
1个SQL干崩核心系统长达12小时!分享一下这次的故障排查过程。
大周末的接到项目组的电话,反馈应用从凌晨4点开始持续卡顿,起初并未关注,到下午2点左右,核心系统是彻底干绷了,远程接入后发现,数据库后台有大量的异常等待事件
enq:TX -index contentioncursor: pin S wait on Xdirect path read通过监控发现服务器IO和CPU使用率已经高达90%整个数据库算是夯住了!根据经验判断应该是性能的问题
1、AWR分析
对于这种性能的问题,首先采集到AWR报告并结合ASH报告分析一下
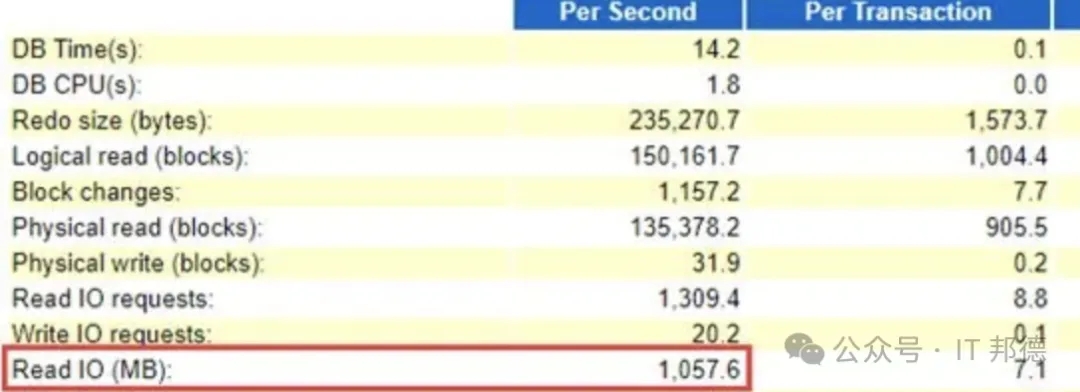
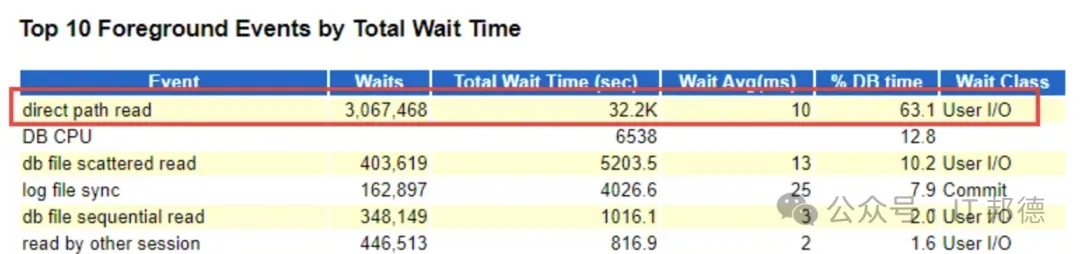
Direct path read事件尽然排到了第一位!占DB time高达63%,这个等待事件是让一些不常使用的大表数据(冷数据),在全表扫描时,每次都从磁盘读到用户的私有内存(PGA),而不要去挤占有限的、宝贵的、频繁使用的数据(热数据)所在的共享内存(SGA-buffer cache)。
2、定位异常SQL
对该TOP SQL分析发现,sql执行频繁,怀疑是执行计划发生变化,如果不把导致问题的根本原因找到,那么很有可能下次还会再发生!
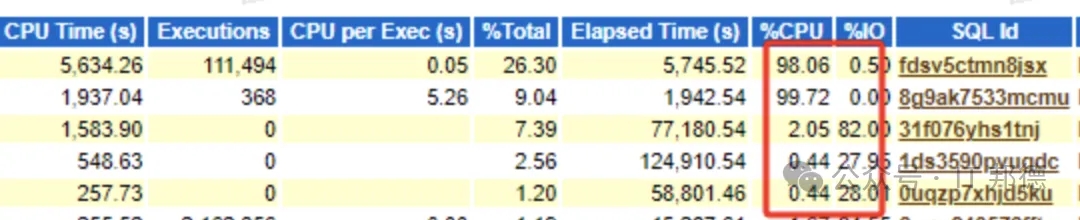
3、分析执行计划
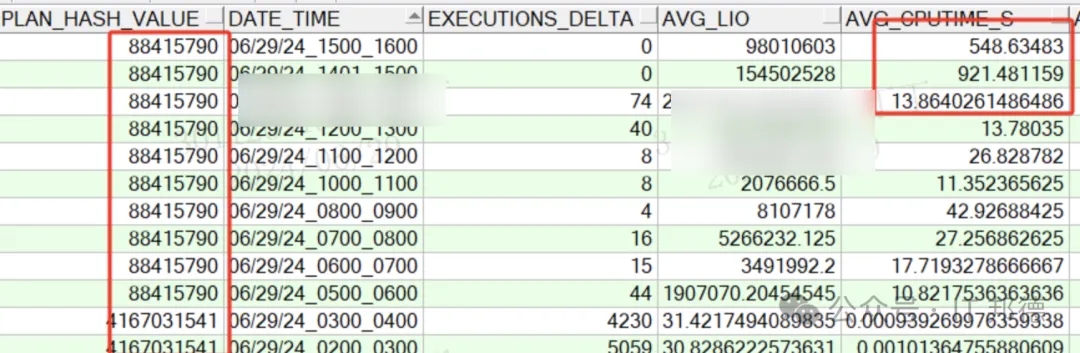
通过定位SQL Id,我们去看内存中的执行计划,明显看到了执行计划发生了变化,全表扫占用大量的IO,这里查看执行计划的方法很多。
--该方法是从共享池得到如果SQL已被age out出share pool,则查找不到select * from table(dbms_xplan.display_cursor('&sql_id',null,'typical'));--该方法是通过awr中得到select * from table(dbms_xplan.display_awr('&sql_id'));
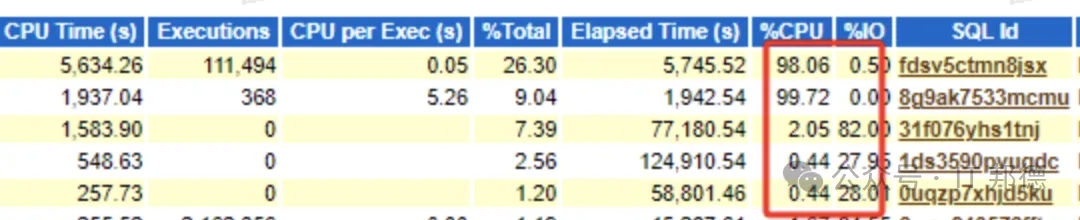
此时再追踪历史的执行计划发现,从凌晨故障发生开始,执行计划就发生了变化,SQL执行耗费到CPU的平均时间高达上百秒,历史执行计划再次验证了我的判断!
4、故障定位
跟业务确认得知,在凌晨业务人员发现,存储空间不够,删除了分区的来释放空间,此处相当于对表结构做了修改,执行计划发生了变化,再加上故障SQL的对应分区,统计信息一直未收集导致这次执行计划发生改变!
1.定位到SQL的内存地址,从内存中刷出执行计划select address,hash_value,executions,parse_callsfrom v$sqlarea wheresql_id='4ca86dg34xg62';--刷出内存exec sys.dbms_shared_pool.purge('C000000A4C502F40,4103674309','C');2.收集分区统计信息BEGIN-- 为整个表加上统计信息(包括所有分区)DBMS_STATS.GATHER_TABLE_STATS(ownname => 'YOUR_SCHEMA', -- 替换为你的模式名tabname => 'YOUR_PARTITIONED_TABLE', -- 替换为你的分区表名cascade => TRUE, -- 收集所有分区的统计信息estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE, -- 自动估算采样百分比method_opt => 'FOR ALL COLUMNS SIZE AUTO', -- 为所有列自动决定采样大小degree => DBMS_STATS.DEFAULT_DEGREE -- 使用默认并行度);END;/
此时我们再次查看执行计划,正确了!
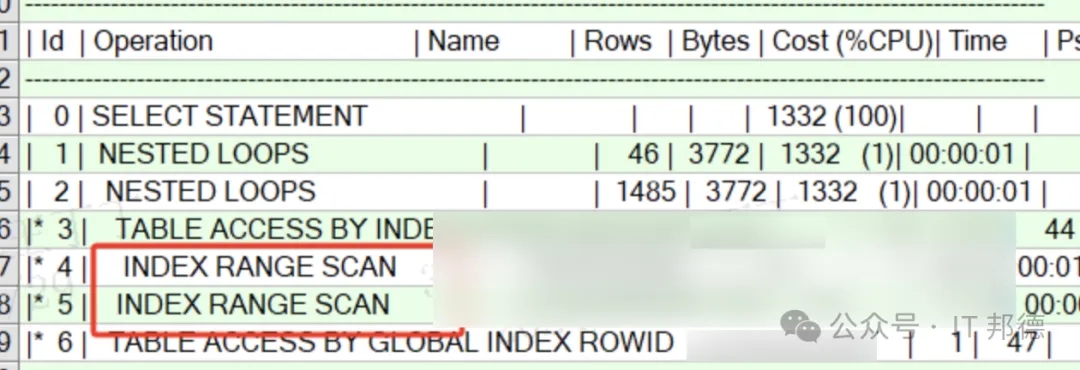
分区索引的失效,会引起执行计划的改变1.TRUNCATE、DROP 操作可以导致该分区表的全局索引失效,而分区索引依然有效,如果操作的分区没有数据,那么不会影响索引的状态。需要注意的是,对分区表的 ADD 操作对分区索引和全局索引没有影响。2.如果执行 SPLIT 的目标分区含有数据,那么在执行 SPLIT 操作后,全局索引和分区索引都会被被置为 UNUSABLE。如果执行 SPLIT 的目标分区没有数据,那么不会影响索引的状态。3.对分区表执行 MOVE 操作后,全局索引和分区索引都会被置于无效状态。4.对于分区表而言,除了 ADD 操作之外,TRUNCATE、DROP、EXCHANGE 和 SPLIT操作均会导致全局索引失效,但是可以加上 UPDATE GLOBAL INDEXES 子句让全局索引不失效。
在 12C 之前的版本,对分区表进行删除分区或者 TRUNCATE 分区,合并或者分裂分区MOVE 分区等 DDL 操作时,分区表上的全局索引会失效,通常要加上 UPDATE GLOBAIINDEXES 或者 ONLINE 关键字,可是加上这些关键字之后,本来很快的 DDL 操作可能就要花费很长的时间,而且还要面临锁的问题。“
Oracle 12C推出了分区表全局索引异步维护特性这个特性有效的解决了这个问题,在对分区表进行上述 DDL 操作时,既能快速完成操作,也能保证全局索引有效,然后通过调度JOB 在固定的时候对全局索引进行维护。
警惕Oracle数据库性能“隐形杀手”——Direct Path Read,如果不把导致问题的根本原因找到,那么很有可能下次还会再发生!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721