
Kafka以解决大规模数据处理问题而闻名,并被广泛部署在许多知名公司的基础设施中。早在2015年,LinkedIn有60个集群,总共有1100个Broker,每秒处理1300万条信息。
但事实证明,规模并不是Kafka唯一擅长的事情。它所提倡的编程范式——分区、有序、事件处理——对于你可能面临的许多问题都是一个很好的解决方案。例如,如果事件代表的是要被索引到搜索数据库的行,那么最后的修改就是最后的索引,这一点很重要,否则搜索将无限期地返回陈旧的数据。同样,如果事件代表用户行为,处理第二个事件(“用户升级账户”)可能依赖于第一个(“用户创建账户”)。这种范式与传统的作业队列系统不同,在传统的作业队列中,事件是由许多工作者同时从队列中弹出的,这很简单,可扩展,但它破坏了任何排序保证。假设你想要有序的处理,但也许你不想使用Kafka,因为它是一个难以操作或昂贵的重型系统的声誉。
Redis现在有了5.0版本发布的“流”数据结构,与之相比如何?它是否解决了同样的问题?
Kafka的架构
我们先来看看Kafka的基本架构。基本的数据结构是主题。它是一个按时间排序的记录序列,只需追加。使用这种数据结构的好处在Jay Kreps的经典博文The Log中得到了很好的描述。
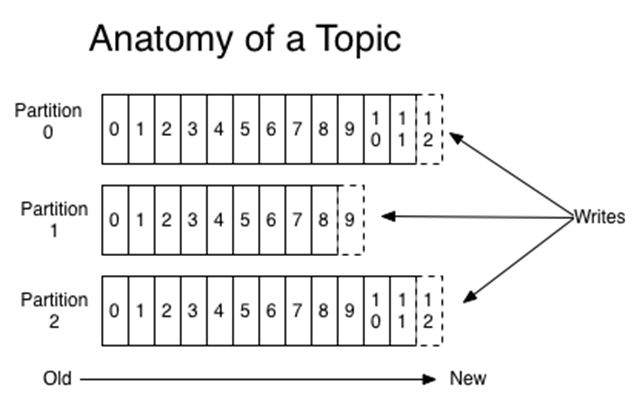
主题Topic被分区,以使它们能够扩展:每个主题可以被托管在单独的Kafka实例上。每个分区中的记录都被分配了连续的ID,称为偏移量,它可以唯一地识别分区中的每个记录。消费者按顺序处理记录,保持跟踪其最后看到的偏移量。由于记录被持久化在一个主题中,多个消费者可以相互独立地处理记录。
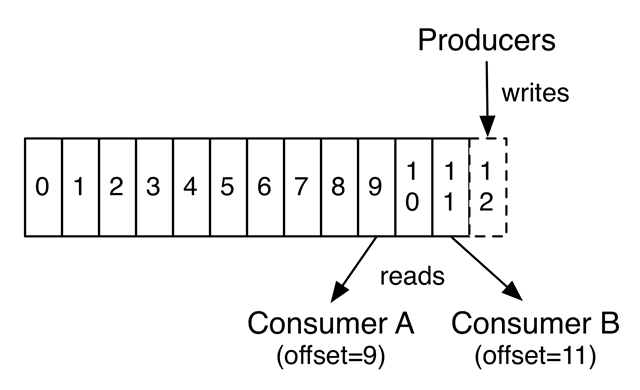
在实践中,你可能会将你的处理分布在许多机器上。为了实现这一点,Kafka提供了一个 “消费者组”的抽象,它是一组合作的进程,从一个主题消费数据。一个主题的分区被划分给组内的成员。然后,当成员加入或离开该组时,必须重新分配分区,以便每个成员都能获得公平的分区份额。这就是所谓的再平衡算法。
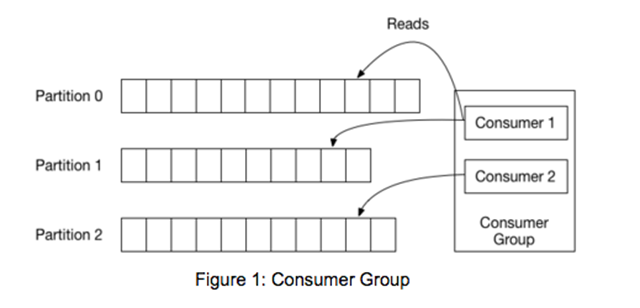
请注意,一个分区只能由消费者组的一个成员来处理。(但一个成员可能负责多个分区)这使得严格有序的处理得到保证。
这套工具是非常有用的。你可以通过添加更多的工作者来轻松地扩展你的处理,而Kafka则负责处理分布式协调问题。
Redis的流数据结构
Redis的“流”数据结构是如何比较的?Redis流在概念上等同于上面描述的Kafka主题的一个分区,但有一些小的区别。
它是一个持久的、有序的事件存储(与Kafka中相同)
它有一个可配置的最大长度(与Kafka中的保留期相比)。
事件存储键和值,就像Redis Hash(相对于Kafka中的单个键和值)。
最主要的区别是,Redis中的消费者组与Kafka中的消费者组完全不同。
在Redis中,一个消费者组是一组全部从同一流读取的进程。Redis确保事件只会被传递给组内的一个消费者。例如,在下图中,消费者1不会处理'9',它会跳过它,因为消费者2已经看到它了。消费者1将得到下一个未被任何其他组成员看到的事件。
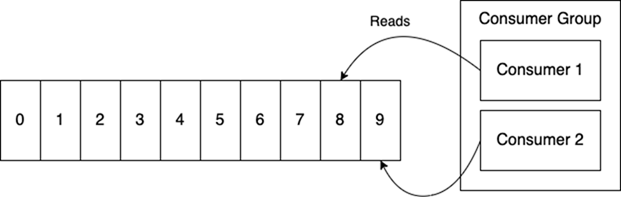
组的作用是将单个流的处理并行化。这看起来很像一个传统的作业队列结构。因此,它失去了作为流处理核心的排序保证,这是很不幸的。
流处理作为一个客户端库
那么,如果Redis只提供有效的具有作业队列语义的主题的单一分区,我们怎么能在Redis之上建立一个流处理引擎?好吧,如果你想要Kafka的功能,你需要自己构建它们。这意味着要实现:
1. 事件分区。你需要创建N个流,并将每个流视为一个分区。然后,在发送时,你需要决定哪个分区应该接收它,大概是基于事件的哈希值或其中的一个字段。
2. 一个工人分区分配系统。为了扩展和支持多个工作者,你需要创建一个算法,在他们之间分配分区,确保每个工作者拥有一个相互排斥的子集,也就是相当于Kafka的“再平衡”系统。
3. 有确认的顺序处理。每个工作者都需要迭代其每个分区,跟踪其偏移量。尽管Redis消费者组有作业队列语义,但它们在这里可以提供帮助。诀窍是每个组使用一个消费者,然后为每个分区创建一个组。然后每个分区将被按顺序处理,你可以利用内置的消费者组状态跟踪。Redis不仅可以跟踪偏移量,还可以跟踪每个事件的确认,这是很强大的。
这是绝对的最低要求。如果你希望你的解决方案是健壮的,你可能还想考虑错误处理:除了崩溃你的工作者,也许你会想要一个机制,将错误转发到一个 "死信 "流并继续处理。
好消息是——如果你喜欢Python的话--已经解决了这些问题,并且在一个新发布的名为Runnel的库中解决了更多问题。如果你想从Redis上类似Kafka的语义中获益,欢迎你来看看。下面是它的外观,基本上与上面的Kafka图之一相同。
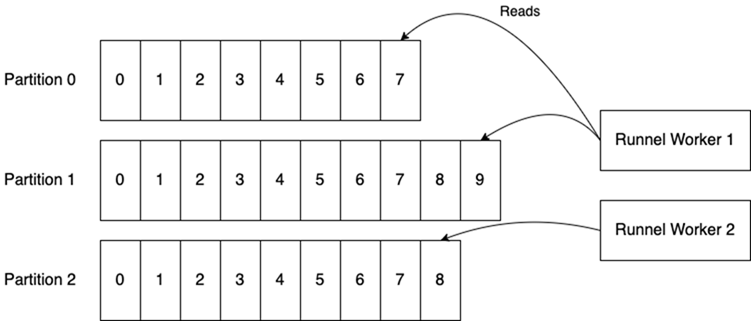
作者通过Redis中实现的锁来协调他们对分区的所有权。他们通过一个特殊的“控制”流相互沟通。更多信息,包括架构和再平衡算法的详细分解,请参阅Runnel文档。
权衡
Redis是大规模事件处理的好选择吗?有一个基本的权衡:因为一切都在内存中,获得了无与伦比的处理速度,但它不适合存储无限制的数据量。使用Kafka,你可能愿意无限期地保存你的所有事件,但使用Redis,你肯定要存储最近的事件的固定窗口——只够你的处理器有一个舒适的缓冲区,以防止它们变慢或崩溃。这意味着你可能还想使用一个外部的长期事件存储,例如S3,以便能够重放它们,这增加了你的架构的复杂性,但降低了成本。
研究这个问题的主要动机是在部署和操作Redis时涉及的易用性和低成本。这就是为什么它对Kafka有吸引力。它也是一套神奇的工具,经受住了时间的考验,非常了不起。事实证明,经过努力,它也可以支持分布式流处理范式。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721