

1.前言
关于SQL优化,前辈们、技术大咖们、各个技术论坛上早就有很多的优秀文章,今番我再次提起,心情忐忑,实在是有些班门弄斧和自不量力了。
在大家的鼓励下我想写一下也好,就写我们身边的事,用身边的案例来演绎SQL优化,用形象语言把SQL优化说成我们身边的事,希望能让接触到SQL的同学可以体会到SQL提速的乐趣!
2.理解几个名词
提到SQL优化,我们不得不学习几个名词,这就好比武侠小说里练习武功一样,不知道几个穴道,不了解几个气门都不好意思提自己是练功夫的。名词挺多,除了这里提到的还有好多,比如内外连接、嵌套循环、游标共享、绑定变量、软硬解析等等,武功太多,练不过来,那我们先把马步扎好再说。没有提到的功夫在藏经阁都有,请按需百度。
2.1 执行计划
执行计划是什么呢?就是SQL执行的路径和执行步骤。怎么理解呢?你从家里到公司可以选择开车走高速,也可以选择做公交车走市区街道,那么你选择用哪个交通工具,走哪个路线,就是你的执行计划。但是一次只能有一个方案。
一个SQL生成了执行计划,他就会被固定到共享池里,只有在表发生了变更、统计信息过旧、共享池被刷新、数据库重启等情况下SQL才会重新生成执行计划。还是从家到公司,城市在修路,公交路线变化都会影响你选择什么样的方式上班。
2.2 索引
索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。怎么理解呢?表是一本书,索引就是这本书的目录。
2.3 统计信息
统计信息主要是描述数据库中表,索引的大小、规模、数据分布状况等的一类信息。比如表的行数、块数、平均每行的大小、索引的leaf blocks、索引字段的行数、不同值的大小等,都属于统计信息。
Oracle的基于成本的优化器(还有一种是基于规则的,武功过时了,不练了)正是根据这些统计信息数据,计算出不同访问路径下,不同连接方式下,各种计划的成本,最后选择出成本最小的计划。如果没有统计信息呢?会发生动态采样,就是在生产执行计划前去表、索引去进行数据采样。
怎么理解呢?还是从家到公司,有了地图和公交信息,高速收费情况等信息,大家就可以选择最合适的上班方案了。没有这些现成的信息你就需要实际去调研一下了,比较麻烦,而且可能造成不合适的选择。
3.某个SQL是否能优化?
怎么能确定一个SQL是否能优化呢?这个不太好回答,DBA们经常说先分析分析看看。那么分析什么呢:现在效率如何?执行计划?跑的时候等待事件?表多大?选择列上有无索引?选择性如何?有统计信息?连接方式?......又是这些名词,还没有完全理解的小伙伴不要着急,我不是卖野药的,马上就要表演啦!
其实呢,也可以不用这么复杂。一个非常劣质的SQL(跑几十分钟,甚至是几个小时的SQL)最终能不能有质的提速,主要就是看业务的本质上需要访问多少数据量,如果业务本质上需要访问的数据量越少,一般来讲提速余地就越大。简单吧,所以一个业务专家,你遇到了一个劣质SQL,不用DBA分析,你应该就知道有没有优化余地了。
怎么理解呢?一个大操场上有一个红色的玻璃球,让你去拿到,你没看见,地毯式的找半天,有人给你个坐标图,你10秒钟跑过去就找到了,这就是有提速余地,如果满操场上都是需要的红色玻璃球让你拿,无论怎么拿,都要拿半天,这就是没法有质的飞跃(就是没办法几秒钟、几分钟把活干完)。
下面我们循序渐进的讲一些案例吧。
少商剑:合理利用索引
1.1利用索引提高效率
INS_USER_571 表上有两个索引IDX_INS_USER1_571,IDX_INS_USER2_571分别对应列BILL_ID,EXPIRE_DATE列,SQL 和执行计划:
select * from SO1.INS_USER_571 M where M.BILL_ID = '13905710000' and M.EXPIRE_DATE > sysdate;
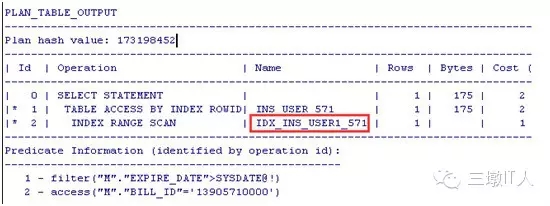
符合BILL_ID的数据只有一条,而符合EXPIRE_DATE条件的数据有几万条,就是说BILL_ID选择性好,选择IDX_INS_USER1_571索引就会更快的找到这条数据。
怎么理解?大操场上找1个玻璃球,给你两个坐标图,一张直接告诉你这个玻璃球的具体位置,一张图告诉你在某个10米的范围圈内,选择哪个呢?肯定选第一张。
1.2走索引反而慢?
在CREATE_DATE上建立个索引IDX_INS_USER4_571:
SQL:
SELECT COUNT(*) FROM SO1.INS_USER_571 M WHERE M.CREATE_DATE >= TO_DATE('20110101','YYYYMMDD') AND M.CUST_TYPE='1';
PLAN:没有走索引?!
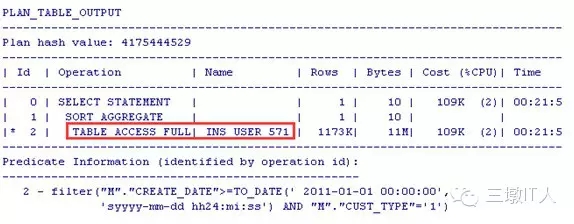
难道是优化器有问题?测试下就知道了。为了明确加Hints测试:
SELECT /*+full(M)*/COUNT(*) FROM SO1.INS_USER_571 M WHERE M.CREATE_DATE >= TO_DATE('20110101','YYYYMMDD') AND M.CUST_TYPE='1';
SELECT /*+INDEX(M,IND_INS_USRE4_571)*/COUNT(*) FROM SO1.INS_USER_571 M WHERE M.CREATE_DATE >= TO_DATE('20110101','YYYYMMDD') AND M.CUST_TYPE='1';


看来优化器没有错!
当需要扫描的数据量较大时,走索引的成本比全表扫描的成本还要高。
怎么理解?一本书1000页,其中800页的内容都是你需要的,那你看书的时候就没有必要每看一页都要回过头来翻翻目录了,这样多罗嗦呀!直接顺序往下读好了。
1.3本招的几个口诀
在where条件中选择列上加了函数,没法利用索引
例如:where to_char(create_date,’YYYY-MM-DD HH24:MI:SS’)>= ‘2015-04-08 00:00:00’
这样没法利用到create_date的索引
正确的写法:
where create_date>=to_date( ‘2015-04-08 00:00:00’,’YYYY-MM-DD HH24:MI:SS’)
案例:select count(t.visitor_id) as pv
from t_stat_logbase t
where instr(t.visit_url, :""SYS_B_0"")>:""SYS_B_1"" and
to_char(t.visit_date,:""SYS_B_2"")=:""SYS_B_3""
visit_url, visit_date 都有索引,而且visit_url列的选择性非常好,但是因为在本列上加了instr的函数,造成只能全表扫描,因每天零点左右执行频率高,数据库经常出现性能告警,应用改造后有效利用了索引,数据库恢复正常。
Ø 变量类型要正确,避免隐式转换造成没法利用索引
Bill_Id 是varchar2的类型
Where bill_id=1 就没法利用索引。
Ø Where条件终须用到前导列才能走上组合索引,组合索引中选择性好的要放在前面:
索引ind_ins_user5_571(create_date, cust_type): where cust_type =1
只有cust_type这个条件,而没有create_date走不上索引ind_ins_user5_571
Ø 在多表关联的情况下,即使表很小,在关联字段上加索引往往都非常有效,可能影响表的连接方式而节约成本。
Ø 不要试图每一个字段上都加索引,索引越多对表的DML影响越大,对DML要求很高的接口表都不建议加索引,组合索引的列越多,索引树可能越深,有时候不但不能查询提速,反而还影响了DML效率。
例如:Where条件中有一个选择性非常好的字段,如BILL_ID/ACC_ID/USER_ID,其他选择条件如STATE/TYPE没有必要再进行组合索引。
1.4老板再也不用担心我的数据积压啦
某报表库下有这样一条sql,每个地市启动了10个线程,去进行数据处理,每个地市执行频率每小时高达几万次,造成数据库CPU压力巨大,而降低线程又会出现数据积压,咋整呢?DBA们也捉急呀!
select ROWID, t.*
from CHK_ORD_INTERFACE_574 t
where mod(INTERFACE_ID, :"SYS_B_0") = :"SYS_B_1"
and SCAN_STATE = :"SYS_B_2"
and rownum <= :"SYS_B_3"
sql特点: 执行计划走全表扫描,过滤条件SCAN_STATE字段只有2钟情况(0,1是否已稽核)
业务特点:CHK_ORD_INTERFACE_NN表从营业端通过dsg同步到报表端,在报表端进行数据稽核,稽核过的数据进行delete,本表按日进行分区,也就是碎片重用率很低,造成本表碎片极为严重,碎片率达99%以上,因dsg同步是通过rowid进行,造成本表不能通过move,shrink等手段进行碎片清理。走不上分区,过滤条件选择性低!不能整理碎片!看起来这不是没办法嘛?!
方案:本表的碎片率高达99%,说明实际的数据量非常少,可以创建全局索引(本表的生命周期是永久保留,全局索引在本业务特点下可以提高索引碎片的重用率,有效控制索引大小),数据块虽然很多,索引很小呀,建立,有效!原来1.4S,创建索引后0.002s,线程调整到1,照样完成任务,CPU也下去了,老板再也不用担心我的数据积压啦!
中冲剑:合理的逻辑
1.1 有效利用连接,避免嵌套
表的外连接一般都会比半连接效率上高的多,在保证业务效果的情况下,我们更建议表关联代替IN/EXISTS子查询,好处多多,关系到驱动表啦,连接模式啦,这里不细表。有兴趣,请实践,有疑问,喊DBA!
在某报表系统的专项优化中,我们抓到了一个异常复杂的sql涉及到13张表,5层的嵌套....通过分析业务需求之后,发现用多表关联可以代替In字查询(业务效果不变)我们将SQL里面的三个小段落做了类似如下修改,并在关联键上创建了索引,由原来跑2个小时提速到10秒之内:

修改为:

1.2 括号内外差别很大
直接上菜:
原sql


问题出在哪里呢?本sql缓慢的根源是括号,括号犯了什么罪?他造成了针对RP_BUSI_DETAIL_NNN(571 180G)进行全表扫描,而业务特点是读取distinct customer_order_id, SALER_ID 且与RPT.INSX_OFFER_PRG_577 的ustomer_order_id列进行关联。
方案:创建customer_order_id, SALER_ID的组合索引(两列都非空),并将RPT.INSX_OFFER_PRG_NNN表的其他过滤条件放进子查询中,这样sql执行计划扫描索引,而且不进行回表。
效果:这个sql在1小时快照周期内就没有完成过,不过优化后就好啦,在不同的条件范围内1-30秒都可以完成。
新sql:


1.3 深入理解业务,利用好分区
很可惜,上个故事还没有结束,过了一个星期,业务侧反映有些业务很快了,可是有些却很慢,特别是一次性统计3个月的报表根本就跑不了......有些快?有些慢?这个是重点,立即联系业务侧和开发确认快和慢的场景,并进行了跟踪,发现快的场景下都输入了ORG_ID条件,而慢的场景下都没有ORG_ID条件,那么关键点就在这里了!
不带条件ORG_ID = :ORG_ID,某月份的数据为例,那么符合条件的INSX_OFFER_PRG_571的数据有14万之多,与RP_BUSI_DETAIL_NNN表关联时 CBO优化器只会选择hash jion连接,且选择的索引只能是done_date(取出范围内的数据后再进行hash),如此大的两张表肯定没法在50秒内(超时限制)完成,而输入了条件IOP.ORG_ID = :ORG_ID那么符合条件的INSX_OFFER_PRG_571的数据在100条以内,sql可以走嵌套循环,而且两张表都可以利用到高效的索引,速度自然就大大提高。
那么不带条件ORG_ID = :ORG_ID下能不能快呢?最后发现了一个关键点RP_BUSI_DETAIL_NNN是个按月分区表,每个分区只有1-6G,比起180G自然是小的多了!而且分区字段也是DONE_DATE,很可惜sql中没有利用到分区,立即联系需求侧和开发侧确认,INSX_OFFER_PRG_NNN 和RP_BUSI_DETAIL_NNN两张表的DONE_DATE在业务意义上是否一致或者差距很小?是否可以把RP_BUSI_DETAIL_NNN表的DONE_DATE也一并放在条件中?非常幸运,我的这个提议立刻得到了肯定的回复,在后续的沟通和测试下,重新定制了业务规则,最多只能按自然月查询(考虑表按自然月分区)查询,业务超时由原来的50秒改成3分钟,最终将SQL改写成了:

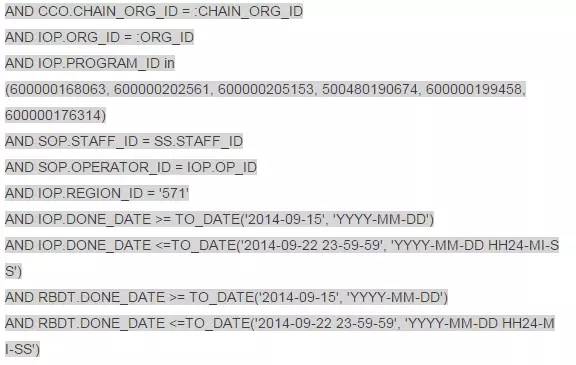
虽然目前的执行计划中INSX_OFFER_PRG_NNN 和RP_BUSI_DETAIL_NNN两张表还是通过hash jion连接,数据量也还是较大,但是我们走上了分区过滤,特别是RP_BUSI_DETAIL_NNN这张大表只会单分区扫描,所以在新的规则和超时机制下我们顺利的完成了这个报表的优化。
1.4 数据库迁移前的优化
背景:某个有点年头的数据库在某次项目改造中需要迁移并升级到新的机器上,这个库因为业务不停的上线和实在有点低的硬件配置原因在迁移升级前主机CPU的使用率也是很高了,而迁移需要借助某第三方工具,这个工具的初始化过程需要有足够的CPU资源,而割接时间窗口和业务原因只能准在线割接(可以停业务的时间很短),也就是说虽然这个数据库在目前的低配置机器上转不了几天了,但是为了保证割接的顺利进行DBA们还是硬着头皮去进行优化。
优化过程中的一个案例:
原sql:




这个SQL执行时间在25秒左右,逻辑上看起来实在是有点复杂,不过我们耐心的拆解分析下找到了第一个突破点:修改以下子查询的写法

上面的写法等同于:

下面的写法执行时间可以从15秒降到10秒,有些进展!继续。
考虑到这个子查询所进行的表连接,可以将连接条件放置在这个子查询的where字句中,进一步简化逻辑,改写为:


该子查询的执行时间进一步减少到1.7秒,在原SQL中使用这个新子查询,原SQL的执行时间从25秒减少到4.6秒,性能提高了5倍多。好了,理解联系开发进行测试验证,2天后他们反馈业务效果完全一样,而且速度的确明显快了很多!
看吧!我们什么也没做,没有加索引,没有改造表的物理模型,仅仅通过梳理逻辑,简化sql执行的步骤和避免重复数据扫描就完成了一项优化,所以我们以后在写代码的过程中是不是要多想一想呢?!通过2周的努力,我们终于将主机CPU使用率给总体降下来接近10%,顺利的保障了割接。
1.关冲剑:绑定执行计划
1.1 合理利用Hints
Hints定制执行计划,在割接、经分、稽核等场景下应用广泛,合理的利用可以有效利用资源,提高执行效率。
Parallel 并行:合理的利用parallel可以有效利用资源,提高执行效率。但是在日常生产期间,核心库不允许吆!Parallel开的越高,就是并行度越高,那么资源使用就越严重,所以既要考虑效率,也要考虑负载,曾经在某些系统中抓到了/*+parallel(a,64)*/,这位老兄!我们逻辑的CPU也不过只有32颗!
Select /*+parallel(a,6)*/count(*) from ins_offer_571 a where .....
Append nologging:Append nologging 高水位直接路径写入,减少写日志,经分,割接场景下较多使用
INSERT /*+ APPEND NOLOGGING PARALLEL(TMP_H_MD_PAR_EXT_USER_D16,3) */
INTO TMP_H_MD_PAR_EXT_USER_D16
(......)
SELECT /*+PARALLEL(R,3)*/*
from H_MD_BLL_TMN_BUSN_D_574 PARTITION(P20150406) R
/*+index(a,index_name)*/ 指定索引扫描
/*+full(a)*/ 指定全表扫描
........ 还有好多,这里不一一列举了,都在:select * from v$sql_hint
1.2 SQL PROFILE,还好有你!
某报表库有个前台的多选框操作的报表,sql的条件组合多样化,表RP_BUSI_DETAIL_NNN上存在12个索引,且多为组合索引,索引键重复情况较多,某天爆发了一下,大量的执行计划走错,统计信息收集了,游标刷出去了,没有效果。大白天的改造索引风险又太高,还好本sql有个特点,DONE_DATE字段一定要用的...... 情况紧急!DBA们还有一招 SQL PROFILE。
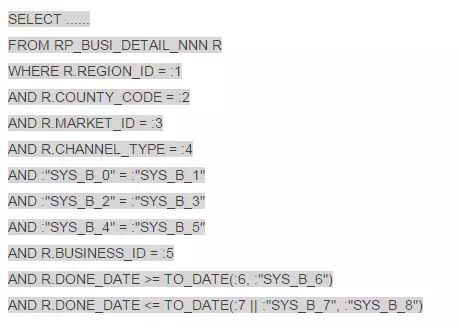
1 获取outline
select* fromtable(dbms_xplan.display_cursor('0bbt69m5yhf3p',null,'outline'));
2 创建sql profile 绑定执行计划


绑定完成后,kill执行计划有问题的SQL,数据库的性能就逐渐恢复了。后续业务梳理完成后改造了索引,各类sql的执行计划也就都稳定了。
2.少冲剑:怎么就突然慢了?缘来是你!
某核心系统的维护找过来,天天跑的一个作业这几天变慢了,原来跑1.5-2个小时的作业,现在6个小时了也没跑出来。老板说搞定他!
Sql过来了:
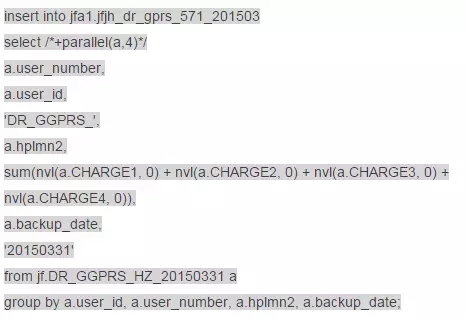
执行计划先看看
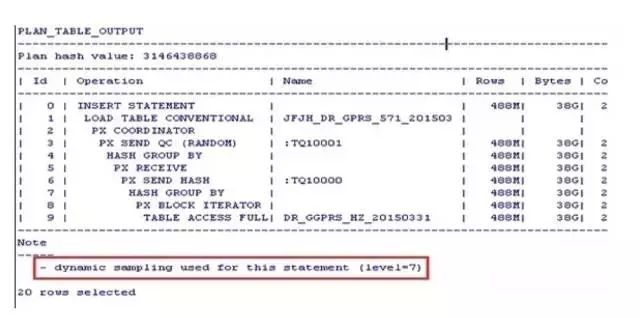
这不是在动态采样嘛!还是level=7的,难不成跑了6个小时还是在动态采样中?开个10046看看会话在什么,一看不仅仅有动态采样造成的问题呀,还有GC!

赶紧回访一下,果然这个作业一直就是跑在1号节点的。DR_GGPRS_XX_YYYYMMDD 是在2号节点入库的!那么在1号节点执行本作业就是有问题!
动态采样怎么办呢?这个DR_GGPRS_XX_YYYYMMDD表大地市超过400G,想收集统计信息是不可能的,何况作业每天仅仅跑一次,也不存在什么游标共享的问题了,干脆直接绑定执行计划,避免动态采样,在2号节点测试一下。

1590s完成!
通知应用,本作业调整到2号节点,并通过Hints /*+parallel(a,4) dynamic_sampling(a,0)*/
避免动态采样,后续反馈作业都可以在30分钟内完成。
3.少泽剑:高效的update,不能为所欲为!
某核心系统,Cpu使用率接近100%,监听的响应速度非常慢,主营业务数据入库积压严重!分析过后找到了罪魁祸首,竟然是几个循环的update语句把CPU耗尽的!
我们来看看他的威力:
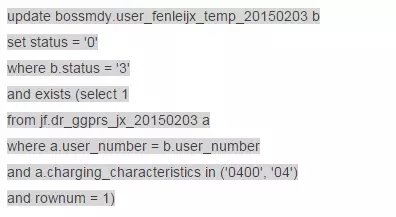
仅仅从语句的变量中就发现了一个问题:本语句是循环执行的!而且循环次数非常多!找到应用方,电话回访,果然如此!而且本作业跑了一天了好没有跑完。
匹配条件表DR_GGPRS_XX_YYYYMMDD根据地市不同在70-200G之间,数据量都是亿级,执行计划都不用看了,有没有索引都不重要了,就凭着这么循环下去,我也只能呵呵了!
被更新的表user_fenleijx_temp_YYYYMMDD很小啊,才几百MB!我前面说什么来着?!一个SQL能不能本质上被提速,看看他最终业务上需要扫描的数据就可以了,这必须可以提速啊!
我们开始吧!
1.create tmp_table
create table jf.tmp_tab1 parallel 10 nologging as select distinct user_number from jf.dr_ggprs_jx_20150203 where charging_characteristics='04';
create table jf.tmp_tab2 parallel 10 nologging as select distinct user_number from jf.dr_ggprs_jx_20150203 where charging_characteristics='0400';
2.Create unique index
create unique index jf.ind_user_number_1 on jf.tmp_tab1(user_number) nologging;
create unique index jf.ind_user_number_2 on jf.tmp_tab2(user_number) nologging;
3.高效的update
update (select a.status
from bossmdy.user_fenleijx_temp_20150203 a,
jf.tmp_tab1 b
where a.user_number = b.user_number
and a.status = '3')
set status = '0';
update (select a.status
from bossmdy.user_fenleijx_temp_20150203 a,
jf.tmp_tab2 b
where a.user_number = b.user_number
and a.status = '3')
set status = '0';
不需要循环update,只需要创建一张匹配条件为唯一性的临时表,再创建一个唯一性索引,一次性update目标表,整个工作耗时10分钟。不仅仅是高效,CPU资源的高消耗也没有了,数据库恢复了正常。
高效UPDATE方式
update (select a.col_a,b.col_b from t_tab_a a,t_tab_b b where a.id=b.id and b.col_x=’x’) c
set c.col_a=c.col_b;
要保证匹配条件b.id上有唯一性索引,如果没有唯一性索引则可以通过创建中间表的方式取出唯一性数据再创建唯一性索引如:
Create table t_tab_c as select * from t_tab_b where b.col_x=’x’;
Create unique index ind_t_tab_c on t_tab_c(id);
1.商阳剑:割接这三板斧!
说起割接,是让DBA、开发、测试等人都谈虎色变的事情,因为割接时间窗口紧张,割接资源消耗严重,割接要各种备份,割接产生大量日志,跑错了要回滚........总之风险有点高。
1.1 备份、临时表不写日志
割接中需要大量的备份、拍照,减少写日志可以有效提高效率,也能减轻数据库的归档压力,因为我们很多库上还有DSG同步,减少日志量也能避免DSG分析延迟。

3.ddl 代替 dml,减轻undo压力
将A表的数据全部插入到新建的B表,推荐的做法:
create table B tablespace tbs_data nologging as select * from B;
rename 和 CTAS (create table as select)建表是在割接场景中很受欢迎的做法
1.2 批量提交,降低UNDO/REDO压力
割接的时候有很多场景需要对大表进行DML,一次性执行大表的DML一般效率较低,而且undo表空间压力很大,一旦取消,大事物回滚非常消耗性能,可能会影响后续割接,而用游标进行一条条的提交,同样会造成redo的IO问题,也可能造成大量的log file sync事件。因此对大表进行全量或者是近全量DML时我们建议采用批量提交。
1.3 提高聚簇因子,只争朝夕!

在某个每月一次的维护作业下有如上一段脚本,本质上就是对大表I_USER_STATUS_CENTER进行按条件的批量更新,表I_USER_STATUS_CENTER上有约16亿数据,且MSISDN列上有索引,distinct number约1.1万所有,也就是每次循环符合条件的数据:16亿/1.1万=15万。
都按照步骤做了,可是跑了2个小时也没有跑完........
执行计划也看过了,走索引,没问题!表的属性暂时改成nologging了,不写日志了!够了吧?!可是速度还是不行,一分析,预计72小时以上.........在核心库上执行这样的作业哪里可以忍受?!该做的都做了,难道没办法再提速了么?
前面有个例子,操场上捡玻璃球,现在不是一个一个的捡,而是一组一组的捡,每组按照颜色不同来捡,一次捡1.5万,如果这每组球都分散在不同的地方,有了索引又如何呢,捡这么多还不是累死人?!如果说每组的球都堆在一个地方,不是分散到各个角落,那么是不是会快许多呢?!
这就是提高聚簇因子。
(1)将目标表按照MSISDN排序重建。
Alter table I_USER_STATUS_CENTER rename to I_USER_STATUS_CENTER_bak;
Create table I_USER_STATUS_CENTER tablespace tbs_data parallel 10 nologging as
Select /*+parallel(a,10)*/* from I_USER_STATUS_CENTER_bak a order by MSISDN;
Create index ind_ USER_STATUS_CENTER1 on I_USER_STATUS_CENTER(MSISDN) tablespace tbs_data parallel 10 nologging;
Alter table I_USER_STATUS_CENTER noparallel;
Alter index ind_ USER_STATUS_CENTER1 noparallel;
(2)MSISDN列上建立索引
(3)执行上面的脚本1.5小时完成
(4)修改表和索引的日志属性
Alter table I_USER_STATUS_CENTER logging;
Alter index ind_ USER_STATUS_CENTER1 logging;
(5)还可以更快么?
可以的!可以将游标按照业务字段net_id进行范围拆分,如:
SELECT NET_ID||HLR_SEGMENT BILL_ID,REGION_ID FROM RES_NUMBER_HLR where net_id >=1 and net_id<100;
SELECT NET_ID||HLR_SEGMENT BILL_ID,REGION_ID FROM RES_NUMBER_HLR where net_id >=100 and net_id<200;
........
拆分成8个游标,同时将这段程序放在不同的窗口执行,那么15分钟之内我们这个作业就会完成啦!
2.总结
本期的漫谈SQL优化就暂时讲到这里了,这里通过几个例子希望能给大家一点启发。在SQL优化过程中往往都不是那么顺利的,大部分情况下都是跟系统问题、业务需求、物理模型等紧密相连的,需要分析考虑的地方很多。兵无常势,水无常形。我们这里也没有万能公式,不过我们IT人有认真负责、灵活运用、钻研到底的态度,所以很多难题我们最终都能迎刃而解!
(本文章源自三墩IT人订阅号,经作者同意由DBA+社群进行合并整理)
文/卢进文,新炬网络资深DBA
小编精心为大家挑选了近日最受欢迎的几篇热文↓↓↓
(关注订阅号dbaplus,回复以下数字,即可获取相应文章)
回复011,看邹德裕《数据库运维工具化:一切从“简”,只为DBA更轻松》。
回复012,看马育义《Oracle内核系列3-揭秘ASM磁盘头信息》。
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看杨德胜《Oracle故障日志采集“神助攻”—TFA工具详解》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看卢钧轶《揭秘Facebook数据库备份策略》;
回复019,看杨建荣《看似简单的dual,其实深藏玄机》;
回复020,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721