
茹作军,曾任职我查查运维工程师、1号店MySQL DBA,现就职于平安好医生。Lepus开源数据库监控系统作者(www.lepus.cc)。
业务与技术往往是共同前进的,2016年,我加入平安好医生,在业务快速发展的同时,我们的数据库自动化平台也得到了快速的建设和发展。
一、背景
两年多的时间里,我们DBA Team快速完成了数据库自动化、白屏化、闭环化、服务化的建设。完成了JKDB数据库自动化平台(含元数据管理、自动化部署调度系统、监控系统、备份系统、高可用和在线切换、容量趋势分析规划、校验中心等)、数据库自助查询平台、权限申请和审批平台、自助变更执行平台、流程引擎、工单系统、敏感信息探测系统等等。
在这期间,除了偶尔故障和特殊支持之外,DBA基本不需要登录服务器去部署和操作数据。从2016年到现在,我们管理的数据库实例大概翻了3倍,但是DBA人数基本没有变化,目前是4个DBA维护了约1000+的MySQL实例、1500+Redis实例,另外还维护着若干PostgreSQL / Oracle / MongoDB / Hbase集群。
本文就将针对我们DBA Team完成的数据库自动化平台构建和期间的建设思路做一些简单介绍,主要分享前期标准化构建和自动化模型搭建思路方面的部分。后续如果大家有兴趣,我可以更加深入的介绍一下自动化平台其他方面的内容。
2016年,当我入职公司时,大概经过了两周的熟悉,俨然发现公司数据库自动化的影子。
其一是标准化,标准化是自动化的重要前提。那个时候,我们这边标准化是做得比较好的,从OS的标准化到DB层的标准化都有着统一的标准。比如OS的操作系统版本、文件系统格式、磁盘挂载点、预装软件、内核参数等等,我们所有MySQL服务器基本都是一致的。
这里我们是怎么做到保持一致的呢?
首先是我们DBA对其中一台服务器经过初始化设置和优化,比如按数据库的最优策略调整内核参数,分区和挂在磁盘,预装pt-tool \ MHA Node \ Xtrbackup \ Innotop \ oak-tool等数据库常用的管理软件,然后交付给运维同学进行打包镜像,之后所有交付给DBA的服务器都是按此镜像进行部署。这样一来,我们的OS服务器就非常标准化了,同时也预装了我们常用的管理工具。
我们的数据库也有自己的部署标准,比如配置文件标准化,除了部分可调参数是变量,其他参数全部使用标准化模板;另外像MySQL的安装目录、数据目录、二进制日志目录、临时文件目录都有统一的标准,根据不同的实例端口来区分。
当然MySQL严格要做到标准化,在未做到自动化部署之前,是比较困难的,困难的不是部署技术,而是规则意识。通常一个公司都有好多个DBA共同管理数据库,由于之前的工作习惯大家喜欢按照自己的方式来部署数据库,或者没有标准部署规则、有规则但是没有严格遵守,都是无法做到标准化的。我们是从一开始就做了标准化规则和自动化部署脚本,所以我们目前线上所有数据库的部署都是标准化的,为后续自动化平台建设打下了非常好的基础。
例如,我们在管理机使用如下命令,则会在对应的IP服务器上创建一个innodb_buffer_pool等于10GB的数据库实例,端口为3306,挂载设备为fioa,版本为MySQL-5.6.28-OS7-x86_64,数据库编码为utf8:
自动化创建的实例按照端口进行标准化部署,如下所示,某台服务器安装了3306、3307、3308三个端口,则部署目录如下所示:
配置文件路径:
/etc/my3306.cnf
/etc/my3307.cnf
/etc/my3308.cnf
数据库安装路径:
/storage/fioa/mysql3306:
binlog
data
mysql-error.log
mysql-tmpdir
/storage/fioa/mysql3307:
binlog
data
mysql-error.log
mysql-tmpdir
/storage/fioa/mysql3308:
binlog
data
mysql-error.log
mysql-tmpdir
这样部署的数据库达到了标准化的水平,所以我们DBA只要知道IP和端口,就可以很容易地知道这个实例的所有信息,无疑是自动化的良好基石。
二、自动化任务平台构建
有了好的标准化基础,我们就开始着手构建平台了。
既然作为平台,那么WEB管理界面、任务调度、API服务几个核心部分是不可以少的。下面展示一个建设初期的一个基础架构:

如上图所示,自上而下,系统核心部分由3层架构组成:
第一层为WEB控制层;
第二层为任务管理层和数据采集层,用于任何调度管理和数据的交互处理;
第三层为工作模块层,用于实现各功能的功能,比如安装实例、配置Replication、配置MHA、创建数据库、授权等等,这些都是由不同的底层模块来完成,通常由一系列脚本组成。
同时系统将提供Restful API用于内部数据更新,提供HTTP API用于外部系统对接,例如和CMDB、发布平台等平时实现数据共享和任务对接,提供消息通知功能用于发送各类报警和服务类的通知功能,提供任务上报功能用于各工作模块和WEB层的信息对接。
当然,后期我们数据库平台和中间件团队、SA团队、配置中心团队完成了很多数据和功能的对接,打造了数据库管理的闭环,例如CDMD创建好DB的资源后会通过我们的API将机器信息推送到元数据中心,我们也会调用DNS平台的服务接口来更改DNS,或者我们的平台自动化部署完数据库后会将域名、端口、授权用户密码自动推送到发布平台实现数据库自动配置,开发在配置中心申请git库时就可以同步申请数据库等等。
通过DB平台和公司其他部门的平台相互打通,减少了很多人为操作环节,实现了数据库管理闭环。
如下图所示为我们平台更加详细的架构图:

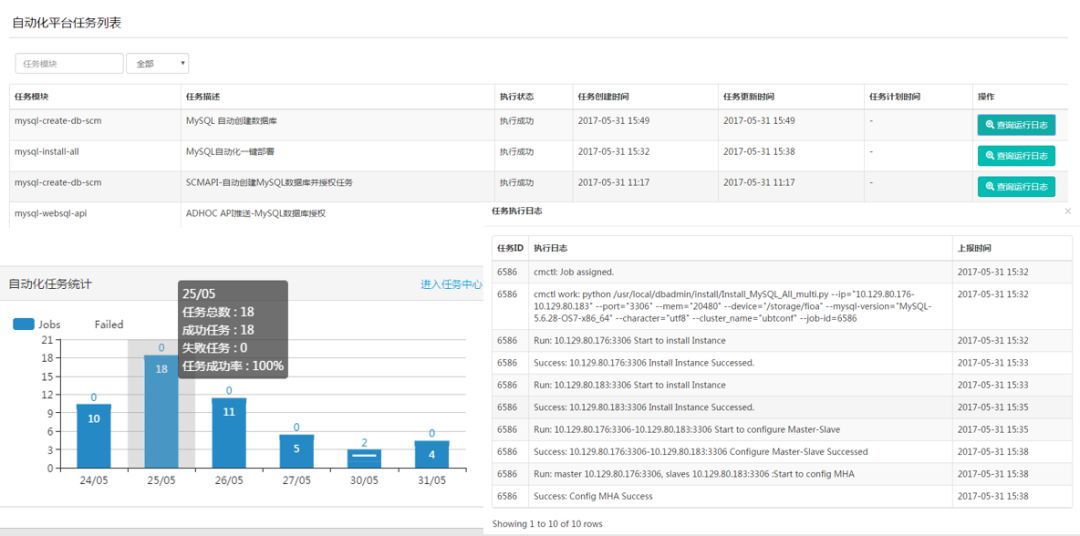
系统的核心是任务调度管理层,我们任务管理的界面如下所示,可以看到每个任务都有一个任务模块名称,并实时记录任务执行状态和执行日志:
三、关于模块化设计构建
在上面我们简单介绍了系统的基础架构,里面提到了底层任务模块,比如安装实例、创建主从模块等等,那么这些模块底层如何优雅地设计呢?
我们平台从开始设计时后端代码层就遵循高内聚、低耦合的设计思想进了模块化开发,这是我们后端设计的核心思想。
很多人在想,代码实现功能不就好了吗?还需要什么设计思想?这可能也就是开发与运维同学的思维差别。
我们知道运维同学常常忙于很多琐碎的事情,效率优先,也习惯于脚本化开发,可能分分钟就写一个脚本实现某个功能。但是在平台建设中,这种方式是不可取的。如果代码没有规范的思想指导,当多人协同开发的过程中,很难进行项目的管理和跟进。
我们在设计时,在遵照模块化开发思想的同时,根据任务情况,设计出了任务三层调度模式,类似堆积木方式,可以很快地完成不同需求的底层任务模块,同时可维护性可非常高。另外就是复用和解耦,模块不允许同级模块相互调用和依赖,只允许高级模块调用低级模块。
如下面所示:
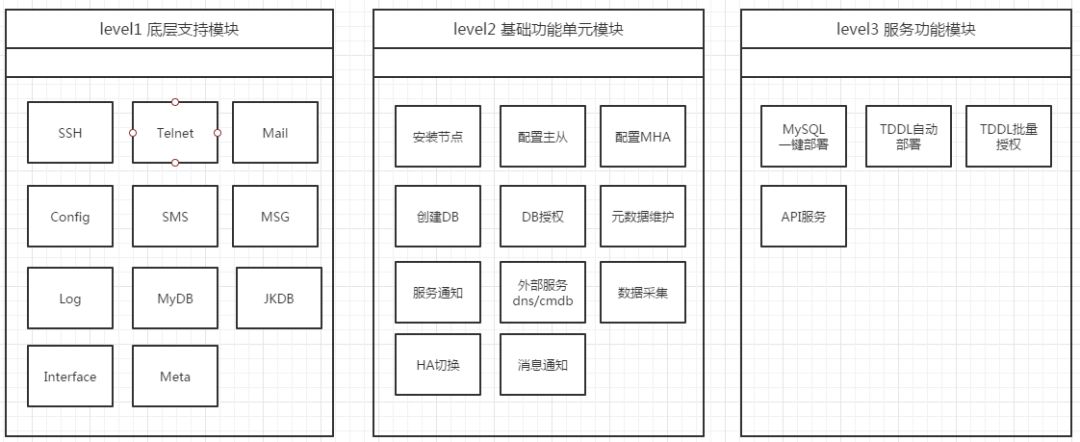
上面这幅图可以很好的解释底层的三级模块调用流程:
Level 1为底层支持模块:例如SSH操作模块、MySQL连接和操作模块、消息模块(短信,邮件,内部信息)、日志模块、外部接口模块(DNS变更,CDMD同步等)、元数据维护模块(meatdata)等。
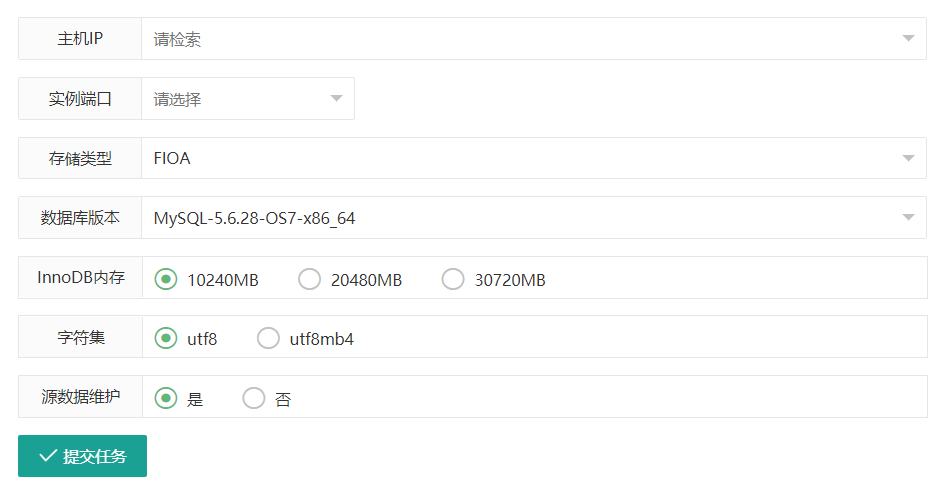
Level 2为基础单元模块:比如安装MySQL节点、配置主从、配置MHA、创建数据库、DB授权等等,这些都是二级模块,基本就是完成某一个特定功能。注意Level 2里代码除了业务逻辑部分,其余只需要调用Level 1的模块即可。例如下面是一个安装MySQL实例的截图,属于二级模块:
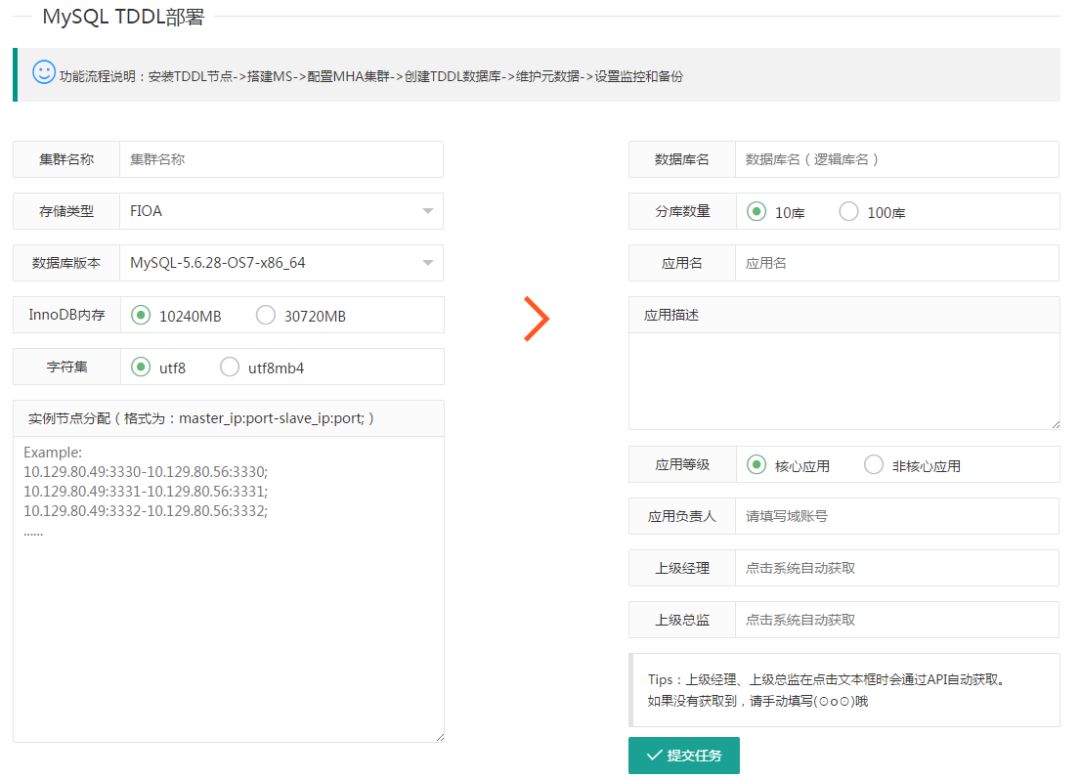
Level 3则为服务模块:真正经常使用的模块,都是调用Level 2模块来进行封装的。例如在一般业务方使用数据库中,DBA至少需要安装2个实例,配置个主从复制,也需要配置MHA,当然备份和监控配置也不能少。这些工作一个DBA来完成通常大半天时间过去了。那么如果需要部署10套呢?会花费更多的时间。所以这种情况下就需要一键部署,一键通通搞定。说到这里,还有一个问题——大家大概也注意到了安装实例、创建数据库等这些单一模块在Level 2模块都有,那么Level 3干嘛呢?其实就是调用Level 2就可以了。如下是一键部署页面截图,DBA填写好提交任务即可,剩下的时候就可以处理其他工作了:
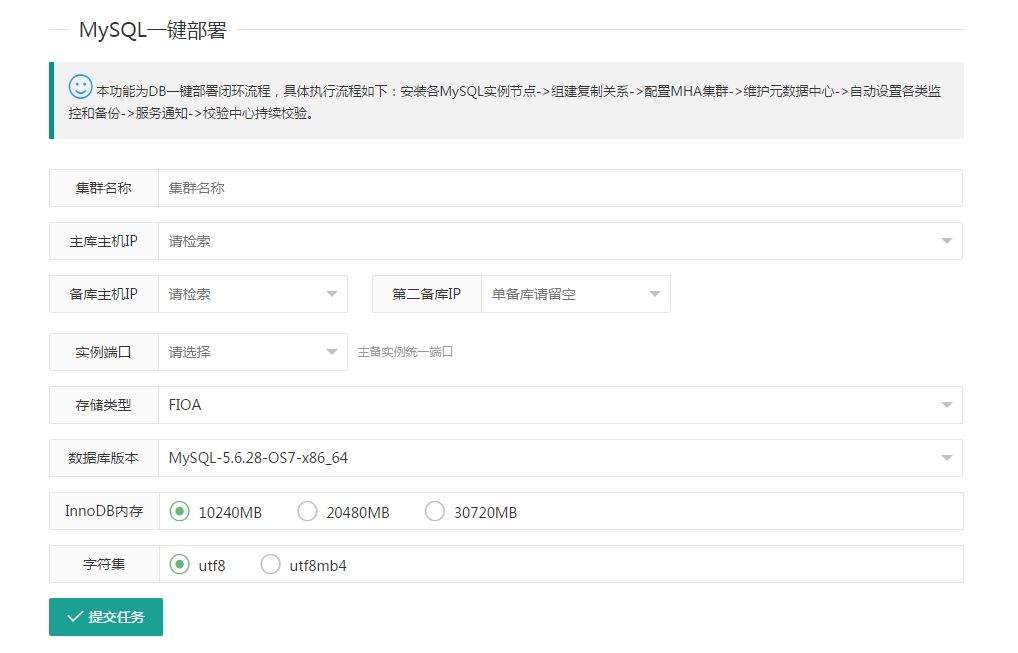
然后我们监控上报的任务日志可以看到底层执行过程,大家可以看到任务会创建2个实例,然后配置了主从,最后配置了MHA,当然这里面还有一些元数据维护,备份和监控开关设置等等,其实在后台已经完成了。大概6分钟,完成了一个DBA半天的工作,并且保证了部署的数据库都是标准化的,不同DBA部署没有任何差异。
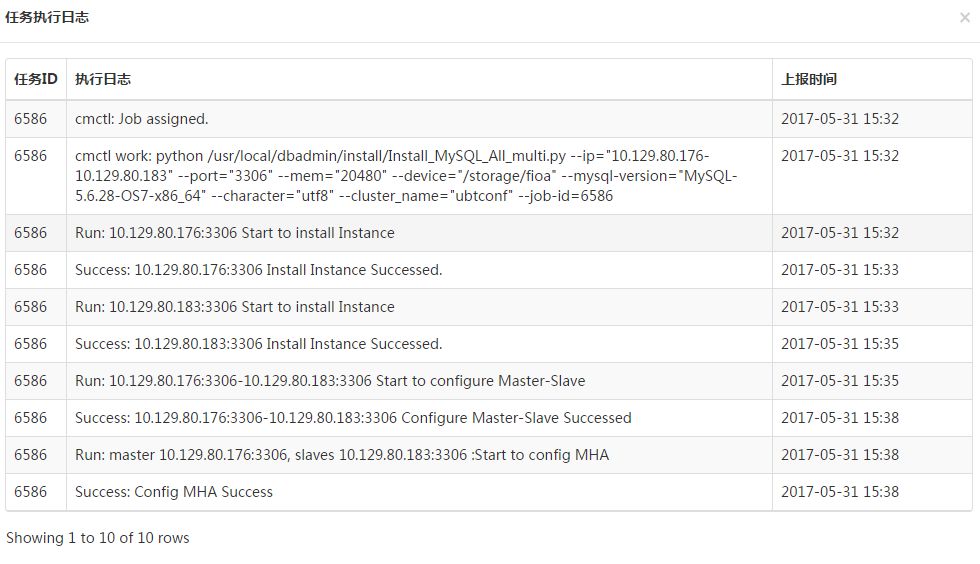
再举另外一个场景例子,通常公司对核心大业务会做TDDL分库分表,比如十库百表、百库千表,需要部署在不同的物理机,这时候我们就开发了TDDL批量部署模块,基本就是封装并行任务调用Level 2模块的各个模块,例如创建100个数据库sharding的TDDL集群,无非就是并行调用200次安装MySQL实例的模块,然后调用100次配置主从,调用100次配置MHA,最后发个消息通知。一般手工操作需要1-2天时间的任务几十分钟就完成了。
有了上述自动化任务调度平台和设计规范作为基础,我们DBA基本都很快参与进行了进行模块开发。模块开发的好处就是大家很容易上手开发,甚至之前有不会Python的同学,在简单学习了Python之后也能照猫画虎很快完成一个模块。
在大家的共同努力下,MySQL以及Redis日常部署和维护工作都实现了任务调度化管理。通常需要大家登录服务器的操作现在基本都在WEB界面端就完成了。一般除了需要登服务器定位问题和处理线上故障,基本就白屏化了数据库管理。
这样下来,对于整个公司而言效率高了,DBA不需要那么多了,数据库人为故障也少了;但对个人而言,职业工作就受到了挑战,机会也少了,所以个人的发展只能说主要是看自己,靠自己。
最后讲一点题外话,经常看到一些文章在讲数据库自动化、未来AI智能化,预测将来DBA可能会失业。这个观点我是二分之一认同的:随着很多公司的自动化越来越完善,可能需要的DBA会越来越少,但我认为DBA这个岗位在任何时候都不会被淘汰。
虽然数据库完全自动化后,难免对DBA的职业发展造成影响,但换个角度来看,留给DBA思考创新、提升自我价值的时间也更多了。其实从数据库在公司的重要性和敏感性来看,从业务向技术转换过程中,DBA作为数据库的专业评审员,发挥的作用是其他岗位所无法替代的。而未来DBA应该做的,是试着转变观念去接收一些新事物,比如可以尝试开发,参与到平台开发中,或者学习一些大数据、机器学习相关的技能,又或者更深入钻研数据库。我相信,只要自己努力,是金子总会发光的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721