会出现在 ARM 等机器上。
内存交换这里其实也是一个关键点:
这里主要关注的点是:maxmemory、maxmemory-policy、evicted_keys。
一是最大内存限制 maxmemory,如果不设这个值,可能导致内存超过了系统可用内存,然后就开始 swap,最终可能导致 OOM。
二是内存驱逐策略 maxmemory-policy,如果设了 maxmemory 这个值,还需要让系统知道,内存按照什么样策略来释放。
这里补充个知识点 Reids4.0 之后可以将驱逐策略放在后台操作,需要这样设置。
lazyfree-lazy-eviction yes
三是驱逐数:evicted_keys,这个可以通过 info stats 查看,即采用驱逐策略真正剔除的数据数目。

四是内存碎片率,在上面的引用已经给出了,内存碎片率低的情况下可能导致 swqp。你看,这里其实是内存和磁盘 IO 的联动点。
回到问题,从上面的截图可以看到,除了 CPU 外,基本指标是正常的(maxmemory 虽然没设,但内存远没到限制)。那么再来查查 Redis 数据存储的问题。
1)key 的总数
命令为 info keyspace,主要是 Redis 实例包含的键个数。
这里单实例建议控制在 1kw 内;单实例键个数过大,可能导致过期键的回收不及时。
之所以先查这个是因为,这里很可能是一个容易被人忽略的点,可能每个业务的量不大,但最后一个业务成为压死骆驼的最后一根稻草,所以有问题先排查这里。

这里可以看到,总 key 的数目是没有超过限制的,问题点不在这。
2)Bigkey、内存大页
所谓大 key,就是耗时久的 key,具体定义,这里是 bigkey 的危害:
Redis 阻塞:因为 Redis 单线程特性,如果操作某个 bigkey 耗时比较久,则后面的请求会被阻塞。
内存空间不均匀:比如在 Redis cluster 或者 codis 中,会造成节点的内存使用不均匀。
过期时可能阻塞:如果 Bigkey 设置了过期时间,当过期后,这个 key 会被删除,假如没有使用 Redis 4.0 的过期异步删除,就会存在阻塞 Redis 的可能性,并且慢查询中查不到(因为这个删除是内部循环事件)。
导致倾斜:某个实例上正好保存了 bigkey。bigkey 的 value 值很大(String 类型),或者是 bigkey 保存了大量集合元素(集合类型),会导致这个实例的数据量增加,内存资源消耗也相应增加。实例的处理压力就会增大,速度变慢,甚至还可能会引起这个实例的内存资源耗尽,从而崩溃。
总之就是查询和删除容易造成堵塞,所以要专门看一下,当然这里还有一个关联的知识点:
内存大页:内存页是用户应用程序向操作系统申请内存的单位,常规的内存页大小是 4KB,而 Linux 内核从 2.6.38 开始,支持了内存大页机制,该机制允许应用程序以 2MB 大小为单位,向操作系统申请内存。
由于系统采取的 COW(写时复制)的方案、如果频繁写请求操作的是一个 bigkey,那主进程在拷贝这个 bigkey 内存块时,涉及到的内存大页会更多,时间也会更久,从而延迟比较久。
具体命令:redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01
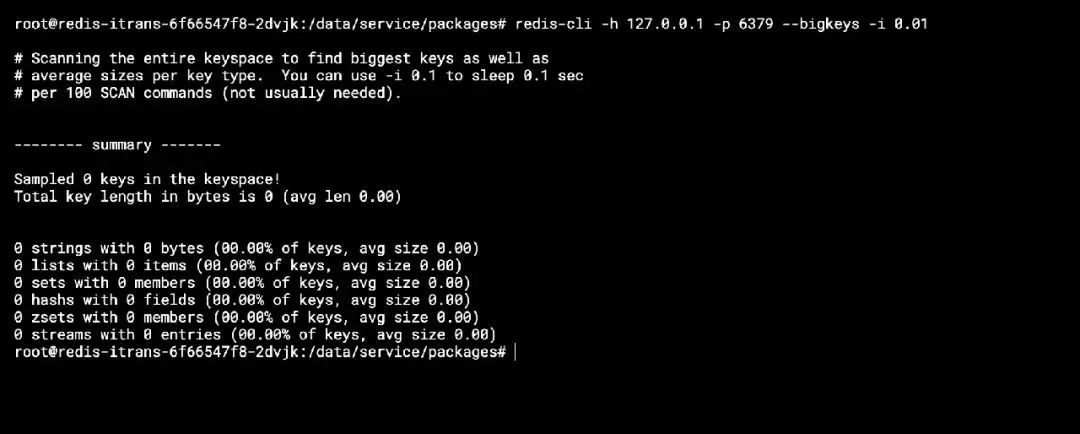

可以看到,没有 bigkey,内存大页也没开启,问题点也不在这里。
3)key 集中过期
除了当数据库用,基本上 Redis 里面的 key 都会设置过期时间,这时有可能存在集中过期导致负载过高的问题。
这里补一个知识点:过期策略和驱逐策略的区别

回到主线,结论就是 Redis 的定时过期策略虽然会有时间上限限制,但依然在大量过期的情况下出现延时高的情况。
不过,这里与这个问题应该关系不大,因为如果是过期问题,不会仅出现在数据量大的情况发生,应该是“周期性出现”,所以问题点也不在这里。既然不是数据本身的问题,那再看看是不是访问的问题。
1)客户端连接数、阻塞客户端的数
这里可能会奇怪,为什么查这个数据,一般业务服务链接 Redis 的请求不是通过客户端,嗯,就是因为问题很少可能出现在这里,所以先查这里。
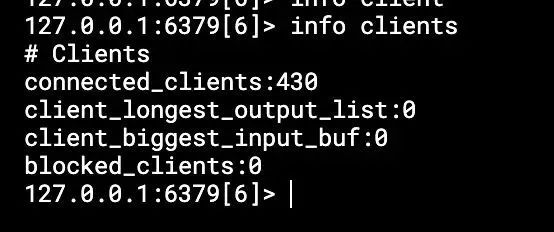
连接数430个、阻塞数0个,没有超过限制,所谓问题不在这里。阻塞的经典函数包括:BLPOP, BRPOP, BRPOPLPUSH。
2)慢命令
即查看请求的命令耗时多久。如下图:
第一个命令是指保留慢命令的条数:128。
第二个命令是慢命令的标准 1000毫秒。
第三个命令是查看慢命令的 top 2和 top 3。
第一个值是 id。
第二个值是执行的时间点。
第三个值是执行时间。
第四个值是执行的命令。
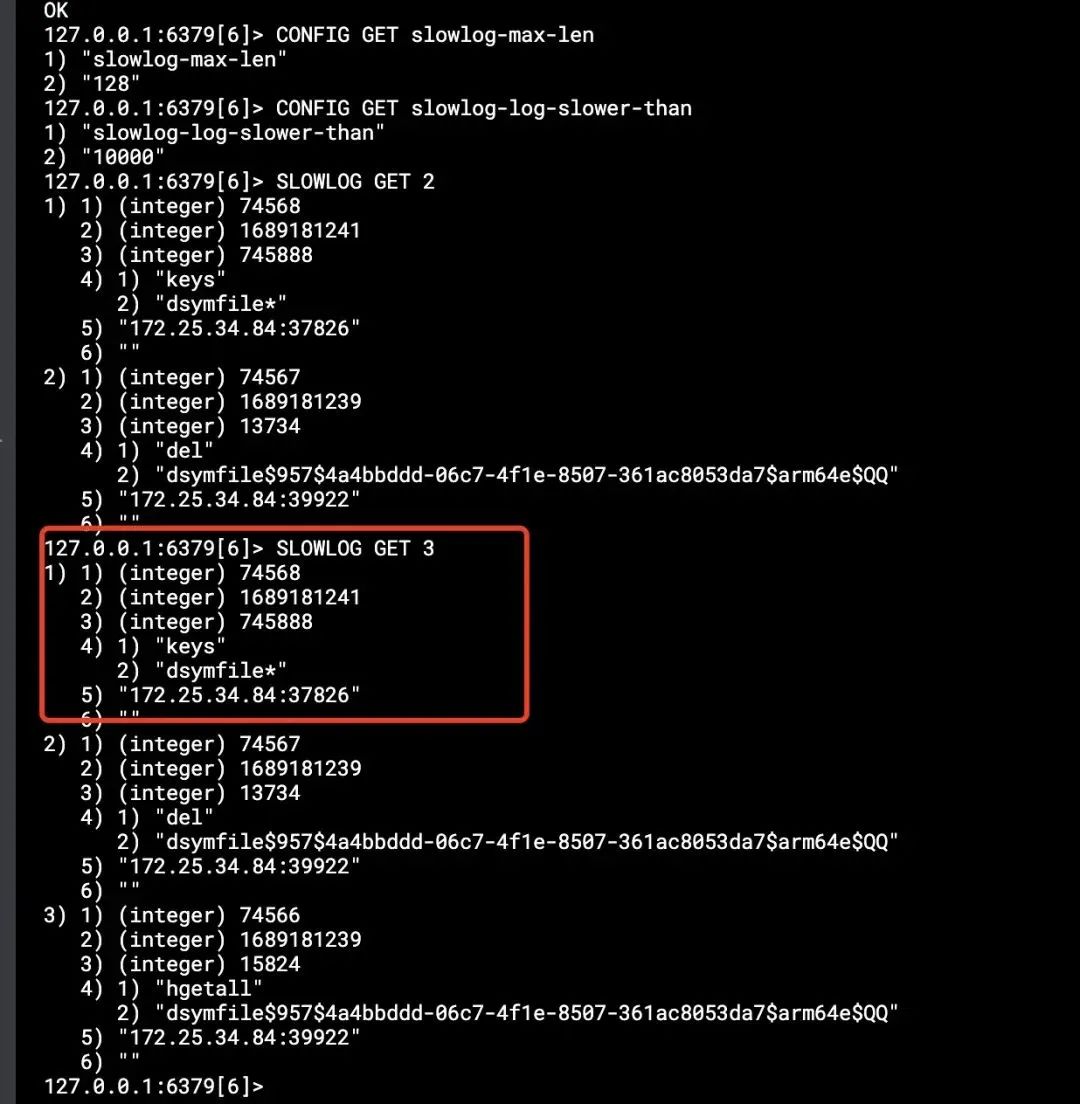
这里对几个慢命令的时间进行了查询,发现与 Redis 回包慢的时间不相符,而且并没有太慢,故问题也不在这里。
3)缓存未命中
这里主要是看 info stats 的两个值:
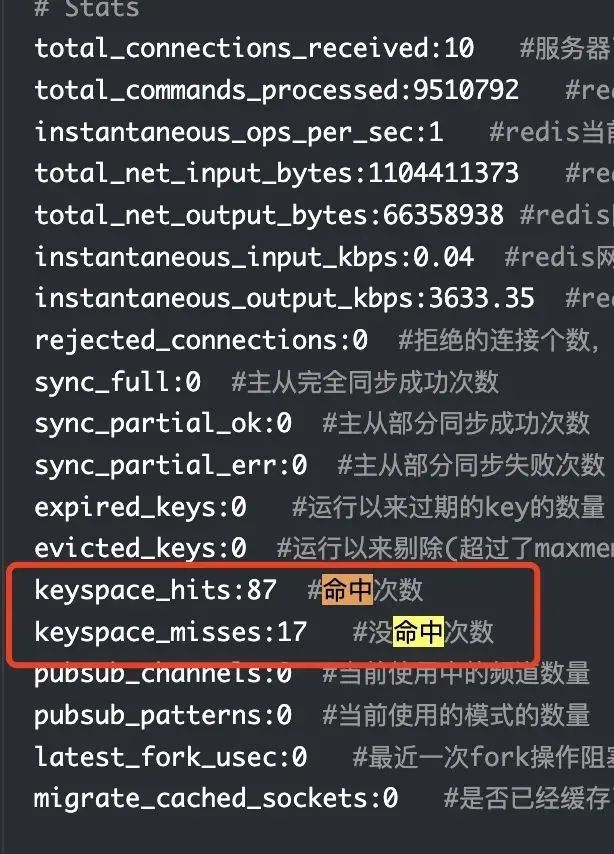
不过这里并不是这个问题的重点,通过梳理业务逻辑得知,并没有未命中就去持久化数据库再去查询的逻辑。
4)Hotkey
反过来,会不会是访问了某个点太多次了,在 Redis4.0.3 之后,可以查 hotkey 的情况。
当然,要先把内存逐出策略设置为 allkeys-lfu 或者 volatile-lfu,否则会返回错误:

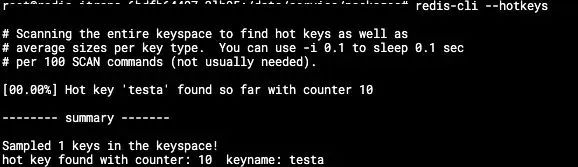
这里有个小细节,笔者负责的模块是 Redis4.0.0,刚好没有 hotkey 监控,然后笔者尝试升级了 Redis 到5.0.0。
依然也没有,最后发现还需要升级业务服务的 Redis 的组件库(pakeage)。
还好,笔者的负责的服务自己构建了一个热度统计。
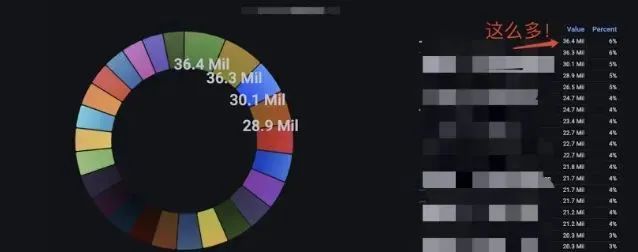
嗯,看起来 hotkey 的问题确实存在,好,我们继续。
经过以上三个方面的排查:我们发现,CPU 高、hotkey 明显。这里隐含了一个点:与 CPU 相对的是 OPS 并没有很高。
也就是说,虽然 Redis 很忙,但似乎并没有很高的服务产出——对,这句话用在工作上有时也挺合适。一般遇到这个情况,我们就要仔细分析下,到底 Redis 的 CPU 消耗在哪里了。
这里就要仔细分析下 Redis 的服务架构了,Rrdis6.0之前,主要采用的单线程模式,为什么采取单线程。官方的回答是:

核心意思是:CPU 并不是制约 Redis 性能表现的瓶颈所在,更多情况下是受到内存大小和网络I/O的限制,所以 Redis 核心网络模型使用单线程并没有什么问题,如果你想要使用服务的多核C PU,可以在一台服务器上启动多个节点或者采用分片集群的方式。
除了上面的官方回答,选择单线程的原因也有下面的考虑。在另一篇文章中:使用了单线程后,可维护性高,多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
回到正题,对于文件事件来说结构图是下图,单线程处理逻辑是:
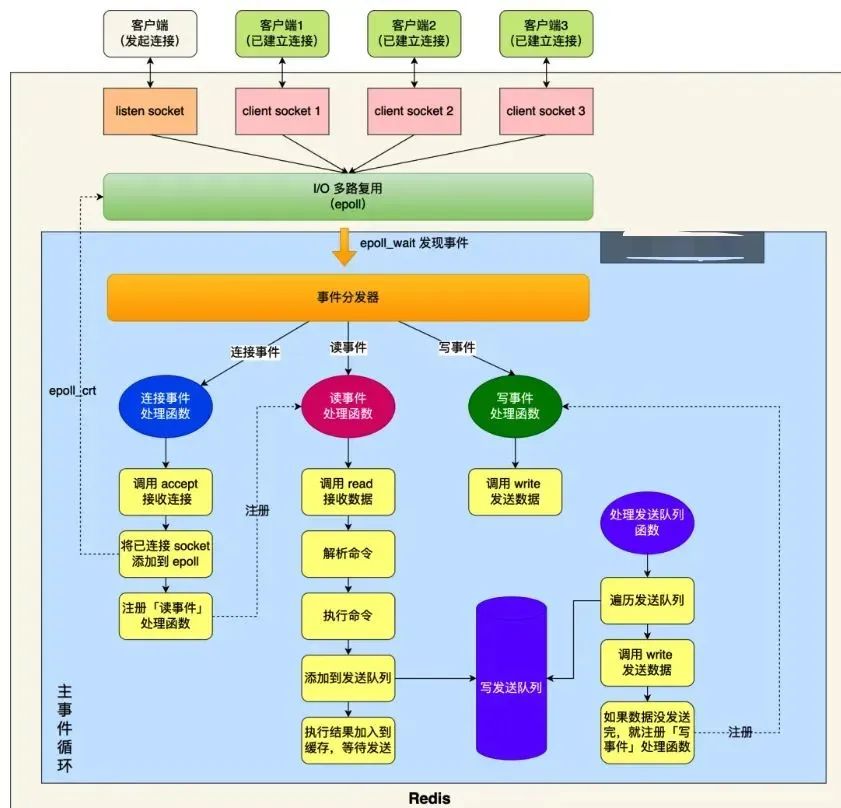
图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程,所以看起来这里会有挺多的网络 IO 在里面,那这里会不会有坑呢?
其中,在《Redis 6.0 新特性-多线程连环13问!》指出:
Redis 将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis 服务器可以处理80,000到100,000 QPS,这也是 Redis 处理的极限了,对于80%的公司来说,单线程的 Redis 已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的 QPS。常见的解决方案是在分布式架构中对数据进行分区并采用多个服务器,但该方案有非常大的缺点,例如要管理的 Redis 服务器太多,维护代价大;某些适用于单个 Redis 服务器的命令不适用于数据分区;数据分区无法解决热点读/写问题;数据偏斜,重新分配和放大/缩小变得更加复杂等等。
从 Redis 自身角度来说,因为读写网络的 read/write 系统调用占用了 Redis 执行期间大部分 CPU 时间,瓶颈主要在于网络的 IO 消耗,优化主要有两个方向:
提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
使用多线程充分利用多核,典型的实现比如 Memcached
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis支持多线程主要就是两个原因:
可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
多线程任务可以分摊 Redis 同步 IO 读写负荷
咦,这里是不是就是问题的关键呢?笔者负责的 Redis 的版本是5.0,且 QPS 这里也比较符合。事实上,关于网络 IO 占用 CPU 问题的深究来说,网上也有文章有说明。
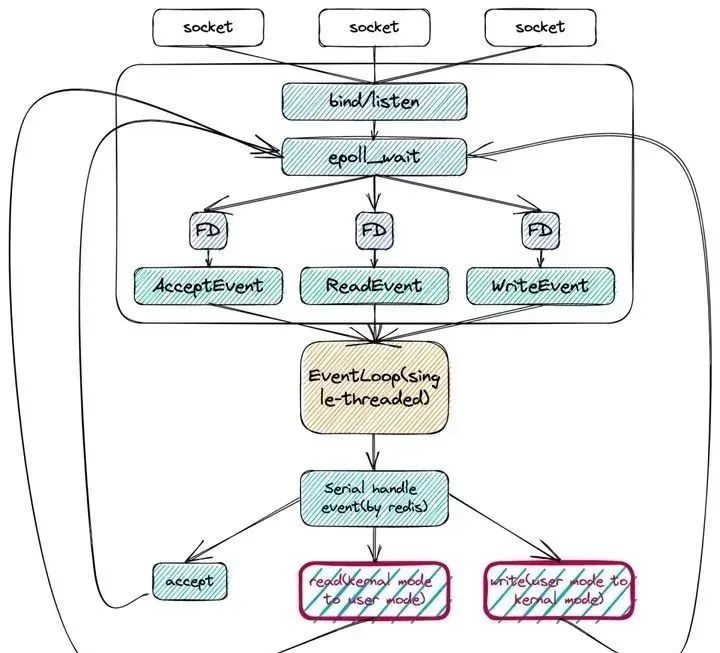
而 Redis 6.0 以前的单线程网络 IO 模型的处理具体的负载在哪里呢?虽然 Redis 利用epoll机制实现 IO 多路复用(即使用 epoll 监听各类事件,通过事件回调函数进行事件处理),但 I/O 这一步骤是无法避免且始终由单线程串行处理的,且涉及用户态/内核态的切换,即:
从socket中读取请求数据,会从内核态将数据拷贝到用户态 (read 调用)
将数据回写到socket,会将数据从用户态拷贝到内核态 (write 调用)
按照上文的介绍:上面的红色部分会导致 CPU 的消耗——说好的 Redis 的瓶颈不在 CPU 呢!
第三个重点:复现问题和测试的基本方法
那如何确认这里的猜测呢?按照先 Demo 确认——再模拟线上服务的方式。
既然是网络 IO 多,那怎么减少网络 IO 呢?两个方案:一个是 pipeline、一个是 Lua 脚本。
首先 kevine 同学了做了 pipline 的测试,并用 perf 做了检测,发现上下文切换次数却是少了!
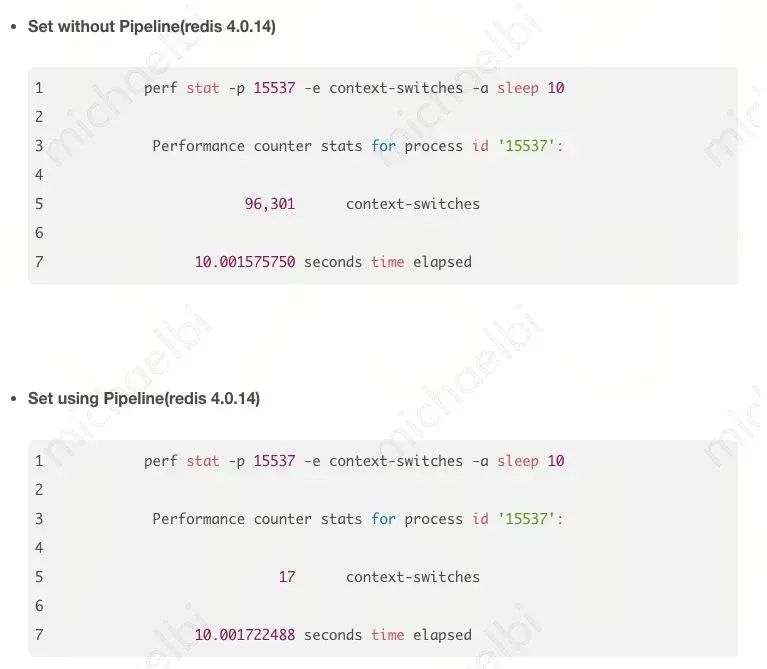
这里就会比较麻烦,因为一到线上,数据链路就会比较长。我们先简化一下服务链路。
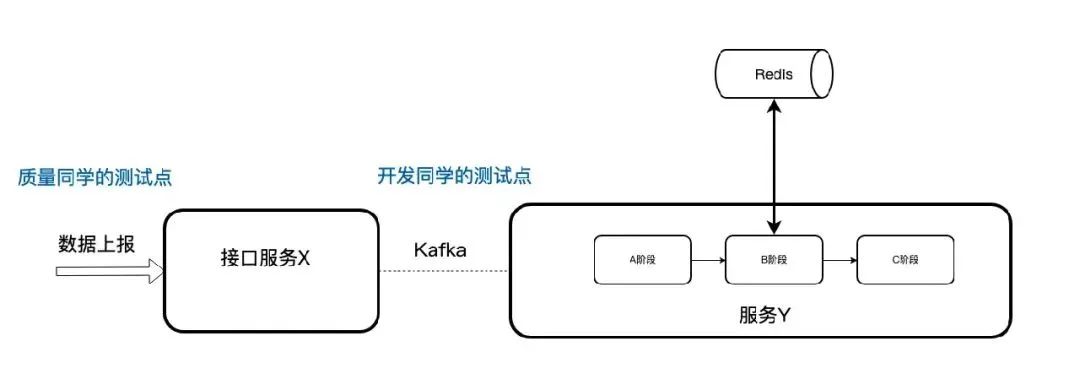
从质量同学的角度上看:压测讲究的是全链路模拟,不然就无法做上线前的最后的质量守护。
从开发同学的角度上看:复现问题最好用到最低的资源,因为更多的资源意味着更多的人力成本、时间成本、沟通成本。
两个角度都没有问题,事实上,笔者认为,只有从两个角度看问题,才能更好地平衡质量和效率。
在这里,笔者主要用的开发角度尽快的复现问题,所以选择模拟 kafka 的数据消费,然后给到服务 Y 压力,最终将压力传导到 Redis 中,具体工具使用 kaf。
首先将 kaf 装在了 kafka 的一个服务中。
然后抓取线上的数据30条(之所以抓的这么少,是因为线上就是 hotkey 的问题,这里模拟的就是大量相似数据访问的场景)。
使用 kaf 给到10000次的生产数据。
cat xxx-test | kaf produce kv__0.111 -n 10000 -b qapm-tencent-cp-kafka:9092
结果,压力不够。
为了提高压力,这里指定不同的 partition 平均写入,即每个 partition 写入10000次。
for i in {0..8};do cat xxx-test | kaf produce kv__0.111 -n 10000 -p ${i} -b qapm-tencent-cp-kafka:9092 ; done
结果,压力还是不够。
那就将 kaf 装在每一个 kafka 的服务中。
结果:
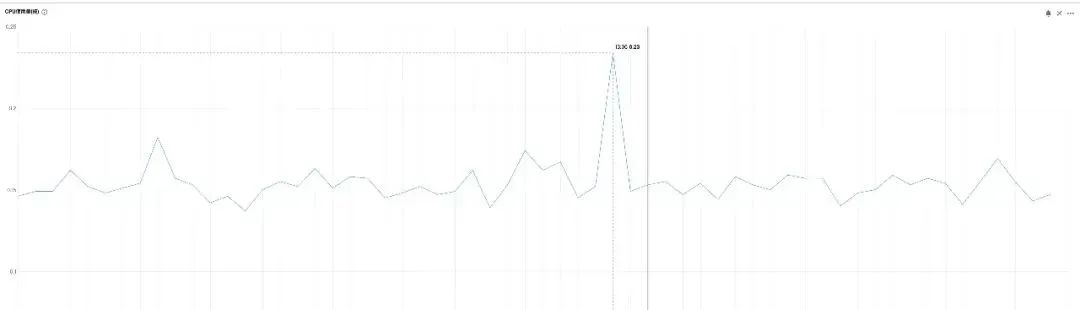
有效果,但 Redis 的 CPU 还是不是很高。
看下监控。
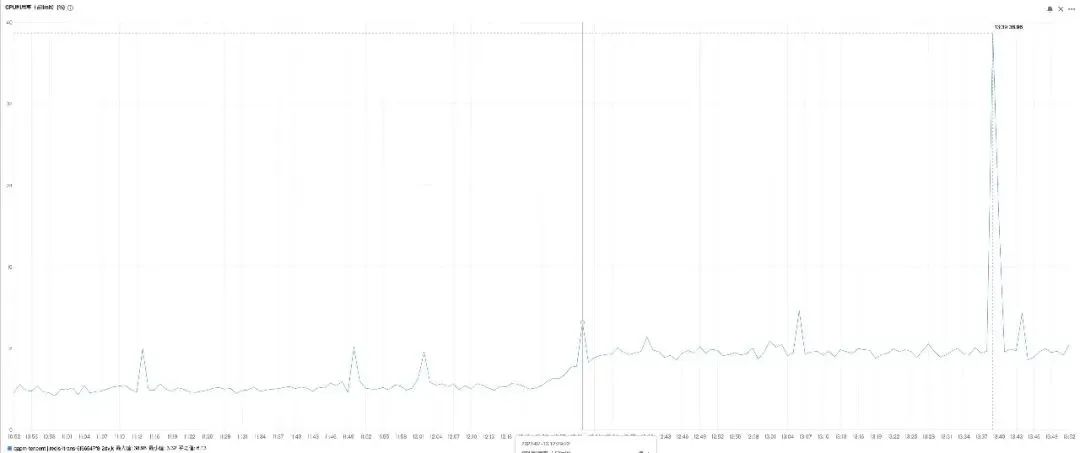
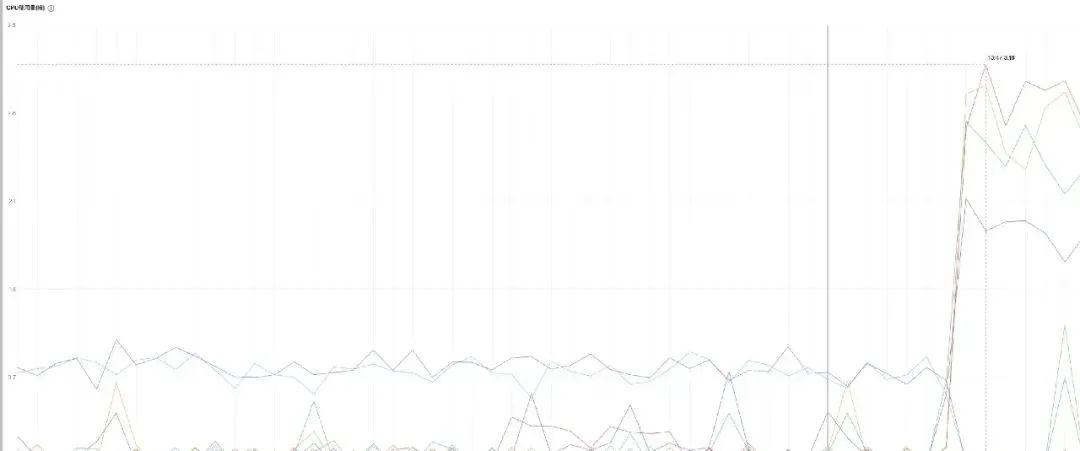
啊,服务 Y 的 CPU 一直也不高,看来,服务 Y 并没有感受到压力。
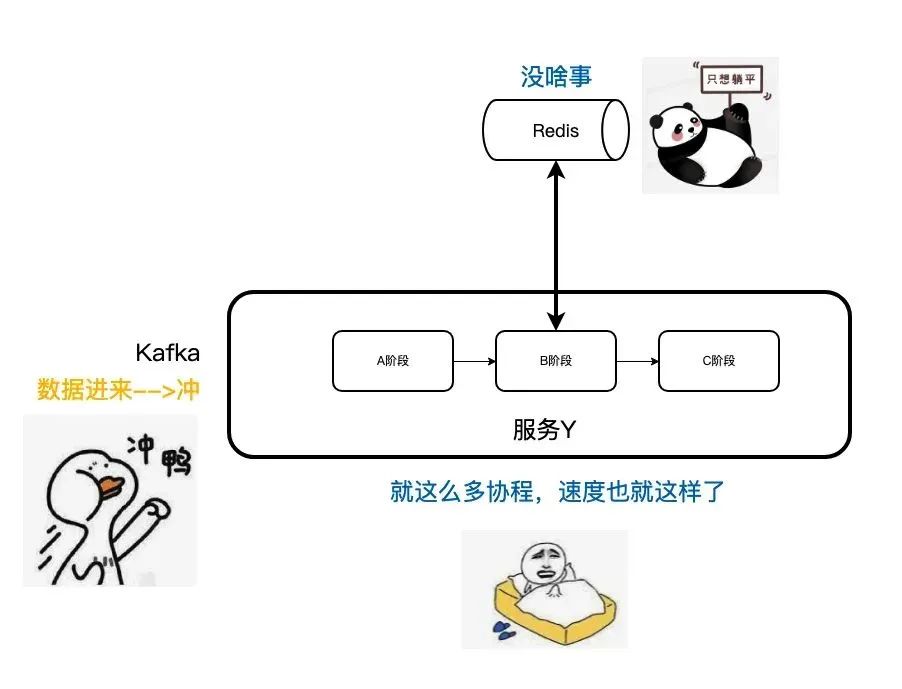
但内存提前满了。

加内存。这里其实也是一个资源调优的经验,事实上,一个服务的内存和 CPU 的比例关系需要结合线上的负载来看,而且要定期看,不然也会导致资源浪费。
好的,CPU 和内存都调整了,搞起!
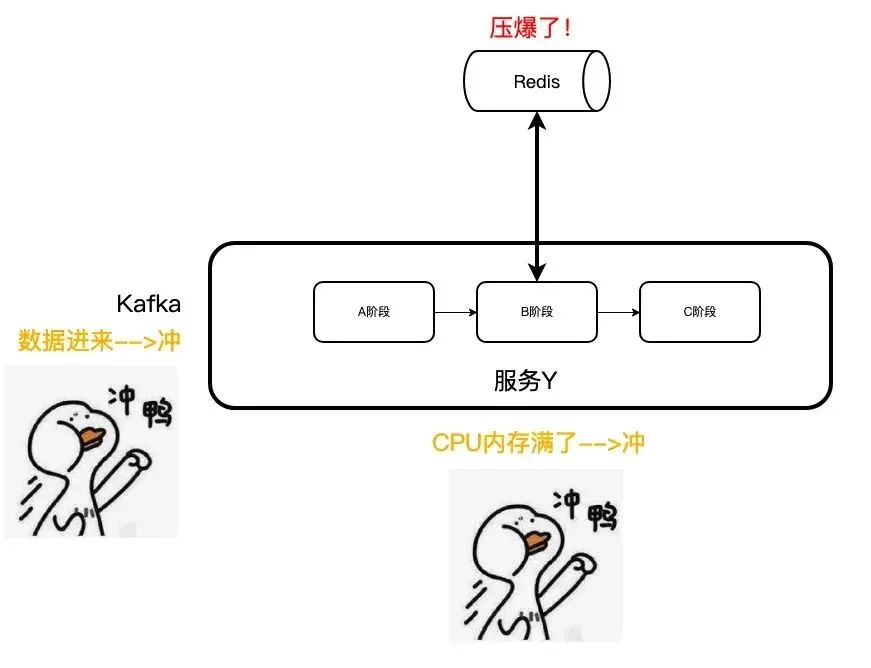
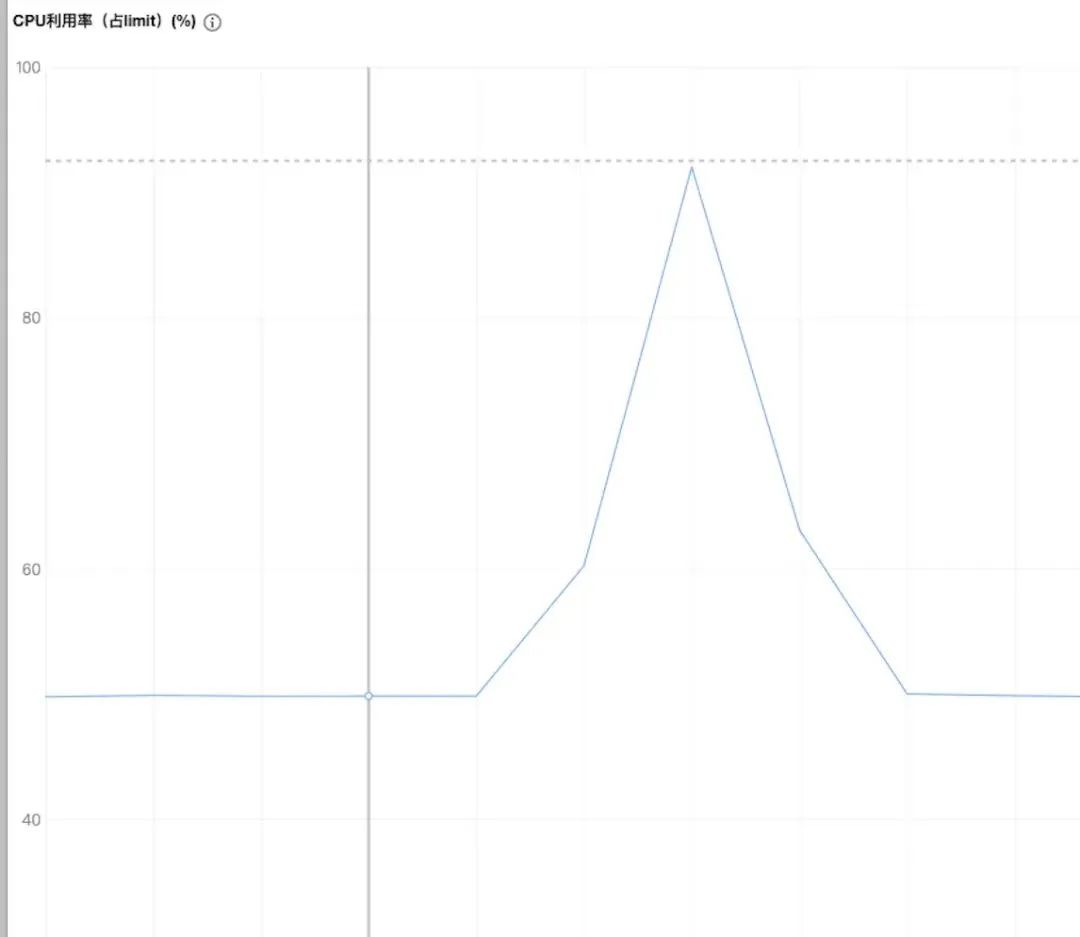
终于,Redis 的 CPU 上去了!看下 OPS:
果然:hotkey 其实就会导致 CPU 变高,而这时,因为大量的 CPU 都在数据切换和存储上,导致其他的请求比较慢。
现象对上了!那如何解决呢?
也是三板斧:
如果是多实例的话,就是经典的读写分离!
如果是单实例的话,就使用 pipeline 批量写入。
如果pipeline无法满足业务的话,就在业务服务只加一层缓存。
毕竟滑铁卢大学教授 Jay Black 的一句名言:计算机科学中的每个问题都可以用一间接层解决。
基于服务现状,笔者选择了第三种方案:然后,服务耗时降下来了!
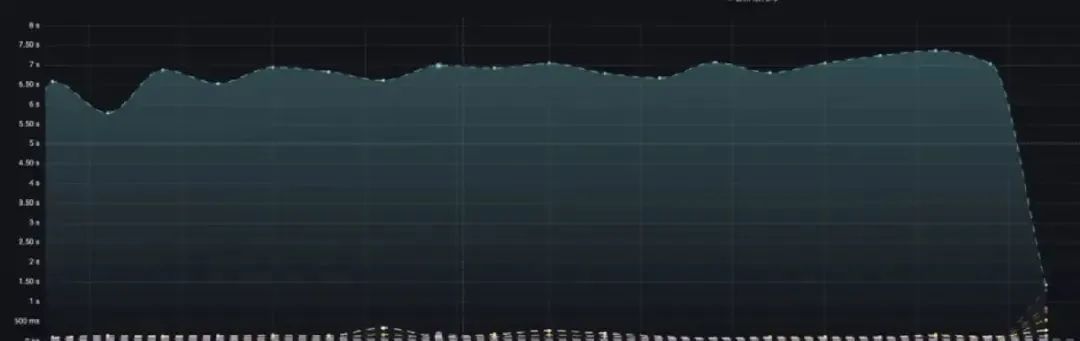
CPU 也降下来了。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721