
作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
在《SQL优化案例之五味杂陈》之后的若干天,开发人员来到我座位,不说话,只是端看着我,还似笑非笑。看着这诡异的一幕,从他不怀好意的神情中,隐隐感觉到一丝丝不祥之感。果真,又出现了性能问题。刹那间,我心里瘆得慌,因为当时我曾断言,在经过对数据模型进行大刀阔斧的优化后,性能撑个一年两年的是没问题的。而现在还不到一个月的时间,就在开发人员痴痴的笑声中被啪啪啪打脸了。

我故作镇定地与开发做了一番交谈:
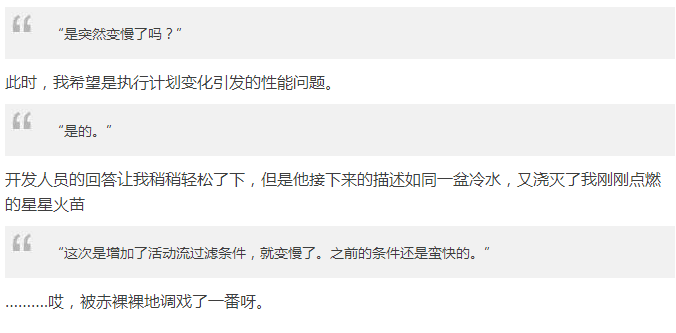
找开发人员拿到了SQL,如下:

这个SQL我是相当的熟悉了,根据开发人员的说法,只是比之前的SQL多了一个过滤条件:
这个非常简单的过滤条件居然会有如此大的魔力,将我千辛万苦优化的SQL,轻而易举地让性能从2秒变成了90秒,不仅打回原形,还“变本加厉”了。面对如此赤裸裸的挑衅,也激发了我的应战情绪。
在展开分析之前,结合之前的优化过程,我梳理了下思路:
这次性能问题特征很明显:由一个过滤条件引发的性能问题;
增加一个过滤条件,正常情况下对性能的影响不会太大,但是可能会对执行计划产生一系列影响,比如如果该过滤字段有索引,很可能会将之前的TABLE ACESS FULL变成INDEX RANGE SCAN,继而,其与其他表的关联方式会从之前的NESTED LOOP变成HASH JOIN。
因此,我初步判定这个条件过滤引发了执行计划的变化,为了印证我的判定,我对比了执行计划,如下:
我先来看下带有TASK_FLOW_ID条件的执行计划
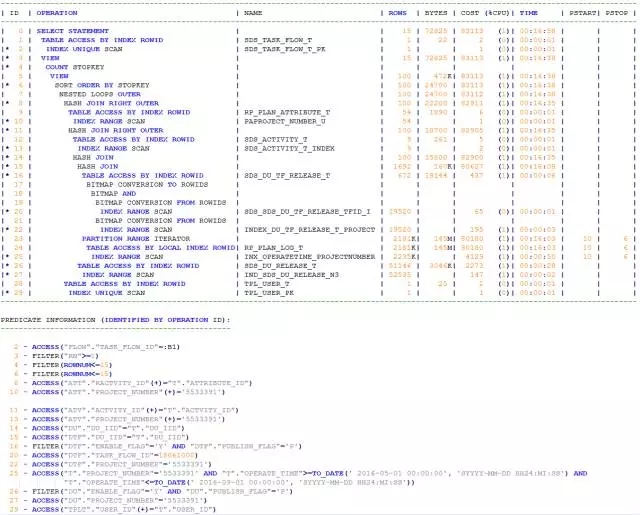
简单解读如下:
驱动表是SDS_DU_TF_RELEASE_T,该表的访问方式是TABLE ACCESS BY INDEX ROWID,因为在该表上,分别在字段TASK_FLOW_ID和PROJECT_NUMBER上创建了索引,所以ORACLE优化器选择了两个索引BITMAP AND操作。需要注意的是,此时出现的索引SDS_SDS_DU_TF_RELEASE_TFID_I正是因为过滤条件AND (T1.TASKLOWIDS IN (18061000)) 引起的;
SQL中的主体表RP_PLAN_LOG_T的访问方式是TABLE ACESS BY LOCAL INDEX ROWID,被访问的索引是INX_OPERATETIME_PROJECTNUMBER,即过滤条件中PROJECT_NUMBER和OPERATE_TIME的字段组合索引。由于OPERATE_TIME命中的是多个分区,所以最终是PARTITION RANGE ITERATOR;
结果1和结果2两个集合通过DU_IID做了HASH JOIN。
接下来我们看看没有TASK_FLOW_ID过滤条件的执行计划:
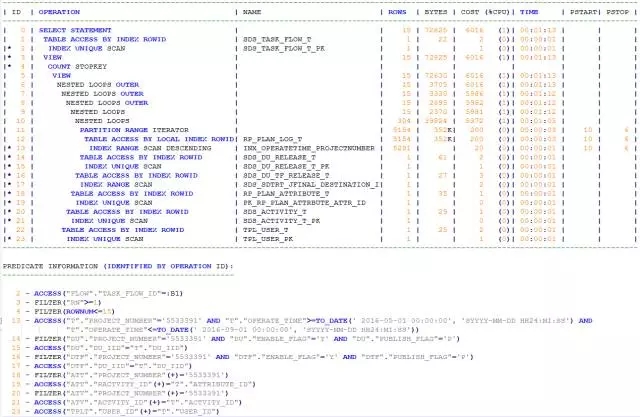
驱动表为SQL中的主体表RP_PLAN_LOG_T,访问方式是TABLE ACESS BY LOCAL INDEX ROWID,被访问的索引是INX_OPERATETIME_PROJECTNUMBER,即过滤条件中PROJECT_NUMBER和OPERATE_TIME的字段组合索引。由于OPERATE_TIME命中的是多个分区,所以最终是PARTITION RANGE ITERATOR;
SDS_DU_TF_RELEASE_T,该表的访问方式是TABLE ACCESS BY INDEX ROWID;
结果集1和结果集2通过DU_IID,进行了NESTED LOOPS关联。
通过上述对比,我们发现:
RP_PLAN_LOG_T的访问方式是没有变化的,前后都是:

驱动表发生了变化,没有TASK_FLOW_ID过滤条件时,驱动表为RP_PLAN_LOG_T表。而后变成了SDS_DU_TF_RELEASE_T
RP_PLAN_LOG_T与SDS_DU_TF_RELEASE_T的关联方式也发生了变化,没有TASK_FLOW_ID过滤条件时,关联方式为NESTED LOOPS,而后变成了HASH JOIN
至此,我的心情有些失落。一开始,我是做了打一场大战硬战的准备,而这场战斗才刚开始,就似乎要结束了。这个起初“山雨欲来风满楼,剑拔弩张马齐嘶”的性能问题突然变成了一个非常常见又平常的案例:由一个查询条件引发了执行计划变化,从而导致了性能问题。而此类问题的药方也通用:干扰Oracle优化器。比如这次的方案,可以通过HINT,或者LEADING指定驱动表,或者NO_INDEX强制不使用TASK_FLOW_ID的索引,或者USE_NL指定关联方式。
该案例的优化工作就这样在大起大落中平淡收场了。然而,有两个问题并没有随着优化结束而水落石出,其一是为何增加了一个过滤条件会引发执行计划变化?其二是为何RP_PLAN_LOG_T做驱动表的性能会高?尤其是第二个问题,要知道,RP_PLAN_LOG_T通过PROJECT_NUMBER和OPERATE_TIME综合过滤后,其数据量达到了百万级,是数据量最大的结果集,这明显有违小表驱动的基本原理。
我们先看看第一个问题,这个问题相对简单。为了弄清这个问题,我们首先要看看SDS_DU_TF_RELEASE_T的模型结构,在该SQL中,关于这个表的关键字段有三个字段,分别是DU_IID、TASK_FLOW_ID、PROJECT_NUMBER。三者之间的关系如下:

从PROJECT_NUMBER—>TASK_FLOW_ID—>DU_IID,数据粒度越来越细,所以当TASK_FLOW_ID作为了过滤条件,Oracle就认为可以过滤掉大量的数据,而且TASK_FLOW_ID上又存在索引,从而认定可以作为驱动表。
现在重点看看第二个问题:为何RP_PLAN_LOG_T做驱动表的性能会高?
带着这个疑问,为了便于说明,我们简化下这个SQL,砍掉枝枝叶叶,只保留RP_PLAN_LOG_T这个“孤家寡人”,同时我们也略作改动,即将ORDER BY的字段由OPERATE_TIME修改为CDESCRIPTOIN。如下:
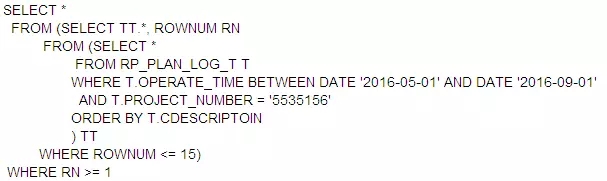
其中RP_PLAN_LOG_T的表结构如下:
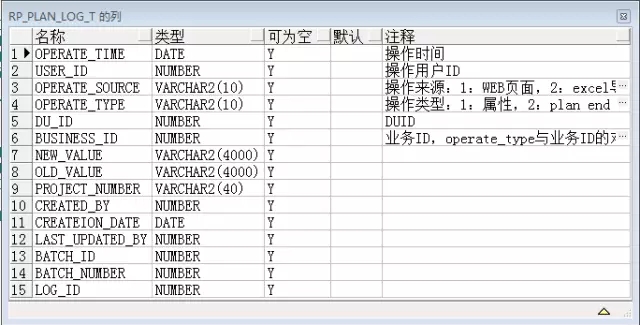
表的索引如下:

执行计划如下:

由于满足条件的数据量近170万,整个SQL耗时达1.5S,而执行计划与我们预期是一样的,主要包含两步骤:
先通过本地索引获取到符合条件的数据(INDEX RANGE SCAN)
再根据CDESCRIPTOIN字段排序(SORT ORDER BY STOPKEY)
从成本看,很大一部分成本消耗在SORT上。现在我们将ORDER BY CDESCRIPTOIN还原成ORDER BY OPERATE_TIME。那么,在性能上会发生什么神奇的效果呢?
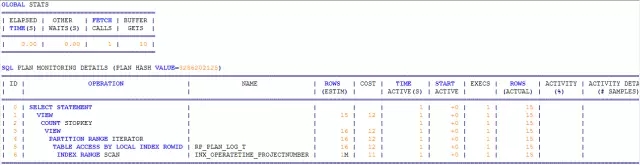
索引还是那个索引,表还是那个表,只是SORT ORDER BY STOPKEY不见了,成本降低了,执行效率达到了毫秒级。
这里,有一个大写的疑问:明明是ORDER BY OPERATE_TIME,为何在执行计划里面没有SORT ORDER BY STOPKEY步骤了?难道是Oracle优化器的BUG?此时,你会不会因为发现了Oracle的BUG而欢呼雀跃?很遗憾的告诉你,这并非Oracle的BUG,反而是Oracle优化器的高明之处。
索引的特性之一就是有序,我们先通过OPERATE_TIME字段上的索引获取到了有序的OPERATE_TIME(及其对应的ROWID),以此为基础,通过TABLE ACCESS BY LOCAL INDEX ROWID获取其它字段信息,这样得到的结果集自然是已经按照OPERATE_TIME排好序的有序结果:
请问,这还需要“教条”般的再次排序吗?
除了大写的疑问外,还有一个小写的疑问:不考虑排序,同样的查询条件,同样的索引扫描,为何成本差异如此之大?在无SORT的情况下,INDEX RANGE SCAN的COST值为11,而如果进行了SORT,COST值为1910。
难道是SORT会影响到INDEX RANGE SCAN的成本?事实上ORACLE引擎是先执行INDEX RANGE SCAN,再执行SORT,也只能是:INDEX RANGE SCAN的结果集会影响到SORT的成本,因为INDEX RANGE SCAN的结果集越大,SORT的成本会越高。
那么,这里面到底发生了什么呢?还得要从根本说起:在正常情况下,我们如果想要获取前N条数据,就必须要按照既定字段排序,那就意味着我们首先要获取到全部的数据;但是,如果我们拿到的是已经按照既定字段排好序的数据,那么就可以直接获取前N条数据,而无需获取全部数据。这就是同样是INDEX RANGE SCAN,而COST相距甚远的玄妙所在。
这个猜想也是可以在执行计划中得到印证:就是INDEX RANGE SCAN这步操作的实际返回ROWS,如下:
看到这里,你是否会有些小激动?因为你发现:在排序字段上创建一个索引,就能将分页时排序产生的性能开销幻灭于无形。其实并非绝对。为了印证,我们继续以上述案例为例举证。
在RP_PLAN_LOG_T表中,字段PLAN_LOG_ID的值由序列号填充,并且在上面创建了UNIQUE INDEX:

现在,我们将ORDER BY的字段由OPERATE_TIME修改为PLAN_LOG_ID,我们来看看执行计划:
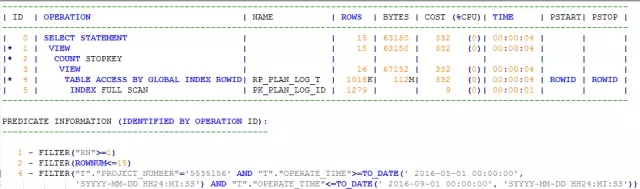
嘿,还真如我们所料:利用了索引数据有序的特性,COST也相当得低。
是真实的性能呢?通过SQL*MONITOR,我们发现耗时竟达66S。
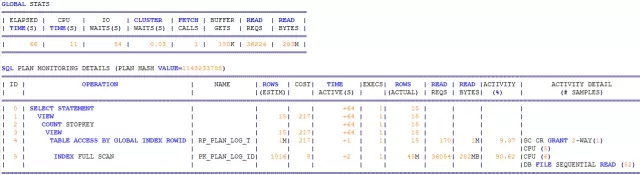
其中IO等待耗时54S,为何?原来这个执行计划实际加载了45M的数据量,这个就是全表的数据量。
由此可见,理想是丰满的,而现实却一地排骨。利用索引数据有序的特性做分页排序,是要讲究缘分的,可遇而不可求。必须要满足如下两个条件:
排序字段上必须要建有(前缀)索引;
在多表关联的SQL中,排序字段所在表,必须为执行计划中的驱动表
否则,反而事与愿违适得其反。
至此,为何RP_PLAN_LOG_T做驱动表的性能会高?这个问题就迎刃而解了。
我们再次通过SQL*MONITOR来回顾下执行计划:
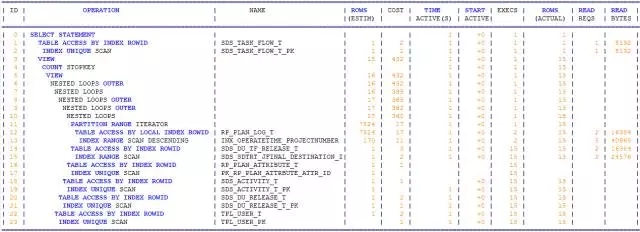
表面上,我们看到的是通过PROJECT_NUMBER和OPERATE_TIME过滤后的结果集多大170万,而事实上,Oracle优化器巧妙的利用了OPERATE_TIME索引字段的排序:
只获取了15条记录,用这15条记录来驱动,即便千万级集合,也会是弹指一挥间;
省却了庞大结果集排序的开销,SORT的COST灰飞烟灭。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721