
蒋健,云趣网络科技联合创始人,Oracle ACE,11g OCM,多年Oracle设计、管理及实施经验,精通数据库优化,Oracle CBO及并行原理。云趣鹰眼监控核心设计和开发者,资深Python Web开发者。
春节前某天下午4点的样子客户打来电话,说近期的某个关键系统经常HIGH CPU,业务频频反馈说数据库运行极慢,CPU使用率频频100%,而且主机无法ssh登录,年底业务高峰期,系统性能故障对业务影响极大。
甲方DBA已经自己优化了差不多两天了,效果不明显,需要到场优化。
过来之前问客户了解了些大概信息,这个库历史上CPU使用率并不高,年底业务高峰期加上可能要拉报表所以负载会高一些。主机为AIX系统,虚拟化后CPU有48个,内存96G单机的数据库,版本为10.2.0.5的。
一、应急处理
到场后情况不乐观,客户那边忙成一团,监控中看了下历史CPU情况,如下:

刚准备上机操作,发现数据库主机又开始又登录不进去了,客户DBA尝试了几分钟后,终于登录进去,一查果然CPU 100%了,为了应急保证业务,临时决定先杀一批没有事务的会话。
HIGH CPU的时候观察了下,主机层面user大约92%,sys的约7,几乎没有io wait的CPU,也没有页交换出现,CPU消耗高的进程基本上都是Oracle用户的。

反复运行以上命令后,CPU使用率勉强稳定到了90%,基本上可以开始分析性能故障了。
二、AWR报告信息
AWR报告开始生成不出来,一些常规操作后,拿到了故障时间段的AWR报告。先看下大概的信息,采样的一个半小时内数据库AAS(平均活跃会话数)已达84,redo量比较大,硬解析、登录、排序等指标没严重的问题。
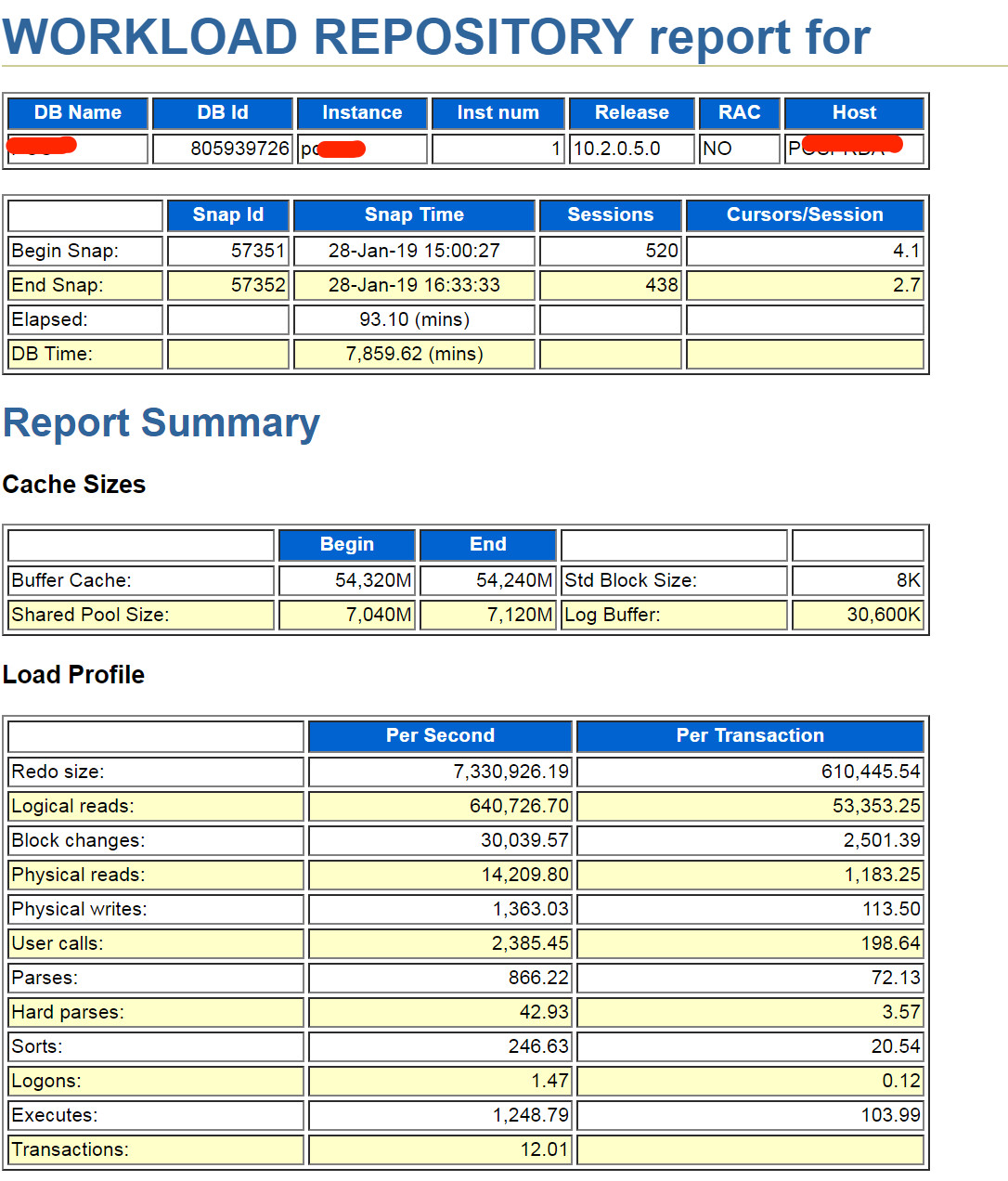
其实大部分情况到这步了很多DBA基本上就直接搜索`SQL ordered by CPU Time`或是`SQL ordered by Gets`去定位TOPSQL了。
那么这里也贴下对应的部分,并没有明显的TOPSQL,甚至top1也就占1.6%。那么这时候怎么办呢?
三、是硬解析导致TOPSQL不明显么
通过`force_matching_signature`这个标志位可以去判断下是否其实有那种高占比的TOPSQL由于应用没有使用绑定变量而被掩盖,由于监控中带功能识别这种问题,我没写SQL去判断。
通过监控的识别快速打破了这种美好的愿景,哪怕强制绑定变量后TOP 1的SQL数据库时间占比也不超过3%,top10加起来目测也不超过20%。显然找到TOPSQL再实施优化,目前看起来行不通,毕竟找不到TOPSQL。
四、换个角度能否突破
其实在之前的文章中也提到过,SQL层面的定位难以突破时,可能需要聚合到对象层面(一般涉及访问路径优化),也就是对象层面。
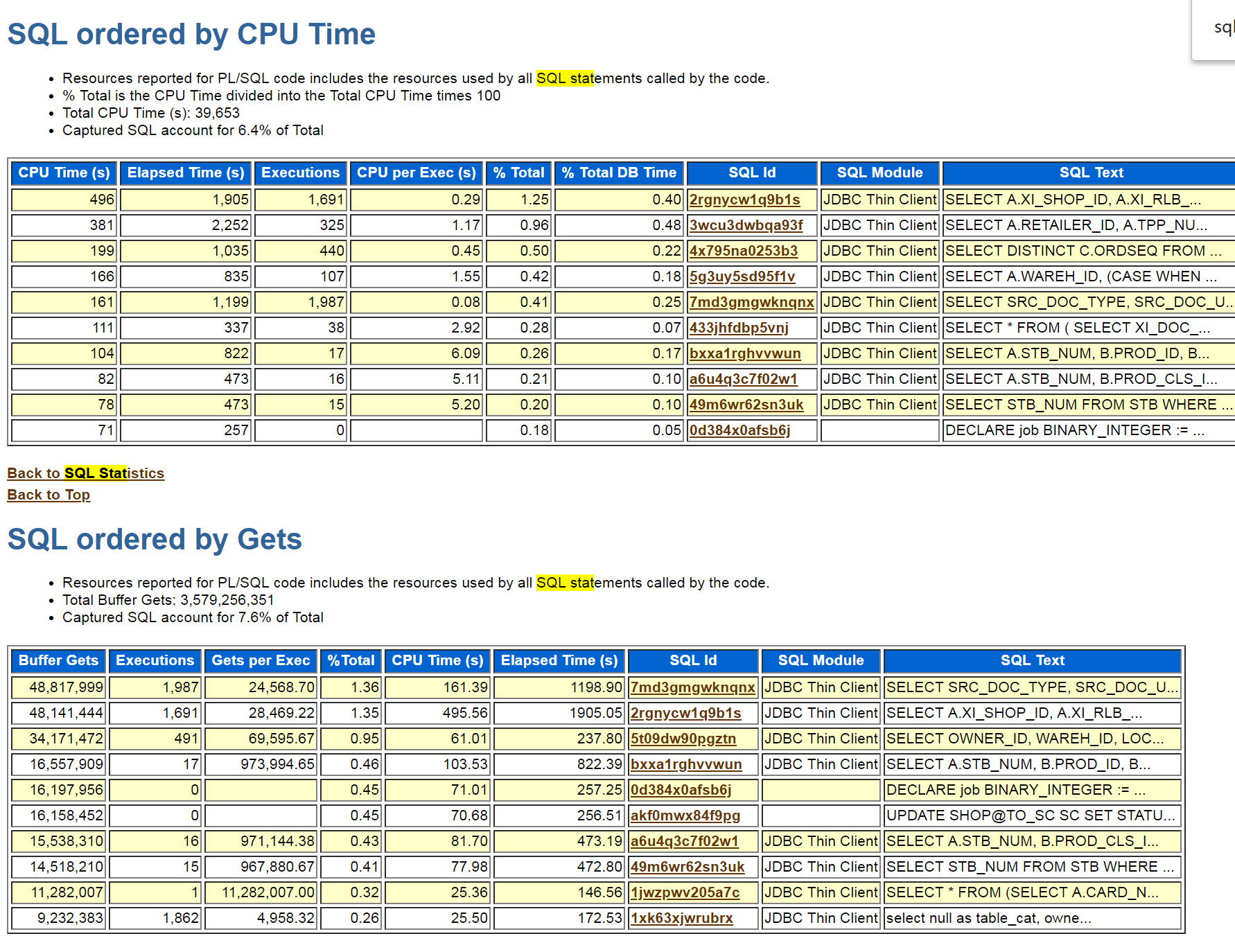
通过搜索`Segments by Logical Reads`可以发现上帝在为你关上一扇的门的时候,顺便也把窗户关上了......
没错,聚合到了对象层面,top1只占16%,这几乎就说明想优化两三个SQL就解决问题的想法不现实。
五、真相其实...
其实现场,我并没有太多的困惑,毕竟写文章需要,上面的思路基本是按照客户DBA处理的思路延伸了下。
真相是上来我就已经看过了以下信息,基本换了大方向了。在看了这个信息后大家有别的思路了么。

没错,top5等待事件比较有趣。
正常CPU-bound的数据库系统,latch、mutex相关的等待伴随也比较多,会出现在top5/10里,而这个100% CPU的系统竟然是top5,等待事件却是`User I/O`类,常规指标`User I/O`与`db file scattered read`的平均IO延迟是2ms,似乎IO没成为瓶颈,与之对应的是开始主机层面CPU的io wait很少。
虽然看似IO也有一定消耗的,但并不合适直接去看`SQL ordered by Reads`再深入去看TOPSQL,毕竟要解决的问题是系统100%CPU。当然这里也贴图看下:
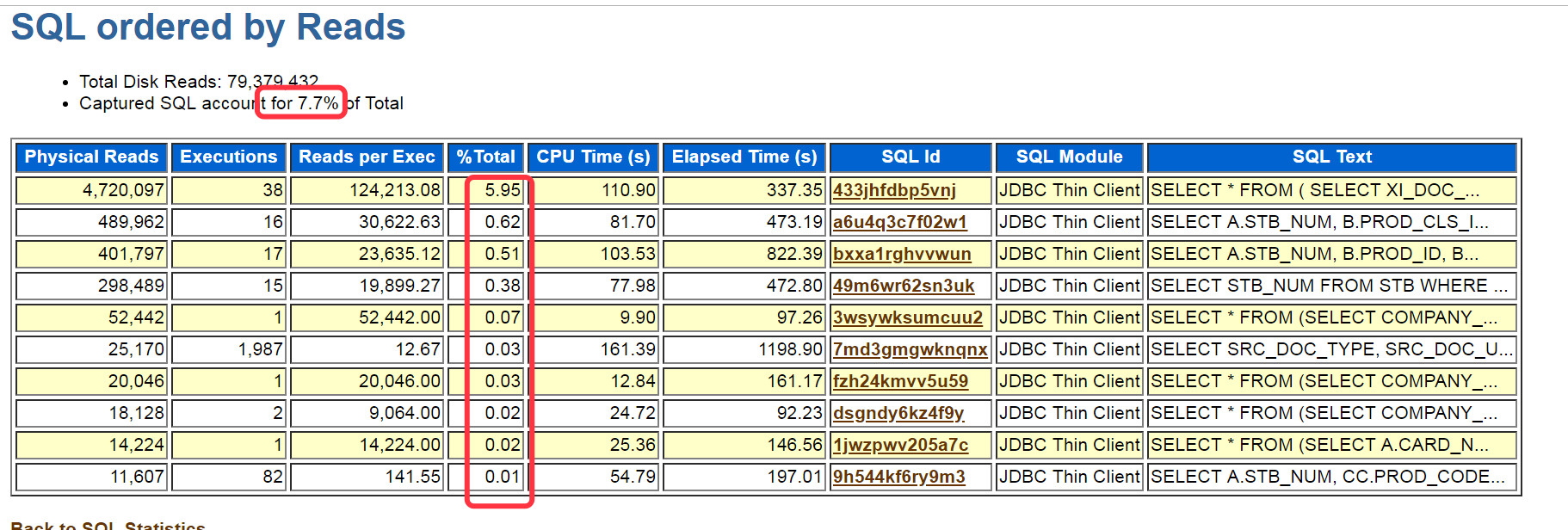
依然没有大的TOPSQL。
六、另几个坑?
在看到了top5的等待事件后,我马上搜索了下log file出现了如下信息`log file sync`39ms`log file parallel write`也达到了20ms。
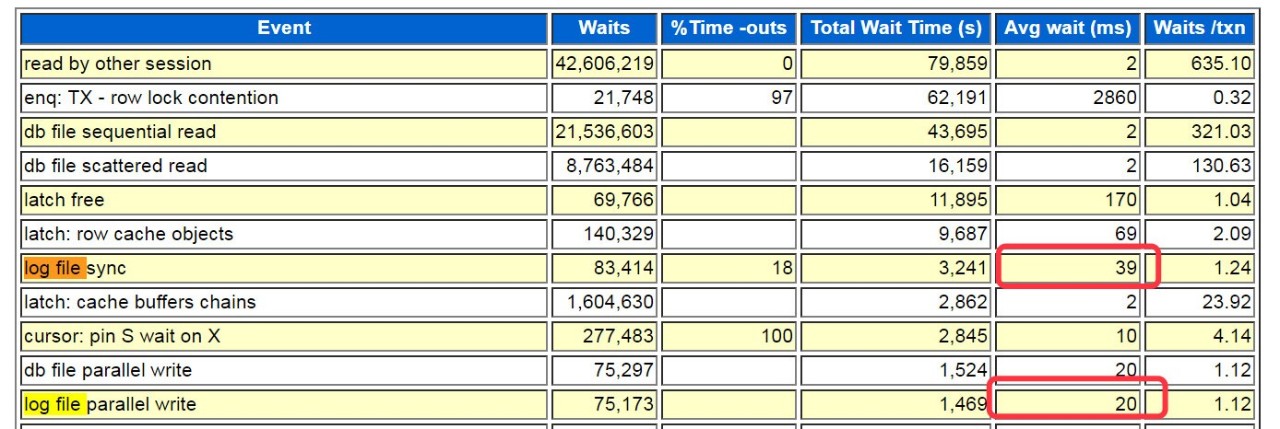
10g没`redo synch poll writes`,不用检查`_use_adaptive_log_file_sync`参数。
看到这里是否感觉可能问题其实是出在存储上呢?
常见的存储IO性能故障引起日志同步变慢,AAS大幅提升最终引发故障的场景屡见不鲜。
一般来说从数据库层面会以后台等待事件`log file parallel write`的延迟来衡量存储顺序写的性能,那是否我们应该把关注重心转移到存储IO性能上呢。
其实以个人的优化经验看来,`log file parallel write`的高延迟最终能确认是存储问题比例其实不高,刚好客户这边XIV的软件不知是有异常还是什么原因,查不到过去一小时的IO写延迟。
关于`log file parallel write`,虽然从事件的定义上它可作为衡量存储性能的重要指标,但由于事件的登记都是由LGWR进程去做的,也就是受到进程调度的影响,在CPU使用率高的时候(或是cpu_count超过128的时候),这个指标其实并不准确,更多信息可以去参考Oracle support的文档(34583.1)。
是继续纠结在IO性能这里呢,还是按照客户DBA的建议优化那些他们抓出来的几页长的报表SQL呢?客户的CTO在线等你给建议。
存储这边也可以让存储维保厂商继续过来确认存储性能问题,哪怕是加内存,进而调整SGA,甚至是keep一些关键表都是可操作的。
而报表SQL语句这边呢,要改写,要优化,要协调开发,也可以商量,毕竟业务影响实在太大。
但有一点,在做之前需要明确的就是,这些接来下打算做的操作能否将CPU降低一个合理的比例保障业务的正常运行,这是CTO肯定会问的问题,白费力气忙活一场,没解决问题那肯定很尴尬的。
七、决策
不知不觉,时间已经到了快下班的时候,客户CTO表示今天晚上做些操作,希望明天能看到效果。这时候如果是你,接下来打算怎么处理,又打算给客户一个降低CPU多少的期望呢?
我当时给出的保守期望是降低20%,不改参数,只是在三张表上建立四条索引。哪三张表?参考下图前三张表:
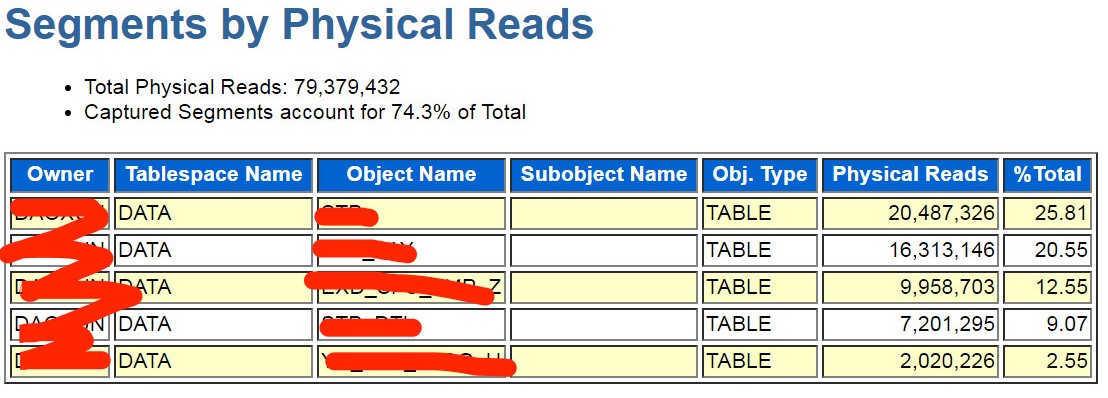
四条索引的依据则三张表的数据访问路径的聚合,其中一条对应的SQL当天运行情况如下:
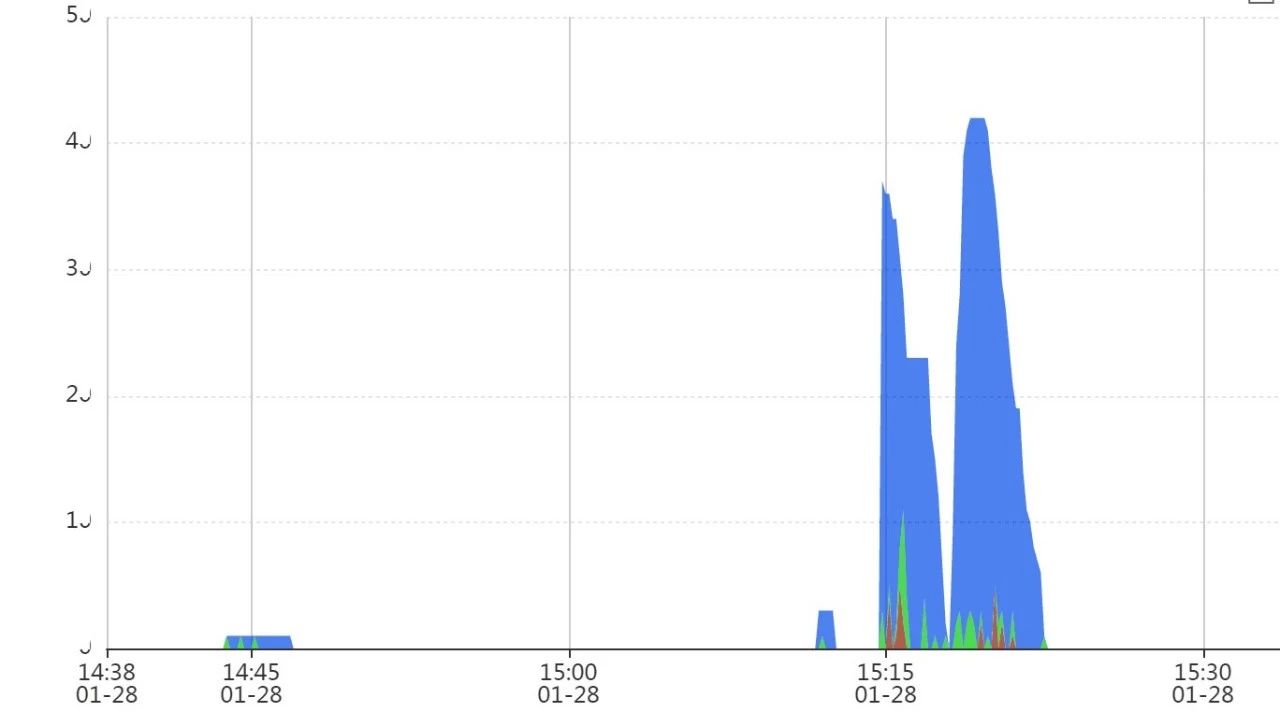
可以发现这种SQL瞬间的并发非常高,ASS能达到40+,但过了峰值可能又是别的SQL上来,并且这种SQL通过`force_matching_signature`聚合后,一个小时的采样数据都进步了前20,这种SQL在AWR也不一定能进AWR各个维度的top10SQL,这类SQL的发现不太适合使用AWR报告。
当然定位了top segment后,通过表名的关键字两边加上空格,也可以尝试下搜索相关SQL。
如果手工写脚本分析,建议聚合分析`dba_hist_active_sess_history`,`dba_hist_sqlstat` 等视图。
本次优化最终选择的是优化SQL的方式处理,而且是优化物理读消耗多的SQL入手,原因是对系统故障的猜测:
部分高IO消耗的SQL,影响了redo的刷新性能(自动巡检报告中,系统redo未隔离数据文件),系统并发性上去后,CPU消耗过高,LGWR进程CPU调度不能保证,(巡检报告中,常见参数`_high_priority_processes`没有设置LGWR),又进一步加剧DML慢的问题,系统并发从而更高,不断恶化。
`_high_priority_processes`这个参数并未修改,因为该参数修改需要重启数据库,而通过临时处理时renice可以达到相似效果,而不用重启。所以我计划第二天现场发现CPU高过80%时,再手工调整。这样也方便自己对单个调整能取得的收益有个更好的认识。
八、开奖
第二天的情况出乎意料的好,几乎腰斩,CPU偶尔达到60%,以至于根本不用renice操作,我都忍不住去群里确认了下当天的业务确实没有任何变更。
做了份AWR报告,我关心的`log file sync`,`log file parallel write`如图勉强还行,但跟昨天比好太多了。
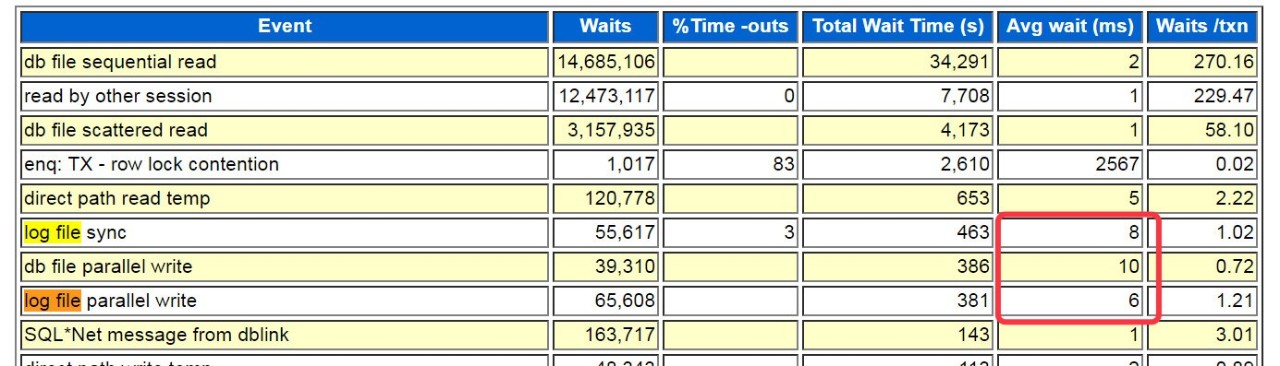
系统AAS也降到了30左右。

九、总结
这次故障处理的过程反思可以发现,其实不少的隐患,在日常的巡检,SQL审核中都可以被发现,但到了故障现场,可能由于环境的复杂,被放大后出很多衍生故障,分析定位起来则麻烦不少。日常的巡检,SQL审核多花些精力,定期更新自己的知识库,这些时间最终都是高回报的。
100% CPU使用率的风险是大部分系统都存在的,最难受的是发生了HIGH CPU后,可能主机SSH都无法访问。这种风险建议在CPU_COUNT层面做调整,该参数默认值是使用全部的CPU资源,考虑对其进行调整为逻辑CPU-2(单机数据库)。
RAC架构下同一集群有多个数据库的结合具体情况考虑实例CPU隔离,参考support文档(1362445.1)。
resource manager在处理整体使用率上不太好用,业务上AP、TP混合的话,可以通过RM调整业务的优先级,保障重点业务。报表拖垮了交易系统的问题,可以通过RM来实施保障。
高CPU使用率(一般超过80%)或CPU个数过多情况下,LGWR性能可能受CPU调度影响较大,建议`_high_priority_processes` 设置LGWR。该参数调整需要重启数据库,建议规划后集中调整。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721