
目录:
【大数据生态圈】
Hadoop
Hadoop 3.0.0 Alpha版本发布
Druid
Druid 0.9.2版本发布
Kudu
Apache Kudu 1.1.0正式发布
HAWQ
HAWQ 2.1.0.0企业版正式发布
【Docker发展概况】
官方版本发布情况
国内情况
落地情况
感谢名单
大数据生态圈
一、Hadoop
Hadoop 3.0.0 Alpha版本发布
由于Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,所以Hadoop社区于2016年9月3日发布了全新的基于JDK 1.8的Hadoop 3.0.0 alpha版本。
目前Hadoop 3.0.0仅提供Alpha测试版本,整个系统的稳定性没有保障,所以不推荐在正式的开发系统中使用该版本。
相比于Hadoop2.7.0,3.0.0版本更新的主要变更的官方链接:
http://hadoop.apache.org/docs/r3.0.0-alpha1/index.html
全部变更的官方连接:
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-common/release/3.0.0-alpha1/RELEASENOTES.3.0.0-alpha1.html
我们针对主要的功能点版本进行了翻译,如下:
1、Java的最低版本要求从Java 7改成了Java 8
3.0以后所有的Hadoop JARs都是基于Java 8进行编译的,所有还在使用Java 7或者是更低版本的用户,应该升级到Java 8。
2、HDFS支持纠删码(Erasure Coding、EC)
Erasure coding纠删码技术简称EC,是一种数据保护技术。最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术。他通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性。在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复。
与副本技术相比,纠删码是一种能够显著的节约空间的用于存储持久化数据的方法。进行数据存储的时候,标准编码(比如Reed-Solomon (10,4))有着1.4倍的空间开销,而如果使用HDFS的副本模式已经数据存储的时候,有着3倍的空间开销。由于纠删码在进行重建和远程读的时候会有额外的开销,所以它一般情况下,被用于存储冷的,不经常被访问的数据。用户在使用纠删码这一功能的时候应该要考虑CPU以及网络的额外开销。
关于HDFS的纠删码的更多细节,可以访问官方文档或者Jira:
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
https://issues.apache.org/jira/browse/HDFS-7285
国内也有相关的技术博客文章:
https://www.iteblog.com/archives/1684
3、YARN 时间轴服务V.2
在Hadoop2.4版本之前对任务执行的监控只开发了针对MR的Job History Server,它可以提供给用户用户查询已经运行完成的作业的信息,但是后来,随着在YARN上面集成的越来越多的计算框架,比如spark、Tez,也有必要为基于这些计算引擎的技术开发相应的作业任务监控工具,所以Hadoop的开发人员就考虑开发一款更加通用的Job History Server,即YARN Timeline Server。
3.0版本引入了YARN Timeline Service: v.2,主要用与解决两大挑战:
提高时间轴服务的稳定性和可拓展性。
增强流式和聚合的可用性
更多关于YARN Timeline Service: v.2 可以访问官方文档
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-yarn/hadoop-yarn-site/TimelineServiceV2.html
4、Shell脚本重写
The Hadoop shell scripts have been rewritten to fix many long-standing bugs and include some new features. While an eye has been kept towards compatibility, some changes may break existing installations.
为了修复一些长时间存在的BUG并添加一些新的功能,Hadoop的shell脚本在3.0版本被重新进行了改写。其中绝大部分的脚本能够保证一定的兼容性,但是有些变化还是会是现有的一些配置出现问题。
相关不兼容的变更我们可以查看:
https://issues.apache.org/jira/browse/HADOOP-9902
如果你想了解3.0版本中脚本的更多细节我们可以访问Unux Shell用户指导及API手册:
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-common/UnixShellGuide.html
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-common/UnixShellAPI.html
5、MapReduce任务级别的本地优化
MapReduce 添加了C/C++输出到collector的本地实现(包括了Spill,Sort,和Ifile等),通过作业级别的的参数调整就能够切换到该实现上对于shuffle密集型的作业来说,可以提高30%以上的性能。
更多细节可以查看:
https://issues.apache.org/jira/browse/MAPREDUCE-2841
6、支持两个以上的Namenode
早期版本的HDFS Namenode的高可用提供了一个active状态的Namenode和一个standby状态的Namenode,他们之间通过3个JournalNode应用edit的方式进行同步。在这种架构下,允许两个节点中的任意一个节点失效。有的时候,我们的系统可能需要更要的容错性,这个时候我们就需要3.0的多Namenode的新特性了。它可以允许用户配置多个standby Namenode,如果说,配置说三个Namenode,5个JournalNode,这样这个系统就允许坏两个Namenode了,进一步提高了系统的冗余性。
如何进行配置多个Namenode请查看如下文档:
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
7、多个服务的默认端口的变化
在此之前,很多Hadoop的默认端口都是属于linux的临时端口范围(32768-61000)这意味着我们的服务在启动的时候由于端口已经被其他的服务所占用导致启动的失败。现在这些可能会引起冲突的端口都已经做了变更,不再是在临时端口范围内了,这些端口的变化会影响Namenode、SecondaryNamenode、DataNode和KMS。这些变化,在Jira中都有说明,详见:
https://issues.apache.org/jira/browse/HDFS-9427
https://issues.apache.org/jira/browse/HADOOP-12811
8、支持Microsoft Azure Data Lake filesystem连接器
现在Hadoop支持Microsoft Azure Data Lake filesystem,并可替代作为Hadoop默认的文件系统。
9、Intra-DataNode均衡器
一个datanode可以管理多个磁盘,正常写入,各个磁盘会被均匀写满。然后,后期当重新添加或者替换磁盘的时候,就会导致DataNode内部的数据存储严重倾斜。这种情况下,HDFS的balancer是无法进行处理的。这种情况下,通过调用dfs diskbalancer CLI,可以实现 Intra-DataNode 的动态balance。
更多细节详见:
http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
10、重写守护进程及任务的堆管理
https://issues.apache.org/jira/browse/HADOOP-10950
介绍了配置守护进程Heap大小的新的方法,现在已经可以实现基于主机内存的动态调节,同时HADOOP_HEAPSIZE此参数已经被弃用。
https://issues.apache.org/jira/browse/MAPREDUCE-5785
介绍如何去配置了Map以及Reduce task的heap大小。现在所需的堆大小不在需要通过任务配置或者Java选项来实现,已经指定的配置选项不受变更的影响。
二、Druid
Druid 0.9.2版本发布
Druid是一款开源的分布式分析型数据存储系统,它最大的卖点是实时OLAP,导入即可查询,OLAP查询亚秒级响应,数据量可以扩展到PB级,其高并发以及高可用等特性适合构建面向用户的数据分析产品。
2016年12月1日,Druid发布了0.9.2版本。在这一版本中包含了来自30多位Contributor贡献的100多项性能提升、稳定性提升以及Bug修复。主要的新功能包括新的Group By查询引擎,数据摄入阶段可以关闭Roll-up,支持对Long类型字段的过滤,Long类型字段的新编码方式,HyperUnique和DataSketches的性能提升,基于Caffeine的查询缓存实现,可配置缓存策略的Lookup扩展,支持ORC格式数据的摄入以及增加了标准差和方差的Aggregator(聚合函数)等。
1、新的Group By查询引擎
Druid为了提升性能以及优化内存管理,彻底重写了Group By查询引擎。在官方测试数据源上进行基准测试,有2~5倍的性能提升。新的查询引擎依然支持严格限制内存使用大小,同时增加了在内存耗尽时溢写到磁盘的选项,这样避免对结果集大小的限制以及潜在的内存溢出异常发生。新引擎模式默认是不开启的,你可以通过修改查询上下文中的相应参数开启,在Druid的未来发行版本中将默认采用新的查询引擎。其实现细节,详见http://druid.io/docs/0.9.2/querying/groupbyquery.html#implementation-details。
2、禁用Roll-up的选项
从一开始,Druid在数据摄入阶段以及查询阶段,区分维度和度量值。Druid是唯一仅有的数据库,支持在数据摄入阶段进行聚合,我们把这一行为叫做“Roll-up”。Roll-up可以显著地提升查询性能,但会失去查询原始数据的能力。 禁用Roll-up以后,会将原始数据摄入,但不会影响查询阶段的聚合。Roll-up默认依然是开启的,具体配置详见“http://druid.io/docs/0.9.2/ingestion/index.html ”。
3、对整数类型列的筛选能力
Druid新增了对整数类型列的复杂筛选能力,整数类型列包括long类型的度量值以及特殊的__time(时间)列。以它为基础,将开创一系列新功能:
对时间列的筛选聚合,它对于实现对比两个时间段的查询非常有帮助,例如使用DataSketches实现用户留存。
针对整数类型列进行筛选,特别是禁用Roll-up以后。
4、Long类型字段的新编码方式
直到现在,Druid中Long类型字段,包括Long类型度量值以及特殊的__time列,都是采用64bit 8字节 longs存储,然后使用LZ4按块压缩。Druid0.9.2增加了新的编码方式,它会在很多场景下,减少文件大小以及提升性能。它有如下Long类型编码方式:
auto,会在扫描一遍数据以后,得到其基数以及最大值,选择table或者Delta编码方式,使得存储使用小于64bit存储每一行。
longs,默认的策略,总是使用64bit存储每一行。
新增加了“none”的压缩策略,类似原来的“uncompressed”,摒弃了原来块存储的方式,提升了随机查找的性能。
默认仍然采用“longs”编码方式+“lz4”压缩方式。在官方测试中,产生有效收益的两个选项是 "auto" + "lz4"(通常文件大小会小于longs+lz4)和 "auto" + "none"(通常会比longs+lz4块,但文件大小影响各不相同)。
5、Sketch性能提升
DataSketch性能最多提升80%,HyperUnique性能提升19%~30%。
三、Kudu
Apache Kudu 1.1.0正式发布
Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的新成员之一(incubating),专门为了对快速变化的数据进行快速的分析,是对HDFS与HBase的补充 。
新功能和改进:
Python客户端已经与C ++和Java客户端具有同等特性。
列表谓词。
Java客户端现在具有客户端跟踪功能。
Kudu现在发布用于使用Scala 2.11编译的Spark 2.0的jar文件。
Kudu采用Raft算法实现预选举,在我们的测试中这个功能大大提高了稳定性。
更多内容可以参考链接:
http://kudu.apache.org/2016/11/15/weekly-update.html
四、HAWQ
Apache HAWQ是基于HDFS存储上的MPP引擎,兼备MPP并行数据库的查询处理优势和HDFS存储的可扩展性优势。此外,HAWQ还提供了Madlib数据挖掘工具,提供了对R,Python,Perl的脚本嵌入,使得用户可以方便地开发兼容第三方语言和SQL的软件。
HAWQ 2.1.0.0企业版正式发布
2016年12月,基于Apache HAWQ 2.0 的Pivotal HDB 2.1.0.0企业版正式发布,功能包括:
1、资源管理及弹性查询执行
可动态从YARN申请资源并在负载下降时动态归还。支持查询级别的资源管理,可使用多级资源管理队列分配用户以及查询使用资源。自动对资源进行隔离及强制。
基于virtual segment实现弹性查询执行。基于查询的代价动态分配virtual segment,使其运行在集群部分节点。解决了经典MPP引擎缺点,提高扩展性和查询并行度。
彻底解耦了计算和存储,Segment节点和Master节点。这意味着在集群节点大小变化的时候表不需要重新分布,从而HAWQ可以实现秒级扩容。
新调度器可以动态组合不同节点上的查询执行进程来动态调度和管理查询的执行。
2、存储相关
优化了AO以及Parquet表存储格式,使得一个大文件可以被多个Scanner进程以快级别分割来读。使得HAWQ可以达到优化的查询并行度。
将一个表的所有数据文件存放在HDFS的一个目录中,方便了HAWQ与外部系统的数据交换,比如外部系统可以把数据文件放到该表对应HDFS目录中,实现数据加载。
HAWQ需要HDFS文件块位置信息来实现派遣计算到数据的调度。HDFS在RPC的处理速度上在高并发时往往响应较慢。元数据缓存提升了数据局部性匹配方法的效率。
实现与HCatalog集成。基于PXF对Hive表的访问不需要先创建外部表;支持将Hive中ORC存储格式文件作为外部表进行查询,同时在外部表处理中支持谓词下推和投影下推。
HAWQ Register 能够直接将HDFS文件注册到HAWQ内部表。可被用于:直接注册Hadoop生态系统其他模块生成的parquet存储格式文件; HAWQ集群的迁移。
3、其他功能改进及增强
新版gporca查询优化器包括了许多新功能和大量的错误修正。
基于心跳和动态探测的容错服务,可动态检测到新加节点并且移除失效节点。
用户可以通过一个新的命令“hawq”来完成几乎所有的管理操作,该命令整合了所有的其它子命令。
4、其他模块集成与支持
HDP 2.4.x的版本升级到2.5.0,包括Apache Hadoop从2.7.1 到 2.7.3 升级。
Ambari 2.2.2版本插件现在支持HAWQ 2.0的配置和部署。
HAWQ/PXF插件现在支持自动的Kerberos安全配置。
Docker发展概况
一、官方版本发布情况
Docker从2013年开源。2015年是Docker开源项目突飞猛进的一年,这段时间Docker官方先后发布了V1.5、V1.6、V1.7、V1.8、V1.9等5个大版本以及7个修订版本。
2016年Docker发展同样迅速,截止2016年12月7日Docker官方共发布了V1.10、V1.11、V1.12、V1.13等4个大版本以及8个修订版本。
重大变化主要是V1.12版本,原Swarm项目改为SwarmKit并内置到了Docker引擎中。
详情:https://github.com/docker/docker/releases
二、国内情况
Docker容器技术目前在国内还属于早期阶段。
第一:技术太新,技术人员需要一个接受的过程;
第二:容器技术和虚拟化技术不一样,和企业业务结合还需要进一步磨合。
阿里云和Docker官方合作,Docker公司选择aliyun平台作为Docker Hub在中国运营的基础服务,且阿里获得Docker DataCenter的运营权。
由工信部、中国信息通信研究院联合成立的云计算开源产业联盟(OSCAR),在12月2日,发布了国内第一个“容器技术应用场景”规范,且该规范已立项为中国通信标准协会研究课题。
三、落地情况
国内的企业也有实际落地使用,互联网居多。代表性的列举几个:
互联网行业:京东、微博、知乎、豆瓣、PPTV;etc。
汽车行业:长安汽车、上海汽车;etc。
金融保险:永隆银行、中英人寿、广发证券;etc。
其他:…
感谢名单
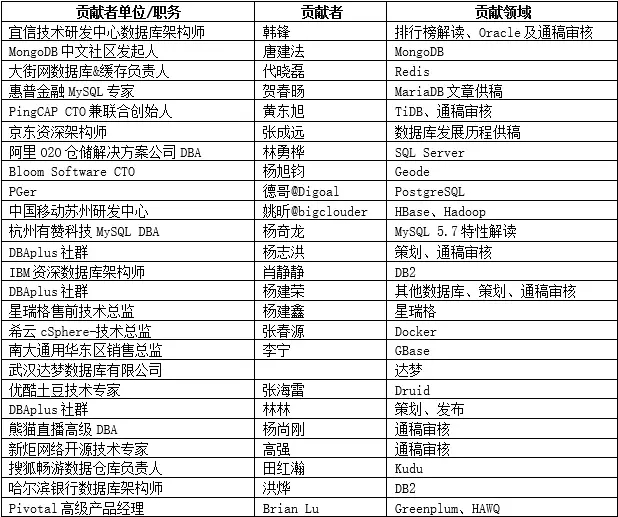
感谢本期提供宝贵信息和建议的专家朋友,排名不分先后。
回复“newsletter”至DBAplus社群订阅号(dbaplus)可下载本期Newsletter完整版
欢迎提供Newsletter信息,发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿,发送至邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721