
DB-Engines数据库排行榜
一、RDBMS家族
MySQL发布正式版8.0.11(GA)
MariaDB发布10.3.8版本
SQL Server AlwaysOn 2017特性解读
DB2发布11.1.3.3版本
PostgreSQL发布 11 beta1版本
Greenplum发布5.9版本
二、NoSQL家族
MongoDB 4.0发布第一个RC版本
Redis发布5.0 RC1版本
Neo4j发布3.4版本
三、NewSQL家族
TiDB发布2.1 Beta版本
CockroachDB发布2.0版本
本期新秀:Apache Trafodion最新R2.2版本
四、时间序列
InfluxDB更新1.5.3和1.5.4
OpenTSDB 2.3.1发布新功能
五、大数据生态圈
Hadoop发布三个发行版本
Apache Flink发布1.5.0版
Apache Ignite 2.5:千级节点伸缩性
Apache Beam发布2.3.0版
ElasticSearch发布 6.3.30版本
六、国产数据库概览
浪潮发布K-DB 11g FS06版本
本期新秀:易鲸捷发布EsgynDB V2.4版本
OceanBase发布1.4.71版本
SequoiaDB发布3.0版本
GBASE发布GBase AI
七、推出DBAplus Newsletter的想法
八、感谢名单
为方便阅读、重点呈现,本期Newsletter(2018年7月)将对各板块内容进行精简。需要阅读全文的同学可点击“此处”进行下载。
DB-Engines数据库排行榜
以下取自2018年7月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。

DB-Engines排名的数据依据5个不同的因素:
Google以及Bing搜索引擎的关键字搜索数量
Google Trends的搜索数量
Indeed网站中的职位搜索量
LinkedIn中提到关键字的个人资料数
Stackoverflow上相关的问题和关注者数
RDBMS家族
2018年4月19日,MySQL 发布正式版 8.0.11 。
(注意:从 MySQL 5.7 升级到 MySQL 8.0 仅支持通过使用 in-place 方式进行升级,并且不支持从 MySQL 8.0 降级到 MySQL 5.7,或从某个 MySQL 8.0 版本降级到任意一个更早的 MySQL 8.0 版本。唯一支持的替代方案是在升级之前对数据进行备份)
下面简要介绍 MySQL 8 中值得关注的新特性和改进:
性能:MySQL 8.0 的速度要比 MySQL 5.7 快 2 倍。
MySQL 8.0 在读/写工作负载、IO 密集型工作负载、以及高竞争("hot spot"热点竞争问题)工作负载等方面带来了更好的性能。
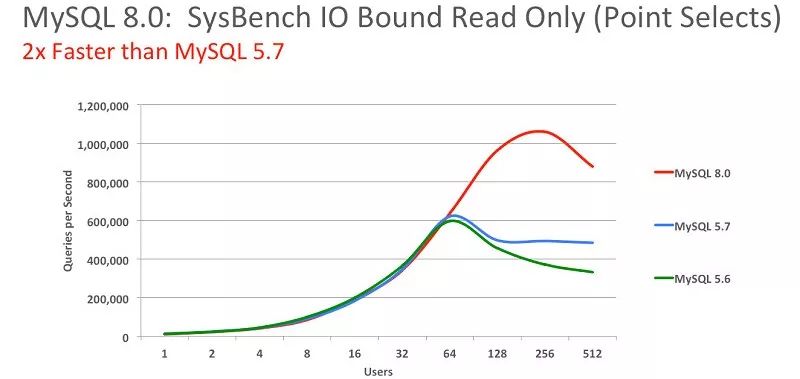
NoSQL:MySQL 从 5.7 版本开始提供 NoSQL 存储功能,目前在 8.0 版本中这部分功能也得到了更大的改进。该项功能消除了对独立的 NoSQL 文档数据库的需求,而 MySQL 文档存储也为 schema-less 模式的 JSON 文档提供了多文档事务支持和完整的 ACID 合规性。

窗口函数(Window Functions):从 MySQL 8.0 开始,新增了一个叫窗口函数的概念,它可以用来实现若干新的查询方式。窗口函数与 SUM()、COUNT() 这种集合函数类似,但它不会将多行查询结果合并为一行,而是将结果放回多行当中。即窗口函数不需要 GROUP BY。
不可见索引:在 MySQL 8.0 中,索引可以分为“可见”和“不可见”状态。当对索引为“不可见”状态时,它不会被查询优化器所使用。我们可以使用这个特性用于性能调试。如果数据库性能有所下降,说明这个索引是有用的,然后将其置为“可见”状态;如果数据库性能看不出变化,说明这个索引是多余的,可以考虑删掉。
降序索引:MySQL 8.0 为索引提供按降序方式进行排序的支持,在这种索引中的值也会按降序的方式进行排序。
通用表表达式(Common Table Expressions CTE):在复杂的查询中使用嵌入式表时,使用 CTE 使得查询语句更清晰。
UTF-8 编码:从 MySQL 8 开始,使用 utf8mb4 作为 MySQL 的默认字符集。
JSON:MySQL 8 大幅改进了对 JSON 的支持,添加了基于路径查询参数从 JSON 字段中抽取数据的 JSON_EXTRACT() 函数,以及用于将数据分别组合到 JSON 数组和对象中的 JSON_ARRAYAGG() 和 JSON_OBJECTAGG() 聚合函数。
可靠性:InnoDB 现在支持表 DDL 的原子性,也就是 InnoDB 表上的 DDL 也可以实现事务完整性,要么失败回滚,要么成功提交,不至于出现 DDL 时部分成功的问题,此外还支持 crash-safe 特性,元数据存储在单个事务数据字典中。
高可用性(High Availability):InnoDB 集群为您的数据库提供集成的原生 HA 解决方案。
安全性:对 OpenSSL 的改进、新的默认身份验证、SQL 角色、密码强度、授权。
2018年7月2日,MariaDB发布10.3.8版本。
其中重要的新特性有:
1、System-versioned tables系统版本表,有效防止数据丢失,闪回功能升级。
http://dbaplus.cn/news-11-2057-1.html
系统版本表是SQL:2011标准中首次引入的功能。系统版本表存储所有更改的历史数据,而不仅仅是当前时刻有效的数据。举个例子,同一行数据一秒内被更改了10次,那么就会保存10份不同时间的版本数据。就像《源代码》电影里的平行世界理论一样,你可以退回任意时间里。从而有效保障你的数据是安全的,DBA手抖或程序BUG引起的数据丢失,在MariaDB10.3里已成为过去。
2、Instant ADD COLUMN亿级大表毫秒级加字段
加字段是痛苦的,需要对表进行重建,尤其是对亿级别的大表,虽然Online DDL可以避免锁表,但如果在主库上执行耗时30分钟,再复制到从库上执行,主从复制就出现延迟。使用instant ADD COLUMN特性,只需弹下烟灰的时间,字段就加好了,享受MongoDB那样的非结构化存储的灵活方便。
3、Semi-sync plugin半同步复制插件已合并到主服务器中,无需安装。
4、InnoDB引擎版本捆绑甲骨文MySQL 5.7.22。
MariaDB 10.2版本里废弃了Percona XtraDB,详见下面的连接:
https://mariadb.com/kb/en/library/why-does-mariadb-102-use-innodb-instead-of-xtradb/
5、Spider引擎增补腾讯的补丁,目前GA版本为3.3.13。
腾讯游戏DBA团队解决了原Spider引擎许多性能和稳定性问题,以及增加了诸如连接池、全局自增ID、并行查询、查询条件下推等功能特性,将TenDB Cluster的连接池特性、force index下推等功能及几个bug fixed合并到了Spider3.3,详见下面的连接:
http://tencentdba.com/blog/%E7%A4%BE%E5%8C%BA%E5%88%9D%E9%B8%A3%EF%BC%8C%E6%A2%A6%E6%83%B3%E5%A7%8B%E5%85%B4-%E8%85%BE%E8%AE%AF%E6%B8%B8%E6%88%8Fdba%E6%90%BA%E6%89%8Bmariadb%E5%BC%80%E6%BA%90%E8%B5%B7%E8%88%AA/
AlwaysOn可用性组作为SQL Server 2012的新特性被引入,它增强了数据库镜像和故障转移集群技术,提供了高可用和灾难恢复。虽然里面的两个版本是2016、2017年更新的,时间隔得比较久远,但仍有很多人不太清楚这些特性,在这里汇总说明一下2017版本的解读。
AlwaysOn 2017一些新特性和增强:
1、可用性组参数配置:最小提交辅助副本数(REQUIRED_COPIES_TO_COMMIT)
CREATE AVAILABILITY GROUP [ag1] WITH (REQUIRED_COPIES_TO_COMMIT = 1)
让用户来配置在主副本上提交事务前,需要提交事务的最小副本数量。确保事务等待直到事务日志在最小辅助副本上更新。默认值为0,最大值为副本数减去1(相关副本必需为同步提交模式)。通常,如果承载辅助同步副本的 SQL 服务器停止响应,主副本将标记该辅助副本未同步,并且继续。当无响应的数据库重新联机时它将处于“未同步”状态,并且副本将被标记为不正常,直到主可以使其再次同步。如果最小副本数不可用则在主副本上的提交将失败。ALTER AVAILABILITY GROUP支持REQUIRED_COPIES_TO_COMMIT。
2、读取缩放可用性组(Read-scale availability groups)
在 SQL Server 2016 及更早版本中,所有可用性组都需要群集。 群集用于提供业务连续性,实现高可用性和灾难恢复 (HADR)。 此外,配置次要副本以执行读取操作。 如果目标不是高可用性,配置和运行群集消耗了相当大的运营开销。 SQL Server 2017 引入了不需要群集的读取缩放可用性组。
总体来说,该特性只有DR功能,不支持HA。该特性适用于只是为了在多个服务器上部署多个只读副本,分担读取压力。
不同地理位置的解决方案可以使用分布式可用性组实现读取缩放解决方案。 这可用于减轻主要副本、可读次要副本以及靠近读取工作负荷源的站点的读取工作负荷。
3、Linux上的可用性组
在Linux上配置AG基于群集Pacemaker和仲裁Corosync。
4、Linux上的故障转移群集实例
在Linux上配置FCI官方文档还很简陋,从共享存储来看,目前支持iSCSI、NFS和SMB协议。
5、跨平台的可用性组
此配置不支持高可用性,因为没有任何群集解决方案来管理跨平台配置。创建具有 Windows server 上的一个副本和 Linux 服务器上的其他副本始终在可用性组 (AG) 的步骤。此配置是跨平台,因为副本均在不同操作系统上。迁移到另一个平台或灾难恢复 (DR) 使用此配置。
总结:最新版的AlwaysOn可用性组提升了功能性、可扩展性、可管理性,并在高可用和灾难恢复上更加健壮。
5月11日,DB2更新Mod Pack 3 and Fix Pack 3。
包含以下新增特性:
数据库管理方面:
新增支持在列组织表上创建索引(modification state index),在之前版本中,只支持通过主键或唯一约束隐式创建的索引,但在新版本中,可以通过create index命令为列组织表创建索引以提高查询性能。
联邦:
1、在联邦中支持Kerberos认证方式,通过Kerberos认证方式,用户可以不用输入用户名密码直接连接数据库。
2、在对MariaDB的数据类型映射及函数下推提供更好的支持。
3、联邦服务器现在可以通过REST服务接口连接MongoDB。
高可用性:
1、在所有操作系统环境中HADR主节点到备节点间的日志传输支持SSL。
2、归档日志可以通过TSM或者第三方程序配置超时时间,如果DB2到TSM或者第三方备份软件间的日志传输在超过指定的时间仍然失去应答,DB2会中断尝试转而使用本地归档方式。
3、当读取事务日志时,通过自动调整的缓冲IO实现提高大事务的回滚性能,内部测试过程中,可以缩短3倍左右的回滚时间。
4、HADR只读备份数据库中,通过设置DB2_HADR_REPLAY_ONLY_WINDOW_DIAGLEVEL参数或者db2pd –transactions选项可以更方便地发现是什么操作导致的HADR备库进入REPLAY ONLY窗口。
5、HADR环境中,如果在网络传输过程中发生失败,一旦网络修复后,在网络传输过程中的事务日志数据会自动启用无缝重传,无需用户干预。
6、db2haicu可以通过-o选项导出或者备份HA配置。
时钟服务器支持:
如果按照db2时已经配置了Chrony NTP,会自动进行设置。
PostgreSQL 11 beta1发布,包含重大特性:
1、分区表增强:
支持高效分区过滤。
https://github.com/digoal/blog/blob/master/201804/20180424_02.md
支持哈希分区,之前需要通过list分区实现哈希分区。
https://github.com/digoal/blog/blob/master/201802/20180205_02.md
支持跨分区更新。
支持外部分区表,用户可以使用外部分区表实现数据库Sharding。
https://www.postgresql.org/docs/devel/static/postgres-fdw.html
支持分区表按分区并行JOIN,类似MPP操作模式,性能大幅提升。
https://github.com/digoal/blog/blob/master/201802/20180202_02.md
支持分区表按分区并行聚合,类似MPP操作模式,性能大幅提升。
https://github.com/digoal/blog/blob/master/201803/20180322_07.md
2、并行计算增强:
支持并行排序。
支持并行创建索引。
https://github.com/digoal/blog/blob/master/201802/20180204_01.md
支持并行哈希JOIN与哈希聚合使用共享哈希表,大幅度提升性能。
支持UNION与APPEND语句使用并行。
https://github.com/digoal/blog/blob/master/201802/20180204_03.md
支持并行写数据,包括根据QUERY建表,创建物化视图,SELECT INTO等操作。
支持并行协处理,工作进程在工作时,协处理进程主动接收工作进程的结果,提高整体吞吐率。
3、HTAP特性增强:
支持JIT。
https://github.com/digoal/blog/blob/master/201803/20180323_01.md
大量同时COMMIT的并发能力增强。
Postgres_fdw的更新、删除JOIN下推。使得Sharding的性能更高。
2018年6月20日,Greenplum发布5.9版本。
Pivotal的Greenplum是基于MPP架构的数据库产品,它可以满足下一代大数据仓库和大规模的分析任务的需求。通过自动对数据进行分区以及多节点并行执行查询等方式,它使一个包含上百节点的数据库集群运行起来就像单机版本的传统数据库一样简单可靠,同时提供了几十倍甚至上百倍的性能提升。除了传统的SQL,Greenplum还支持MapReduce、文本索引、存储过程等很多分析工具,所支持的数据量可以从上百GB到几百TB。
Greenplum 5.9.0可以从这里下载:
Pivotal Network:https://network.pivotal.io/products
文档在这里:
Pivotal Greenplum Database Documentation:
https://gpdb.docs.pivotal.io/
主页在这里:
Greenplum Database project:http://greenplum.org/
源代码在github:
https://github.com/greenplum-db/gpdb
新特性支持:
gpcopy:Greenplum集群间的高速数据迁移工具
5.9中包含了新的Greenplum数据迁移工具,可以用gpcopy完成以下任务:
通过--full进行全量备份,包括表,索引,视图,用户,资源队列等。
复制指定的表或数据库到目标数据库。
通过--schema-only 只复制元数据。
gpcopy更多的信息可以参考它的文档:
https://gpdb.docs.pivotal.io/590/utility_guide/admin_utilities/gpcopy.html
备份恢复功能的增强
Gprestore可以通过不同的参数恢复如下数据库对象:
metadata-only:只从备份中恢复元数据,表和视图不做恢复。
data-only:只从备份中恢复数据,表需要事先创建好;gprestore不再执行创建表的工作。
jobs:定义同时运行的任务的数目,增加这个参数的大小可以提高备份和恢复的速度。
通过gpbackup和gprestore的--include-table 和--include-table-file 参数,可以同时备份视图和序列。
gpbackup和gprestore的文档可以参考这里:
gpbackup:
https://gpdb.docs.pivotal.io/590/utility_guide/admin_utilities/gpbackup.html
gprestore:
https://gpdb.docs.pivotal.io/590/utility_guide/admin_utilities/gprestore.html
Pl/Container资源管理功能增强
在5.9中,可以通过设置
为资源队列预留CPU资源
Greenplum 5.9中可以通过资源队列预留CPU资源,可以保证将CPU留给特定的查询来保证其查询速度。
NoSQL家族
2018年5月,MongoDB发布4.0版本。其核心的一些新特性包含:
1、多文档事务
结合MongoDB文档模型内嵌数组、文档的支持,目前的单文档事务能满足绝大部分开发者的需求。为了让 MongoDB 能适应更多的应用场景,让开发变得更简单,MongoDB 4.0将支持复制集内部跨一或多个集合的多文档事务,保证针对多个文档的更新的原子性。而在未来的MongoDB 4.2版本,还会支持分片集群的分布式事务。
MongoDB的事务接口非常简单,开发者只需要将「需要保证原子性的更新序列」放到一个session的开始事务与提交事务之间即可。

事务是MongoDB开发团队经过3年多努力的结果,从3.0版本引入WiredTiger、到3.2版本支持ReadConcern、3.6支持Causal Consistency等,很多工作都是在为事务功能做准备,最终在4.0版本将整个事务的API提供给用户,帮助用户更好地构建应用。
2、聚合类型转换
灵活的文档模型是MongoDB相比传统关系型数据库的一大优势,应用开发者无需为存储的数据预先定义结构(或者模式),这使得开发者能快速的应对开发需求的迭代;在灵活的同时,MongoDB还提供了schema validation功能,使得开发者可以根据需要定义文档数据的模型。
MongoDB 4.0引入了新的聚合操作符$convert, 允许用户在aggregation pipeline里将文档的字段转换成统一的类型输出,使得数据消费端,比如MongoDB BI工具、Spark Connectors以及其他ETL工具能更简单的处理MongoDB数据。
3、非阻塞的备节点读
为了确保备节点上的读与主节点保持相同的因果一致性语义,MongoDB备节点在批量应用oplog的时候会阻塞读请求,这使得在高写入负载下,备节点上读的平均延时通常比主节点更高。
借助事务功能中storage engine timestamps and snapshots的实现,引擎层可以很容易的实现「指定时间戳快照读取的功能」,使得备节点上的读请求无需阻塞等待就能读到一致时间点的数据。这个特性将极大地提升MongoDB读扩展的能力。
4、迁移速度提升40%
应用在不断演进过程中,其负载特性也在不断发生变化,这就要求数据库具备扩展的能力,及时适应应用的负载变化。MongoDB分片集群支持实时的添加、移除shard节点,并能在各个shard之间自动迁移数据来均衡负载。
MongoDB 4.0支持在迁移数据的过程中,并发的读取(源端)和写入(目标端),使得迁移的性能提升了约40%,使得新添加的节点能更快地承载业务压力,让分片集群发挥最佳效果。
5、扩展修改订阅
MongoDB 3.6推出了修改订阅(Change Streams)的功能,使得用户能实时的获取数据的修改,同时通过Change Streams还能很方便的实现多数据中心跨复制集的数据同步。MongoDB 4.0进一步扩展Change Streams功能,可以实现分片集群维度的修改订阅。
点击链接可以体验MongoDB 4.0 RC:
https://www.mongodb.com/download-center?_ga=2.40929313.2061101136.1526915320-227146665.1496867788#development
2018年6月1日,Redis 发布5.0 RC1版本,
Redis 5是一个专注于几个重要特性的发行版。不同于Redis 4非常专注于操作,Redis 5的变化大多是面向用户的,在现有的基础上增加新的数据类型和操作类型。
以下是此版本的主要特性:
新的Stream数据类型:
https://redis.io/topics/streams-intro
新的Redis模块API:Timers and Cluster API。
RDB现在存储LFU和LRU信息。
集群管理器从Ruby(redis-trib.rb)移植到C代码——在redis-cli中。通过`redis-cli --cluster help`以了解更多信息。
新的sorted set命令:ZPOPMIN / MAX和阻塞变量。
主动碎片整理V2。
增强HyperLogLog实现。
更好的内存统计报告。
许多带有子命令的命令现在都有一个HELP子命令。
客户端经常连接和断开连接时性能更好。
错误修复和改进。
Jemalloc升级到5.1版。
可以看到,Redis 5.0引入了新的流数据类型,并新增了Redis模块APIs:Timers和Cluster API。
Redis 5.0引入的新流数据类型可参考:
https://redis.io/topics/streams-intro
从4.0版本迁移到5.0版本的注意事项:
Redis 4.0大多是5.0的严格子集,应用程序从4.0升级到5.0通常不会遇到问题。以下是5.0版本中引入的非向后兼容性更改:
redis-cli现在实现了集群管理工具。我们仍然在维护旧的redis-trib,但是新的修复只会在redis-cli中实现。
RDB格式已更改。Redis 5.0能够读取4.0(和所有的过去的版本)文件,反之则不能。
某些日志格式和语句在Redis 5.0中不同。
2018年5月,Neo4j发布3.4版本。
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。
Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下,而不是严格、静态的表中,但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
本季度Neo4j发布了其3.4最新版本,该版本包含的新特性有:
在拥有本地字符串索引的节点上,字符串索引的写入速度现在可提高5倍。
新API内核简化了内部指令。
支持日期/时间格式和三维地理空间数据的新数据类型,从而能够优化Cypher中跨空间和时间的查询。
三维地理空间数据可以搜索笛卡尔纬度和经度坐标,以及径向距离和高度或深度。
得益于多方面效率的改进优化(包括本机索引),事务消耗的内存更少。
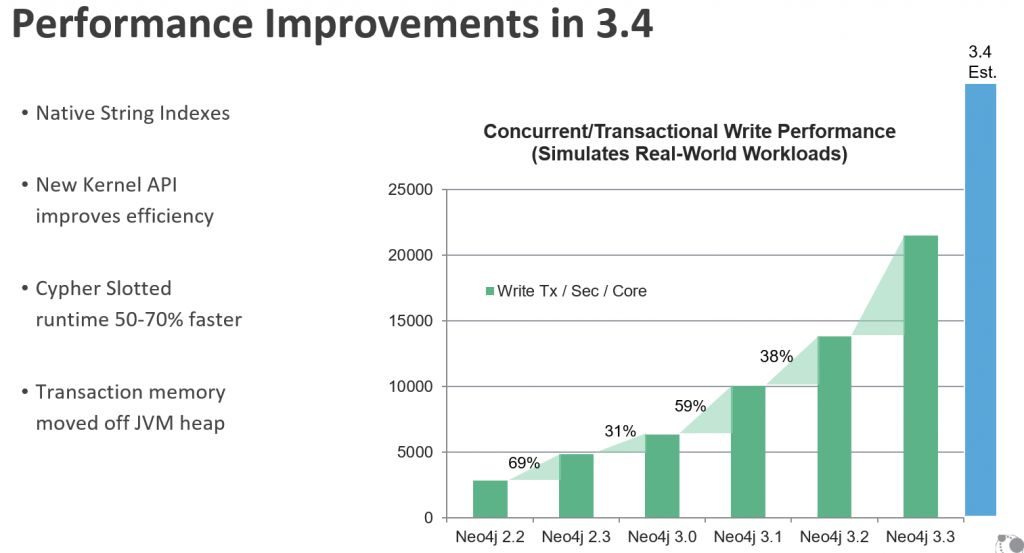
内部测试表明,CYPHER运行时比Neo4j3.3(社区版)快20%。
3.4版本性能提升测试结果:
同时,企业版也进行了多方面的改进:
Multi-Clustering集群极大地拓展了Neo4j扩展可选方案,这样每个租户可以自己灵活扩展集群。通过Multi-Clustering,用户可以对图形进行逻辑分区,或者查看跨企业的图形数据库。
企业版中新的Cypher运行速度比Neo4j3.3快50-70%。
热备的速度现在是之前的两倍,并且可以停止也可以恢复。
在重启或者恢复以后,“ active cache warming”可以自动加载之前操作缓存页,恢复到之前的状态,将服务器恢复到最近一次在线的状态。
新的诊断工具提升了技术支持协作的速度和精度。
滚动升级允许在其他成员稳定并且不重启的情况下进行。
管理员可以对名字进行安全策略设置,并创建用户黑名单。
NewSQL家族
2018年6月29日,TiDB发布2.1 Beta版。
TiDB是一款定位于在线事务处理/在线分析处理(HTAP:Hybrid Transactional Analytical Processing)的融合型数据库产品,模型参考了Google最新的分布式数据库F1/Spanner。除了底层的RocksDB存储引擎之外,分布式SQL层、分布式KV存储引擎(TiKV)完全自主设计和研发。
TiDB完全开源,兼容MySQL协议和语法,可以简单理解为一个可以无限水平扩展的MySQL,并且提供分布式事务、跨节点JOIN、吞吐和存储容量水平扩展、故障自恢复、高可用等优异的特性;对业务没有任何侵入性,简化开发,利于维护和平滑迁移。
TiDB 2.1 Beta Release
相比2.0版本,该版本对系统稳定性、优化器、统计信息以及执行引擎做了很多改进。
TiDB:
1、SQL优化器
优化Index Join选择索引范围,提升执行性能。
优化关联子查询,下推Filter和扩大索引选择范围,部分查询的效率有数量级的提升。
在`UPDATE`, `DELETE`语句中支持Index Hint和Join Hint。
优化器Hint `TIDM_SMJ`在没有索引可用的情况下可生效。
2、SQL执行引擎
实现并行Hash Aggregate算子,部分场景下能提高Hash Aggregate计算性能200%。
实现并行Project算子,部分场景下性能提升达74%。
并发的读取Hash Join的Inner表和Outer表的数据,提升执行性能。
3、Server
添加HTTP API打散table的regions在TiKV集群中的分布。
添加`auto_analyze_ratio`系统变量控制自动analyze的阈值。
4、兼容性
支持更多MySQL语法。
BIT聚合函数支持ALL参数。
支持`SHOW PRIVILEGES`语句。
5、DML
减少`INSERT INTO SELECT`语句的内存占用。
修复Plan Cache的性能问题。
添加`tidb_retry_limit`系统变量控制事务自动重试的次数。
添加`tidb_disable_txn_auto_retry`系统变量控制事务是否自动重试。
6、DDL
优化`Create Table`语句的执行速度。
优化`Add index`的速度,在某些场景下速度大幅提升。
修复`Alter table add column`增加列能超过表的列数限制的问题。
修复在某些异常情况下DDL任务重试导致TiKV压力增加的问题。
修复在某些异常情况下TiDB不断重载Schema信息的问题。
`Show Create Table`不再输出外键相关的内容。
支持`select tidb_is_ddl_owner()`语句,方便判断TiDB是否DDL Owner。
PD:
PD节点间开启raft prevote,避免网络隔离后恢复时产生的重新选举。
优化Balance Scheduler频繁调度小Region的问题。
优化热点调度器,在流量统计信息抖动时适应性更好。
TiKV:
1、功能
使用Rust nightly-2018-06-14版本。
开启PreVote,避免网络隔离后恢复时产生的重新选举。
提供ImportAPI,支持通过lightning快速导入数据。
2、性能
使用Static metric优化多label metric性能(YCSB raw get提升3%)。
去掉多个模块的 Box,使用范型提升运行时性能(YCSB raw get提升3%)。
使用asynchronous log提升写日志性能。
3、稳定性
给Coprocessor decimal增加fuzz测试。
Fix了Coprocessor `do_mul`处理decimal的bug。
更详细的文档请阅读:
https://github.com/pingcap/docs-cn
2018年4月4日,CockroachDB正式发布了2.0版本,在2.0新增了一些企业版特性和开源版特性。
1、企业版特性主要包括:
Table Partitioning:该特性可以帮助用户控制单表数据的地理分布,冷热存储等。
Node Map:该特性是Geo-Partition的Admin UI显示,在Admin UI上会详细显示集群节点全球部署的详细信息。
Role-Based Access Control:该特性可以帮助业务给相应的用户组设置相同权限。
Point-in-time Backup/Restore:数据可以恢复到历史备份中的任意时间点。
2、开源版新增特性:
支持JSON、INET、TIME数据类型。
支持SQL审计。
支持计算列。
支持IMPORT并行导入。
作为2018年初新晋Apache社区顶级项目之一,Apache Trafodion是一款基于Hadoop的,可同时支持事务交易和数据分析(HTAP - Hybrid Transactional and Analytical Processing)的融合型数据库产品。
Trafodion的主要功能包括:
对ANSI SQL的完整支持,使得开发人员完全可以基于现有的SQL技能进行开发。
分布式ACID事务强一致性。
非常成熟的基于成本的SQL优化器,更好地提高OLTP的性能。
并行处理优化器,支持大规模数据集。
集成Apache Spark,支持流式分析。
与Apache Hadoop生态圈中各种工具和方案都可互通,比如Hive、Ambari、Flume、Kafka、Oozie等。
不绑定专门的Hadoop发行版和Linux操作系统,多版本可选。
Trafodion将存储引擎搬到HBase上,更好地集成了Hadoop和HDFS,也获益于很多Hadoop的特性,比如非常好的扩展性。同时,Trafodion也可以无缝地集成原生的HBase、Hive数据。比如用户可以直接在Trafodion中进行HBase、Hive和Trafodion的多表join操作。或者利用Trafodion的SQL接口直接访问存放在Hive和HBase的原生数据,而无需做数据移动和转换。
而Trafodion的与众不同在于,它很好地结合了流行度极高的Hadoop和SQL,并具有HTAP的能力。
关于Trafodion的更多详细介绍,有兴趣可阅读开源的Trafodion如何实现事务与分析一体化?
Trafodion 2.2 Release:
Trafodion的最新版本为R2.2,可在官网下载。
官网:http://trafodion.apache.org
该版本在上一版本基础上加入了以下新功能和新改进:
加强了Trafodion的伸缩性。
在JDBC中支持LOB数据类型。
提高了更新统计信息(UPDATE STATISTICS)对于varchar列的性能。
RMS(Runtime Metrics System)增强。
改进Trafodion中的log4j和log4cxx框架。
将EsgynDB中有关分布式事务管理器的改动放入Trafodion中。
更进一步了解详情,可访问:
http://trafodion.apache.org/release-notes-2-2-0.html
时间序列
本季度InfluxDB 进行了1.5.3和1.5.4两次小版本更新。
InfluxDB是一个使用Go语言编写的开源分布式时序、事件和指标数据库,用于涉及大量时间戳数据的用例的数据存储,包括DevOps监视、应用度量、物联网传感器数据和实时分析。可通过配置InFluxDB来保障计算机上的可用空间,使数据可以保存一定时间,可以设置数据自动过期以便从系统中删除任何不需要的数据。InFluxDB还提供了一种类似SQL的查询语言,用于与数据交互。
我们将这两个更新的小版本合起来,它们功能更新和Bug更新信息汇总后内容如下:
1、功能方面:
添加 debug-pprof-enabled 启动配置项。对于性能问题debug很有用。
添加 influx_inspect 命令,可以用来批量删除TSM裸文件中的度量数据。
2、Bug修复:
修正了多次嵌套调用DISTINCT调用中的验证问题。
返回TOP和BOTTOM的正确辅助值。
修正了readTombstoneV4中的异常。
Buildtsi:保持度量名称不转换。
2018年5月21日, OpenTSDB 发布2.3.1版本。其中包括以下新的功能:
表达式更新:使用时间序列数据查询时间计算,例如将一个指标除以另一个指标。
Graphite样式函数更新:使用Graphite样式函数在查询时对数据进行额外过滤和变异。
基于日历的下采样:提供对公共日历下采样数据的能力。
Bigtable的支持:在使用Google托管的Bigtable云服务中运行TSDB。
Cassandra支持:支持在传统Cassandra集群上运行OpenTSDB。
写过滤器:根据插件或白名单来阻止或允许时间序列或UID分配。
新的聚合器:无返回原始数据。First和Last在下采样期间返回第一个或最后一个数据点。
元数据缓存插件:用于缓存元数据以提高查询性能的新API。
启动插件:用于帮助TSD启动时发现服务的API。
添加JAVA API使用示例。
大数据生态圈
2018年5月,Apache基金会分别公布了三个新的发行版本,分别是3.0.3,2.9.1以及2.8.4。需要特别关注的,这次的版本是由来自腾讯云产品部大数据及人工智能产品中心的专家研究员堵俊平主导发布的,这也是第一次由中国的技术团队主导大数据版本的发布。
1、3.0.3版本
总共修复并改进了自3.0.2版本以来的总共249个Bug与功能:
http://hadoop.apache.org/docs/r3.0.3/hadoop-project-dist/hadoop-common/release/3.0.3/CHANGES.3.0.3.html
主要变更如下:
HDFS-13099
修改默认的state store的存储方式,从本地文件更改为Zookeeper,定义次参数需要配置zookeeper的连接地址。
2、2.9.1版本
总共修复并改进了自2.9.0版本以来的总共208个Bug与功能。
主要内容如下:
HADOOP-12756,HADOOP-14964,HADOOP-15027
这三个JIRA主要针对的是阿里云OSS的适配及一些优化,阿里云OSS在中国拥有大量的云计算的用户,通过对OSS的适配,进一步增强了Hadoop文件系统的兼容性。
HDFS-12883,HDFS-13083
修复了文档的一些错误标注。
HDFS-12895
挂载表支持ACL,普通用户不能修改他们自身的映射条目,超级用户可以修改所有的映射的条目。
3、2.8.4版本
总共修复并改进了自2.8.3版本以来的总共77个Bug与功能:
http://hadoop.apache.org/docs/r2.8.4/hadoop-project-dist/hadoop-common/release/2.8.4/CHANGES.2.8.4.html
2018年5月25日Apache Flink 正式发布1.5.0 版本。
新版本主要包含以下几项重大特性更新:
重新设计并实现了 Flink 的大部分处理模型。
对广播状态的支持(即在某个函数的所有并行实例中复制状态)是一直广受开发者期待的特性。
改进网络栈带来吞吐量提升和低延迟。
任务本地状态恢复。
扩展对 SQL 和表API Join 的支持。
SQL CLI 客户端提供了对数据流的进行探索性查询。
详细发布文档见:
http://flink.apache.org/news/2018/05/25/release-1.5.0.html
完整changelog:
https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12341764&projectId=12315522
随着Ignite的增长,社区对Ignite的发现机制进行重新审视,看它对扩展性有多大的影响,目标很明确,Ignite要扩展至上千个节点,就像目前上百个节点的时候一样。
这项工作花费了几个月的时间,很高兴地告诉大家,Ignite的2.5版本可以轻易地缩放到上千个节点,同时还具有强大的功能,下面看几个关键点:
Apache Ignite 和 ZooKeeper结合。
机器学习:基于分区的数据集。
遗传算法。
持续地自愈和一致性检查。
SQL:安全性和更快的数据加载。
Spark DataFrame查询直接执行。
DEB 和 RPM 包支持。
详细发布文档见:
https://blogs.apache.org/ignite/entry/apache-ignite-2-5-scaling
Apache Beam 2.3.0发布,这个版本包括多处修复与新功能,新特性与改进如下:
Beam迁移至Java8。
Spark Runner现已基于Spark2.x。
支持AWS云计算服务的S3文件系统。
通用的写文件的API。
在python SDK上支持可拆分的DoFn。
可移植性。
详细发布文档见:
https://issues.apache.org/jira/secure/ReleaseNote.jspa?projectId=12319527&version=12341608
发布Blog:
https://beam.apache.org/blog/2018/02/19/beam-2.3.0.html
2018年6月13日,ElasticSearch 6.3.30正式发布,该版本包含以下重要改进:
x-pack包含在默认安装包中,这很平淡是不是,惊喜在于x-pack中已经包含了对SQL的支持,无须任何第三方插件,可以直接写SQL查询ElasticSearch中的数据了;
除了贴心的SQL, 6.3中支持rollup,通过预先定义的rollup函数,可以近实时返回统计结果,如过去5分钟中的均值,最大值,最小值等等;
开始支持Java 10。
英文release notes:
https://www.elastic.co/blog/Elasticsearch-6-3-0-released
国产数据库概览
浪潮K-DB 11g提供基于共享存储的双活/多活动态集群技术,集群内所有数据库节点都可以进行数据读写处理,并且采用缓冲融合、全局锁管理等机制,真正实现了Oracle RAC集群功能。经过国内多家大型客户实际使用验证,一致评价K-DB 11g数据库是除Oracle之外唯一能实现RAC集群的企业级数据库管理系统。
K-RAC(K-DB Active Cluster)技术作为稳定性和高可用性的解决方案,能确保系统在发生各种故障时提供不中断的服务,同时水平添加数据库节点时能够准线性的提升集群处理性能。
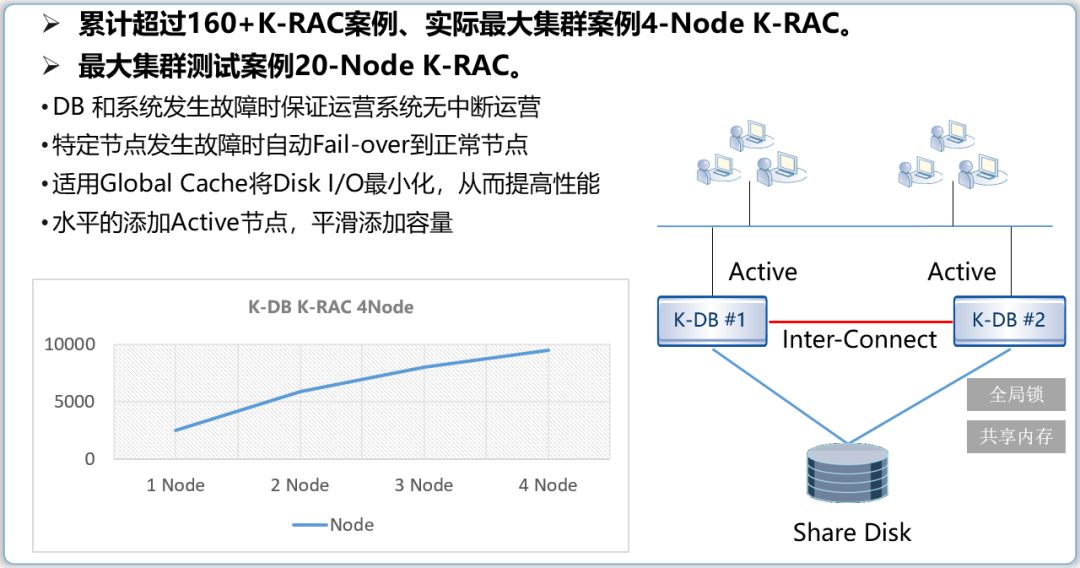
推出类似于Oracle ASM的存储虚拟化功能KAS(K-DB Active Storage)。
KAS存储虚拟化,支持多副本镜像、条带化、再均衡分布等多个特性。
支持Online DDL功能。
在线修改DDL时,DML操作不受限制。
支持DD Wlock Free。
执行查询时,即使未捕获到对DD(Data Dictionary)的ObjectLock,整合性也不会发生问题,并且改善了执行Query时的性能。
支持Listener Multi-port。
支持动态指定多个访问K-DB数据库的监听端口。
EsgynDB,即易鲸捷数据库,是由易鲸捷信息技术有限公司研发,具有自主知识产权,基于开源的Apache Trafodion的企业级数据库,核心研发人员同时也是Trafodion的主要贡献者。
该产品与Trafodion一样,是SQL-on-Hadoop且可同时兼顾事务和分析的HTAP数据库。不仅能针对大数据应用场景提供大规模并行SQL处理能力,同时其先进的分布式事务还能解决传统数据库在事务处理方面扩展性弱的问题。
作为一款通用的国产数据库技术,EsgynDB兼容标准的ANSI SQL语法,让客户原有基于传统数据库开发的应用系统无缝迁移到EsgynDB,降低企业对系统移植的转化成本,同时让客户的现有的数据库开发人员通过SQL就可以使用Hadoop的技术能力,加速Hadoop应用项目的落地。
作为一款企业级数据库,和开源的Trafodion区别在于以下企业级功能、支持和服务:
可在云平台上使用的多租户功能。
强大的数据库管理监控工具DB Manager。
开源版支持ODBC、JDBC同时,增加了对于ADO.NET驱动的支持。
企业级数据库迁移工具,可以方便地将传统关系型数据库如Oracle、SQL Server、MySQL等迁移到EsgynDB。
多数据中心的支持。
基于时间点的数据恢复。
对ORC格式的支持。
通过UDF对Hadoop生态圈各种工具的集成。
更多数据安全方便的特性。
更多扩展的SQL分析函数等。
在最新发布的V2.4版本中,EsgynDB在基础架构、高可用、易用性、安全性方面加入了以下新功能和新改进:
支持Apache Parquet列式存储。
支持通过Cloudera Manager安装EsgynDB。
支持Linux keepalived,提升数据库连接的高可用性。
Windows ODBC驱动支持在ODBC DSN中存储用户ID和密码。
支持对Trafodion表进行增量备份和恢复。
EsgynDB支持查看Hive对象。
支持Region事务。
支持PL/SQL。
支持多城活动目录/LDAP。
易用的数据库开发工具DB Designer发布。
2018年5月10日,OceanBase 1.4.71版本新增功能,可在官网直接下载OceanBase V.1.4安装包。
官网:https://oceanbase.alipay.com
新增功能包括:
支持实例规格扩容和缩容。
ObProxy管理模块发布。
支持租户级别性能监控展示。
支持sys租户性能监控展示。
权限控制模块发布。
Docker管理模块发布。
移动端告警屏蔽功能发布。
资源池管理模块发布。
增加磁盘使用率到70%后进行报警。
支持单实例多租户的实例创建。
支持在指定位置新增列(add column before/after)功能。
支持基本的外键(Foreign key)功能。
支持基本的大对象(Lob)功能。
SequoiaDB巨杉数据库3.0在产品GA发布后,经过近半年在金融级场景的测试、上线和稳定运行之后,于近期正式发布。
1、SequoiaDB 3.0产品定位
SequoiaDB巨杉数据库是一款金融级分布式数据库,包括了分布式NewSQL、分布式文件系统与对象存储、与高性能NoSQL三种存储模式,分别对应分布式在线交易、非结构化数据和内容管理以及海量数据管理和高性能访问场景。
根据Gartner的数据库报告,Multi-model多模是未来10年,下一代分布式数据库发展的最主要方向。从1.0的高性能分布式 NoSQL数据库,到2.0加入的分布式对象存储,再到3.0完整协议级兼容MySQL,SequoiaDB经过6年的不断迭代创新,全面支持企业级结构化、半结构化以及非结构化数据存储。
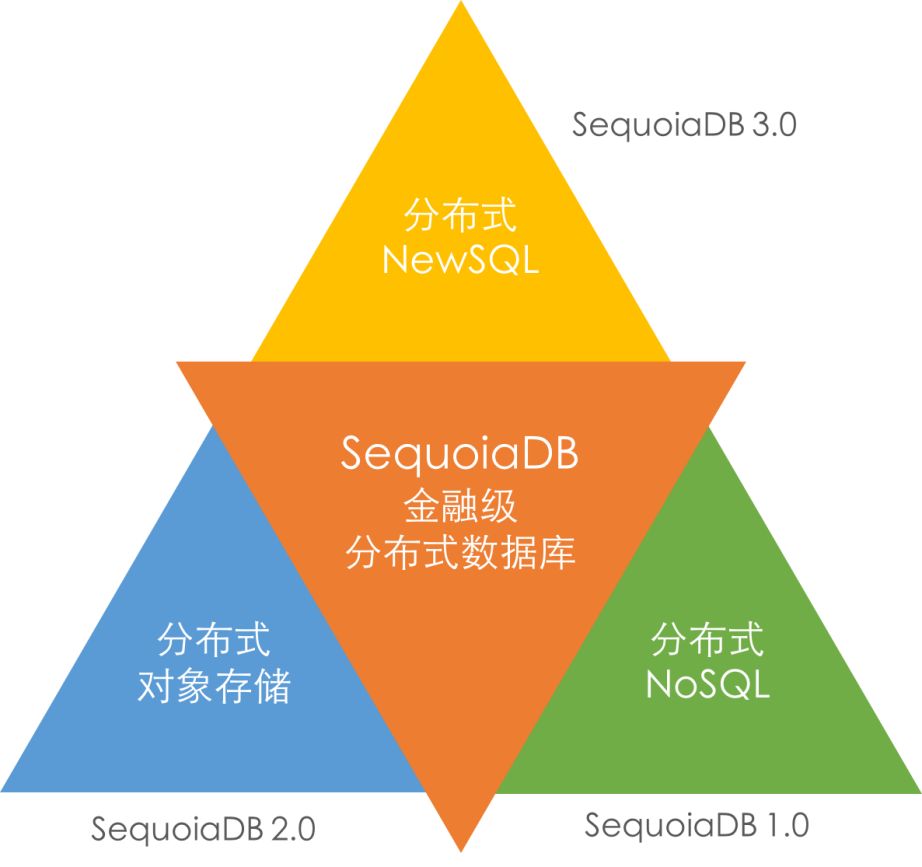
SequoiaDB 3.0产品维度
2、MySQL完整协议级兼容
SequoiaDB 3.0实现了100%的MySQL协议级兼容:
全面兼容:全面支持MySQL协议与语法,用户可以直接使用MySQL客户端或任何管理、开发与监控工具对数据库进行操作。
MySQL语法:由于使用了MySQL原生的解析器,SequoiaDB 3.0 能够实现100%的MySQL语法兼容,支持语法包括基础CRUD操作、多表关联、跨节点事务操作、创建视图、存储过程、索引和访问计划等。
无缝切换:对于任何已有应用程序,SequoiaDB 3.0提供全面的MySQL兼容,几乎无需应用程序代码调整,即可无缝切换。
分布式弹性扩展:通过SequoiaDB存储引擎原生分布式架构,数据库在兼容MySQL同时,无需“分库分表”,分布式存储引擎直接提供弹性容量扩展能力,可以上百倍提升应用程序的存储空间与访问性能。
表多维分区:通过存储-SQL分离架构,用户访问MySQL也可以实现表的多维分区,提升应用的灵活性。

SequoiaDB 3.0 MySQL 兼容架构
SequoiaDB 3.0采用了“存储-SQL 分离”的架构,类似架构也出现在AWS的Aurora数据库等众多新一代分布式数据库上。
SequoiaDB 3.0使用了MySQL数据库原生的SQL解析器,天然支持MySQL协议并可以做到100%语法兼容。在该架构中,MySQL协议解析层作为SQL解析和分发的角色,直接面对应用程序,每一个MySQL服务的接入节点都是一个独立支持读写操作的MySQL进程。
而数据存储和管理层,则完全由巨杉数据库的分布式数据库引擎实现。简单来说,SequoiaDB 3.0作为MySQL的InnoDB替换引擎,在天然支持MySQL的全部语法和功能的同时,提供了数据库存储层弹性扩张的能力。
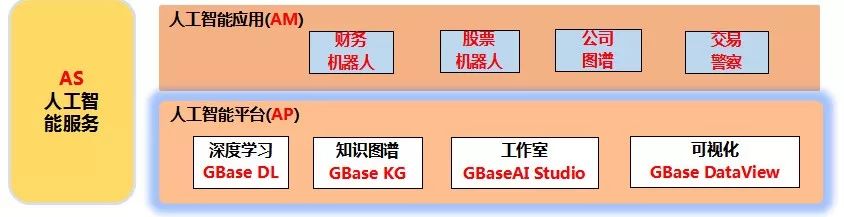
2018年,GBASE发布GBase AI,这是一款基于大数据平台的可视化的人工智能和深度学习工具。通过高效的in-database大数据分析技术,实现海量数据分布式并行计算的高性能AI分析。GBase AI人工智能平台定义了场景化人工智能模型,并基于全数据挖掘,最大化激发企业数据价值。
主要特点:
定义场景化人工智能模型:内置了多个可直接使用的行业主流场景的人工智能模型,如财务异常分析模型、用户画像模型等,大大降低用户通过AI技术进行大数据分析的使用门槛,减少工作量。
操作简单,拖拽定义算法:提供图形化的工作方式。通过拖拽方式就可以在画布上设计机器学习模型,并图形化显示模型和挖掘结果。对于用户来说,应用非常简单,可以将更多的精力投入业务中。
复杂算法实现支撑前台应用:支持全面的人工智能算法,包括机器学习、深度学习、图分析以及数据准备和结果评估等算法。同时支持用多种语言自定义算法来扩充AI算法能力。
全数据挖掘激发数据价值:人工智能平台能够激发数据价值的关键在于与全数据平台GBase UP的无缝对接,用强大的挖掘算法在全数据中进行挖掘。
平台架构图:
推出DBAplus Newsletter的想法
DBAplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、时间序列、大数据生态圈、国产数据库等几个版块。从下期开始,我们还会考虑添加云数据库的章节,希望能够给大家带来新的视角。
我们不以商业宣传为目的,不接受任何商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎大家监督指正。
至于Newsletter发布的周期,目前计划是每三个月左右会做一次跟进,下期计划时间是2018年10月14日~10月25日,如果有相关的信息提供请发送至邮箱:newsletter@dbaplus.cn
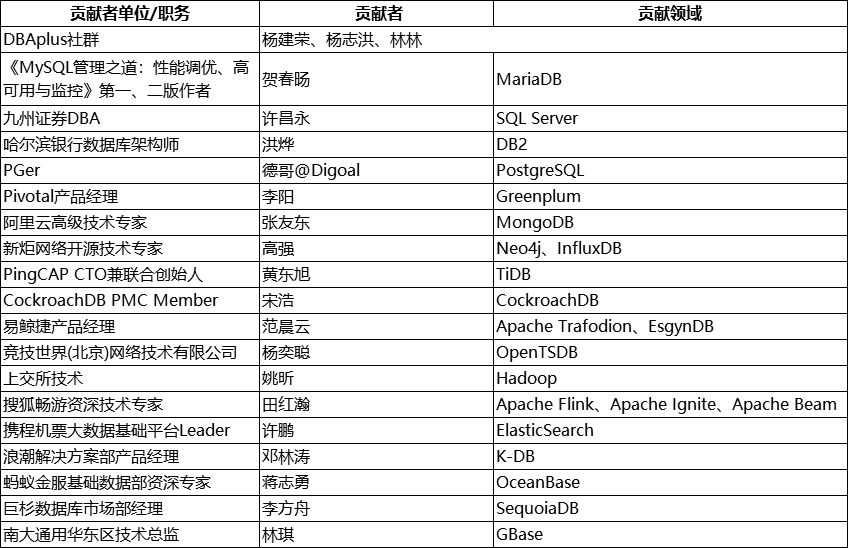
感谢名单
最后要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。
欢迎提供Newsletter信息
发送至邮箱:newsletter@dbaplus.cn
欢迎技术文章投稿
发送至邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721