
一、为什么要做这个事情
这里指的是MySQL慢查询,具体指运行时间超过long_query_time值的SQL。
我们常听常见的MySQL中有二进制日志binlog、中继日志relaylog、重做回滚日志redolog、undolog等。针对慢查询,还有一种慢查询日志slowlog,用来记录在MySQL中响应时间超过阀值的语句。
大家不要被慢查询这个名字误导,以为慢查询日志只会记录select语句,其实也会记录执行时间超过了long_query_time设定的阈值的insert、update等DML语句。
# 查看慢SQL是否开启
show variables like "slow_query_log%";
# 查看慢查询设定的阈值 单位:秒
show variables like "long_query_time";
对于我们使用的AliSQL-X-Cluster即XDB来说,默认慢查询是开启的,long_query_time设置为1秒。
真实的慢SQL往往会伴随着大量的行扫描、临时文件排序或者频繁的磁盘flush,直接影响就是磁盘IO升高,正常SQL也变为了慢SQL,大面积执行超时。
去年双11后,针对技术侧暴露的问题,菜鸟CTO线推出多个专项治理,CTO-D各领一项作为sponsor,我所在的大团队负责慢SQL治理这个专项。
二、要做到什么程度
1)微平均
sum(aone应用慢SQL执行次数)
-----------------------
sum(aone应用SQL执行次数)
我们认为,该值越大,影响越大;该值越小,影响可能小。
极端情况就是应用里每次执行的SQL全是慢SQL,该值为1;应用里每次执行的SQL全不是慢SQL,该值为0。
但是这个指标带来的问题是区分度不佳,尤其是对SQL QPS很高且大多数情况下SQL都不是慢查询的情况,偶发的慢SQL会被淹没。
另外一个问题,偶发的慢SQL是真的慢SQL吗?我们遇到很多被慢查询日志记录的SQL,实际上可能受到其他慢SQL影响、MySQL磁盘抖动、优化器选择等原因使得常规查询下表现显然不是慢SQL的变成了慢SQL。
2)宏平均
sum(慢SQL 1执行次数) sum(慢SQL n执行次数)
----------------- + ------------------
sum(SQL 1执行次数) sum(SQL n执行次数)
---------------------------------------
n
这个算法建立在被抓到的慢SQL有一定执行次数的基础上,可以减少假性慢SQL的影响。
当某些应用QPS很低,即一天执行SQL的次数很少,如果碰到假性SQL就会引起统计误差。
3)执行次数
sum(aone应用慢SQL执行次数)
-----------------------
7
统计最近一周平均每天的慢SQL执行次数,可以消除掉宏平均带来的假性SQL问题。
4)慢SQL模板数量
以上维度均有个时间限定范围,为了追溯慢SQL历史处理情况,我们还引入了全局慢SQL模板数量维度。
count(distinct(aone应用慢SQL模板) )
核心应用:解决掉所有的慢SQL
普通应用:微平均指标下降50%
以CTO-D为单位根据以上多维度指标统计汇总应用的加权平均,由低到高得出排名,突出头尾top3,每周播报。
三、为什么由我来做
猜测可能与我的背景有关,有C/C++背景,曾在上家公司负责过公司层面异地多活架构的设计和落地,对于MySQL比较了解一些。
另外可能是利益无关,我所在小团队业务刚起步,不存在慢SQL,这样可以插入到各个业务线去。
四、行动支撑
索引规约摘录部分:
①【强制】超过三个表禁止join。需要join的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表join也要注意表索引、SQL性能。
②【强制】在varchar字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会高达90%以上,可以使用count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
③【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明:索引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
④【推荐】防止因字段类型不同造成的隐式转换,导致索引失效。
⑤【参考】创建索引时避免有如下极端误解:
索引宁滥勿缺
认为一个查询就需要建一个索引。
吝啬索引的创建
认为索引会消耗空间、严重拖慢更新和新增速度。
抵制唯一索引
认为唯一索引一律需要在应用层通过“先查后插”方式解决。
DDL需要控制变更速度,注意灰度和并发控制,变更发布需要在规定的变更发布窗口内。
五、一些我参与优化的例子
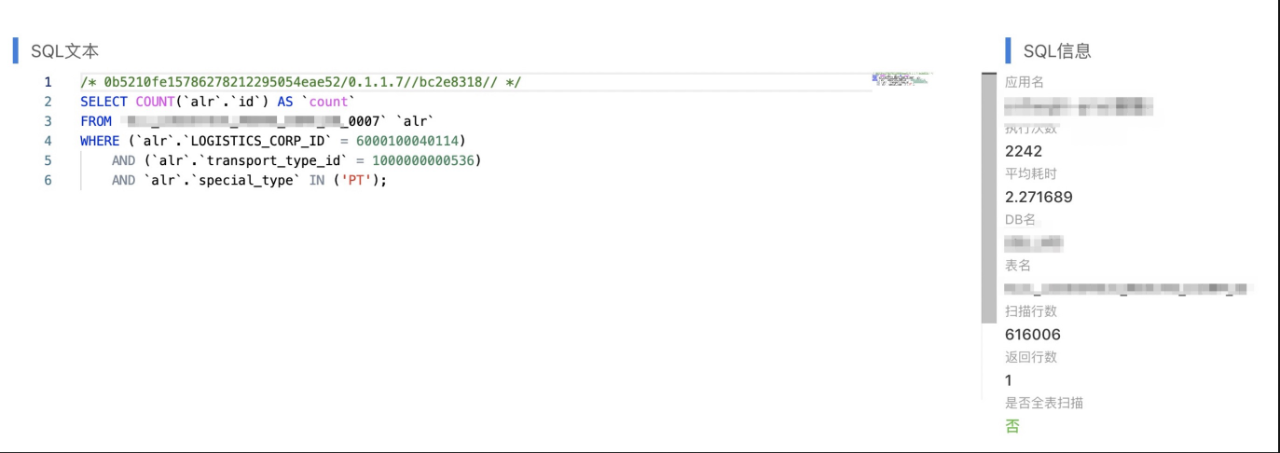
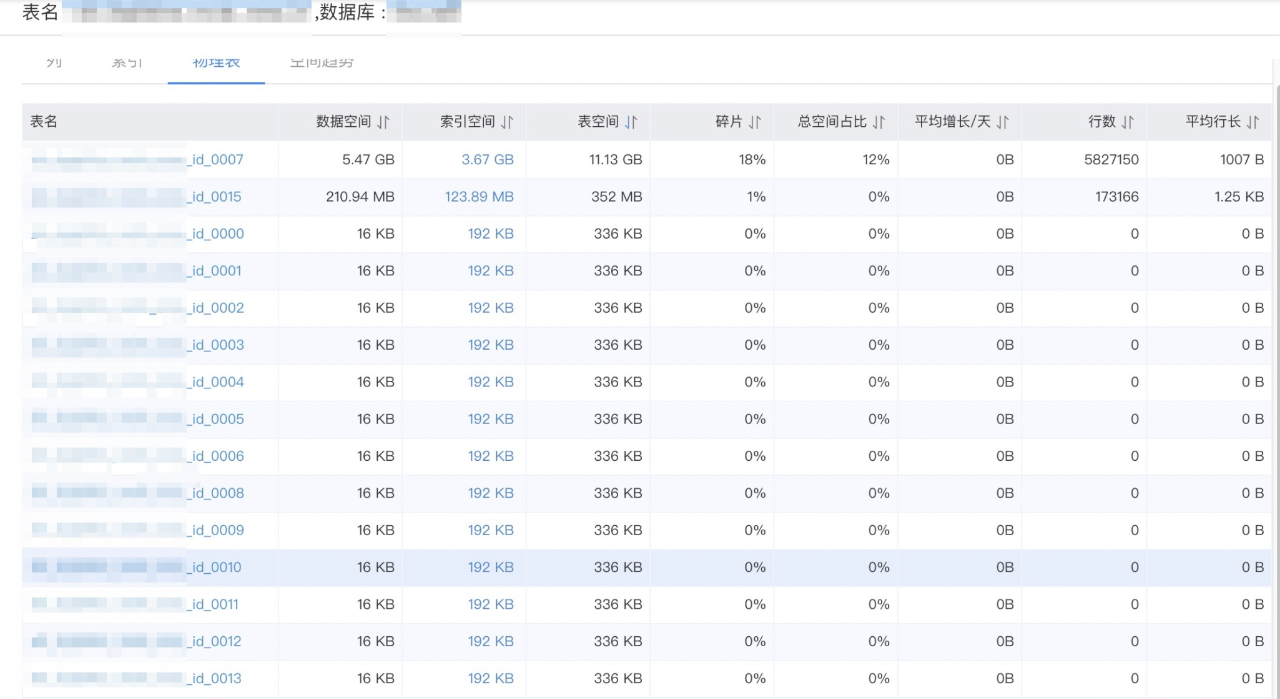
1)分库分表不合理
该业务数据分了8个库,每个库分了16张表,通过查看表空间可以看到数据几乎都分布在各个库的某2张表中。分库分表的策略有问题,另外过高预估了业务增量,这个持保留意见。
2)索引不合理
单表创建了idx_logistics_corp_id_special_id的联合索引,但即便这样区分度依然太低,根据实验及业务反馈(logistics_corp_id,transport_type_id)字段组合区分度非常高,且业务存在transport_type_id的单查场景。
SELECT
COUNT(0) AS `tmp_count`
FROM(
SELECT
`table_holder`.`user_id`,
`table_holder`.`sc_item_id`,
SUM(
CASE
`table_holder`.`inventory_type`
WHEN 1 THEN `table_holder`.`quantity`
ELSE 0
END
) AS `saleable_quantity`,
SUM(
CASE
`table_holder`.`inventory_type`
WHEN 1 THEN `table_holder`.`lock_quantity`
ELSE 0
END
) AS `saleable_lock_quantity`,
SUM(
CASE
`table_holder`.`inventory_type`
WHEN 401 THEN `table_holder`.`quantity`
ELSE 0
END
) AS `transfer_on_way_quantity`,
`table_holder`.`store_code`,
MAX(`table_holder`.`gmt_modified`) AS `gmt_modified`
FROM
`table_holder`
WHERE(`table_holder`.`is_deleted` = 0)
AND(`table_holder`.`quantity` > 0)
AND `table_holder`.`user_id` IN(3405569954)
AND `table_holder`.`store_code` IN('ZJJHBHYTJJ0001', '...1000多个')
GROUP BY
`table_holder`.`user_id`,
`table_holder`.`sc_item_id`
ORDER BY
`table_holder`.`user_id` ASC,
`table_holder`.`sc_item_id` ASC
) `a`;
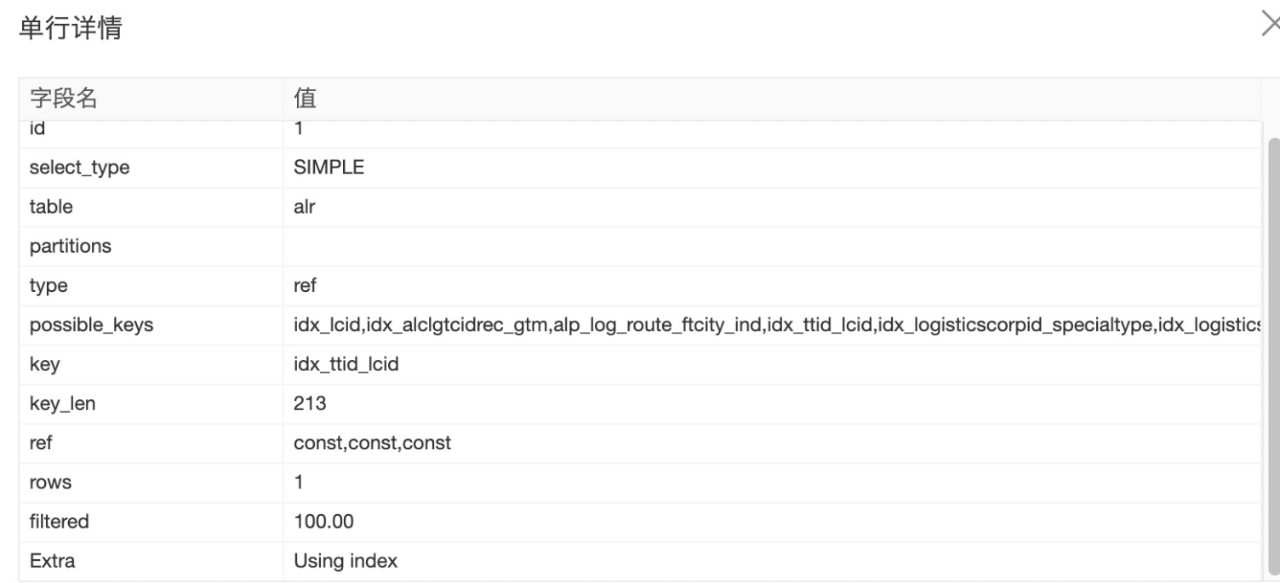
这个case对应的表有store_code索引,因此认为没问题,没办法优化了。实则通过执行计划,我们发现MySQL选择了全表扫描。针对该case实践发现,当范围查询的个数超过200个时,索引优化器将不再使用该字段索引。
最终经过拉取最近一段时间的相关查询SQL,结合业务的数据分布,我们发现采用(is_deleted,quantity)即可解决。
判断执行计划采用的索引长度:key_len的长度计算公式(>=5.6.4)
char(10)允许NULL = 10 * ( character set:utf8mb4=4,utf8=3,gbk=2,latin1=1) + 1(NULL)
char(10)不允许NULL = 10 * ( character set:utf8mb4=4,utf8=3,gbk=2,latin1=1)
varchr(10)允许NULL = 10 * ( character set:utf8mb4=4,utf8=3,gbk=2,latin1=1) + 1(NULL) + 2(变长字段)
varchr(10)不允许NULL = 10 * ( character set:utf8mb4=4,utf8=3,gbk=2,latin1=1) + 2(变长字段)
int允许NULL = 4 + 1(NULL)
int不允许NULL = 4
timestamp允许NULL = 4 + 1(NULL)
timestamp不允许NULL = 4
datatime允许NULL = 5 + 1(NULL)
datatime不允许NULL = 5
用到了索引却依然被爆出扫描2千万行:
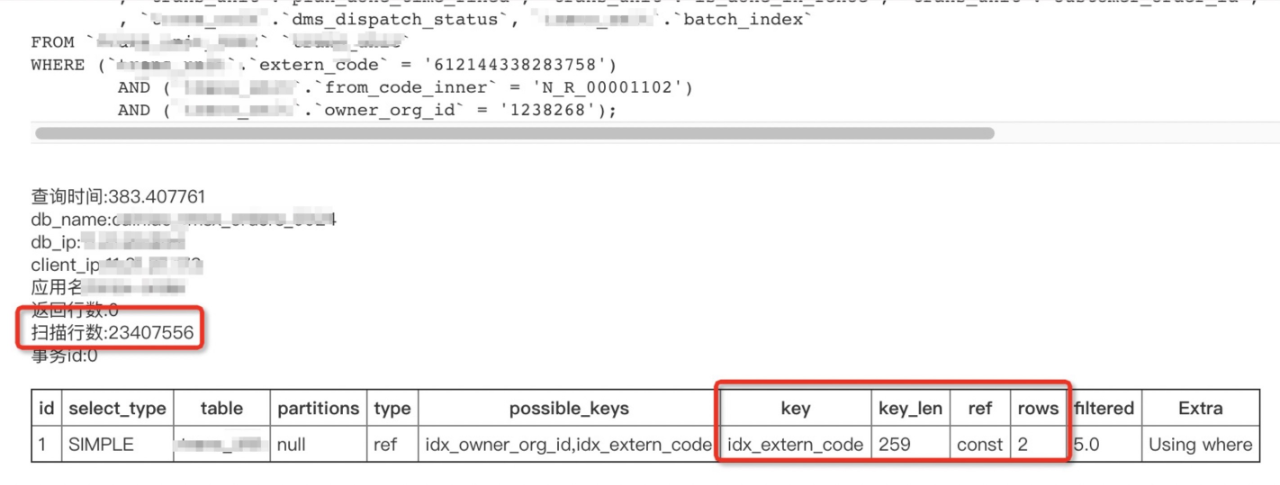
索引字段区分度很高:
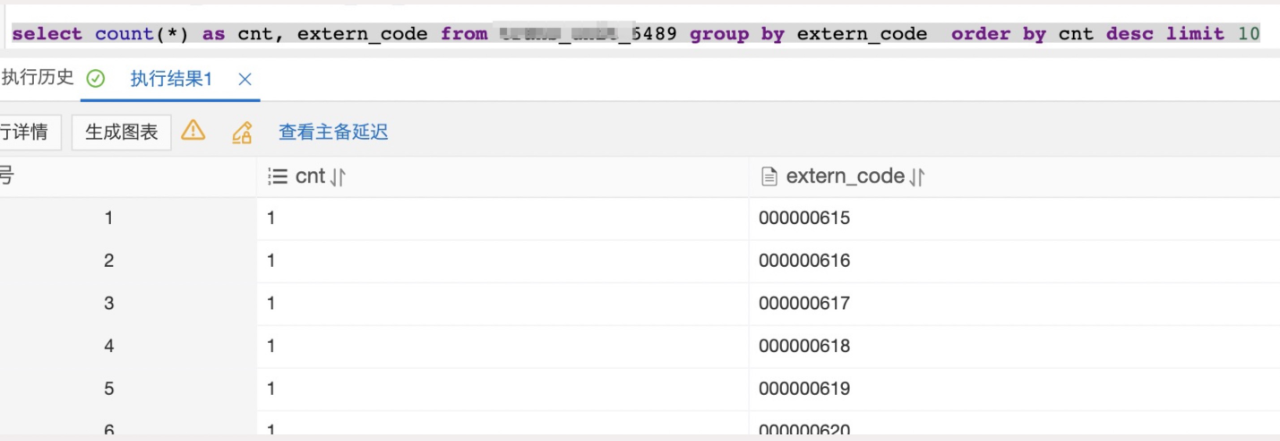
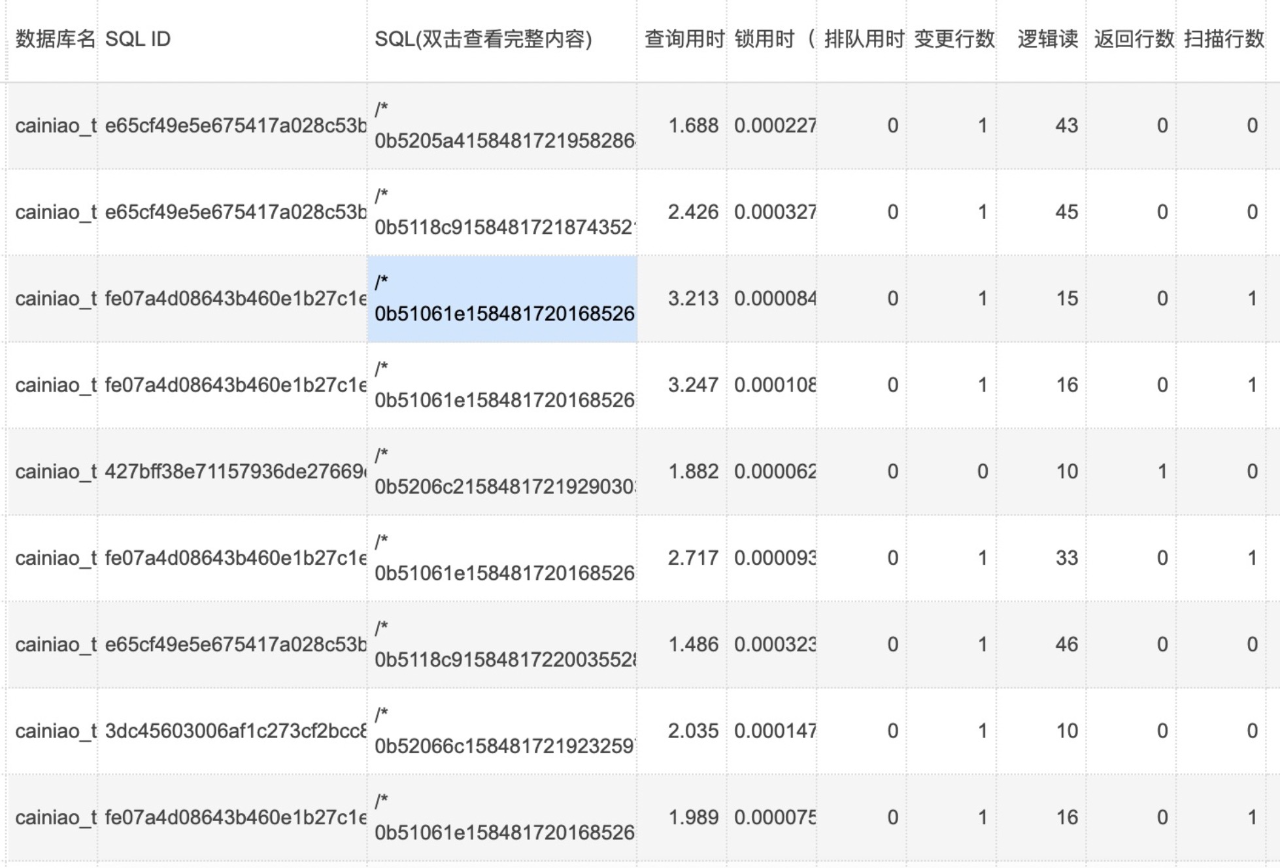
同时期常规SQL变为了慢查询:
DB数据盘访问情况:
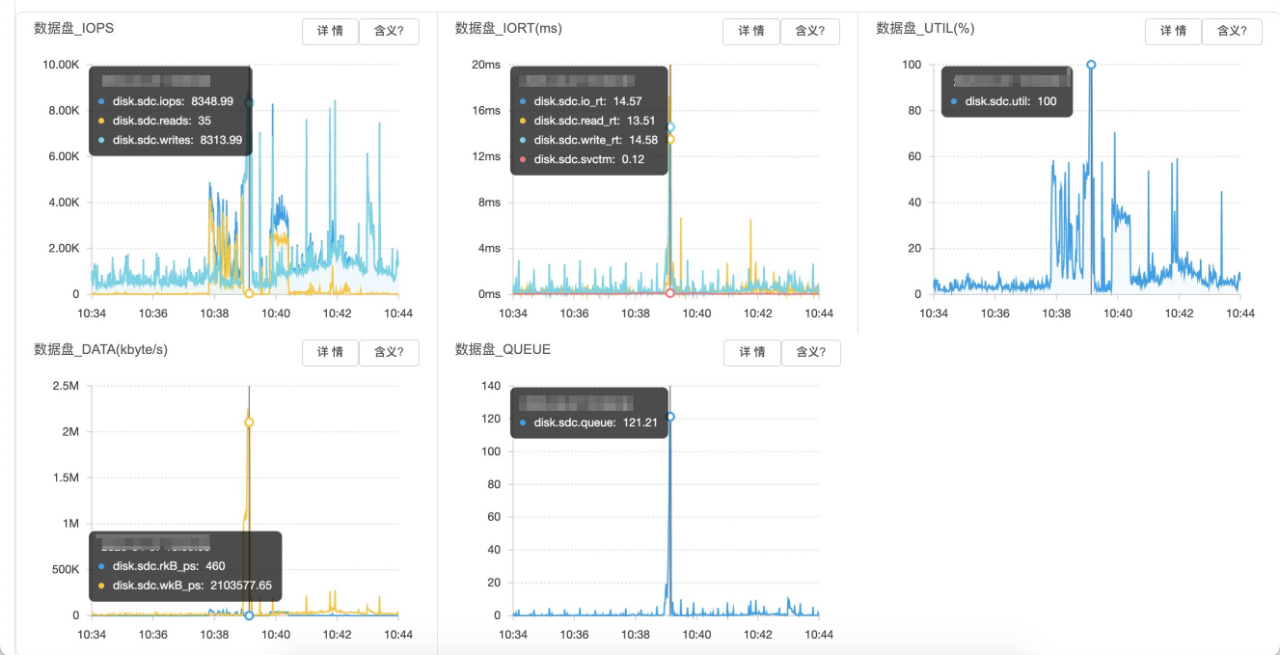
排查共用物理机其他实例的情况,发现有个库在问题时间附近有很多慢sql需要排序,写临时文件刚好写入了2GB:

多个MySQL实例leader节点混合部署在同一台物理机,虽然通过docker隔离了CPU、MEM等资源,但目前还没有做到buffer io的隔离。
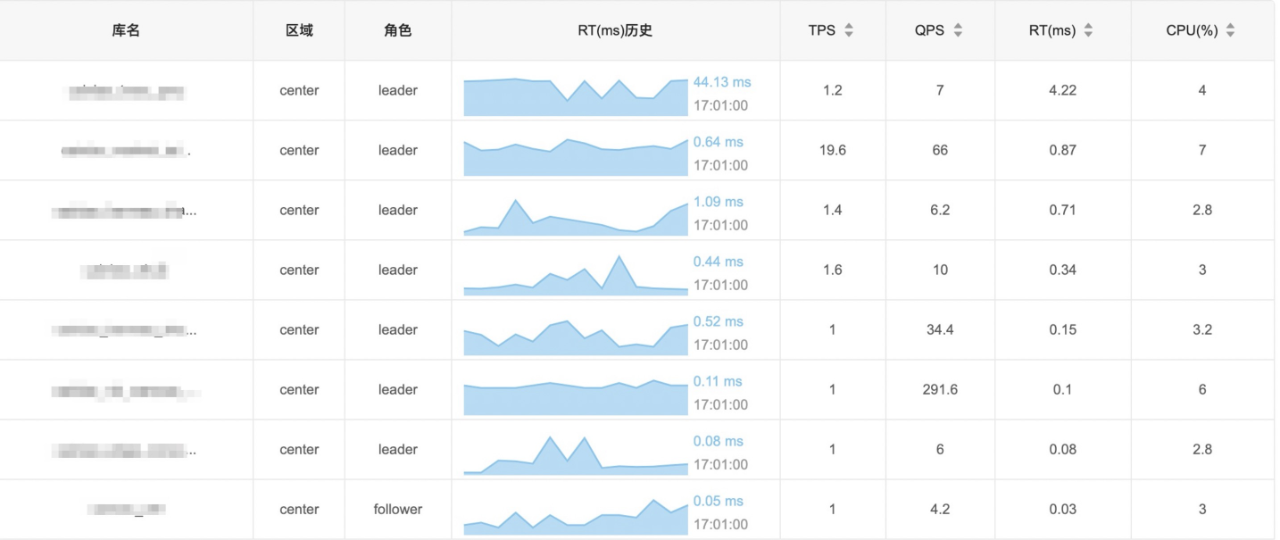
通过汇总分析高频的查询并结合业务得出合适的索引往往能够解决日常遇到的慢查询,但这并不是万能的。
比如有可能索引越加越多,乃至成了这样:
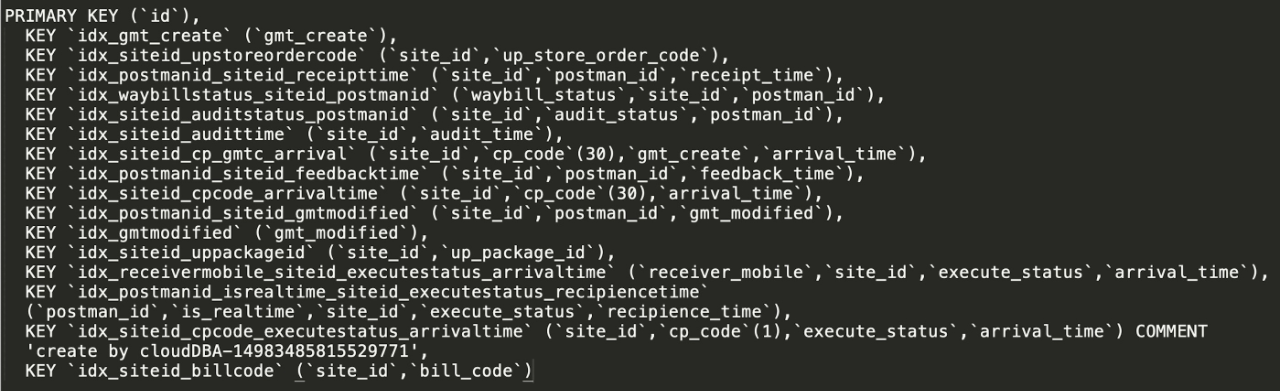
有些场景,比如支持多个字段组合查询,又没有必填项,如果都要通过索引来支持显然是不合理的。

查询场景下,将区分度较高的字段设定为必填项是个好习惯;查询组合很多的情况下考虑走搜索支持性更好的存储或者搜索引擎。
六、日常化处理
随着各个CTO-D线的深入治理,各项指标较之前均有非常大的改观,比如核心应用完成慢查询清零,影响最大的一些慢SQL被得以解决,而我所在的团队排名也由最初的尾部top3进入到头部top3。
慢SQL治理进入日常化,通过每周固定推送慢SQL工单、owner接手处理、结单,基本形成了定期清零的习惯和氛围,慢SQL治理专项也被多次点名表扬。
小结
这是一篇迟到的总结,现在回头看觉得这里面的策略制定、问题分析和解决的过程还是蛮值得拿出来和大家分享下。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721