
数据库技术创新多维度突破
国产势头强劲抢占市场
2024年下半年,数据库行业呈现加速发展态势。随着近些年来的积累,国产数据库发展渐入佳境,步入深水区,在更广泛、更核心的场景投产使用。同时伴随着如国测名单的发布,数据库行业加速洗牌,若干头部厂商呼之欲出。
在技术层面上,AI与数据库融合、多模态数据支持、存算分离与湖仓一体等创新方向有所突破;在产品层面上,性能、兼容性、安全等方面成为各厂商产品发展的重点,具体如下:
AI与数据库融合:数据库产品在AI技术上的增强成为发展重点,不少数据库产品均推出了相关能力。相信未来数据库将更多地与AI技术结合,提升数据分析和处理能力,满足智能化应用需求。
多模态数据支持:随着数据类型日益多样化,数据库对多模态数据的支持需求加大,以向量、图、时序等为代表的非关系型数据正受到更多关注,很多传统关系型数据库产品还是内置对多模态的支持,以此更好地处理和分析复杂多样的数据结构、拓展应用场景。
架构创新:存算分离与湖仓一体的融合成为重要趋势。前者通过资源隔离与扩展,可有效解决计算瓶颈的同时降低存储成本;后者则通过支持多数据源间的数据分析、共享、处理、存储,提升企业整体数据管理效率。
分布式下的内核能力提升:随着近几年的高速发展,产品版本迭代问题凸显,厂家纷纷推出LTS长期稳定版本以加速在传统行业落地。同时,分布式下以性能优化、多租户、稳定性为代表的内核能力,成为厂商更新的热点,以此使产品能更好地处理大规模和复杂业务场景。
基础功能增强:兼容性和易用性正受到更多关注。前者通过加强SQL兼容性,使用户在迁移和使用数据库时更加方便,降低迁移成本和学习难度;后者则通过工具、图形化平台等多种手段,简化产品开发、管理成本,提升工作效率。这些基础功能的增强,正是当前国产数据库在替换改造中所亟需解决的痛点。
数据安全:各家厂商也将安全增强作为产品能力必不可少的一环,并持续增强。
而在市场方面,国内数据库厂商竞争日益激烈。从国内某第三方平台的排名可见,头部厂商的更迭频繁,排名变化速度加快;但从市场发展来看,隐隐出现头部集中的现象,特别是伴随着国测等指导性文件的出台,更是加速了这一趋势。已上牌桌的厂商开始快速扩大占有规模,未上牌桌的厂商也在努力争取。新兴厂商较少,一批中小规模的企业正面临一定的生存压力。在国际市场上,国内企业出海发展相对较慢,仅有少数厂商开始海外布局,尚没有出现在海外具有一定知名度和影响力的国产数据库品牌。国内企业还需根据自身情况,考虑合适的时机出海,积极应对全球化竞争。
dbaplus社群携手一众数据库行业专家,汇总、梳理并提炼出主流数据库近半年的版本更迭、性能优化、功能提升等关键信息,希望对大家了解数据库发展趋势,以及数据库选型工作有所帮助和启发。
DB-Engines数据库排行榜
一、RDBMS
Oracle发布以AI为中心的企业开发架构
MySQL 2024下半年重大更新及技术要点分析
SQL Server发布2025版本,及2022版本新特性汇总
PostgreSQL发布17.2新版本,更新16.6、15.10、14.15、13.18和12.22最终版本
MariaDB 2024下半年重大更新及技术要点分析
OceanBase发布4.2.5 LTS 及4.3.4 GA版本
TiDB发布8.5.0 LTS版本和8.4.0、8.3.0、8.2.0三个DMR版本
二、大数据生态圈
Elasticsearch发布三个大版本
Apache Flink发布2.0-preview版本
ClickHouse发布24.6、24.7、24.8、24.9、24.10、24.11等版本
Apache Doris发布2.0.13-2.0.15,2.1.5-2.1.7,3.0.0-3.0.3等版本
SelectDB 2024下半年技术更新汇总
StarRocks发布3.1、3.2、3.3更新版本
三、国产数据库
达梦数据库更新DM8.1版本
GoldenDB 2024下半年技术创新汇总
KingbaseES发布V9R1C2B0014、V9R3C010(MySQL兼容版)及V9R4C010(SQLServer兼容版)等版本
SequoiaDB发布5.8版本更新
ActionDB列存版及发行版生态工具发布
崖山发布YashanDB V23.3版本、数据库一体机、云服务产品
四、云数据库
阿里云2024下半年数据库产品更新汇总
百度智能云2024下半年数据库产品更新汇总
京东云2024下半年数据库产品更新汇总
2024上半年Newsletter回顾&下载
推出dbaplus Newsletter的想法
感谢名单
为方便阅读、重点呈现,本文对各板块内容进行了精简,需阅读完整版可点击文末【阅读原文】或登录以下链接进行下载:
https://pan.baidu.com/s/1oXaKIt-WM_tz_l1sjxdQoA?pwd=2412(提取码:2412)
DB-Engines数据库排行榜
以下取自2024年12月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。
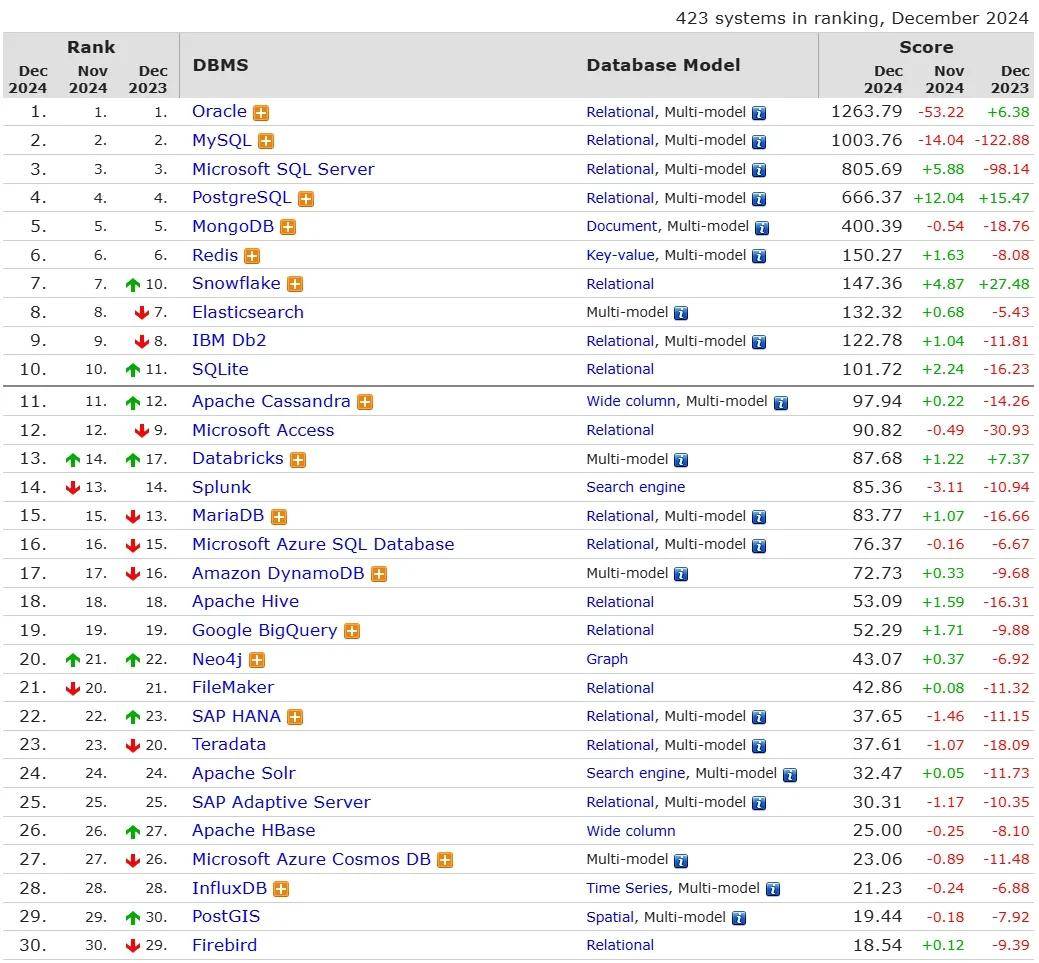
DB-Engines排名的数据依据5个不同的因素:
Google以及Bing搜索引擎的关键字搜索数量
Google Trends的搜索数量
Indeed网站中的职位搜索量
LinkedIn中提到关键字的个人资料数
Stackoverflow上相关的问题和关注者数
RDBMS
1、Oracle推出了以AI为中心的企业应用开发架构,旨在解决传统开发中的复杂性和可维护性问题,帮助客户实现企业应用更灵活、更契合,开发维护更低成本的需求。创新的JSON关系二元性,继承JSON结构开发的灵活和简单又保证了数据的一致性、扩展性,大大提升了应用开发效率。
通过融合数据库,打破了AI数据格式枷锁的束缚,信息无边界,让跨系统开发更简单,AI应用更准确。同时,AI for Data让开发更加关注应用逻辑,而不需要加入大量数据维护和安全代码,让创新随需而行。
此外,Oracle的APEX低代码开发平台为企业提供了AI助手蓝图,可以零代码或低代码快速构建和扩展企业应用的能力,保证了企业应用的可校验和模块化输出。
2、Oracle Database 23ai现已可用于本地Exadata数据库一体机和ODA,同时通过了《信息安全技术网络安全等级保护基本要求》第四级安全计算环境 (数据库) 部分和《信息安全技术信息安全风险评估方法》的要求。
3、Oracle Zero Data Loss Recovery Appliance (ZDLRA) RA23经安全检测符合GB 42250-2022《信息安全技术网络安全专用产品安全技术要求》和数据备份与恢复产品相关规范要求。
2024下半年,MySQL 8.0主要发布了两个版本,包括8.0.39和8.0.40,长期稳定版本发布了8.4.2和8.4.3,这些版本主要是bug修复,基本上没有发布新功能,而创新版发布了9.0.1和9.1.0,在JavaScript支持、新数据类型、性能优化以及企业版功能等方面有重大创新。特别是JavaScript存储程序和VECTOR数据类型的引入,为应用开发提供了新的可能性。以下是对这些更新的简要介绍:
一、MySQL 8.0和8.4版本的主要更新
1、主要改进
修复了在存在数千个只读事务时查询data_lock和data_lock_waits表的性能问题
对于带有ORDER BY和LIMIT的SELECT查询的优化器改进:修复了优化器在处理带ORDER BY和LIMIT的SELECT语句时的成本估算问题
优化了线程池的并发连接处理
改进了文件系统操作的fsync机制
修复了分区表在innodb_parallel_read_threads=1时读取性能问题
修复了TABLE_HANDLES在某些条件下RAM使用量过大的问题(最高可达9GB)
改进了THREADS 列PROCESSLIST_INFO对预处理语句的更新机制
重新设计了performance_schema的data_locks和data_lock_waits表实现,不再需要全局互斥锁
改进了sys.innodb_lock_waits视图性能,每次等待只获取2个锁,而不是每次等待扫描所有锁两次,DATA_LOCKS和 DATA_LOCK_WAITS也添加了主键
修复了REDUNDANT行格式的表使用INSTANT算法的问题
修复了INSTANT算法删除列后的UPDATE/DELETE可能会导致MySQL意外停止的问题
2、复制增强
优化了GTID复制和relay_log_space_limit配合使用的问题,某些场景下会导致无效循环,从而导致复制死锁
改进了工作线程对relay log文件的处理机制
修复了在提交事务到二进制日志时的无限等待问题
3、Group Replication改进
修复了主节点网络不活跃超过20秒导致从节点崩溃的问题
优化了垃圾回收与relay log轮转的配合机制
修复了Group Replication中CREATE TABLE ... SELECT语句的复制问题
优化了组复制的内存管理机制
4、其它增强
优化了启动时tablespace文件扫描性能
mysql客户端新增--system-command选项控制是否允许在客户端执行system命令,默认禁用
优化了redo log容量调整机制
二、MySQL 9创新版本的主要更新
1、主要改进
在少于32个逻辑处理器时,默认关闭innodb_log_writer_threads
改进了复制中用于跟踪二进制日志事务依赖关系的数据结构,从Tree改为ankerl::unordered_dense::map,使用的空间减少了大约60%,有助于提升依赖关系跟踪的性能
放宽了VECTOR数据类型的字符串表示限制
在逻辑处理器少于32个的系统中,innodb_log_writer_threads默认值改为OFF
优化器重要更新:
包含IGNORE关键字的语句不再忽略ER_SUBQUERY_NO_1_ROW错误,因为这可能导致NULL值被插入非空列或子查询转换后行为不一致;升级9.0后,如果IGNORE语句中的标量子查询返回多行将会报错
包含LIMIT 1子句的关联子查询现可优化为派生表的外部左连接
加减列使用的INSTANT ALGORITHM操作的TOTAL_ROW_VERSIONS最大值从64增加到255
优化了CREATE DATABASE和DROP DATABASE语句的原子性
EXPLAIN FORMAT=JSON的输出增强:
新增了连接列信息
添加了semijoin策略信息
添加多范围读取(MRR)信息
Performance Schema中新增两个表:variables_metadata记录系统变量的基本信息(名称、作用域、类型、范围、描述等),global_variable_attributes存储服务器为全局系统变量分配的属性值对信息
新增两个内存临时表转换跟踪变量:TempTable_count_hit_max_ram和Count_hit_tmp_table_size,用于跟踪内部临时表从内存转换到磁盘的情况
新增查询内存使用跟踪变量,用于在启用global_connection_memory_tracking时跟踪查询的内存使用情况:
global_connection_memory_status_limit和相应的计数器
connection_memory_status_limit和相应的计数器
2、JavaScript存储程序
企业版支持使用JavaScript编写存储过程和函数
基于ECMAScript 2023规范,默认开启严格模式
支持大部分MySQL数据类型,包括BLOB、TEXT和JSON
提供SQL和结果集API
3、向量(VECTOR)数据类型
新增VECTOR列类型,支持最大长度是16383
仅InnoDB引擎支持VECTOR列
提供VECTOR_DIM()、STRING_TO_VECTOR()等相关函数
存在部分使用限制(如不能用作键、某些类型的MySQL函数和运算符不接受向量作为参数等)
4、新增组件
新增Option Tracker选项跟踪器组件(Enterprise版)
新增AWS keyring组件(弃用keyring_aws插件)
新增Group Replication流控统计组件(企业版)
增强OpenTelemetry日志支持(仅企业版和MySQL HeatWave支持)
5、功能移除和弃用
移除mysql_native_password认证插件
从MySQL 9.0.0开始,Performance Schema中variables_info表的MIN_VALUE和MAX_VALUE列被弃用,后续版本将删除,建议改用variables_metadata表中的同名列获取相同信息
弃用跨存储引擎的事务(仅支持InnoDB和BLACKHOLE等几个组合)
一、SQL Server 2025 CTP 1重大更新
2024年11月,微软发布了全新SQL Server 2025 CTP 1技术预览版,带来了多项重大更新,具体如下:
1、内置AI功能和AI服务调用:SQL Server 2025集成了先进的AI能力,支持向量搜索和RAG(检索增强生成)模式。新增的向量数据类型和DiskANN高级索引技术,显著提升了数据存储与查询效率。开发者可以通过T-SQL轻松实现混合AI向量搜索,还可以直接调用ChatGPT等AI服务,简化AI应用开发流程。
2、Microsoft Fabric与Azure Arc集成:新版本深度集成了Microsoft Fabric和Azure Arc,实现了数据仓库与OLTP数据源的近实时复制。通过Fabric镜像,用户可将SQL Server数据实时复制到Microsoft OneLake,支持近实时分析。同时,Azure Arc的集成使SQL Server能够在混合环境中灵活部署,兼顾本地与云端的优势。
3、现代化开发工具和开发特性支持:在T-SQL中引入了正则表达式功能,增强数据处理与查询的灵活性,提升开发效率。同时在SSMS数据库管理工具中引入了微软Copilots辅助工具帮助用户智能编写SQL代码,提升了用户开发体验和生产力。
4、Azure SQL DB功能下沉:将Azure SQL DB的多项预览版功能引入本地SQL Server,如优化的查询执行计划和持久化统计信息,确保高性能和安全性,同时支持混合云部署。
5、强化安全性与性能:SQL Server 2025在安全性和性能方面进行了全面升级,支持Microsoft Entra托管身份,提升了凭证管理和合规性。
二、SQL Server 2022 (16.x)版本主要新特性
1、分析功能增强
Azure Synapse Link for SQL:实现对操作性数据的近实时分析,通过与Azure Synapse Analytics无缝集成,支持业务智能和机器学习场景。
对象存储集成:支持与S3兼容的对象存储和Azure Storage的集成,实现数据备份和数据湖虚拟化,支持使用T-SQL查询parquet文件。
2、高可用性提升
包含可用性组:在可用性组级别管理元数据对象,并包含专用的系统数据库,提高管理效率。
3、安全性增强
Microsoft Defender for Cloud集成:通过Defender for SQL计划保护SQL服务器,发现和缓解数据库漏洞,检测异常活动。
Microsoft Purview集成:通过Azure Arc和Purview数据使用管理,实现对SQL Server实例的访问控制和权限管理。
Ledger:使用区块链技术来提供数据篡改证明功能,确保数据完整性,适用于审计和合规需求。
Microsoft Entra身份验证:支持使用Microsoft Entra ID进行身份验证,增强连接安全性。
Always Encrypted with secure enclaves:支持更复杂的加密操作,如JOIN和GROUP BY,提升加密查询性能。
动态数据掩码:提供更细粒度的权限控制,提升数据访问安全性。
4、性能优化
缓冲池并行扫描:利用多核CPU提高大内存机器上缓冲池扫描操作的性能。
有序聚集列存储索引:在内存中排序现有数据,提升列存储索引的压缩效率和查询性能。
虚拟日志文件(VLF)优化:改进VLF增长算法,减少性能影响,提高恢复速度。
即时文件初始化:支持日志文件增长事件的即时文件初始化,提升数据库自动增长效率。
5、查询存储与智能查询处理
查询存储(Query Store)在AlwaysOn的辅助副本上:支持在AlwaysOn的辅助副本上使用查询存储功能,提升查询性能监控。
查询存储(Query Store)提示:通过查询存储提供调整查询计划的方法,无需修改应用代码。
内存授予反馈:根据历史性能调整查询的内存分配,提升查询执行效率。
参数敏感计划优化:为参数化语句自动启用多个缓存计划,适应不同的数据规模。
并行度(DOP)反馈:自动调整并行度,优化重复查询的性能。
基数(CE)估算反馈:识别并修正查询计划中的基数估算问题,提升查询准确性。
6、管理工具和平台支持
加速数据库恢复(ADR)改进:提升ADR的存储和可扩展性,优化清理过程效率。
改进的快照备份支持:支持使用T-SQL创建快照备份,无需VDI客户端。
备份和恢复数据库到亚马逊S3兼容的对象存储:扩展URL备份/恢复语法,支持S3连接器。
去除SQL Server Native Client:推荐使用新的ODBC和OLE DB驱动,提升新应用开发的兼容性。
集成加速与卸载:利用Intel QuickAssist Technology加速技术,提升备份压缩和硬件卸载能力。
7、新的语言功能
可恢复添加表约束:支持暂停和恢复ALTER TABLE ADD CONSTRAINT操作,提升维护灵活性。
时间序列函数:支持时间窗口、聚合和过滤功能,适用于时间变化数据的存储和分析。
2024年下半年,PostgreSQL主要发布了17.2新版本,更新了16.6、15.10、14.15、13.18和12.22最终版本,其中值得关注的新特性有:
1、系统性能提升:优化了vacuum进程,引入新内存结构,最多可减少20倍内存占用,提高vacuum速度;改进I/O层性能,高并发工作负载下写入吞吐量可能提高至2倍;优化使用B树索引的IN子句查询性能,支持BRIN索引并行构建等。
2、开发者体验增强:增加SQL/JSON标准实施,如JSON_TABLE函数等,提供更多与JSON数据交互方式;MERGE命令新增RETURNING子句和更新视图等功能;批量加载和数据导出性能提升,COPY命令新增ON_ERROR选项。
3、逻辑复制增强:简化升级过程,无需删除逻辑复制槽;引入故障转移控制,新增pg_createsubscriber命令行工具。
4、安全性和操作管理改进:新增TLS选项sslnegotiation,增加pg_maintain预定义角色;pg_basebackup支持增量备份,pg_dump新增--filter选项;EXPLAIN新增SERIALIZE和MEMORY选项,可报告垃圾回收索引进度,新增pg_wait_events系统视图。
5、其它更新:提供更安全的异步查询取消方法,内置排序规则程序,改进事件触发器、libpq API等功能。
MariaDB 11.4是最新的长期支持版本(LTS),该分支将一直支持到2029年5月29日。MariaDB在2024下半年关键新特性包括:
一、从Oracle轻松迁移至MariaDB
MariaDB提供了一个创新的Oracle兼容模式,只需简单配置即可实现近乎无缝的迁移。具体而言,通过设置SQL模式为Oracle模式:
SET sql_mode='ORACLE';
在启用Oracle兼容模式后(SET sql_mode='ORACLE'),以下Oracle原生的表结构定义可以在MariaDB中直接执行:
MariaDB [test]> set sql_mode='Oracle';Query OK, 0 rows affected (0.000 sec)MariaDB [test]> CREATE TABLE customers (-> "CUST_NUM" NUMBER(6,0),-> "FIRST_NAME" VARCHAR2(30),-> "LAST_NAME" VARCHAR2(30),-> "ADDRESS" VARCHAR2(120)-> );Query OK, 0 rows affected (0.003 sec)MariaDB [test]> show create table customers\G*************************** 1. row ***************************Table: customersCreate Table: CREATE TABLE "customers" ("CUST_NUM" decimal(6,0) DEFAULT NULL,"FIRST_NAME" varchar(30) DEFAULT NULL,"LAST_NAME" varchar(30) DEFAULT NULL,"ADDRESS" varchar(120) DEFAULT NULL)1 row in set (0.001 sec)
MariaDB能够识别和执行大部分Oracle特有的SQL语法和数据类型。这意味着原有的Oracle表结构、存储过程和查询语句可以在MariaDB环境中直接运行,几乎不需要修改。
二、MariaDB 11.7 RC(开发版本)引入的向量支持
MariaDB向量是一项允许MariaDB服务器作为关系向量数据库运行的功能,用户喜爱的人工智能模型生成的向量可以存储在MariaDB中并进行搜索。
1、向量存储功能
MariaDB现在可以原生存储和管理向量数据
支持将AI模型生成的向量直接保存在数据库中
可以存储高维度的向量,适用于各种机器学习和AI应用场景
2、向量检索性能
提供高效的向量相似度搜索能力
支持多种相似度计算方法,如余弦相似度、欧氏距离等
可以快速在大规模向量数据集中进行相似性匹配
具体使用参考官方文档:https://mariadb.com/kb/en/vector-overview/
三、Spider分片引擎建表语句发生改变
MariaDB Spider分片技术,类似一个中间件(可以把它比作MyCAT),可以让你的应用程序在一行代码不改的情况下轻松实现分库分表。
Spider存储引擎现在支持表选项,而不必在COMMENT/CONNECTION字符串中对其进行编码。
例,在11.4稳定版里,建表语句如下:
CREATE SERVER m57_1 FOREIGN DATA WRAPPER mysql OPTIONS(HOST '127.0.0.1',USER 'admin',PASSWORD '123456',PORT 6666);CREATE SERVER m57_2 FOREIGN DATA WRAPPER mysql OPTIONS(HOST '127.0.0.1',USER 'admin',PASSWORD '123456',PORT 6667);CREATE TABLE test.s (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50)) ENGINE=Spider COMMENT='s表 - 分库分表测试' REMOTE_DATABASE="test" REMOTE_TABLE="s"PARTITION BY HASH (id)(PARTITION ps1 REMOTE_SERVER="m57_1",PARTITION pt2 REMOTE_SERVER="m57_2") ;
这里我们创建了两个数据库节点,版本都是MySQL 5.7,端口6666和6667,我们要实现把数据分散到这两个节点里。
创建分表规则,我们这里以哈希主键id为测试用例,将通过内部的取模规则,将数据分散到后端MySQL 5.7里。
客户端直接连接MariaDB Spider,并插入10条数据,此时回到后端MySQL数据库里查看,你会发现数据已经实现分散。
四、解决MySQL临时表空间无限增大的问题
MySQL BUG复现,影响版本:MySQL 5.7和8.0。
复现步骤:
1、创建一个包含1000万行记录的sbtest1表(可以使用sysbench工具生成数据)。
2、创建一个临时表sbtest2,其结构与sbtest1相同:
CREATE TEMPORARY TABLE sbtest2 LIKE sbtest1;
3、向临时表sbtest2插入1000行数据:
INSERT INTO sbtest2 SELECT * FROM sbtest1;
4、退出会话,临时表sbtest2被系统自动删除:
EXIT;
5、然而,在MySQL中,InnoDB临时表(例如ibtmp1)所占的空间不会被释放,导致专用共享表空间不断增大。
MariaDB解决方案:
在MariaDB中,可以通过设置innodb_truncate_temporary_tablespace_now系统变量,在无需重启数据库的情况下缩减临时表空间:
SET GLOBAL innodb_truncate_temporary_tablespace_now = 1;
这一改进有效避免了MySQL中临时表空间持续膨胀的问题。
2024下半年,OceanBase共发布9个版本,包括面向关键业务负载的全新里程碑版本4.2.5 LTS,以及面向实时分析(AP)场景的首个GA版本4.3.3(目前已迭代至4.3.4版本),其中值得关注的特性包括:
一、面向关键业务负载,OceanBase 4.2.5 LTS发布
OceanBase 4.2.5 LTS版本是面向关键业务负载的全新长期支持版本,性能、稳定性和易用性方面都有显著提升。相较4.2.1 LTS版本,Sysbench基准测试中读写性能提升26%,批量写入性能提升54%,进一步增强OceanBase在关键业务场景下的性能能力。
1、性能优化和优化器能力:4.2.5版本引入了自适应链接和基线优先的SPM演进,通过分区表的晚期物化功能,优化了复杂查询处理能力。同时,优化器性能大幅提升,特别是在估行系统优化、DAS路径选择改进、以及CTE抽取和INLINE代价验证等方面。此外,存储层引入了Batch DML批量接口,进一步提升了DML操作的效率,适用于多种业务场景。
2、兼容性:4.2.5版本针对MySQL兼容性,新增了租户对锁函数、非法日期、XA 事务和中间快速加列的支持,进一步确保MySQL业务平滑迁移的无缝体验。同时针对Oracle兼容性,租户层面新增了DBMS_LOCK 包功能,并支持快速删列和存储过程远程调用的复杂类型,进一步加强关键业务系统对兼容性的能力。
3、系统稳定性和可靠性:4.2.5版本新增了备份配置项功能,提升了数据备份的灵活性和可控性。通过日志强管归档、Transfer活跃事务搬迁、以及基于IO负载的自适应仲裁升降级功能,提升系统在复杂业务场景下的容错能力和稳定性。
4、资源隔离与升级性能:4.2.5版本优化了资源隔离机制,如将统计信息和Clog日志提交纳入资源隔离,并实现了DDL资源隔离,使多租户环境下资源分配更为合理。在多租户升级场景下,表级恢复和升级性能也得到优化,显著缩短了大规模租户的升级耗时,升级过程更加顺畅。
5、安全性与易用性:新版本通过assume role提升了对象存储访问的安全性,并新增了行锁等待和重试等待事件的诊断功能、响应时间直方图和日志传输链路视图,大幅提升了系统的可观测性和诊断效率。同时,Observer资源规格的动态修改实时生效,以及日志副本并行迁移优化,使DBA的管理操作更加便捷。
此外,OceanBase 4.2.5扩展了其多模能力,新增了对OBKV-Redis模型的支持,进一步丰富了其生态系统。通过优化OB-HBase的过期删除机制,解决了“热key”场景下数据版本过多的问题,并新增了ColumnPaginationFilter和Reverse Scan接口,进一步提升了HBase兼容性。
总结来看,OceanBase 4.2.5 LTS版本通过一系列技术和功能优化,巩固了其在关键业务场景中的稳定性、性能和兼容性,同时大幅提升了用户的管理体验和易用性。
二、面向实时AP场景,OceanBase 4.3.3正式GA
针对AP场景进行大幅性能优化,推出全新向量检索功能,实现SQL+AI一体化,深度融合AI与数据库处理,进一步满足客户在云+AI时代的数据管理需求,加速RAG、智能推荐、多模态搜索等业务场景的落地。
1、对多模态数据支持:4.3.3版本进一步扩展了对复杂数据类型的处理能力,新增Array类型,并对Roaringbitmap类型数据的计算性能进行了优化,为企业处理多样化数据结构提供更高的灵活性。
2、向量融合查询能力:4.3.3版本新增向量检索能力,支持向量数据类型和向量索引,并基于向量索引提供强大的搜索能力。用户可通过SQL及Python SDK等方式灵活调用OceanBase的向量检索能力,同时结合对海量数据的分布式存储能力、多模数据类型及多类型索引的支持,极大简化AI应用技术栈,助力企业高效构建AI应用。
3、多工作负载:4.3.3版本对AP(分析处理)场景进行大幅性能优化,尤其是在海量数据分析时,能够提供更短的响应时间和更高的吞吐能力。同时引入了列存副本的新形态,实现满足TP和AP负载的物理资源强隔离,确保系统在处理事务型负载时,不受分析型负载的影响,特别是在实时数据分析和决策场景中,能够保持系统的高性能与稳定性。
一、2024下半年重大更新总结
TiDB发布8.5.0 LTS版本和8.4.0、8.3.0、8.2.0三个DMR版本,其中值得关注的特性有:
1、引入向量搜索:TiDB向量搜索提供了高级的语义搜索功能,可以在文档、图像、音频和视频等多种数据类型之间进行相似度搜索。TiDB向量搜索的SQL语法与MySQL兼容,熟悉MySQL的开发人员可以基于该功能轻松构建AI应用。
2、稳定性和高可用:通过Schema缓存控制、设置统计信息缓存使用内存的上限、PD和统计信息优化、管理大量执行计划绑定、增强资源组管理能力等新特性,进一步提升超大规模集群的稳定性。
3、扩展性和性能:每个TiDB集群支持超过100万张表,批量建表性能提升20多倍,通过多维度降低数据处理延迟、实例级执行计划缓存、projection算子下推等新特性,更好地满足金融领域对SQL处理低延迟的高要求。
4、SQL:支持分区表全局索引,降低了跨分区表查询的复杂性,帮助用户轻松应对大数据量历史表的处理。
5、管理及可观测性:TiKV的TOP SQL按“表”或“数据库”进行聚合、将CPU时间(TiDB&TiKV)系统表中显示等新特性提供了更加精确的资源可视化,提升诊断效率。
二、2025年展望
TiDB将聚焦企业级关键业务场景,继续夯实HTAP和AI方向的多维能力,包括可扩展的在线事务处理、实时的轻量级数据分析、高效的向量及全文检索能力等领域。
TiDB v9将在稳定性、性能和扩展性方面实现关键的提升:通过内存分配模型演进和计划绑定自动推荐增强集群的稳定性;通过Cascades优化器和向量搜索功能的增强实现性能的提升;通过TiCDC新架构和加速批量DDL等新特性进一步提升集群的扩展性。
大数据生态圈
Elasticsearch在2024下半年发布了三个大版本,8.15.x、8.16.x、8.17.x,带来了诸多新的功能特性,在性能上也有大幅度的提升,同时7.17.x发布更新了4个小版本,修复了部分兼容性已知问题。

Elasticsearch 2024下半年版本发布
8.14.x~8.17.x版本的主要新功能特性如下:
1、int4数据类型
8.15发布支持int4向量类型。
LLM大模型时代,内容向量化是必然的,向量化存储消耗大量的存储资源、向量化查询消耗大量的计算资源,默认情况下向量值是采用float32,通过容许一点精度损失,采用int4类型来存储,可以获得数倍的成本优势。
{"properties": {"text_embedding": {"type": "dense_vector","dims": 384,"index_options": {"type": "int4_hnsw"}}}}
2、zstd压缩算法
8.16发布了新的索引的压缩算法zstd,同比lz4,至少可以节约10%的磁盘空间,对于规模庞大的集群,10%的磁盘空间节约明显可以降低成本。
注意,过高的数据压缩率必然会导致更高的cpu资源消耗,启用zstd压缩,依然要根据业务场景与资源消耗来评估,很多时候进行一些详细的索引设计是有必要的。
默认情况下,创建索引依然是lz4算法,使用zstd需要设置索引的编码。
{"settings": {"index.codec": "best_compression"}}
3、logsdb索引模式
8.17版本发布了logsdb索引模式,官方压测同比之前日志存储可以节约2.5倍的磁盘空间。
ELK组合至今依然是企业IT系统首选的日志平台,随着企业接入的日志量越来越多,存储成本越来越高,尤其日志规模动辄数百TB以上,同比要多近1倍的磁盘空间,logsdb日志索引模式可以有效降低企业成本。
logsdb索引模式应用非常简单,索引设置如下:
{"settings": {"index.mode": "logsdb"}}
一、2024下半年重大更新总结
Apache Flink社区正在积极准备 Flink 2.0,这是自Flink 1.0发布8年以来的首次大版本发布。作为一个重要的里程碑,Flink 2.0将引入许多激动人心的功能和改进,以及一些不兼容的破坏性变更。为了促进用户和上下游项目(例如,连接器)尽早适配这些变更,提前尝试这些令人兴奋的新功能同时收集反馈,目前提供了Flink 2.0的预览版本。
注意:Flink 2.0预览版不是稳定版本,请不要应用于生产环境。虽然这个预览版包含了Flink 2.0中绝大部分影响兼容性的变更,但2.0正式版仍可能引入额外的非兼容改动。
这些改动包括移除一些旧的、过时的API,例如DataSet API、Scala DataStream API和TableSource TableSink等等。同时,我们对现有的API,如DataStream API、Table API、REST API和Flink/SQL Client,也进行了小幅度的更新。
在配置方面,旧的flink-conf.yaml配置文件被彻底废弃,新的配置文件全面对接标准的YAML生态。同时,对现有配置项进行了全面的简化和梳理。需要提醒大家的是,Flink 1.X和Flink 2.0之间无法保证100%的Checkpoint (CP) 和Savepoint (SP) 状态兼容性。这主要是因为Flink对其序列化框架进行了多项升级和改造。不过,Flink社区正在积极准备工具,来帮助用户进行非兼容性状态的迁移。另外,Java 8的支持将不再提供,包括Per-job的部署模式也将在2.0版本中移除。用户可以更广泛地采用Application的部署模式。
注:关于API、连接器适配计划、配置等非兼容变更,以及存算分离状态管理、物化表、批作业的自适应执行、流式湖仓等重要新特性的具体信息,可阅读本期Newsletter完整版(点击本文文末【阅读原文】可下载)
二、2025年展望
2025年会正式发布Flink 2.0版本,届时所有preview版本中的预览性功能会更加稳定。同时,会持续完善上下游生态对2.0版本的适配,协助用户更好地升级到新的版本。
一、2024下半年重大更新总结
2024下半年,ClickHouse主要发布了24.6、24.7、24.8、24.9、24.10、24.11六个新版本,其中24.8是LTS版本,值得关注的新特性/新功能如下:
1、并行哈希Join成为默认策略:在24.11版本中,并行哈希Join算法取代了哈希Join,成为默认的Join策略。并行哈希Join是哈希Join的一种改进算法,通过将输入数据分片并并发地构建多个哈希表,实现了更快的Join操作,但需要更多内存资源。除了默认启用外,本次更新还对该算法进行了性能优化。现在,线程间分发的块在并行处理时使用零拷贝技术,避免了每次复制块列所带来的额外开销。
2、BFloat16数据类型:BFloat16数据类型由Google Brain团队开发,专用于表示向量嵌入。顾名思义,它由16位组成,其中1位为符号位,8位为指数,7位为尾数(小数部分)。这一数据类型的指数范围与Float32(单精度浮点数)相同,但尾数位数较少(7位,而非23位)。 现在,ClickHouse已支持BFloat16数据类型,非常适合用于AI和向量搜索场景。
3、可刷新物化视图:之前,可刷新物化视图是一种实验性功能,能够将查询结果存储以便快速读取。在24.9发布中,新增了APPEND功能,使得在更新视图时无需替换整个视图内容,而是直接将新行追加到表末尾。在24.10版本中,该功能不仅支持Replicated数据库引擎,而且已经可以正式应用于生产环境。
4、Variant类型的模式推断。
5、JSON数据类型和用于JSON数据分析的聚合函数:在24.8发布中,实验性地引入了全新的JSON数据类型。这个功能开发已久,之前版本的发布中也提到过它依赖的几种类型——Variable和Dynamic。JSON数据类型专为存储半结构化数据而设计,适用于每行数据结构可能不同或不希望将其拆分为单独列的情况。
6、Merge期间Projection的控制。
7、时序表引擎:24.8引入了时序表引擎 (TimeSeries)。这个表引擎支持使用ClickHouse作为Prometheus的存储,通过远程写入协议 (remote-write) 进行数据存储。此外,Prometheus还可以通过远程读取协议 (remote-read) 从ClickHouse中查询数据。
二、2025年展望
2025年,ClickHouse将持续在新版本体现Join的性能优化和数据湖的整合。
一、2024下半年重大更新总结
2024下半年Apache Doris发布了2.0.13-2.0.15、2.1.5-2.1.7、3.0.0-3.0.3等多个版本,其中值得关注的新特性/新功能有:
1、3.0版本开启存算分离新纪元,基于云原生存算分离的架构,通过多计算集群可实现查询负载间的物理隔离及读写负载隔离;借助对象存储或HDFS等低成本共享存储系统能够大幅降低存储成本。
2、3.0版本湖仓一体再进化,新增数据湖写回功能,支持多数据源间的数据分析、共享、处理、存储;结合异步物化视图,可构建统一的湖仓数据处理引擎。
3、3.0版本半结构化场景持续发力,在倒排索引、N-Gram Bloom Filter、Variant数据类型方面持续增强,对半结构化数据的存储和处理分析更加灵活高效,相比Elasticsearch达到10倍性价比提升,且社区即将发布向量索引能力。
二、2025年展望
新增功能上:
1、内置CDC同步:可以不依赖外部工具,支持从众多TP数据库直接CDC导入数据,打造HTAP Solution。
2、支持增量批量处理:统一实时和批量处理、增量处理,需要Doris支持增量读取表的更新数据。
3、完善湖仓一体:插件化体系,兼容Trino/Presto Connector框架;完善高吞吐读写的Data API。
4、存算一体和存算分离部署形态融合:不再需要两种部署形态,用户可以在使用过程中无缝切换,避免过早复杂性。
一、2024下半年重大更新总结
2024下半年,SelectDB发布了SelectDB Enterprise Core2.1.5-2.1.7、SelectDB Enterprise Manager 24.0.3-24.0.5、24.1.0-24.1.3、SelectDB Cloud Core 4.0.1-4.0.3、SelectDB Cloud Manager 24.3.0-24.4.0、阿里云SelectDB版3.0.10-3.0.11、4.0.1-4.0.4。其中值得关注的新功能特性有:
1、SelectDB Enterprise、SelectDB Cloud、阿里云SelectDB版Core
湖仓一体:新增若干功能和优化。实现Iceberg表的写回功能;增强SQL拦截规则,支持对外表的拦截处理;新增系统表file_cache_statistics,用于查看BE节点的数据缓存性能指标等。
异步物化视图:新增若干功能和优化。支持在构建物化视图中使用非确定性函数;支持原子替换异步物化视图定义等。
半结构化数据分析:新增若干功能和优化。使用VARIANT类型的表支持部分列更新;支持默认开启 PreparedStatement;VARIANT 类型支持导出为CSV格式等。
查询优化器:新增若干功能和优化。支持explain DELETE FROM语句;支持常量表达式参数的Hint形式;完善MySQL协议返回列的信息等。
存储管理:新增若干功能和优化。增加了information_schema.table_options和information_schema.table_properties系统表,支持查询建表时设置的一些属性等。
2、SelectDB Enterprise、SelectDB Cloud、阿里云SelectDB 版Manager
Enterprise Manager:
告警模块优化,策略支持指定告警等级、导入导出、在告警恢复的时候发送通知以及告警信息详情优化。
升级流程增强,支持断点式升级,升级异常支持回滚。
配置管理优化,校验配置有效性,支持配置变更中断。
webui合入manager,打包到manager,不再需要单独部署。
webui支持workload group管理,可以新增、编辑及查看。
webui支持导入任务管理,同时数据板块新增函数展示。
Cloud Manager:
支持设置可维护时间段。
支持设置内核小版本升级策略,用户可以选择自动升级或者手动升级。
支持计划内事件,事件类型目前支持版本升级,包括用户设置了自动升级内核小版本的事件、手动升级选择了指定时间执行的事件。
支持消息中心,目前包括站内信和计划内事件管理。
BYOC仓库使用优化。
官网和Cloud注册/登录/免费试用链路优化。
阿里云SelectDB版:
支持在目标计算资源对应的缓存空间范围内扩缩容集群的缓存空间。
支持续费、升配、退订存储资源包。
集成了配置审计(Cloud Config),支持资源的配置历史追踪、配置合规审计等能力。
支持按量付费集群分时弹性伸缩。
适配了阿里云Dataworks数据集成,支持MySQL系列数据源整库全增量数据实时同步至阿里云SelectDB 版。
适配了阿里云DTS,支持PostgreSQL系列数据源整库迁移或全增量数据实时同步至阿里云SelectDB版。
适配了阿里云托管版Flink,支持用户上传Flink Doris Connector,将多种数据源增量数据实时同步至阿里云SelectDB版。
二、2025年展望
新增功能上:
1、内置CDC同步:可以不依赖外部工具,支持从众多TP数据库直接CDC导入数据,打造HTAP Solution。
2、支持增量批量处理:统一实时和批量处理、增量处理,需要Doris支持增量读取表的更新数据。
3、完善湖仓一体:插件化体系,兼容Trino/Presto Connector框架;完善高吞吐读写的Data API。
4、存算一体和存算分离部署形态融合:不再需要两种部署形态,用户可以在使用过程中,无缝切换。避免过早复杂性。
5、跨可用区容灾:在主可用区故障或发生自然灾害时,可以较快切换到备可用区继续提供服务,保障数据不丢或者只丢失时间最近的少量数据。
6、数据备份恢复:支持在本地或异地备份,可恢复到历史上某个时间点的数据集,协助业务找回大部分数据,或者修复线上生产的错误数据,或者使用线上数据搭建仿真模拟测试环境。
7、支持Serverless云原生秒级弹性:及时感知业务访问压力变化,并且调度合适的计算和存储资源响应,灵活满足业务实际需要的同时,最大程度提升资源利用率,减少冗余浪费。
StarRocks在2024下半年发布了3.1、3.2、3.3等版本。这段时间内StarRocks社区主要致力于提升性能、稳定性和用户体验方面,特别是在物化视图、安全性和数据湖分析等方面。
1、存算分离
优化对腾讯云COS的支持。
优化存算分离架构中的数据缓存功能,可以指定热数据的范围,并防止冷数据查询占用Local Disk Cache。
优化主键表内部修复的逻辑。
2、物化视图
支持备份还原List分区表。
优化物化视图的Text-based Rewrite。
物化视图改写能力得到加强,通过View Delta Join或Query Delta Join技术支持更多查询类型。
3、数据湖
支持从StarRocks读取ARRAY、MAP和STRUCT等复杂类型的数据,并以Arrow格式提供给Flink connector读取使用。
支持Delta Lake Catalog的元数据缓存、元数据手动刷新以及周期性刷新策略。
支持通过Spark connector导入Spark数据至StarRocks。
Paimon外表支持DELETE Vector。
JDBC Catalog支持Oracle、SQL Server和更多的数据类型。
国产数据库
一、2024下半年重大更新总结
2024下半年,达梦数据库主要更新了DM8.1版本,其中值得关注的新特性和新改进有:
1、外部函数优化。
2、备份功能优化。
3、Oracle兼容性增强。
4、新增重载函数,优化DBMS_JOB包相关函数、运算符函数,日期时间函数,改进管道函数、聚合函数等。
5、物化视图及系统视图等功能改进。
6、DBLINK相关功能改进。
7、dexp导出和dimp导入相关功能优化。
8、优化改进重建系统包相关功能及其他系统包的方法功能改进。
9、DSC集群并发插入性能、自治事务功能及内存控制功能等提升优化。
10、DPC环境下自治事务相关功能、分区表相关功能及非分布列并发查询性能等优化提升。
11、SQL语句执行性能提升/功能改进。
二、2025年展望
1、对ST函数执行效率进行优化,简化ST函数,提高ST函数执行效率,缩短函数执行所需时间,性能提升至少10%以上。
2、支持局部临时表的使用方式,包括创建、增删改查等。
3、兼容Oracle本地绑定变量,在disql上实现本地绑定变量的功能。
4、对备份还原进行优化改造并完善监控功能,预期能够较大幅度提升部分场景下的性能以及改善用户的使用体验。
5、对PROC*C进行增强,支持对OBEJCT类型创建、删除、插入数据。
1、引入列存引擎,实现实时分析能力:引入列存后,表支持行存、列存和行列混存等多种存储方式,以便灵活适应事务型和分析型工作负载,可根据查询类型(事务型查询或分析型查询)自动路由至合适引擎,提高HTAP场景数据处理性能。列存采用MPP架构,查询性能出色,能实现秒级查询返回,可实时处理数据,数据更新秒级生效。列存采用分布式架构可线性扩展,通过多副本存储和一致性协议保障高可用性与数据可靠性。
2、容器化部署高阶功能支持:增强对容器化部署的支持,包括支持Operator和部署流程的界面化操作,提供更加灵活的弹性扩缩容方案以满足动态业务需求。
3、异构部署支持:支持服务器与操作系统的异构部署(包括异构芯片架构的兼容部署)。增强对不同部署环境(物理机、云环境)的一致性支持。
4、Oracle兼容性持续改进:新增对更多Oracle SQL语法和对象功能的支持,包括兼容Oracle批量插入行为、物化视图、分区全局索引、DBLINK、闪回操作、绑定执行计划和子分区模板等功能,进一步提升对Oracle应用迁移的支持能力。
5、支持JSON、XML、GIS等多模特性:GoldenDB支持对GIS、XML、JSON等提供了丰富的数据类型、函数、索引和存储等高效数据处理服务。
6、新增SQL并行与智能优化功能,提升SQL处理效率:并行能力全面增强,支持SQL并行查询、并行更新、并行加索引和直方图并行等,优化多用户高并发场景性能。支持SQL智能优化,包括优化器改进、SQL自动改写。小表驱动大表优化,增强查询性能,特别在多表关联和聚合分析场景中表现更优。
7、新增表存储压缩功能:支持分区行压缩,降低数据膨胀率。支持冷热数据分离存储,支持对Decimal数据类型采用变长存储模式,节省存储空间。
8、实现更灵活的备份与恢复功能:支持对指定库、表的备份与恢复。新增备份恢复限流功能,进一步提升系统资源利用率。引入数据库克隆功能,加速数据恢复与部署流程。
9、SQL级监控与治理:全面支持SQLID监控,提供慢SQL、TOP SQL、新SQL、可疑SQL的实时统计与分析功能。实现SQL限流和查杀功能,包括支持按SQL规则动态限流或查杀。在线诊断与调优功能:支持基于在线会话的SQL诊断和执行计划绑定。
10、系统工具包与统计功能:新增系统包方法改进,包括增强统计信息收集性能,优化存储过程及系统函数性能,为大规模业务场景提供更加稳定高效的支持。
一、2024下半年重大更新总结
2024下半年,金仓数据库管理系统KingbaseES发布面向全市场的V9R1C2B0014版本,其中值得关注的功能有:
1、应用迁移与开发:完善迁移方案,支持无源码Oracle应用的迁移验证方案。对异构数据库语法兼容能力显著提升,在迁移时大幅减少应用代码修改量。新增兼容多种语法、函数、视图及语句。
2、性能:增强逻辑优化,改进基数估计逻辑。推出SQL调优工具,优化自治事务、DML执行等性能。大规模分区表并发访问性能提升10倍,TPCH场景与DML语句性能均提升20%。
3、可用性:支持多种备份与恢复功能,具备存储容错及坏块检测能力。强化在线重定义、两地三中心方案及TAC透明应用切换能力,大幅缩短RTO。
4、横向扩展:提升RAC负载均衡性能,新增单活模式。
5、安全防护:增强多租户资源管理,新增防篡改与SQL防护墙功能。
6、软件包及环境适应性:新增DBCA数据库配置工具、rpm、deb等安装包形态及UKEY、LAC等授权机制。
此外,还推出细分市场版本V9R3C010(MySQL兼容版)及V9R4C010(SQLServer兼容版),该版本具备高度的MySQL/SQLServer兼容性。
二、2025年展望
以“五个一体化融合架构”为核心,不断增强产品能力和适应性,最终达成产品终极目标:
1、应用迁移及开发:应用迁移:“0”停机数据迁移,“0”修改应用代码迁移;应用开发:SDK功能丰富,开发工具易用,开发过程高效。
2、性能:全场景、主要目标平台性能指标最优。
3、可用性:无论发生计划外、计划内停机时可以做到RTO=0(业务连续不中断),RPO=0(数据0丢失)。
4、横向扩展:支持本地、跨地理位置扩展;实现近线性的性能加速;不增加开发、管理成本;支持独立扩展瓶颈资源。
5、安全防护:有效应对各种攻击;零安全漏洞;对生产性能影响低。
6、软件包及环境适应性:全部署架构、全运行环境,全使用过程可用、易用。
7、可服务性:用户自服务化,系统自治。
2024下半年,巨杉数据库发布了v5.8版本更新,主要更新内容如下:
1、新功能:实现通信压缩;创建集合支持指定多个数据组;支持克隆创建集合和集合空间。
2、稳定性优化:优化缓存管理,降低内存占用;优化索引创建机制,不阻塞外部写入;优化容错熔断机制,增强自适应调整能力。
3、运维监控优化:慢查询新增十余项监控指标;健康快照新增节点切主信息;优化查询快照和事务快照性能。
4、性能优化:优化数据库节点启动/停止、切分、数据校验性能;优化索引统计信息子表采样率;增加统计信息缓存,提升优化器性能。
5、管理工具优化:SAC监控管理工具新增用户角色权限管理、审计日志、服务器管理、自身元数据备份和恢复、集群日志错误码搜索等特性。优化了集群性能、CPU性能等统计指标。
一、2024下半年重大更新总结
2024下半年,爱可生发布了ActionDB列存版本,并发布了系列工具产品如下:
发行版传输工具:ActionOCP
发行版迁移工具:ActionOMS
发行版开发者工具:ActionODB
新增容器部署方式:ActionDB Docker
二、2025年展望
爱可生云树DMP完成对ActionDB及OceanBase的支持。
一、2024下半年重大更新总结
2024下半年,崖山团队主要发布了YashanDB V23.3版本、崖山数据库一体机和数据库云服务产品。
YashanDB V23.3新特性:
兼容性:Oracle兼容性由90%提升至99%,新增MySQL兼容性形态。
性能:算子性能增强;共享集群性能提升,4节点集群的TPCC达到520万tpmC。
可用性:支持逻辑备库、主备共享集群,推出基于共享集群的两地三中心方案。
安全性:实现表级、列级加密,实现行级访问控制,实现数据动态脱敏,全面支持国密算法。
迁移相关:新增增量迁移组件,实现异构数据实时增量同步。
运维相关:新增支持管控YashanDB共享集群,增强数据库审计及监控可视化能力。
此外,YashanDB联合国内头部软硬件厂商推出数据库一体机,提供软硬一体化方案;云服务则帮助用户解决云上运维、选型、多云切换及分散系统建设难题。
二、2025年展望
下一步,YashanDB将围绕多租户、软硬协同、应对未来数据挑战三大目标继续优化:
1、多租户方面:持续完善资源共享与隔离方案解决企业成本和业务发展需求,降低企业数据库运维成本,提供弹性扩展能力。
2、软硬协同方面:通过对硬件的深度整合,进一步挖掘网络、内存等硬件资源效能,继续提升数据库系统性能。
3、面向未来数据挑战:YashanDB计划通过多机并行计算技术,进一步提升超大集群的扩展能力,在保持联机交易低延时,高并行的基础上,同时提供海量数据分析能力,解决客户多样化的数据使用需求。
云数据库
一、云原生数据库PolarDB
1、PolarDB MySQL版
新增容灾演练功能。
PolarStore推出弹性内存池(EMP)功能。
Serverless集群支持接入列存索引(IMCI)功能。
新增通过弹性并行查询(ePQ)技术来实现冷数据并行查询的方法。
新增Orca(兼容Redis协议)功能。
提供无感数据集成(Zero-ETL)功能。
2、PolarDB PostgreSQL版
标准版正式上线国际站。
新增SQL限流功能,避免异常流量的SQL语句造成业务影响。
新增图数据库,高度兼容Apache AGE的图引擎。
发布安全可靠、兼容PostgreSQL的PolarDB V2.0方案。
3、PolarDB分布式版
新增全球数据库网络(GDN)功能。
新增冷数据行级归档功能。
开源发布2.4.1版本,增强企业级运维能力。
发布安全可靠、兼容MySQL的PolarDB分布式版V2.0方案。
二、云原生数据仓库AnalyticDB
兼具数据湖的扩展性和数据库的易用性,支持灵活、多维度的数据分析。通过自研在线分析MPP引擎和Native执行引擎,AnalyticDB性能可提升50%。基于实例的CPU/内存负载、查询排队、查询并发数等指标,自动进行cluster弹性伸缩,可将弹性时间降至20秒。
集成离线处理Spark引擎,通过Native执行引擎+OSS数据缓存,对比开源版本,AnalyticDB性能提升7倍。
三、云原生多模数据库Lindorm
面向AI和车联网等创新应用开发场景,Lindorm内置AI推理服务,可加载业务所需的模型处理数据,并提供统一的表视图和SQL访问接口,一体化实现数据查询、融合检索、离线分析、交互分析等功能。
一、云数据库RDS
RDS控制台页面全新升级,DMS升级为DBSC(数据库智能驾驶舱),支持可视化查看实例拓扑结构,提供更加流畅的控制台体验。
MySQL支持跨地域备份,可用于监管或容灾恢复等场景。
PG支持插件管理,满足用户对插件的筛选、安装、卸载等需求。
RDS支持智能问答助手「智能领航员」,为客户常见问题答疑解惑。
二、云原生数据库GaiaDB
内核发布新版本:支持列存索引、闪回查询、高权限账号等功能。
产品规格:上线通用型规格,单节点月花销最低为10元,发布GSL4型磁盘,单GB成本大幅下降。
产品功能:重点页面体验升级,升级数据库工具,支持可视化查看实例拓扑结构,连接检查查询,支持智能问答助手「智能领航员」。
三、云数据库Redis
Redis内存型、容量型:支持迁移可用区。
Redis容量型(PegaDB):内核引擎兼容Redis 7.0版本数据类型。
Redis容量型(PegaDB):支持数据快速灌库,相比传统标准协议,数据导入速度提升5~10倍。
Redis容量型(PegaDB):支持异地多活实例组,实现跨地域数据高性能读写。解决了业务因跨地域、远距离访问导致访问延迟大的问题。
Redis容量型(PegaDB):新增数据备份功能,满足各类场景下对数据备份与恢复的需求。
四、云数据库MongoDB
产品功能升级:支持创建实例配置自动备份,云磁盘最大支持10TB。
五、向量数据库VectorDB
内核新版本发布v1.3升级至v2.2,支持RBAC,HNSWPQ索引,batch Search,向量索引的auto build等。
安全提升:支持TLS加密,支持TDE加密。
产品功能:支持回收站。
生态层面实现多项发布与对接,支持VectorDB CLI和AI Search等。
六、数据库智能驾驶舱DBSC
诊断优化支持GaiaDB、Redis、PegaDB。
数据开发上线,支持MySQL、GaiaDB、PostgreQL、Redis 可视化SQL开发,提供数据生成、敏感数据脱敏等能力。
七、数据传输服务
新增MongoDB 5.0数据源支持。
一、分布式数据库TiDB
1、新增实例参数管理和参数模板管理,提升实例参数管理效率。
2、新增多账号管理及细粒度权限分配,完善账号管理能力。
3、新增数据库管理能力。
4、新增TiDB 7.5版本。
5、新增多可用区部署能力。
二、云数据库PostgreSQL
1、PostgreSQL9.6、PostgreSQL10版本支持跨大版本升级,实现一键自助升级能力。
2、新增实例迁移可用区功能,提供一键可用区调整能力。
3、新增实例主备切换日志。
三、云数据库MySQL
1、新增MySQL 5.6版本小版本升级。
2、新增实例迁移可用区功能,提供一键可用区调整能力。
3、通过云盘重挂载提升MySQL实例云盘变配效率。
4、新增实例白名单分组功能。
四、云数据库MongoDB
1、MongoDB实例接入SmartDBA提供性能分析和慢SQL分析能力。
2、新增实例白名单分组功能。
3、通过云盘重挂载提升MongoDB实例云盘变配效率。
五、分析型云数据库ClickHouse
新增ClickHouse 24.3和ClickHouse 24.8版本。
六、云原生数仓Starwift
新增节点组功能,隔离不同租户的资源使用,提升系统的并发能力和稳定性。
七、数据库自治服务SmartDBA
新增MySQL秒级性能监控,提升数据库性能优化和稳定性保障能力。
2024上半年Newsletter回顾&下载
推出dbaplus Newsletter的想法
dbaplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、时序数据库、大数据生态圈、国产数据库、云数据库等几个版块。
我们不以商业宣传为目的,不接受商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎监督指正。
下期Newsletter计划时间是2025年6月16日~6月25日,如果有相关的信息提供请发送至邮箱:newsletter@dbaplus.cn
感谢名单
最后要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后:

欢迎提供Newsletter信息,
发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿,
发送至邮箱:editor@dbaplus.cn
↓ 点击【阅读原文】下载本期完整版(提取码:2412)
https://pan.baidu.com/s/1oXaKIt-WM_tz_l1sjxdQoA?pwd=2412#list/path=%2F








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721