
Nick,携程软件技术专家,关注分布式数据存储以及操作系统内核。
在《携程 Redis 跨 IDC 多向同步实践》一文曾和大家分享过携程在 Redis 双向同步方面的心得,简单介绍了实现一个 Redis 双向同步系统中可能面临的问题,以及其中一种问题(分布式一致性)的部分处理方案 -- CRDT(Conflict-free ReplicatedData Types)。
本文将进一步阐述在具体设计和落地过程中的一些细节,希望对大家能够有所帮助。包括:
Cycle Break -- 如何打破盗梦空间的无限循环;
Last Write Wins & Vector Clock -- 冲突的解决既简单又复杂;
Tomstone -- 忆往昔才能看今朝;
GC -- CRDT 取经之路的通天河;
Expire -- 一致 or 不一致, 这是个问题。
相信通过对这些问题的描述和解答, 大家对于如何实现一个双向同步的 Redis 会有一幅清晰的构图。
一、Cycle Break —— 如何打破盗梦空间的无限循环
以下图为例:

假设 A <-> B <-> C 三个 Redis 建立起了双向复制关系。现在客户端先向其中一个 Redis(假设 A)发送了命令,SET KEY VAL(将 key 的值,设置或更新为 val),那么大概率会发生以下这样的步骤:
A 将 SET KEY VAL 同步至 B 和 C 。
B 和 C 接收到操作后,又再次同步给其他两个 Redis 。
如此循环往复 ...
综上所述,复制回环所带来的问题结合普通的数据结构,会带来以下问题:
网络风暴;
数据不一致。
如何解决这个问题呢,无非以下几种方式:
在数据上做处理,使数据携带一定的信息,服务端通过对数据所携带信息的甄别,过滤掉冗余消息。
在内容分发上做处理,服务端能够识别不同的链接类型,从而做到有的放矢,在同步数据之初便加以控制。
针对 Redis 这种场景,我们选择了第二种处理方案,既在复制数据的时候,根据数据来源的类型,来决策是否同步给其他 Redis。
为了方便大家理解, 这里简单介绍一下 Redis 的内部实现:Redis 对于每一个TCP链接,都会抽象成为一个叫 client 的对象,见下图。而其中有一个 flag 表示了这个链接(client)对应的类型,这就很好地契合了上文中列举出的第二条选项。
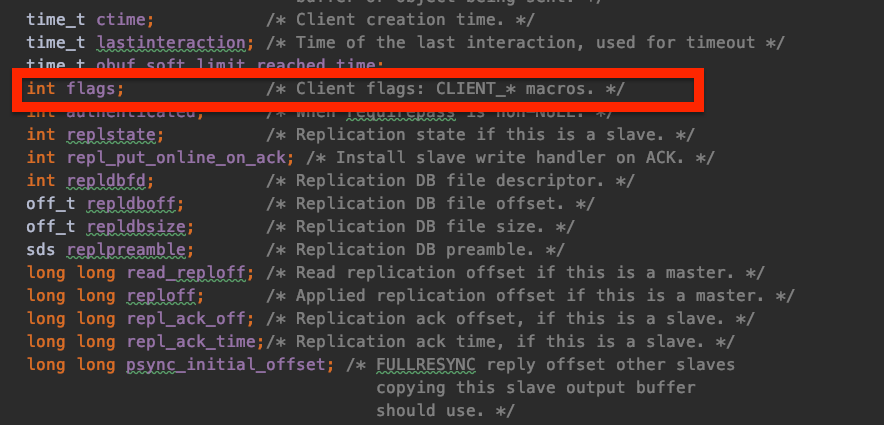
所以,我们最终的处理方案是:Redis对数据源进行甄别,只有属于来自客户端的操作,才会被选择性地同步给 Peer Master。然而,对于传统的 Master-Slave 架构来讲,还是会把所有对数据库有变更的操作,都同步给 Slave。
二、Last Write Wins & Vector Clock ——冲突的解决既简单又复杂
这里以一对简单的 K/V 为例,介绍下是如何处理冲突的。
下面一幅图很好地诠释了,为什么会有冲突以及冲突的后果。
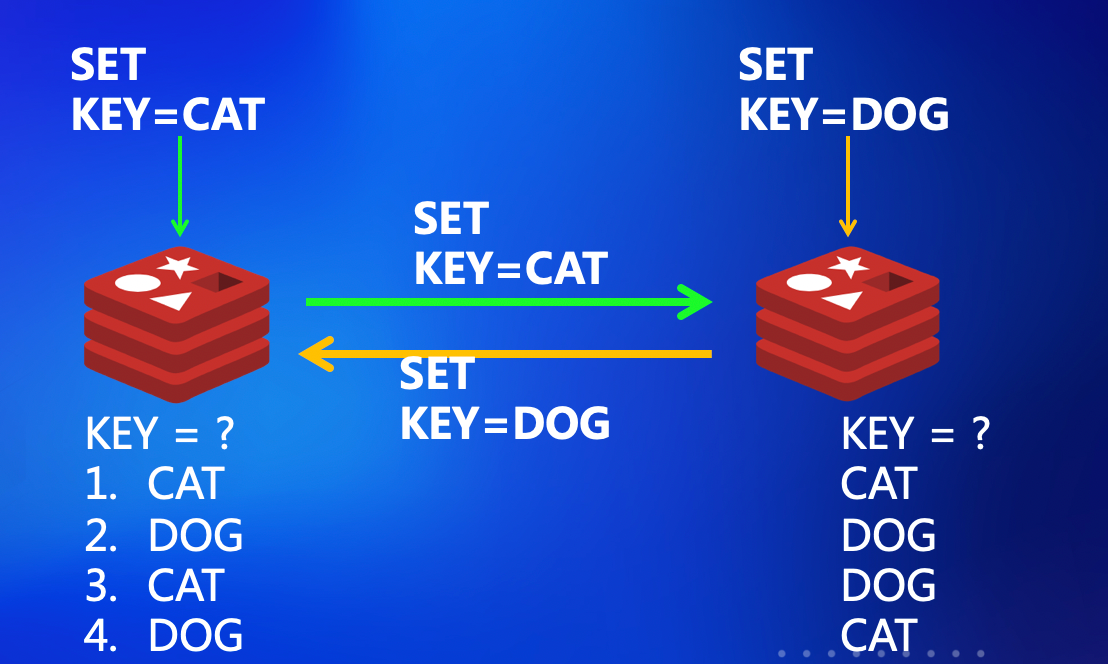
假设我们在同一时刻,分别在两个互相同步的 Redis 上更新了一个 Key,左边的试图将 Key 设置为 CAT,而后边的客户端试图将 Key 设置为 DOG。
那么总共会有以下 4 种结果,前两种虽然不尽如人意,但至少保证了数据的一致性。而后面两种则是大家不希望看到的,因为数据不一致对业务造成不可忽略的风险。
其实解决这个问题也很简单,就是“最后写入为准”的原则。以下图为例,假设两个 Redis 分别收到了对于同一个 Key 的设值需求,那么我们就可以简单地根据这个原则来判定,最终的结果是最后一次的写入为准。
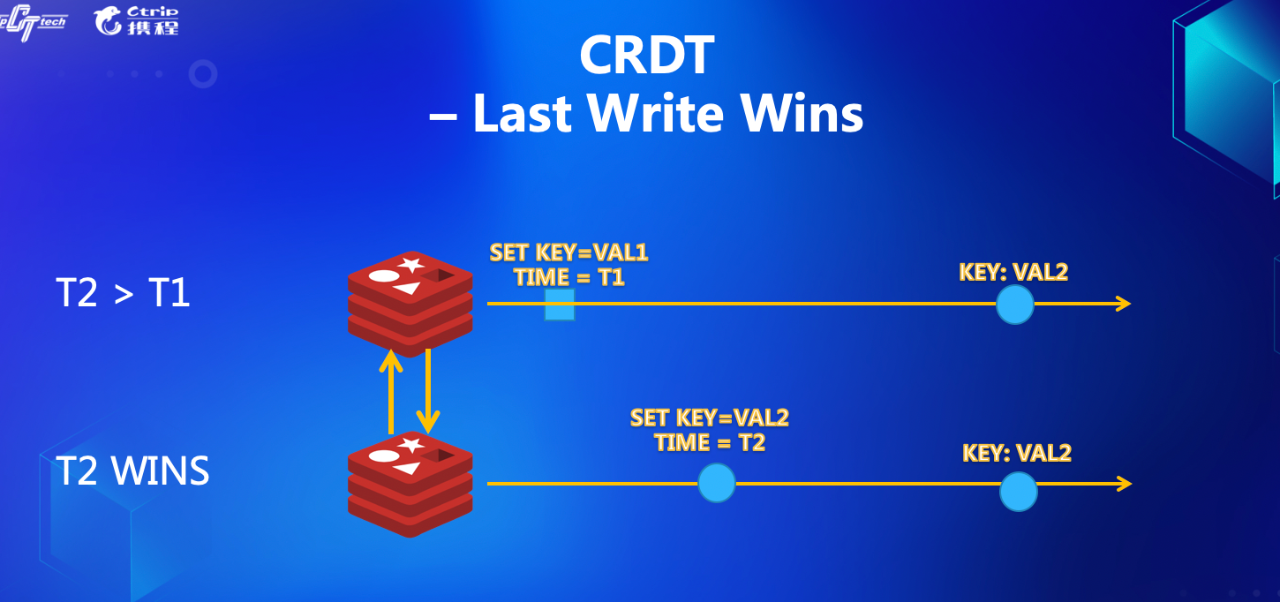
看到这里,大家也许会发现,原来冲突处理如此简单,那我也可以大展身手了。当然,大部分系统的实现,做到这一层,已经解决了分布式一致性的问题。但是,是不是这样就皆大欢喜了呢?
答案当然是否定的,继续往下看你就会发现,这小小的 K/V 一致性,只是分布式系统中的冰山一角。冰山的下面有着千奇百怪的洪水猛兽,一个没处理到,都会带来无可估量的业务损失。
相信部分同学在上学阶段或是工作以后,拜读过分布式系统的经典书目 --Distributed System Concept and Design (如下图)。这本书在开篇就对分布式系统有了一个经典的定义:
Concurrency ;
No Global Clock ;
Independent Failures。

下面这个问题就是由时钟问题引起的。
大家知道,不同的互联网组件之间是靠着 NPT-Server 这一工具来达到时间的一致性的,但是不同的网络区域之间的 NTP-Server 却并不一定是同步的。即使同步,时钟的准确性往往取决于网络的稳定性(这一点与网络延迟无关,也就是说即时延迟是中美之间大概 200~300ms,如果是稳定的延迟,那么 NTP-Server 的同步也基本稳定)。
如下图所示:
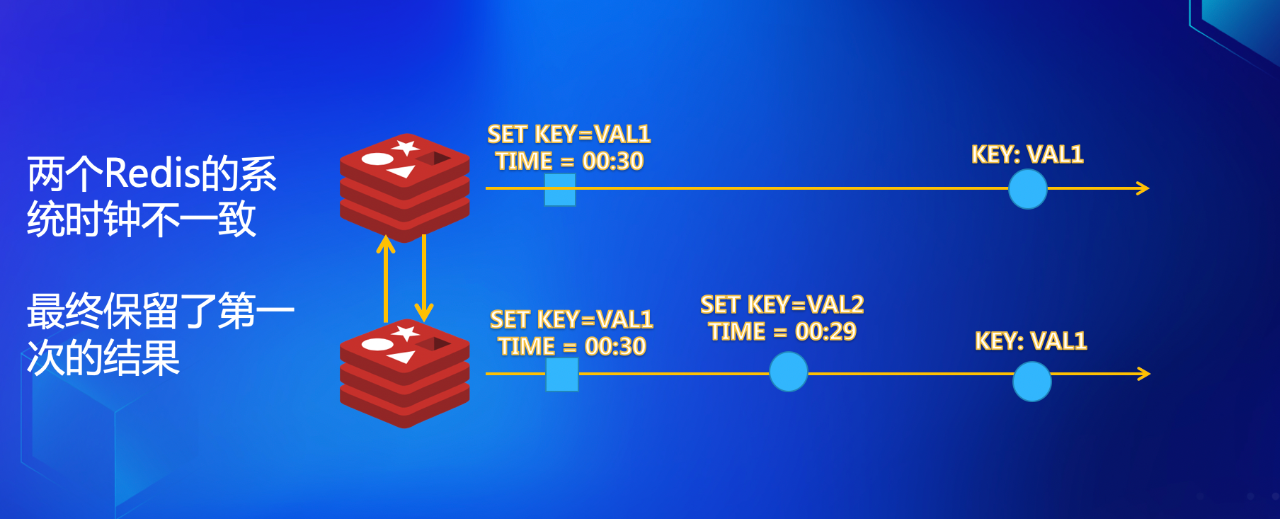
在下面的 Redis(我们称之为 Redis-B)的网络域的物理时钟(Wall Clock),比上面的 Redis(我们称之为 Redis-A)的网络域的时钟慢,在 Redis-A 上一个很早的操作发生之后,Redis-B 方才收到关于同样Key的操作。从逻辑上讲我们更希望 Redis-B 的操作作为最终结果,然而由于时钟的快慢,如果使用 Last Write Wins 的策略,反而是早些时候在 Redis-A 上面的操作占了上风,最终值为 VAL1。
那么时钟快慢带来的问题,是否无可避免?其实未必。
以上面的问题为例,是不需要冲突处理的,只是单从 Wall Clock,我们无法判定逻辑操作的时间。所以引入了一个叫 Vector Clock 的逻辑时钟,来表示一个操作的发生时刻。
以下图为例,全局有两个点,我们通过两个向量来表示发生过的逻辑操作。
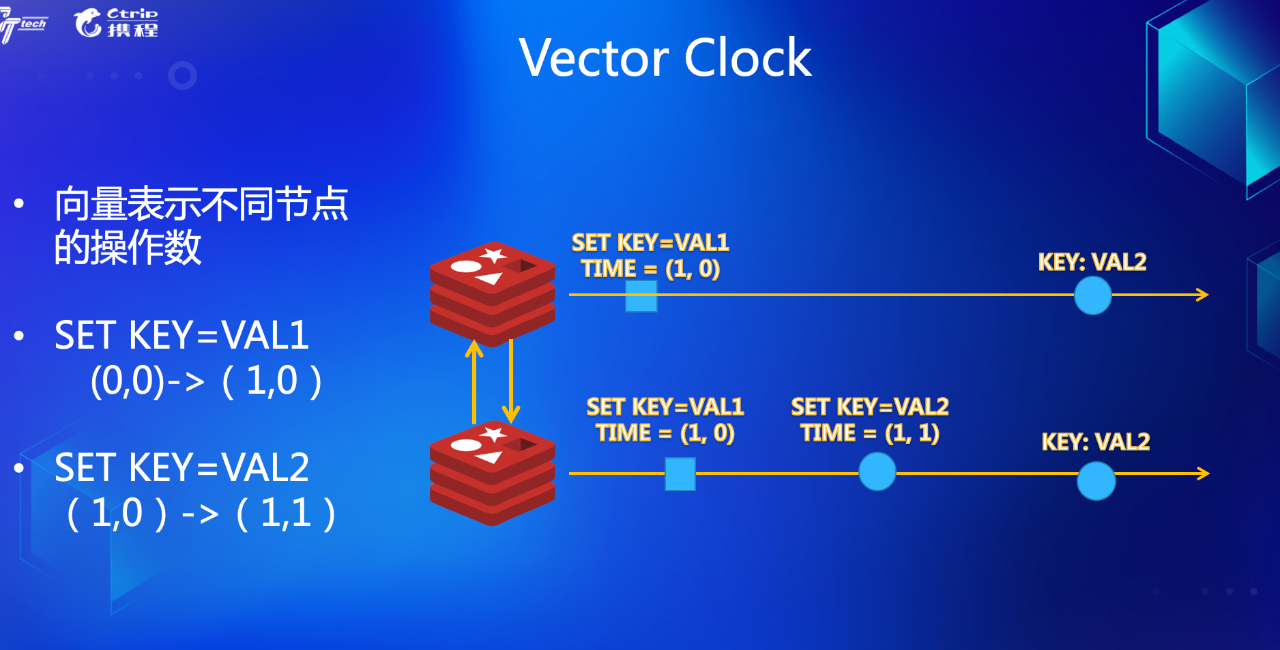
这里不展开讲了,具体 Vector Clock 是如何定义的,有专门的论文论述。而 AWS 闻名遐迩的 DynamoDB,更是通过对 Vector Clock 的理论改进,找到了更加适合自己的一种叫 Version Clock 的理论依据,感兴趣的同学可以 Google 。
三、Tomstone ——忆往昔才能看今朝
前面讲了数据回环复制的处理、数据一致性的处理,这样一个简单的分布式K/V 数据库就诞生了,但是删除操作依然会成为系统的“阿喀琉斯之踵”。
请看下图:
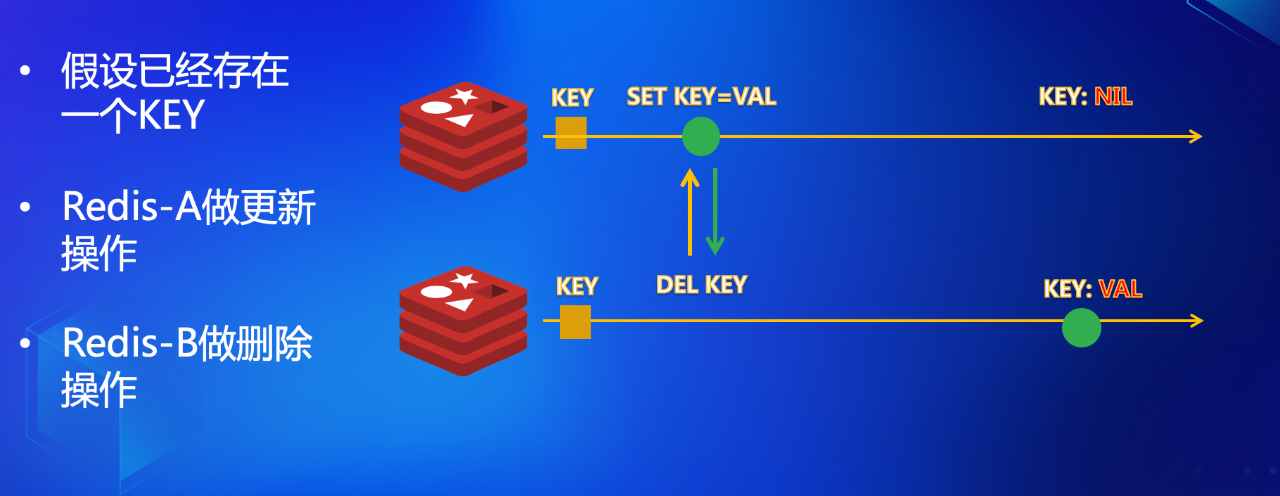
假设我们已经存在了一个Key,在同一时刻 Redis-A(依照上文惯例,我们称上面的 Redis 为 Redis-A)收到了更新请求,设置 Key 为 VAL,而 Redis-B 却收到了 Delete 的命令,两个 Redis 互相同步之后,发现数据不一致了。
问题的根源在哪里呢?在于 Delete 操作,将 Redis-B 上的值删除了,当 SET KEY=VAL 的更新操作到达之时,便没有了可以比较的对象。
这个问题该如何处理?既然是没有对象可比,我们创造一个对象不就可以了吗?于是诞生了 Tomstone —— 被删除对象的栖身地。对象的删除,我们只做逻辑删除,并不会将对象真正地从内存中抹去,而是放置在一个叫做 Tomstone 的地方,让其他后续的命令,能够和之前的命令有一个对比。数据的存留与否也就有了判定的依据。
四、GC —— CRDT 取经之路的通天河
GC -- Garbage Collection,很多语言都有这个特性,像 Java,Go。无独有偶,我们这里所说的 GC,原则和这些语言无异,都是为了处理一类不再使用,但是又占有资源(通常是内存资源)的一些数据的回收。
上一小节,我们简单介绍了 Tomstone 的概念,GC 也是由于 Tomstone 的引入而带来的在实践中不得不面对的问题,如下图所示:
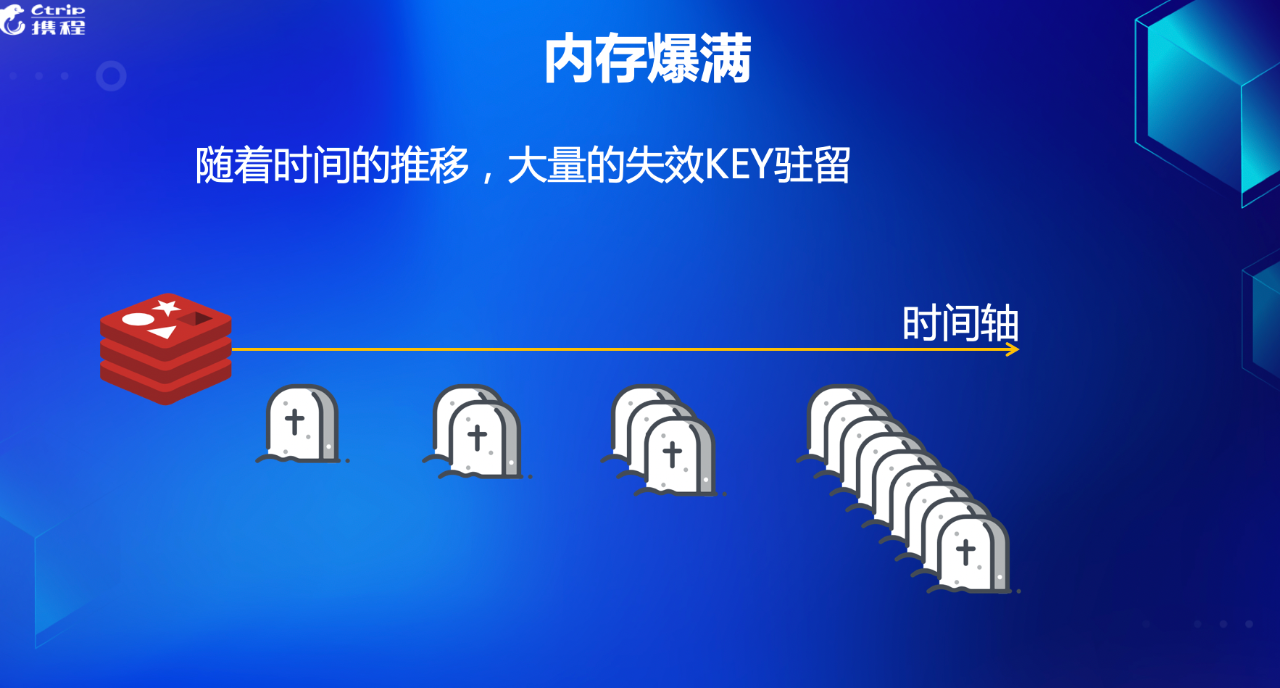
随着时间的推移,我们 Tomstone 中的对象会越来越多,直到吃掉你的全部内存,然后程序崩溃。
VectorClock 的灵活妙用。
如何 GC 的问题,其实不如说是什么对象可以 GC,这里我们也举两个经典的GC算法:
寻根法(GC Root) ;
引用计数法(Reference Count)。
两种算法各有优劣,Reference Count 可以方便地及时发现需要 GC 的对象,却无法解决循环引用的问题;GC Root 可以解决循环引用的问题,却给 GC 扫描带来了一定负担。
我们的系统,采用了类似 RC 的算法来实现 GC:如果发现其他所有同步的 Redis Peer Master 都已经知道了某个对象被删除的事实,那么这个对象,就可以被永久删除(也就是 GC)了。
怎么发现对方知道某个对象被删除了呢,前面有提到每个 Redis 都有自己的 Vector Clock,而 Vector Clock是和操作绑定的,只需 Redis 之间互通有无,互相了解到对方的 Vector Clock,那么如何发现某个对象是否过期的问题也迎刃而解。
当然, 整个过程也并非上面说起来那么简单。
比如,GC 的策略选择,是主动 GC 还是被动 GC,抑或是两者的结合?
单次 GC 时间长短的控制?如果 GC 时间过长,必然会影响 Redis 的响应速度;过短的 GC ,则会导致对象一直堆积在 Tombstone 中,内存得不到释放。

五、Expire ——一致 or 不一致,这是个问题
作为缓存来说,比较常见的是配置一定的缓存过期策略。一方面,可以保障数据的新鲜程度,另一方面无限制地将数据存入缓存,不仅不利于缓存的查询速度,对于资源来说也是不小的开销。所以,Redis 中引入了 Expire 的过期机制,给每一个缓存的 Key 设定一个过期时间是一个良好的习惯。
但是,在加入双向同步的架构之后,expire 似乎成为了一个问题,要不要将过期时间保持一致?如果保持一致的话,应该采取怎样的数据结构?
首先,我们应该确认一个问题,缓存的过期时间不一致,会不会导致数据一致性的问题?结合 Redis 的实现来说,缓存过期时间不一致,不会带来数据一致性的问题(这个数据特指除过期时间之外的用户数据)。要说明白这个道理,我们先来看一下 Redis 是如何过期数据的。
Redis 的过期策略简单来说分为两种,一种是主动过期,以一个固定的频率轮询存储过期时间的字典,发现有 key 过期就执行删除操作;另一种是被动过期,在用户对 key 操作时,同时判定一下 key 的过期时间,是否需要过期掉。
两种过期策略,都由 master 发起,slave 本身通过被动接受 master 同步过来的 delete 操作,来达到数据一致性(这里我们忽略 slave-read-only 为 false,且有客户端过期 key 写入的场景)。其实这个状态下,是存在已经过期,但是在内存中没有被删除的 key,这个时候访问 Redis,外在的表象为 key 不存在。那么对于客户端来说,数据是一致的,过期的 key 确实拿不到了(虽然 Redis 内存中可能还有)。
对于双向同步来说,如果并发地在两端的 Redis 执行 expire 操作,就会发生冲突,是否处理冲突,如何处理冲突,是我们这里想要讨论的点。
在我们实际实现的过程中,曾经有一个版本确实实现了 expire 多个 Redis 之间的一致性,但是这样做,引入了更多的数据结构来解决冲突处理问题。对比普通版本的 Redis,同样大小的 expire 数据量,内存要多出一倍。对于携程这样 Redis 重度依赖的用户来说,内存的增加无疑伴随着大量费用的上升。所以最终的实现上,我们并没有采取 expire 时间一致性的策略。
那么是不是 expire 时间不一致,数据就有问题了呢?当然不是。举例来说,有 A/B 两个 Redis 建立了双向同步。A/B 在同一时间点,分别对同样的 key 设置了不同的过期时间(如下图)。

一边设置过期时间为 30s,另外一边设置为 60s,互相同步之后,时间进行了对调。30s 以后 Redis-A 上面的 key 过期,触发了 del 操作,同时把这个操作传播给 Redis-B,因为 delete 机制的存在,两边的数据是一致的。
缓存过期(Expire)这一小节,先分享到这里。实现的过程中,我们还对过期策略进行了优化,防止并发的过期删除操作,造成不必要的网络开销。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721