
布莱德,携程技术专家,负责Redis和Mongodb的容器化和服务化工作,喜欢深入分析系统疑难杂症。
向晨,携程资深数据库工程师,专注于数据库和缓存智能运维工作。
一、背景
2019年,随着携程G2战略和国际化的推进,有一些大容量的Redis集群需要出海对海外客户提供服务,相比私有云的单GB成本,公有云上的Redis要贵10倍左右,这迫切需要我们寻找一种能替代Redis的廉价方案部署在海外,我们开始着手调研Redis On SSD的可行性。
二、调研和选型
携程大部分Redis数据是通过xpipe同步到海外(图1),而xpipe是实现了Redis复制协议的伪slave, 为了让海外基于SSD存储的替代Redis的方案能够顺利落地,需要兼容Redis的协议,Redis的协议基本分为两大块:
面向客户端的协议,如ping/set/get等客户端的命令。
复制协议,slave同步master时需要用到。
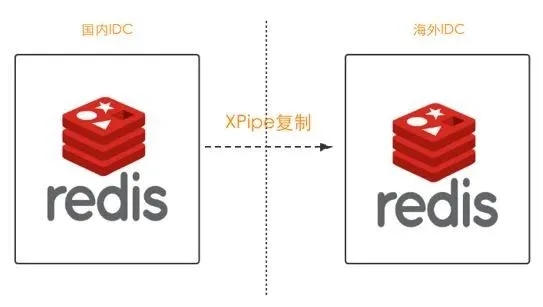
图1
我们调研了目前绝大部分Redis的替代方案,如Redislabs的Redis On Flash,360的pika和美图的kvrocks。
Redis On Flash:https://redislabs.com/lp/redis-enterprise-flash/
pika:https://github.com/Qihoo360/pika
kvrocks:https://github.com/bitleak/kvrocks
其中Redis On Flash是商业化的产品,无开源代码,pika市面上使用的公司比较多,但缺点也很明显:
面向客户端的协议是Redis的二进制协议,而面向复制的却是基于google的protobuf格式,语义层面有割裂感。
复制是基于Rsync的多进程模式,这种复制模式比较重,出现问题也不好定位。
代码风格比较乱,此外网络类库也用的是360自家的pink,二次开发比较困难。
而kvrocks很好的避免了pika的这些问题,语义和复制上与Redis原生的更加接近,缺点是刚刚开源,几乎无任何公司来使用kvrocks,经过权衡,我们发现kvrocks的整体框架和代码比较好把握,我们还是决定基于kvrocks做二次开发。
为什么要二次开发呢?因为面向客户端的协议pika/kvrocks可以达到90%以上的Redis兼容,但复制协议都不兼容,究其原因在于,无论pika还是kvrocks,其底层的存储引擎都是rocksdb,而rocksdb是基于磁盘的KV存储方案,数据已经落盘成文件的无需再像Redis那样复制时将Master内存的数据保存到文件中再发送到slave端,直接传输文件更高效。为了让业务和中间件少改动,我们基于kvrocks进行二次开发,用来支持Redis的SYNC/PSYNC协议,也就等于支持了xpipe,最终的同步模式也就如图2所示。
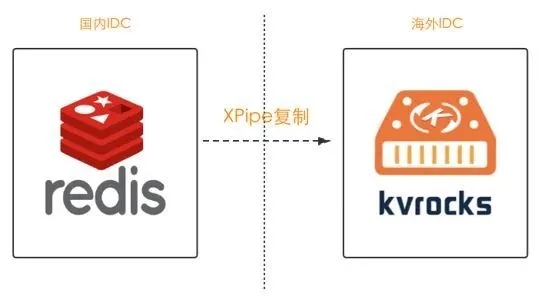
图2
三、二次开发
二次开发前,必须厘清,一个kvrocks实例要成为一个Redis的slave,有以下几个步骤:
执行slaveof后的Redis slave状态机模拟,如下图3所示。
对于全量同步的逻辑,也就是图三中的REPL_STATE_TRANSFER状态,会接受来自master的RDB文件,接受完成后,需要解析RDB。
完成RDB文件解析后,模仿正常客户端命令写入Rocksdb中。
进入CommandPropogate阶段后,死循环接受Master传来的增量命令,每一秒ACK一次当前的offset。

图3
此外,还需要区分kvrocks复制kvrocks和kvrocks复制Redis,得益于kvrocks良好的代码风格,其Replication模块已经实现了一个kvrocks复制kvrocks的状态机,其中psync_steps_和fullsync_steps_表示kvrocks复制kvrocks的增量同步和全量同步,这样我们的思路就很清晰了:
1)将目前的slaveof的语义改为复制Redis,并将kvrocks自身的复制重命名为kslaveof,这样在输入端,我们就知道客户端需要执行的是复制kvrocks还是复制Redis,当然为了对哨兵透明,也可以统一slaveof,而在slaveof后续步骤出错时根据返回值来判断是否回退到起始状态,执行另外一种复制逻辑。
2)kvrocks的server类添加Redis复制的一些特有标识,比如repl_offset,repl_id等,并添加一个字段slave_mode来区分当前是作为Redis/kvrocks的slave。
3)Replication复制类添加一个类似的状态机redis_steps_,在此状态机中完成上面图3状态切换的函数封装。最终简化成以下的逻辑:

图4
完成了上面的流程,我们就获得了一个同步Redis的kvrocks slave,解析master传播过来的RDB文件,对于每个key,遍历其是否过期,然后根据类型 (string,hash,set,zset) 选择对应的插入命令,将其导入到rocksdb中。RDB 解析完成后,会进入Command Propogate阶段,而对于PSYNC的支持,只需要保存master的repli_id和offset,在传送RDB之前根据master返回是否是+CONTINUE来区分是增量同步还是全量同步。
如果是增量则直接进入Command Propogate阶段,此时只需要循环接受master传过来的命令,累加repl_offset,并每一秒ack一次当前的repl_offset,kvrocks就可以一直online并且对外提供服务,而对于master/客户端/中间件来说,它跟真正的Redis无任何差别。
除了上面的这些步骤外,为了监控需要,我们完善了一些Redis上支持的,但kvrocks暂时还没支持或无法支持的命令或统计信息,如role,instantaneous_ops_per_sec等,这里就不再一一赘述。
我们经过将近100个版本和线上2个月的生产测试,总结的数据主要分为以下几个方面(除了从master同步的命令外,面向客户端的基本都是读操作,大部分操作为hget/get, value<1024byte,单个实例QPS<20K):
kvrocks和普通Redis的区别。
线程数和响应时间的关系。
kvrocks跑在傲腾SSD和普通SSD上的区别。
kvrocks适用场景。
成本节约多少?
1)kvrocks VS Redis

图5
从图5上我们可以看到,基于SSD的kvrocks和基于内存的Redis性能没有明显差别,而且这是基于rocksdb的配置比较低的情况(4线程处理client命令,1线程复制,metadata/subkey的block_cache_size为128M,write_buffer_size 64M,wal_size 2G)。
2)线程数和响应时间

图6
我们固定其他参数,只开放处理client命令的线程,图6中是4线程和1线程的对比,从图上来看,这个差距还是比较明显的,但是否线程数越多越好?也不是,如图7所示,4线程和8线程的平均响应时间无任何差别,因此实际上线上版本我们固定为4线程处理client命令。

图7
3)傲腾SSD VS 普通SSD
我们除了在普通SSD上测试,还测试了傲腾SSD的场景,这种情况下,傲腾SSD是用来当硬盘而不是当内存用。从结果来看,傲腾SSD相比普通SSD的优势是全方位的领先,首先用redis-benchmark来测试SET的性能,傲腾的100%响应时间约为普通SSD的1/3(图8,9),而QPS却是3倍(图10,11)。

图8

图9

图10

图11
kvrock的实际场景也证实了压测的数据(图12),延迟和抖动方面傲腾SSD有明显的优势。
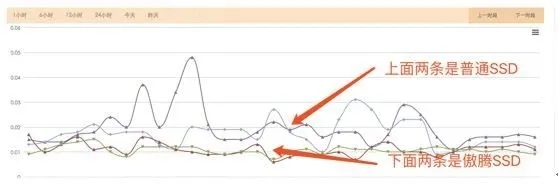
图12
四线程的kvrocks跑在傲腾上甚至比Redis的性能更要好,这点也比较出乎我们的意料,如图13所示:

图13
随着下半年PCI-4.0的傲腾量产和kvrocks自身固有的落盘优势,重启实例不会丢失数据和全量同步,完全可以畅想下kvrocks未来在傲腾上的应用场景。
4)kvrocks适用场景
上面这些数据说明了kvrocks代替Redis的可行性,但并不是所有场景都合适,主要原因在于rocksdb自身的一些限制,这里可以认为是将Redis的内存密集型转换成了CPU/IO密集型,尤其是CPU(图14,15),在写入量大的情况下相比Redis有7-8倍的提升。
这主要是由于rocksdb为了防止空间放大和读放大,定时会compaction,而写入的越频繁,compaction也就越频繁并且单次compaction的CPU就越高,所以就形成了图15这种脉冲式的波峰。

图14
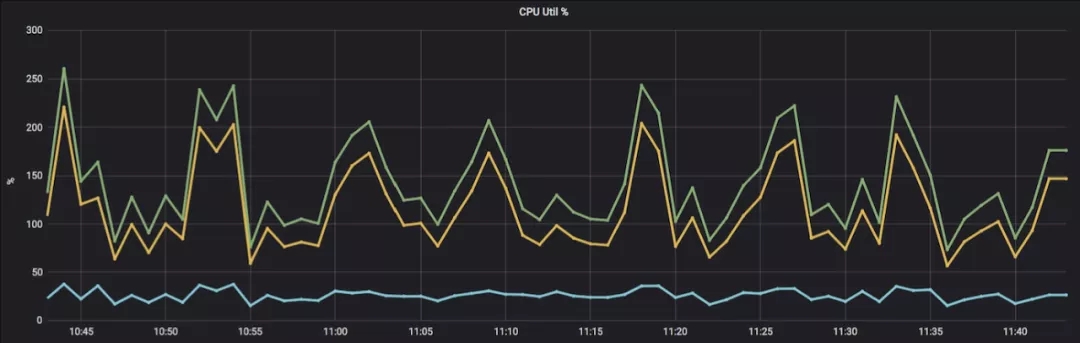
图15
从我们测试的经验来看,单个实例QPS<1万情况下,用kvrocks替换Redis是比较合适的,如果QPS过高,会导致CPU过高,我们甚至无法选择到合适的宿主机来存放这种类型的实例,因为这时候CPU内存的配比是2:1或者更高的关系。
5)成本能节约多少
这实际上需要在CPU/内存/磁盘中做各种tradeoff,我们需要在保证响应延迟的情况下尽可能地降低CPU/内存的使用率。以我们线上某实际的集群为例,经过rocksdb各种参数调整后,该集群单个Redis实例所用内存为6G,而这些数据全部跑在kvrocks中,大概CPU为100%,内存为1G左右如图16,17所示。
按这样的关系换算我们之前选用的Redis宿主机机型和计划选用的kvrocks宿主机机型,用kvrocks大概能将成本节约63%,并且实例越大,节省越多,整体能节约60-80%的成本。
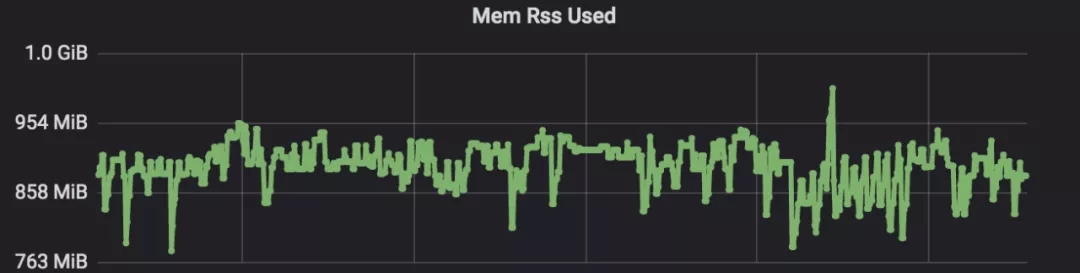
图16
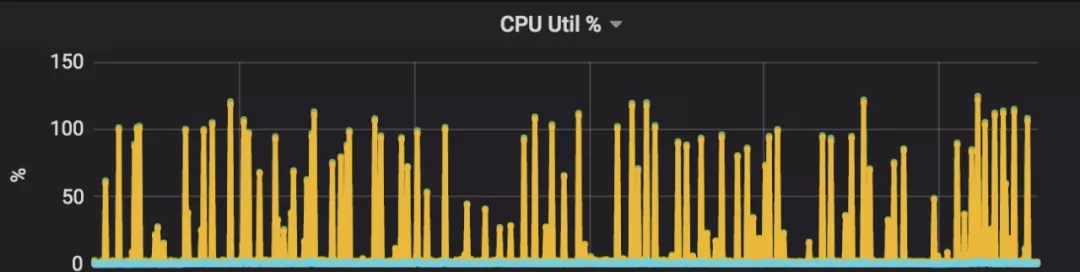
图17
四、一些坑
二次开发过程中,遇到各种奇怪的坑,有些是为了支持Redis复制协议或者跑在容器上才出现的,有些是kvrocks固有的。
1)编译时jemalloc必须指定--with-jemalloc-prefix=je_,否则无法在容器中运行 。
具体可见:https://github.com/bitleak/kvrocks/issues/54
2)在新的CPU机器上编译后无法在老的机器上运行,会报非法指令错误,这个现象在pika上同样存在,考虑都使用了Rocksdb,启用snappy压缩,高度怀疑snappy压缩在高级CPU上采用某些指令集有关。
3)rocksdb在某些虚拟机虚拟出来的文件系统上无法工作,这个现象在pika上同样存在,猜测是跟linux的底层系统调用没有实现有关系(根据pika开发者反馈是access系统调用),切换到xfs文件系统解决。
具体可见:https://github.com/bitleak/kvrocks/issues/56
4)对于setbit操作,Redis认为value是个string,但kvrocks认为是个bitmap,所以如果一个setbit操作的string在全量同步阶段被同步到kvrocks中,再有命令传播的setbit/getbit操作的话,kvrocks会报类型不匹配的错误,该问题已经提交给官方,官方会试图将这两种类型统一。
而作为暂时的解决方案,setbit操作的key加上指定的前缀比如"bit_" ,这样程序就认识到此string为bitmap类型,而选择对应的数据导入方式,而如果kvrocks复制kvrocks的话则不会有这种问题。
5)兼容Redis的时发现有个断错误,多抓取core文件发现是二次开发的代码导致,多线程访问了libevent的同一个evbuffer(图18),同时读写操作同一个evbuffer会导致无法预期的错误,解决方法是evbuffer加锁。

图18
6)kvrocks pub/sub方面的一个死锁,堆栈如图19,提给官方后很快修复。
具体可见:https://github.com/bitleak/kvrocks/issues/68
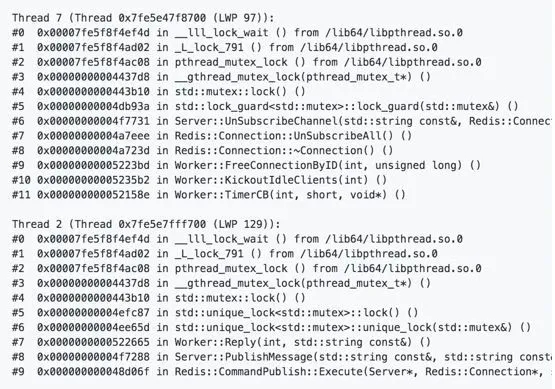
图19
五、未来展望
目前我们已经将公有云上50%+的实例都替换成为了kvrocks,未来我们计划将公有云上所有可以替换的Redis都替换成kvrocks来降低成本,除此之外,支持Redis slaveof kvrocks,之后再考虑开源。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721