
郝昊喆,新炬网络数据库专家。擅长数据库方面的开发、整体架构及复杂SQL的调优,参与了多个行业核心系统的优化工作,目前专注于对开源技术、自动化运维和性能调优技术的研究。
一、关于标量子查询及伪代码表示
标量子查询由于需要传值,因此它和嵌套循环连接类似,被驱动表会被扫描N次。SQL语句中的主结果集为驱动表,标量查询为被驱动表,被驱动表的执行次数为主结果集在连接列上distinct值的数量,例如一条带标量子查询的SQL语句:
select ename, (select dname from dept d where d.deptno = e.deptno) dname
from emp e
where e.job in ('SALESMAN', 'ANALYST');
用伪代码可以表示为:
for i in (select distinct deptno from emp e where e.job in ('SALESMAN', 'ANALYST')):
select dname from dept d where d.deptno = i;
标量部分的执行次数可通过SQL语句计算出:
selet count(distinct deptno ) from emp e where e.job in ('SALESMAN', 'ANALYST');
二、标量子查询易产生的性能问题
结合伪代码,通常来说带有标量子查询的SQL语句易产生性能问题的地方有三点:
1、主查询过滤结果集时的效率,在上述例子中,是指对主表emp基于job字段进行过滤时的性能,如果访问路径较差,例如全表扫描、错误的索引扫描,易产生性能问题;
2、主查询过滤结果集后返回的数据量较大(这里的数据量指的是连接列的唯一值),会导致标量部分多次查询,即使标量的访问路径为INDEX UNIQUE SCAN,也容易因为较多的查询次数产生性能问题;
3、标量部分的查询效率,如果标量部分的访问路径较差,易引起性能问题。
三、标量子查询常规优化方案
介绍了标量子查询的特点后,接下来聊聊优化的问题,通常来说,当标量子查询存在性能问题时,可采取的优化方案主要有3种方式:
1、对于查询语句中的标量子查询,通常使用left join改写,当然,如果标量部分与主表在连接列上为主键、外键关系时,可以改写为inner join,进一步提升性能;
2、对于update语句中的标量子查询,通常使用merge语句改写;
3、在某些环境下不能改写时,可通过索引手段优化标量部分的访问路径、连接方式;
个人建议优先选择改写优化,因为改写最大的优势是可以控制执行计划,改变标量的连接方式(例如通过Hint、profile或者让优化器自己去选择),当某些环境下无法改变SQL语句时,再通过索引方式优化。
四、案例分析
本小节分享3个实际工作中遇到的标量子查询改写优化案例,3个案例分别是:
案例1:select语句中的标量子查询改写;
案例2:where语句后的标量子查询改写;
案例3:update语句中的标量子查询改写;
案例1:select中的标量子查询
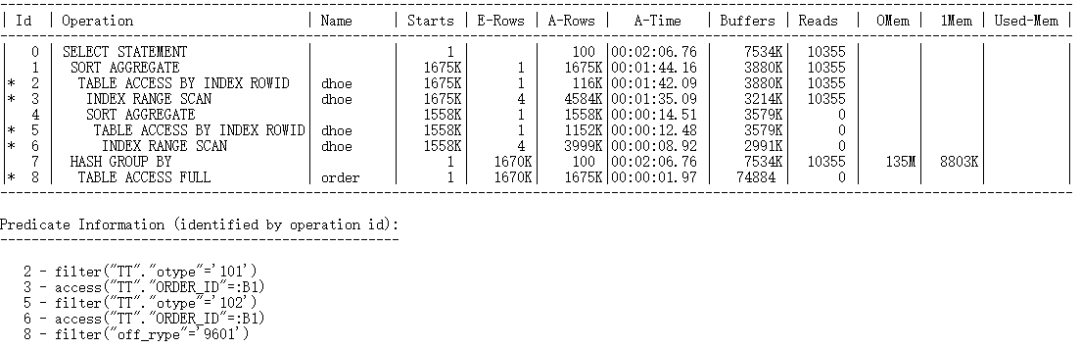
该案例为数仓平台中的报表SQL,总执行时间约2分钟左右,主表order加上过滤条件并group by后,返回数据量约160万。
真实执行计划显示,这一步仅耗时不到2秒,大部分时间耗费在ID=3-access(“TT”.”ORDER_ID”=:B1),体现在SQL语句中,则是标量部分的SELECT COUNT(1) from dhoe tt where tt.order_id = t.order_id,由于主表返回的数据量在连接列distinct值较多,导致标量部分扫描的次数较多(约160万),造成性能瓶颈。
select t.num_id,
t.create_time,
1 if_3to4,
max(case
when (select count(1)
from dhoe tt
where tt.order_id = t.order_id
and tt.otype = '101') > 0 then
0
when (select count(1)
from dhoe tt
where tt.order_id = t.order_id
and tt.otype = '102') > 0 then
1
else
0
end) if_hk
from order t
where off_rype = '9601'
group by t.num_id, t.create_time;
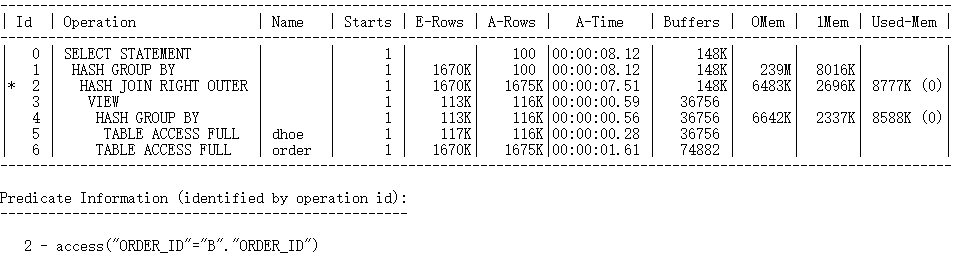
对于select语句后的标量子查询,我们通常使用left join或者inner join方式改写,在该案例中,标量部分的表dhoe与主表order在连接列order_id上不存在主外键关系,因此只能使用left join改写,改写时只需将标量部分在连接列上进行分组,将结果提前计算后与主表做关联即可。
改写后,优化器选择将主表与原先的标量查询做哈希外连接,每个表只访问一次即可完成查询,大大减少了物理I/O次数。
当然,并不是改写后优化器一定会选择哈希外连接,在某些情况下(如统计信息、特殊查询干扰优化器对rows的估算等等),优化器也会选择与改写后的标量视图做连接列谓词推入,从而导致改写后的标量视图做被驱动表与主表进行嵌套循环连接,这种执行计划通常要比标量写法还要差,因此改写完后我们仍需要检查下执行计划有没有问题。
select num_id,
create_time,
1 if_3to4,
max(case
when b.cnt101 > 0 then
0
when c.cnt102 > 0 then
1
else
0
end) if_hk
from (select t.num_id, t.create_time, 1 if_3to4, order_id
from order t
where off_rype = '9601') a
left outer join (select order_id,
count(case
when otype = '101' then
1
end) cnt101,
count(case
when otype = '102' then
1
end) cnt102
from dhoe
group by order_id) b
> group by num_id, create_time;
案例2:where后的标量子查询
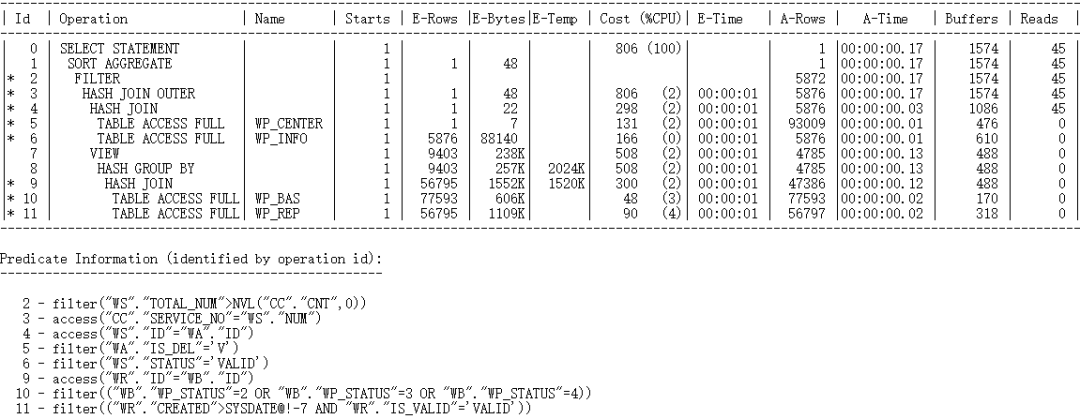
where后面有标量子查询时,由于需要传值,标量部分同样需要执行N次,只不过在执行计划中会出现关键字Filter,这一点和select后的标量子查询执行计划有点区别,但是运算方式是一样的,Filter的驱动表为主结果集,被驱动表为标量子查询。
该案例是大屏定时刷新页面的SQL语句,每次执行耗时52秒,通过真实执行计划可看到,大部分时间耗费在标量部分的传值计算中:
select count(*)
from wp_info ws
inner join wp_center wa
> where ws.status = 'VALID'
and wa.is_del = 'V'
and (select count(1)
from wp_bas wb
left join wp_rep wr
> where wb.WP_STATUS in (2, 3, 4)
and wr.is_valid = 'VALID'
and wr.created > sysdate - 7
and wr.service_no = ws.num) < ws.total_num;

与select中标量子查询的改写方式一致:标量部分按连接列分组提前将结果计算好后与主结果集做left join即可,在这个案例中,需要注意使用nvl函数对改写后的标量字段空值处理后再进行比较:and nvl(cc.cnt, 0) < ws.total_num
select count(*)
from wp_info ws
inner join wp_center wa
> left join (select wr.service_no, count(1) cnt
from wp_bas wb
left join wp_rep wr
on wr.id = wb.id
where wb.WP_STATUS in (2, 3, 4)
and wr.is_valid = 'VALID'
and wr.created > sysdate - 7
group by wr.service_no) cc
> where ws.status = 'VALID'
and wa.is_del = 'V'
and nvl(cc.cnt, 0) < ws.total_num;
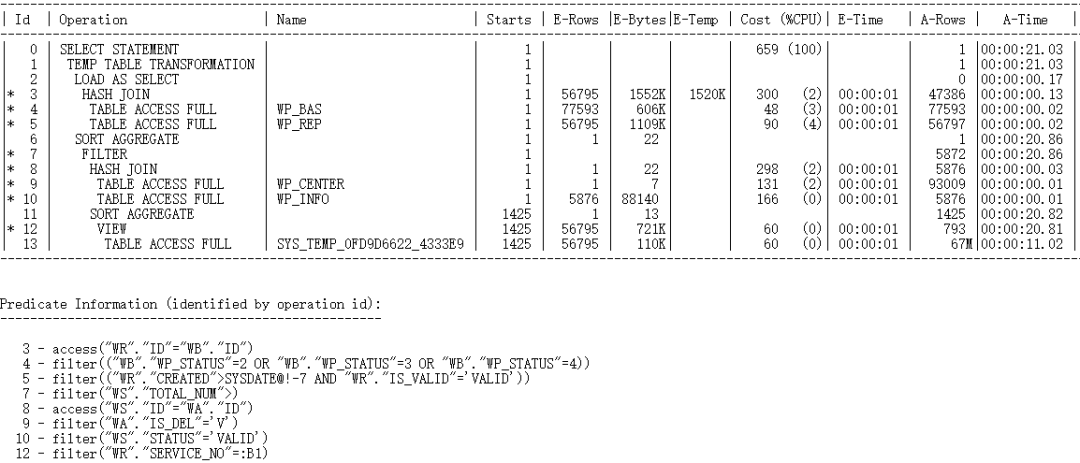
这里跟大家聊聊另外一种思路:在某些情况下,我们可以使用with+materialize物化的方式对标量的计算过程进行优化,这样改写优点就是简单方便,可以减少每次计算标量部分带来的性能开销,缺点则是它不能像left join改写那样控制执行计划,即无法改变被驱动表的执行次数。
对于案例二,用with+materialize方式的改写方案如下:
with t as
(select /*+ materialize */
wr.service_no
from wp_bas wb
left join wp_rep wr
> where wb.WP_STATUS in (2, 3, 4)
and wr.is_valid = 'VALID'
and wr.created > sysdate - 7)
select count(*)
from wp_info ws
left join wp_center wa
> where ws.status = 'VALID'
and wa.is_del = 'V'
and (select count(1) from t wr where wr.service_no = ws.num) <
ws.total_num;
案例3:update中的标量子查询
update set语句后面有传值时,也会导致子查询被扫描N次,通常使用merge语句进行改写,使用merge语句改写时,需要注意关联条件的写法。
该案例的更新语句每次执行耗时约20分钟,通过真实执行计划可以看到,标量部分执行了257次是该SQL语句的性能瓶颈:
UPDATE RE_RPT A
SET A.TCNT =
(SELECT NVL(SUM(G.REDCODE), 0)
FROM RP_GRANT G,
(SELECT DISTINCT REDCODE, REDCODE_MD5
FROM RP_SCAN) S,
IMT_CODE V,
(SELECT DISTINCT W_ID, NAME
FROM MATER
WHERE SUBSTR(ORDER, 1, 2) = 'OF'
AND W_ID IS NOT NULL) M
WHERE G.REDCODE = S.REDCODE
AND S.REDCODE_MD5 = V.N_CODE
AND V.W_CODE = M.W_ID
AND G.RP_CLASS = '有效'
AND G.CREATE_DATE = '2018-05-05'
AND A.NAME = M.NAME)
WHERE A.CHOOSE_TIME = '2018-05-05';
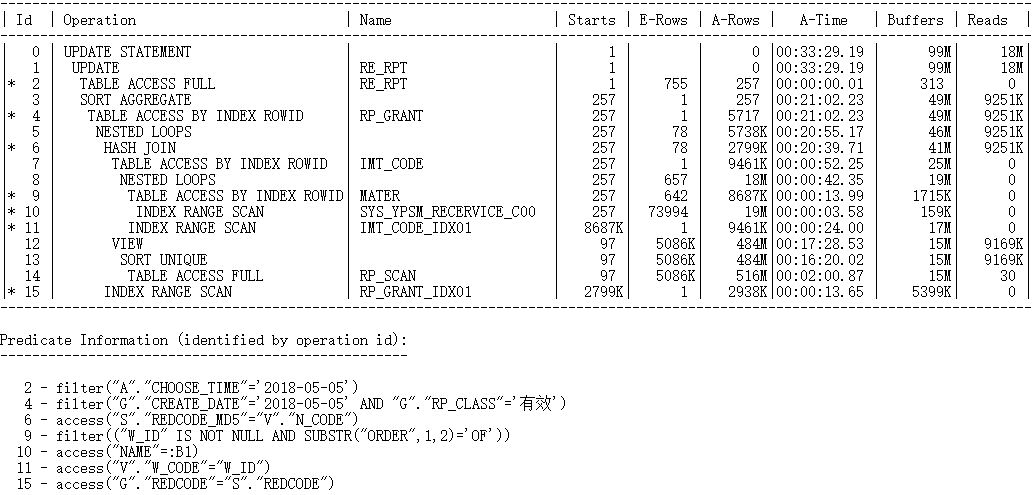
通过以下查询也可以计算出标量执行次数:
SQL> select count(distinct NAME)
2 from RE_RPT A
3 WHERE A.CHOOSE_TIME='2018-05-05';
COUNT(DISTINCTNAME)
---------------------------
257
由于该语句每次执行时,是对每日数据进行全量更新,因此merge语句的关联条件可以写为外连接的方式:A.NAME = M.NAME(+)
MERGE INTO (select *
from RE_RPT A
WHERE A.CHOOSE_TIME = '2018-05-05') A
USING (SELECT M.NAME, SUM(G.REDCODE) SUM_CODE
FROM RP_GRANT G,
(SELECT DISTINCT REDCODE, REDCODE_MD5
FROM RP_SCAN) S,
IMT_CODE V,
(SELECT DISTINCT W_ID, NAME
FROM MATER
WHERE SUBSTR(ORDER, 1, 2) = 'OF'
AND W_ID IS NOT NULL) M
WHERE G.REDCODE = S.REDCODE
AND S.REDCODE_MD5 = V.N_CODE
AND V.W_CODE = M.W_ID
AND G.RP_CLASS = '有效'
AND G.CREATE_DATE = '2018-05-05')
group by M.NAME) M
ON (A.NAME = M.NAME(+))
when matched then
update set A.TCNT = nvl(SUM_CODE, 0);

五、总结
本文主要跟大家介绍了标量子查询的特点,并结合实际工作中遇到的3个案例聊了下通用的改写方案,如果一条SQL语句的性能瓶颈在标量子查询,那么可以通过改写SQL来改变主表与标量子查询的连接方式,或者通过建立索引优化标量部分的访问路径,本质都是一样的:减少物理I/O次数,达到提升性能的目的。
《All in Cloud 时代,下一代云原生数据库技术与趋势》阿里巴巴集团副总裁/达摩院首席数据库科学家 李飞飞(飞刀)
《AI和云原生时代的数据库进化之路》腾讯数据库产品中心总经理 林晓斌(丁奇)
《ICBC的MySQL探索之路》工商银行软件开发中心 魏亚东
《金融行业MySQL高可用实践》爱可生技术总监 明溪源
《OceanBase分布式数据库在西安银行的落地和实践》蚂蚁金服P9资深专家/OceanBase核心负责人 蒋志勇








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721