
一、Redis内存数据结构与编码
想要弄清楚Redis内部如何支持5种数据类型,也就是要弄清Redis到底是使用什么样的数据结构来存储、查找我们设置在内存中的数据。
虽然我们使用5种数据类型来缓存数据,但是Redis会根据我们存储数据的不同而选用不同的数据结构和编码。
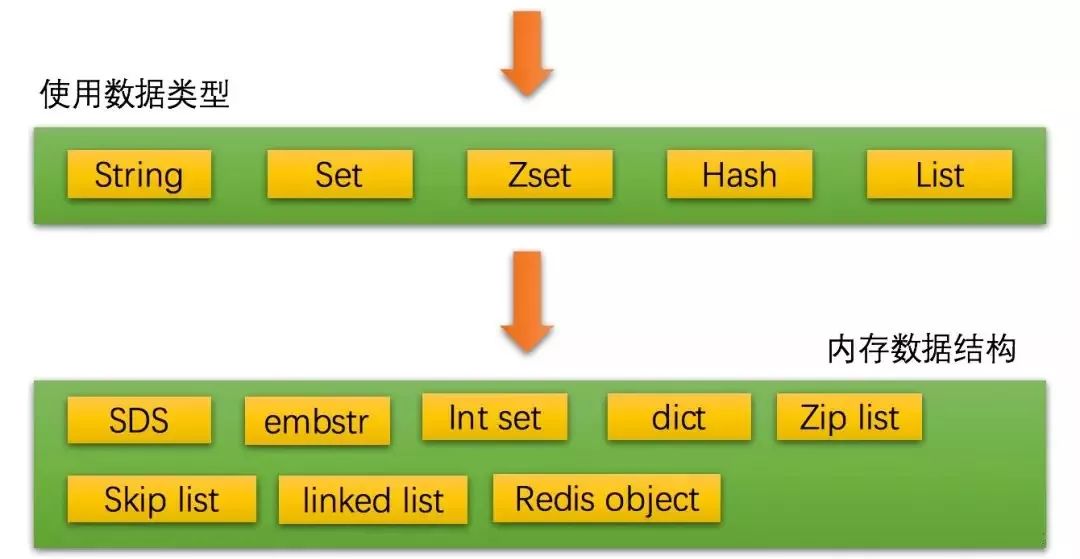
这些数据类型在内存中的数据结构和编码有很多种,随着我们存储的数据类型的不同、数据量的大小不同都会引起内存数据结构的动态调整。
本文只是做数据结构和编码的一般性介绍,不做过多细节讨论,一方面是关于Redis源码分析的资料网上有很多,还有一个原因就是Redis每一个版本的实现有很大差异,一旦展开细节讨论,每一个点每一个数据结构都会很复杂,所以我们这里就不展开讨论这些,只是起到抛砖引玉作用。
1、OBJECT encoding key、DEBUG OBJECT key
我们知道使用type命令可以查看某个key是否是5种数据类型之一,但是当我们想查看某个key底层是使用哪种数据结构和编码来存储的时候,可以使用OBJECT encoding命令。

同样一个key,由于我们设置的值不同,Redis选用了不同的内存数据结构和编码。虽然Redis提供String数据类型,但是Redis会自动识别我们cache的数据类型是int还是String。
如果我们设置的是字符串,且这个字符串长度不大于39字节,那么将使用embstr来编码;如果大于39字节将使用raw来编码。Redis4.0将这个阀值扩大了45个字节。
除了使用OBJECT encoding命令外,我们还可以使用DEBUG OBJECT命令来查看更多详细信息。

DEBUG OBJECT能看到这个对象的refcount引用计数、serializedlength长度、lru_seconds_idle时间,这些信息决定了这个key缓存清除策略。
2、简单动态字符串(simple dynamic String)
简单动态字符串简称SDS,在Redis中所有涉及到字符串的地方都是使用SDS实现,当然这里不包括字面量。SDS与传统C字符串的区别就是SDS是结构化的,它可以高效的处理分配、回收、长度计算等问题。
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
这是Redis3.0版本的sds.h头文件定义,3.0.0之后变化比较大。len表示字符串长度,free表示空间长度,buf数组表示字符串。
SDS有很多优点,比如,获取长度的时间复杂度O(1),不需要遍历所有charbuf[]组数,直接返回len值。
static inline size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
当然还有空间分配检查、空间预分配、空间惰性释放等,这些都是SDS结构化字符串带来的强大的扩展能力。
3、链表(linked list)
链表数据结构我们是比较熟悉的,最大的特点就是节点的增、删非常灵活。Redis List数据类型底层就是基于链表来实现。这是Redis3.0实现。
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
在Redis3.2.0版本的时候引入了quicklist链表结构,结合了linkedlist和ziplist的优势。
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
quicklist提供了灵活性同时也兼顾了ziplist的压缩能力,quicklist->encoding指定了两种压缩算法。quickList->compress表示我们可以进行quicklist node的深度压缩能力。Redis提供了两个有关于压缩的配置:
List-max-zipList-size:zipList长度控制;
List-compress-depth:控制链表两端节点的压缩个数,越是靠近两端的节点被访问的机率越大,所以可以将访问机率大的节点不压缩,其他节点进行压缩。
对比Redis3.2的quicklist与Redis3.0,很明显quicklist提供了更加丰富的压缩功能。Redis3.0的版本是每个listnode直接缓存值,而quicklistnode还有强大的有关于压缩能力。
LPUSH list:products:mall 100 200 300
(integer) 3
OBJECT encoding list:products:mall
"quicklist"
4、字典(dict)
dict字典是基于Hash算法来实现,是Hash数据类型的底层存储数据结构。我们来看下Redis3.0.0版本的dict.h头文件定义:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
int iterators;
} dict;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
说到Hash table有两个东西是我们经常会碰到的,首先就是Hash碰撞问题,Redis dict是采用链地址法来解决,dictEntry->next就是指向下个冲突key的节点。
还有一个经常碰到的就是rehash的问题,提到rehash我们还是有点担心性能的。那么Redis实现是非常巧妙的,采用惰性渐进式rehash算法。
在dict struct里有一个ht[2]组数,还有一个rehashidx索引。Redis进行rehash的大致算法是这样的:
首先会开辟一个新的dictht空间,放在ht[2]索引上,此时将rehashidx设置为0,表示开始进入rehash阶段,这个阶段可能会持续很长时间,rehashidx表示dictEntry个数。每次当有对某个ht[1]索引中的key进行访问时,获取、删除、更新,Redis都会将当前dictEntry索引中的所有key rehash到ht[2]字典中。一旦rehashidx=-1表示rehash结束。
5、跳表(skip list)
skip list是Zset的底层数据结构,有着高性能的查找排序能力。
我们都知道一般用来实现带有排序的查找都是用Tree实现,不管是各种变体的B Tree还是B+Tree,本质都是用来做顺序查找。
skip list实现起来简单,性能也与B Tree相接近。
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplistNode->zskiplistLevel->span这个值记录了当前节点距离下个节点的跨度。每一个节点会有最大不超过zskiplist->level节点个数,分别用来表示不同跨度与节点的距离。
每个节点会有多个forward向前指针,只有一个backward指针。每个节点会有对象__*obj__和score分值,每个分值都会按照顺序排列。
6、整数集合(int set)
int set整数集合是set数据类型的底层实现数据结构,它的特点和使用场景很明显,只要我们使用的集合都是整数且在一定的范围之内,都会使用整数集合编码。
SADD set:userid 100 200 300
(integer) 3
OBJECT encoding set:userid
"intset"
int set使用一块连续的内存来存储集合数据,它是数组结构不是链表结构。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
intset->encoding用来确定contents[]是什么类型的整数编码,以下三种值之一:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
Redis会根据我们设置的值类型动态sizeof出一个对应的空间大小。如果我们集合原来是int16,然后往集合里添加了int32整数将触发升级,一旦升级成功不会触发降级操作。
7、压缩表(zip list)
zip list压缩表是List、Zset、Hash数据类型的底层数据结构之一。它是为了节省内存通过压缩数据存储在一块连续的内存空间中。
typedef struct zlentry {
unsigned int prevrawlensize, prevrawlen;
unsigned int lensize, len;
unsigned int headersize;
unsigned char encoding;
unsigned char *p;
} zlentry;
它最大的优点就是压缩空间,空间利用率很高。缺点就是一旦出现更新可能就是连锁更新,因为数据在内容空间中都是连续的,最极端情况下就是可能出现顺序连锁扩张。
压缩列表会由多个zlentry节点组成,每一个zlentry记录上一个节点长度和大小,当前节点长度lensize和大小len包括编码encoding。
这取决于业务场景,Redis提供了一组配置,专门用来针对不同的场景进行阈值控制:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
上述配置分别用来配置ziplist作为Hash、List、Zset数据类型的底层压缩阈值控制。
8、Redis Object类型与映射
Redis内部每一种数据类型都是对象化的,也就是我们所说的5种数据类型其实内部都会对应到Redis Object对象,然后再由Redis Object来包装具体的存储数据结构和编码。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS;
int refcount;
void *ptr;
} robj;
这是一个很OO的设计,redisObject->type是5种数据类型之一,redisObject->encoding是这个数据类型所使用的数据结构和编码。
我们看下Redis提供的5种数据类型与每一种数据类型对应的存储数据结构和编码。
/* Object types */
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
#define REDIS_ENCODING_RAW 0
#define REDIS_ENCODING_INT 1
#define REDIS_ENCODING_HT 2
#define REDIS_ENCODING_ZIPMAP 3
#define REDIS_ENCODING_LINKEDLIST 4
#define REDIS_ENCODING_ZIPLIST 5
#define REDIS_ENCODING_INTSET 6
#define REDIS_ENCODING_SKIPLIST 7
#define REDIS_ENCODING_EMBSTR 8
REDIS_ENCODING_ZIPMAP 3这个编码可以忽略了,在特定的情况下有性能问题,在Redis 2.6版本之后已经废弃,为了兼容性保留。
图是Redis 5种数据类型与底层数据结构和编码的对应关系:
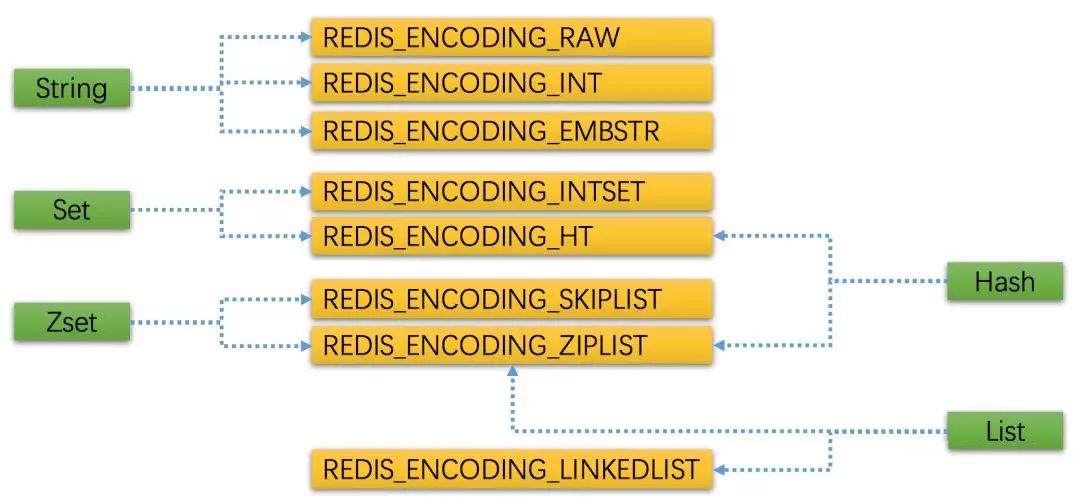
但是这种对应关系在每一个版本中都会有可能发生变化,这也是Redis Object的灵活性所在,有着OO的这种多态性。
redisObject->refcount表示当前对象的引用计数,在Redis内部为了节省内存采用了共享对象的方法,当某个对象被引用的时候这个refcount会加1,释放的时候会减1。
redisObject->lru表示当前对象的空转时长,也就是idle time,这个时间会是Redis lru算法用来释放对象的时间依据。可以通过OBJECT idletime命令查看某个key的空转时长lru时间。
二、Redis内存管理策略
Redis在服务端分别为不同的db index维护一个dict,这个dict称为key space键空间。每一个RedisClient只能属于一个db index,在Redis服务端会维护每一个链接的RedisClient。
typedef struct redisClient {
uint64_t id;
int fd;
redisDb *db;
} redisClient;
在服务端每一个Redis客户端都会有一个指向redisDb的指针。
typedef struct redisDb {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
struct evictionPoolEntry *eviction_pool;
int id;
long long avg_ttl;
} redisDb;
key space键空间就是这里的redisDb->dict。redisDb->expires是维护所有键空间的每一个key的过期时间。
1、键过期时间、生存时间
对于一个key我们可以设置它多少秒、毫秒之后过期,也可以设置它在某个具体的时间点过期,后者是一个时间戳。例如:
EXPIRE命令可以设置某个key多少秒之后过期;
PEXPIRE命令可以设置某个key多少毫秒之后过期;
EXPIREAT命令可以设置某个key在多少秒时间戳之后过期;
PEXPIREAT命令可以设置某个key在多少毫秒时间戳之后过期;
PERSIST命令可以移除键的过期时间。
其实上述命令最终都会被转换成对PEXPIREAT命令。在redisDb->expires指向的key字典中维护着一个到期的毫秒时间戳。
TTL、PTTL可以通过这两个命令查看某个key的过期秒、毫秒数。
Redis内部有一个事件循环,这个事件循环会检查键的过期时间是否小于当前时间,如果小于则会删除这个键。
2、过期键删除策略
在使用Redis的时候我们最关心的就是键是如何被删除的,如何高效准时地删除某个键。其实Redis提供了两个方案来完成这件事情:惰性删除、定期删除双重删除策略。
惰性删除:当我们访问某个key的时候,Redis会检查它是否过期。
robj *lookupKeyRead(redisDb *db, robj *key) {
robj *val;
expireIfNeeded(db,key);
val = lookupKey(db,key);
if (val == NULL)
server.stat_keyspace_misses++;
else
server.stat_keyspace_hits++;
return val;
}
int expireIfNeeded(redisDb *db, robj *key) {
mstime_t when = getExpire(db,key);
mstime_t now;
if (when < 0) return 0; /* No expire for this key */
if (server.loading) return 0;
now = server.lua_caller ? server.lua_time_start : mstime();
if (server.masterhost != NULL) return now > when;
/* Return when this key has not expired */
if (now <= when) return 0;
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_EXPIRED,"expired",key,db->id);
return dbDelete(db,key);
}
定期删除:Redis通过事件循环,周期性地执行key的过期删除动作。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* Handle background operations on Redis databases. */
databasesCron();
}
void databasesCron(void) {
/* Expire keys by random sampling. Not required for slaves
* as master will synthesize DELs for us. */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
}
要注意的是:
惰性删除是每次只要有读取、写入都会触发惰性删除代码;
定期删除是由Redis EventLoop来触发的。Redis内部很多维护性工作都是基于EventLoop。
3、AOF、RDB处理过期键策略
既然键会随时存在过期问题,那么涉及到持久化Redis是如何帮我们处理的?
当Redis使用RDB方式持久化时,每次持久化的时候就会检查这些即将被持久化的key是否已经过期,如果过期将直接忽略,持久化那些没有过期的键。
当Redis作为master主服务器启动的时候,载入rdb持久化键时也会检查这些键是否过期,将忽略过期的键,只载入没过期的键。
当Redis使用AOF方式持久化时,每次遇到过期的key Redis会追加一条DEL命令到AOF文件,也就是说只要我们顺序载入执行AOF命令文件就会删除过期的键。
如果Redis作为从服务器启动的话,它一旦与master主服务器建立链接就会清空所有数据进行完整同步。当然新版本的Redis支持SYCN2的半同步,如果是已经建立了master/slave主从同步之后,主服务器会发送DEL命令给所有从服务器执行删除操作。
4、Redis LRU算法
在使用Redis的时候我们会设置maxmemory选项,64位的默认是0不限制。线上的服务器必须要设置的,要不然很有可能导致Redis宿主服务器直接内存耗尽,最后链接都上不去。
所以基本要设置两个配置:
maxmemory最大内存阈值;
maxmemory-policy到达阈值的执行策略。
可以通过CONFIG GET maxmemory/maxmemory-policy分别查看这两个配置值,也可以通过CONFIG SET去分别配置。
maxmemory-policy有一组配置,可以用在很多场景下:
noeviction:客户端尝试执行会让更多内存被使用的命令直接报错;
allkeys-lru:在所有key里执行lru算法;
volatile-lru:在所有已经过期的key里执行lru算法;
allkeys-random:在所有key里随机回收;
volatile-random:在已经过期的key里随机回收;
volatile-ttl:回收已经过期的key,并且优先回收存活时间(TTL)较短的键。
关于cache的命中率可以通过info命令查看键空间的命中率和未命中率。
# Stats
keyspace_hits:33
keyspace_misses:5
maxmemory在到达阈值的时候会采用一定的策略去释放内存,这些策略我们可以根据自己的业务场景来选择,默认是noeviction 。
Redis LRU算法有一个取样的优化机制,可以通过一定的取样因子来加强回收的key的准确度。CONFIG GET maxmemory-samples查看取样配置,具体可以参考更加详细的文章。
三、Redis持久化方式
Redis本身提供持久化功能,有两种持久化机制,一种是数据持久化RDB,一种是命令持久化AOF,这两种持久化方式各有优缺点,也可以组合使用。一旦组合使用,Redis在载入数据的时候会优先载入aof文件,只有当AOF持久化关闭的时候才会载入rdb文件。
1、RDB(Redis DataBase)
RDB是Redis数据库,Redis会根据一个配置来触发持久化:
#save
save 900 1
save 300 10
save 60 10000
CONFIG GET save
1) "save"
2) "3600 1 300 100 60 10000"
表示在多少秒之类的变化次数,一旦达到这个触发条件Redis将触发持久化动作。
Redis在执行持久化的时候有两种模式BGSAVE、SAVE:
BGSAVE是后台保存,Redis会fork出一个子进程来处理持久化,不会block用户的执行请求;
SAVE则会block用户执行请求。
struct redisServer {
long long dirty;/* Changes to DB from the last save */
time_t lastsave; /* Unix time of last successful save */
long long dirty_before_bgsave;
pid_t rdb_child_pid;/* PID of RDB saving child */
struct saveparam *saveparams; /* Save points array for RDB */
}
struct saveparam {
time_t seconds;
int changes;
};
RedisServer包含的信息很多,其中就包含了有关于RDB持久化的信息。
redisServer->dirty至上次save到目前为止的change数。redisServer->lastsave上次save时间。
saveparam struct保存了我们通过save命令设置的参数,time_t是个long时间戳。
typedef __darwin_time_t time_t;
typedef long __darwin_time_t; /* time() */
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
REDIS_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == REDIS_OK))
{
redisLog(REDIS_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveBackground(server.rdb_filename);
break;
}
}
}
Redis事件循环会周期性的执行serverCron方法,这段代码会循环遍历server.saveparams参数链表。
如果server.dirty大于等于我们参数里配置的变化并且server.unixtime-server.lastsave大于参数里配置的时间,并且server.unixtime-server.lastbgsave_try减去bgsave重试延迟时间,或者当前server.lastbgsave_status== REDIS_OK则执行rdbSaveBackground方法。
2、AOF(Append-only file)
AOF持久化是采用对文件进行追加对方式进行,每次追加都是Redis处理的命令。有点类似command sourcing命令溯源的模式,只要我们可以将所有的命令按照执行顺序在重放一遍就可以还原最终的Redis内存状态。
AOF持久化最大的优势是可以缩短数据丢失的间隔,做到秒级的丢失率。RDB会丢失上一个保存周期到目前的所有数据,只要没有触发save命令设置的save seconds changes阈值数据就会一直不被持久化。
struct redisServer {
/* AOF buffer, written before entering the event loop */
sds aof_buf;
}
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
aof_buf是命令缓存区,采用sds结构缓存,每次当有命令被执行当时候都会写一次到aof_buf中。有几个配置用来控制AOF持久化的机制。
appendonly no
appendfilename "appendonly.aof"
appendonly用来控制是否开启AOF持久化,appendfilename用来设置aof文件名。
appendfsync always
appendfsync everysec
appendfsync no
appendfsync用来控制命令刷盘机制。现在操作系统都有文件cache/buffer的概念,所有的写入和读取都会走cache/buffer,并不会每次都同步刷盘,因为这样性能一定会受影响。所以Redis也提供了这个选项让我们来自己根据业务场景控制。
always:每次将aof_buf命令写入aof文件并且执行实时刷盘。
everysec:每次将aof_buf命令写入aof文件,但是每隔一秒执行一次刷盘。
no:每次将aof_buf命令写入aof文件不执行刷盘,由操作系统来自行控制。
AOF也是采用后台子进程的方式进行,与主进程共享数据空间也就是aof_buf,但是只要开始了AOF子进程之后Redis事件循环文件事件处理器会将之后的命令写入另外一个aof_buf,这样就可以做到平滑的切换。
AOF会不断的追加命令进aof文件,随着时间和并发量的加大aof文件会极速膨胀,所以有必要对这个文件大小进行优化。Redis基于rewrite重写对文件进行压缩。
no-appendfsync-on-rewrite no/yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
no-appendfsync-on-rewrite控制是否在bgrewriteaof的时候还需要进行命令追加,如果追加可能会出现磁盘IO跑高现象。
上面说过,当AOF进程在执行的时候原来的事件循环还会正常的追加命令进aof文件,同时还会追加命令进另外一个aof_buf,用来做新aof文件的重写。这是两条并行的动作,如果我们设置成yes就不追加原来的aof_buf 因为新的aof文件已经包含了之后进来的命令。
auto-aof-rewrite-percentage和auto-aof-rewrite-min -size64mb这两个配置前者是文件增长百分比来进行rewrite,后者是按照文件大小增长进行rewrite。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721