
译者介绍:张冬洪,Redis中国用户组主席
刚刚结束的RedisConf2017大会,在国外是比较大型的Redis盛会了,而且已经举办多年,每次都会在全球邀请业界知名公司的技术大咖分享他们在企业应用中的典型案例和踩过的坑,以及他们正在积极探索的新的技术实现或扩展。
今年就有许多好玩的新玩意比较吸引我,比如Redisearch、Redis-ML和Amazon ElastiCache for Redis等。我们都知道,如今CI/CD和AI非常火爆,前段时间亚马逊发表了一篇关于用机器学习自动优化数据库的博客轰动一时(详情戳此看社群文章《DBA要失业了?看ML如何自动优化数据库》),我们感叹的不仅仅是DBA要失业(joke),还是技术更新太快,日新月异。那么在Redis领域是否也能用机器学习来帮助做一些更高级的事情呢?答案不言而喻,是肯定的。在本次大会上来自Redislabs的Shay Nativ大神就分享了“用Redis-ML模块来实现实时机器学习”的案例, 主要内容如下:
Redis主要区别
(1)高性能

(2)简单-多种数据结构
(3)可扩展-Redis Modules

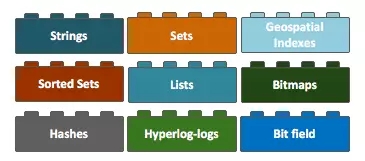
Redis主要的数据结构概括

Redis Modules:一种革命的方式
任何C/C++程序现在都可以运行在Redis上
Modules是用一种本地的方式来扩展Redis的新用例和功能
使用现有的或者添加新的数据结构
享受简单,无限可扩展性和高可用性的同时保持着redis的本机的速度
可以由任何人创建
Adapt your database to your data, not the other way around

Redis-ML:机器学习模型服务器
(1)机器学习的世界
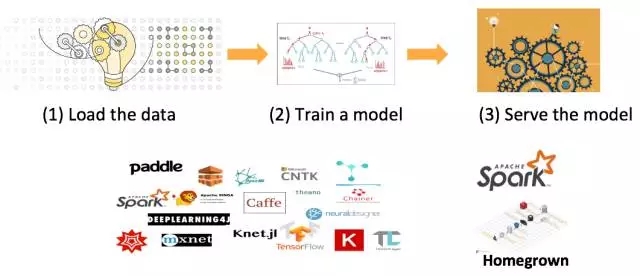
(2)传统的基于Spark-ML机器学习的生命周期
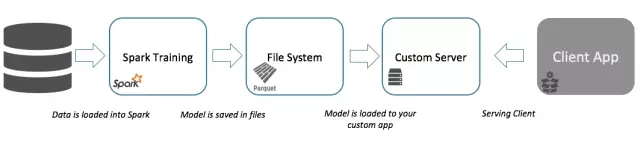
(3)基于ML模型的服务挑战
ML变得非常流行,但是Models却变得很大,很复杂
需要以更快的速度去分发/部署它们
速度和大小方面不能很好的扩展,需要保持他们在集群中的一致性以及使得他们持久化
可靠的服务很难做到 – 需要确保服务的可靠性
比较昂贵 – 需要投入更多的硬件资源和人力成本
一个简单的基于Redis-ML的机器学习生命周期

Redis-ML:ML服务引擎
以“热模式”存储机器训练输出
直接在Redis中进行评估
轻松整合现有的C/C++ ML lib库
可以在运行过程中进行调整
享有Redis的高性能,可扩展性和HA
ML Modules
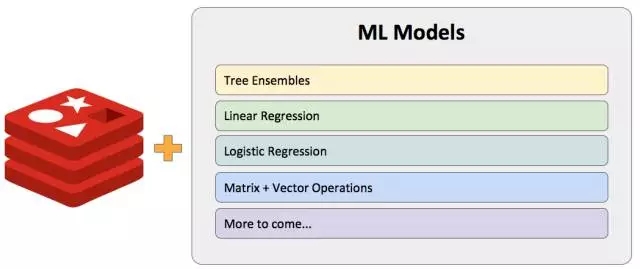
随机森林模型
一个决策树集合
支持分类和回归
分离节点
按类别(例如:day == “sunday”)
按数值(例如:age < 43)
决策是由大多数决策树所决定的
Gini impurity:基尼不纯度准则
【充电】在实际训练中, 需要根据不同的需求选择适当的损失函数是必须的,损失函数的形式即是我们选择最优分支函数的优化目标。损失函数形式设定分为两类:分类树损失函数和回归树损失函数,其中分类树损失函数又分为4种准测:基尼不纯度准则、信息熵准则、对数价值准则和经过Kass调整的对数价值准则;回归树损失函数分为方差的最大似然估计准则、绝对偏差准则和分支规则的F检验准则。
公式
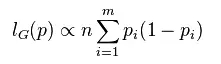
按其定义式所表达的,它的含义是“任意取两个观测其属于不同类的概率”。

在分支时的基尼不纯度公式改进为:
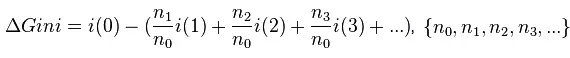
分别为当前节点与其分支节点的观测数;基尼不纯度改进越大,说明分支后各个子节点任取两个观测数与不同类的概率越低。
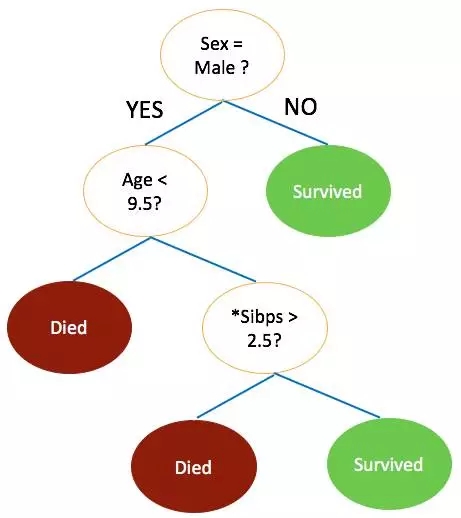
在一个决策树上的泰坦尼克号的生存预测
在一个随机森林上的泰坦尼克号的生存预测

举一个例子:John的特征是:
{male, 34, married + 2, US, CA, 1.78m, 78kg, 110iq, blue eyes}
那么根据上面的随机森林的计算,John会生存下来吗?
Tree#1 - Survived
Tree#2 - Died
Tree#3 - Survived
结果:根据随机森林决策是Survived。
真实世界的挑战
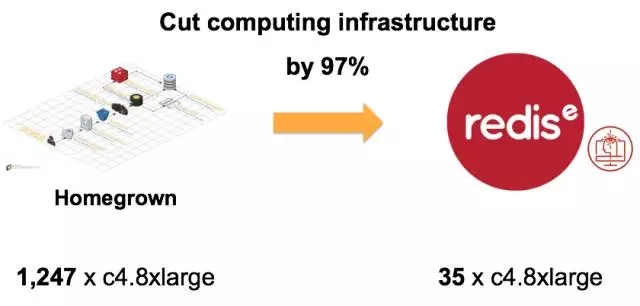
广告服务的公司需要在数据中心50ms的延迟的条件下完成每秒20000次广告服务。运行1000次活动需要1000个随机森林,每一个森林有15000棵决策树,平均每一棵树的深度有7层。可以想象计算量是很庞大的。针对这个案例,广告模型服务在基于Homegrown和Redis-ML的机器学习计算中的比较:

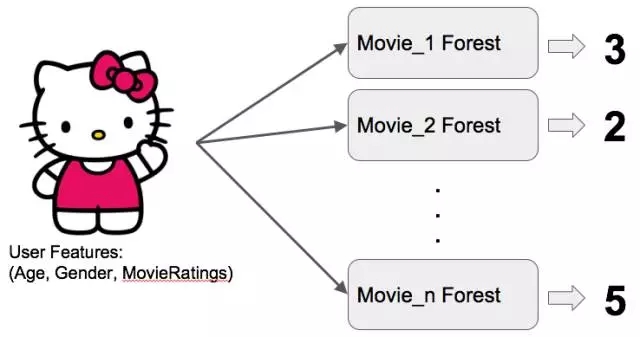
真实世界的一个案例:电影推荐系统
(1)概述

(2)用到的工具集

(3)Docker中运行Redis-ML 和spark-redis-ml
# docker pull shaynativ/redis-ml
# docker run --net=host shaynativ/redis-ml
# docker pull shaynativ/spark-redis-ml
# docker run --net=host shaynativ/spark-redis-ml
(4)一棵森林对应一个电影
数据处理的过程分为以下几步:
(1)获取数据
下载和提取数据:MovieLens 100K Dataset,数据内容格式大致如下:
Ratings: user id | item id | rating (1-5) | timestamp
Item (movie) info: movie id | genre info fields (1/0)
User info: user id | age | gender | occupation
我们的分类器应该返回用户给出的一个考虑之中的电影的期望等级(从1到5)。
(2)转换格式
对每部电影的训练数据应该包含每个用户一行数据,如:
class (rating from 1 to 5 the user gave to this movie)
user info (age, gender, occupation)
user ratings of other movies (movie_id:rating ...)
user genre rating averages (genre:avg_score ...)
运行gen_data.py来转换文件所需要的格式。
(3)训练和加载数据到Redis中
// Create a new forest instance
val rf = new
RandomForestClassifier().setFeatureSubsetStrategy("auto").setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setNumTrees(500)
…..
// Train model
val model = pipeline.fit(trainingData)
…..
val rfModel =
model.stages(2).asInstanceOf[RandomForestClassificationModel]
// Load the model to redis
val f = new Forest(rfModel.trees)
f.loadToRedis(”movie-10", "127.0.0.1")
(4)在Redis中执行运算

Python例子:
>> import redis
>> config = {"host":"localhost", "port":6379}
>> r = redis.StrictRedis(**config)
>> user_profile = r.get("user_shay_profile")
>> print(user_profile)
12:1.0,13:1.0,14:3.0,15:1.0,17:1.0,18:1.0,19:1.0,20:1.0,23:1.0,24:5.0,1.0,115:1.0,116:2.0,117:2.0,119:1.0,120:4.0,121:2.0,122:2.0,
........
1360:1.0,1361:1.0,1362:1.0, 1701:6.0,1799:435.0,1801:0.2,1802:0.11,1803:0.04,1812:0.04,1813:0.07,1814:0.24,1815:0.09,1816:0.32,1817:0.06
>> r.execute_command("ML.FOREST.RUN", "movie-10", user_profile)
'3'
Redis cli例子:
>> KEYS *
1) "movie-5"
2) "movie-1"
........
8) "movie-6"
9) "movie-4"
10) "movie-10"
11) "user_1_profile”
>> ML.FOREST.RUN movie-10
12:1.0,13:1.0,,332:3.0,333:1.0,334:1.0,335:2.0,336:1.0,357:2.0,358:1.0,359:1.0,362:1.0,367:1.0,368:3.0,369:2.0,404:4.0,405:1.0,406:2.0,407:1.0,408:1.0,409:1.0
........
,410:3.0,411:2.0,412:2.0,423:1.0,454:1.0,455:1.0,456:1.0,457:3.0,458:1.0,459:1.0,470:1”
"3”
性能
Redis time: 0.635129ms, res=3
Spark time: 46.657662ms, res=3.0
---------------------------------------
Redis time: 0.644444ms, res=3
Spark time: 49.028983ms, res=3.0
---------------------------------------
Classification averages:
redis: 0.9401250000000001 ms
spark: 58.01970206666667 ms
ratio: 61.71488053893542
diffs: 0.0
获取实际的推荐的完整脚本classify_user.py


总结

参考资料:
Redis-ML:
Spark-Redis-ML:
Databricks Notebook:
Dockers:
决策树:
作者:redislabs Shay Nativ








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721