
雷孝龙,去哪儿网资深DBA。2019年8月加入去哪儿网,负责公司的MySQL/Redis运维,以及自动化方案的设计与实施。曾就职于达梦数据库、映客直播;擅长于数据库管理、维护及优化等工作。
(文末有本期内容的PPT获取方式,不要错过哦~)
分享概要
一、背景介绍
二、去哪儿网Redis自动化运维体系
三、总结与展望
一、背景介绍
疫情三年对全球经济造成了巨大冲击,许多公司的业务量大幅下滑,旅游业更是遭受了重创。在这样的大环境下,公司为了降低运营成本,不得不采取一系列措施来缩减开支。其中,对于 DBA 这种运维团队来说,降低成本最直接的方法就是减少机器的开销。
在疫情期间,由于公司机票、酒店、火车票等核心业务流量的大幅减少, Redis 这种缓存服务器的内存使用量也骤然降低。于是,公司决定整合服务器资源,对 Redis 集群进行缩容降配,将多个实例集中部署到较少的机器上,从而腾出一部分空闲的服务器进行下线处理。据统计,疫情期间下线的机器约占 Redis 总资源的 30% 左右,这一举措大大降低了公司的运营成本。
然而,随着疫情得到控制,旅游业开始快速复苏。到 2023 年春节期间,流量已经基本恢复到疫情前的水平。Redis 资源的使用率大幅增加,但服务器的扩充速度却远远跟不上业务增长的速度。尤其是在春节这样的高峰期,导致服务器剩余可用资源和负载频繁报警,给运维工作和服务稳定性带来了巨大的压力和挑战。
为了应对这一现状,自动化运维工具成为了缓解压力的必要手段。通过开发和升级自动化平台,DBA 可以更加高效地管理大量的数据库服务器,减少人工干预和错误率,从而更好地应对与日俱增的 Redis 需求和流量。
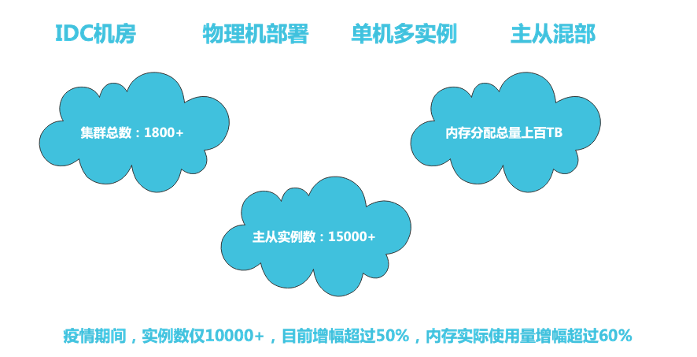
去哪儿网 Redis 目前部署在 IDC 机房,采用物理机进行单机多实例的主从混和部署,规模 百TB 级别,主从实例数 15000+ 。从疫情至今,实例数增长超过 50% ,内存占用总量超过 60% 。
流量快速上涨:整体内存用量快速增长,Redis 请求量增加,CPU 负载告警频繁。
业务上云:物理距离增加,网络延时变大,业务访问 Redis 超时变多。
业务容器化:业务容器化之后,机器数变多,Redis 连接数频繁告警,存在打满的风险。
业内机房故障:近两年,业内多次出现的机房级别故障,造成重大损失,给我们敲响了警钟,需要反思自己维护的服务是否真正具备跨机房容灾的能力。
二、去哪儿网 Redis 自动化运维体系
在介绍运维体系之前,首先了解我们的 Redis 集群架构。
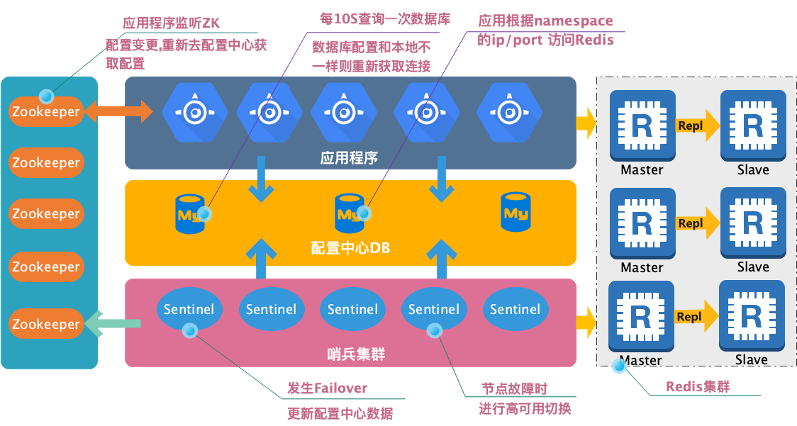
去哪儿网 Redis 集群是一个分布式的高可用架构,整个架构主要由以下几个重要部分组成:
Redis Server 节点:每个节点有一主一从两个实例,多个节点组成一份完整的集群数据,其中每个节点只有主库对外提供服务,从库仅仅用于节点高可用、数据持久化及定时备份。
Zookeeper 集群:由五个zk节点组成,存储Redis集群名,每个集群对应一个znode,用于Redis集群配置变更后,通知客户端进行重连。
Redis Sentinel 集群:由五个 Sentinel 节点组成,用于 Reids Server 节点的高可用,主从切换、故障转移、配置更新等。
配置中心:由五个 MySQL 节点组成的 PXC 集群,用于存储 Redis 集群的分片信息,即每个节点的 Master 实例信息及分配 key 的一致性 hash 值范围。
应用程序客户端:配置集群名和 zookeeper 地址,监听 znode 变化,通过集群名从配置中心获取 Redis 拓扑结构。
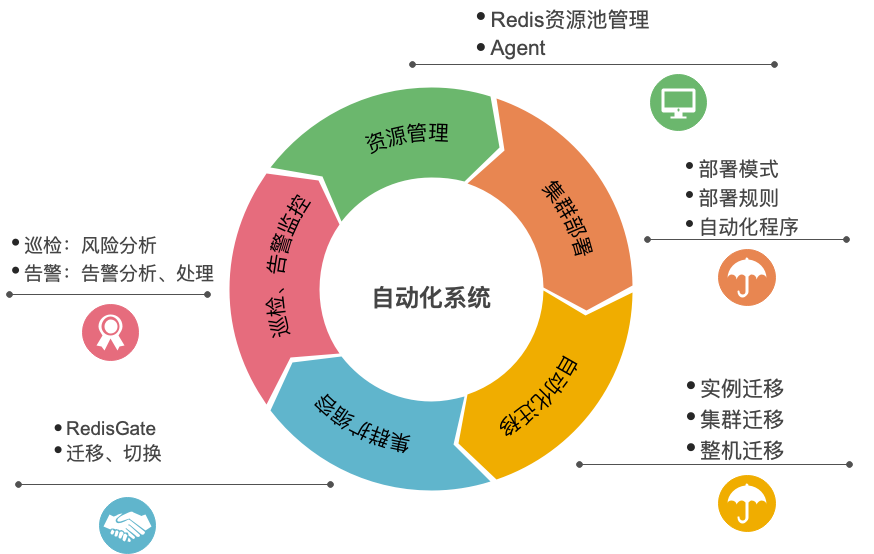
我们的 Redis 自动化运维系统主要由以下几个功能模块构建而成:
1)资源管理
Redis资源池管理
Redis 机器资源池依托于 OPS 的服务树,Redis 机器挂在对应的服务树节点,当有新机器交付时,会在对应服务树中添加,被数据库运维平台识别到,完成初始化后,便可以投入使用。
对于 Redis 集群资源的归属,根据访问机器所属的业务 appcode 来划分部门,一般情况下 Redis 资源基本不会跨部门使用,而且访问的应用相对单一。
dbaAgent
采集机器信息,实时更新实例部署情况、资源使用情况,业务连接机器。
提供一些运维脚本,大 key、空闲 key 分析等。
提供接口,实现远程调用,本地执行命令完成一系列的自动化流程。
在 Redis 集群部署和迁移等过程中,准确的基础信息是不可或缺的。因此,必须确保基础信息的准确性,并将其视为其它运维工作的基准。
2)集群部署
在 Redis 使用需求不断增长的背景下,集群部署是日常最为频繁的操作。运维的效率在很大程度上依赖于部署工具的稳定性和性能。通过使用我们自主研发的 agent 工具取代之前的 salt-minion ,自动化流程的性能和稳定性得到了显著提升。这大大减少了人为干预的时间,加快了交付速度,为我们的日常工作减轻了负担。同时,这也确保了业务能够快速获得所需资源,从而保证了业务的连续性和高效性。
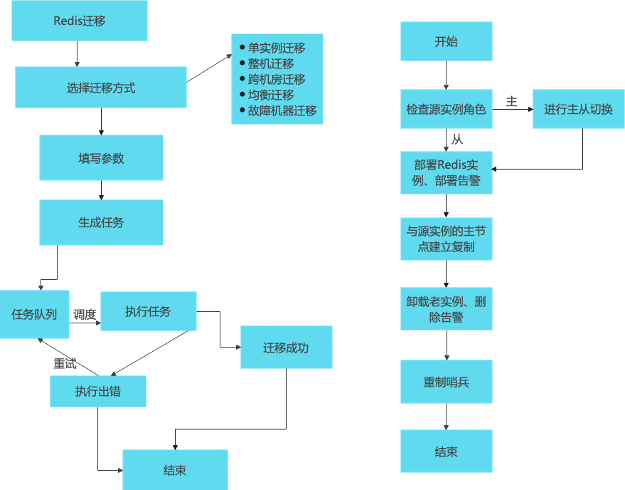
下图左边是自动化部署流程,根据填写的参数,如集群名、分片数、分配内存、机房选择等,提交部署任务;提交之后,存入任务队列等待调度,调度之后便开始部署,在某些情况下任务出错可进行重试,基本不需要人为介入处理,最后进行信息回填和交付。
右边是执行部署的步骤,按照定义好的部署规则,依次对集群的各个模块进行安装部署。
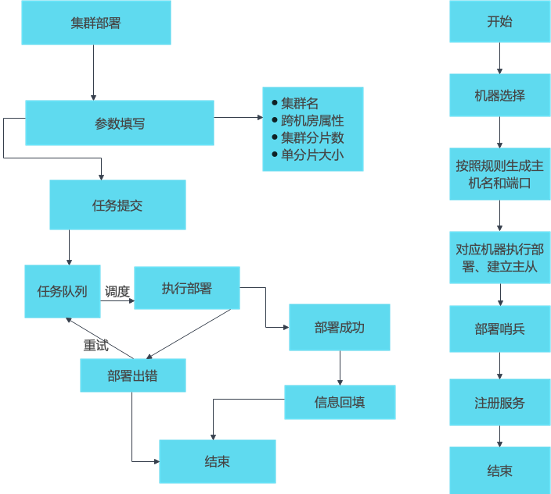
部署规则
每对主从实例端口相同且唯一。
单实例内存不大于10G。
机器部署实例数低于CPU核心数的1.5倍。
机器选择:使用内存不超过总内存使用中位数的10%。
同集群在相同机器部署分片数不允许超过3个。
3)自动化迁移
在日常工作中,我们经常遇到机器故障或升级维护的情况,这时候需要对 Redis 实例进行迁移。另外,随着业务增长,机器内存使用也会相应增加,为了确保有足够的内存提供服务,我们也需要对 Redis 实例进行动态迁移和调整。
基于日常运维需求,我们的迁移平台支持以下几种迁移模式,满足日常各场景的维护工作,迁移的规则仍然依照部署的规则实施,确保部署和使用的规范性:
① 单实例迁移
单个 Redis 分片点对点的迁移,从机器 A 迁移至 B ,迁移的节点为从节点,如果遇到主节点,需要先进行切换。
② 多实例迁移
多实例迁移故名思义是由一个个独立的单实例组合而成,用于不同的运维场景,多实例的场景下,尽可能的分散机器迁移,提升迁移的并行度,减少等待时间。多实例迁移主要用于以下几个场景:
③ 机器资源均衡迁移
在资源有限的情况下,面对业务线日益增长的需求,Redis资源超卖是不可避免的,必须采取一些有效措施来应对资源超卖引发的问题。疫情恢复初期,Redis内存分配总量超过了总机器内存的150%,业务高峰期时,不少机器内存使用大量增长。为了解决这一问题,需要快速调整Redis部署情况,将高使用率机器的实例迁移至使用率相对较低的机器上。当然,自动化程序在选择迁移目标机器时,也必须遵循部署规则,确保每台机器部署的Redis和使用情况保持相对均衡。
④ 集群迁移
按照集群维度集群迁移,主要用于跨机房/跨云改造。由于近期业内机房级别的故障频发,公司对于服务跨机房/跨云容灾相当重视,因此对于原先未按照跨机房部署的集群进行迁移改造,实现多机房部署。云主机对于我们来说,可看作一个新的机房,实现Redis集群的云容灾,将从库部署迁移至云主机即可。当然,云主机若要提供服务,延迟自会比本地机房大,这又是另外一个值得讨论的问题了。
⑤ 整机迁移
针对于机器故障、机器维护、升级、替换等场景,需要对单台机器的所以实例进行迁移,迁移前需要将机器的所以主实例切换为从节点,一键生成迁移任务;故障迁移场景区别于主动维护,机器故障后,故障机器对外服务的主节点由哨兵触发切换,自动化程序需要找到故障机器切换后的节点,这依赖于我们基础信息的维护与实时更新机制,能够正确找到对应节点,在不同机器上部署从库即可。
具体迁移流程如下,与集群部署类似,填入参数后即可发起迁移任务,等待任务队列进行调度;右图为编排好的自动化迁移流程,按照传入的参数顺序执行,完成单个实例的迁移过程。
4)集群扩缩容
Redis 是一个高性能的内存数据存储系统,能够随着业务需求的变化而灵活地调整内存和流量负载。在疫情期间,为了降低成本,我们采取了缩容降配和下线操作。然而,随着疫情的恢复和业务的快速增长,我们需要进行扩容以应对更高的需求。
去哪儿网使用的 Redis 集群架构与原生 Redis 集群有所不同,它采用客户端分片的方式。因此,对于这种架构来说,扩缩容相对困难,无法像原生 Redis 集群那样通过简单地添加新节点和重新分配数据槽位来实现。为了解决这个问题,我们采取了数据迁移的方法。
具体操作步骤如下:首先,将现有集群的数据迁移到新的待扩缩容的集群中;然后,交换新老集群的名称,以实现最终的扩缩容。这种方法有效且稳定,确保了数据的完整性和服务的连续性。
客户端分片
去哪儿网的 Redis 集群采用 hash 算法对数据进行分片存储。与原生 Redis 不同,它需要使用特定的客户端。在读写数据时,客户端会先计算出 key 的 hash 值,采用的是 murmurhash2 算法,hash 范围在 0~2**32 之间。根据集群配置中心的拓扑信息,客户端能够确定数据所在的分片,然后连接对应的分片进行读写操作。这一设计使得数据能够在集群中均匀分布,提高系统的扩展性和可用性。Redis 配置信息如下图所示:

如何建立Redis连接
前文提及的去哪儿网 Redis 架构中,客户端通过 zookeeper 集群监听对应集群的 znode 信息,并从访问配置中心数据库获取集群拓扑信息,进而连接到 Redis 分片。当 Redis 集群拓扑结构发生变化时,哨兵、自动化平台等会触发对应集群的 znode-dversion 变化,进而使客户端感知到并重新获取集群拓扑结构和重建连接。
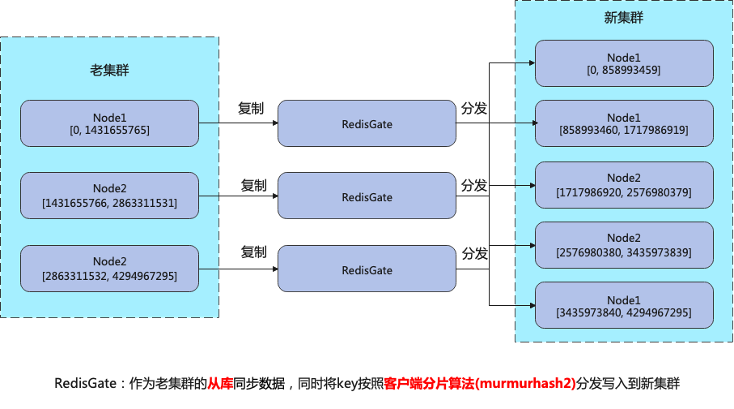
RedisGate
RedisGate 是基于 Redis 源码改造,作为去哪儿网 Redis 集群扩缩容的中间件角色,主要作用如下:
作为源端集群的从库,同步源集群的数据。
作为目的端集群的主库,存储目的端集群的拓扑信息;按照客户端分片算法,将数据分发到目的端集群的各个分片,实现新老集群数据同步,从而达到扩缩容的效果。
扩缩容架构如下:
代码实现如下:

扩缩容切换
使用 RedisGate 中间件实现源和目的端增量同步后,即可进行数据校验,比对源和目的端的数据一致性。可从两个维度进行比对,一是看源和目的 Key 的数量,但如果主库数据过期时间较短,因为 Redis 的惰性删除,往往会导致差异较大;此时可进行抽样对比,scan、randomkey 等,抽取部分 key-value 进行比对。从原理上看,我们的扩缩容架构等同于 Redis 的级联复制,因此同步延迟可等同 Redis 的主从级联复制。
当数据达到增量同步后,需要考虑如何在业务不做任何变更的情况下,做到无损的切换到新集群。前文提到的高可用切换依赖于 zookeeper,当集群拓扑结构发生变化时,会更新 znode 的 dversion ,因此在扩容切换时,先是交换配置中心源和目的的集群名(即修改源集群的拓扑结构),然后触发 znode 变更,从而通知客户端重新获取集群拓扑结构,重建连接。扩容切换,可类比一次集群的主从切换,对业务来说,需进行一次重连。经过上千次线上环境的实践,方案可行性和稳定性已得到验证,切换过程对于业务可以做到几乎无感知。
自动化流程
从新建集群、建立 RedisGate 数据同步、清理迁移环境等,整个流程已在平台实现自动化,仅在触发切换动作时,需人为介入点击确认,同时通知业务线完成扩缩容。
5)Redis巡检系统
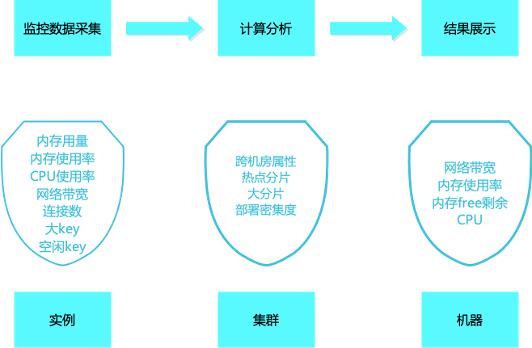
在提升系统稳定性方面,除日常的运维操作需遵循规范外,风险的预知也至关重要。为提前发现潜在风险,需要依赖于日常对线上服务的巡检。我们的巡检系统数据来源于监控系统和 agent 采集的数据。
通过实例、集群、机器等多个维度,对各项指标进行采集和分析,如果达到我们预设的风险值,即将问题暴露出来,需进行进一步的分析处理。虽然日常告警也能揭示一些问题,但往往达到告警阈值时,故障可能已经发生。
因此,通过设置更低的阈值和进行更全面的分析,可以有效预防 Redis 集群可能出现的各种问题。这样,系统稳定性得到了进一步增强,确保了服务的连续性和可用性。
下图展示了去哪儿 Redis 巡检系统的相关流程及巡检指标:
三、总结与展望
以上详述了去哪儿网 DBA 团队如何使用和维护 Redis 集群,并直面遇到的各种挑战。通过自动化手段,我们实现了许多日常运维操作的规范化和标准化,如部署、迁移、扩缩容等。整个过程几乎无需人工干预,从而显著减轻了 DBA 的负担,真正地达到了降本增效的目标。此外,自动化程序取代了人工操作,使得线上变更流程更为统一规范,消除了人为的不确定性,进而提升了 Redis 服务的整体稳定性。
尽管自动化为我们减轻了大量负担,但仍面临诸多挑战。在我们公司,几乎所有业务已顺利迁移至云端或具备随时弹性上云的能力,但部分敏感业务由于无法容忍云端到本地机房的延迟,这便要求我们解决 Redis 的跨云部署和就近访问的问题。这是我们当前需要攻克的难题。
随着 AI 技术的迅猛发展和广泛应用,数据库运维领域也需紧跟时代步伐。通过运用机器学习和人工智能技术,我们可以实现更智能的 Redis 监控和维护。尽管我们的巡检系统已能提前发现潜在问题,但进一步的深度分析和处理仍需人工介入。为此,我们渴望利用 AI 技术,实现在风险被识别时即刻进行优化和自愈,这是我们对未来的憧憬,也是我们未来的工作重心。
获取本期PPT,请添加群秘微信号:dbayuqing








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721