
观察一:三类大模型繁荣发展,筑牢AI4SE的AI能力底座
智能化软件工程领域持续涌现出以代码大模型为首的三类大模型,代码大模型数量最多,运维和测试大模型次之。代码大模型以其强大的代码理解注释、代码生成补全、代码检查优化、研发问答等能力,助力软件编码效率和质量的提升。运维大模型当前重点关注运维知识问答、工单处理等方面,未来将从故障识别、故障预测、运维安全等多维度推动AIOps全过程智能水平提升。测试大模型相较而言数量较少,目前大量单测用例生成依靠通用大模型或代码大模型而实现高覆盖率和高完备度,测试大模型需寻找到测试阶段独特的发力点,从真正意义上提升测试能力。
图1 智能化软件工程相关大模型一览
观察二:智能化能力在软件工程多环节赋能,成效渐显
中国信息通信研究院持续开展智能化软件工程行业研究,并根据AI4SE“银弹”案例数据、调查问卷反馈数据及企业走访调研数据,对行业进行深度观察和分析。
一方面,软件开发和测试阶段应用AI提效最明显。受访企业中,超70%的企业在软件开发阶段应用了大模型等AI技术,其次是软件测试也超过了60%。而在软件工程各阶段中,测试和开发过程应用AI技术后提效(人效)最为明显,其次是运维。

图2 软件工程各阶段AI技术应用比例及提效数据
另一方面,智能编码工具应用成效初显。近半数受访企业的代码采纳率集中于20%~40%之间,超60%受访企业的代码生成占比集中于在10%~30%之间。代码采纳率是指智能生成的代码中被开发人员采纳的比例,代码生成占比是指项目代码总数中智能生成的代码的占比。
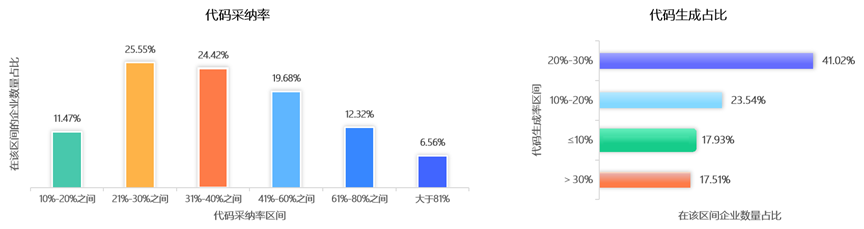
图3 代码采纳率及代码生成占比
观察三:智能编码能力建设成熟度逐步提升
从调研的三十多家金融、互联网、软件服务等领域企业建设情况看,目前业界普遍在简单的基础功能建设上发力较多,在代码静态检查、研发问答、代码生成与补全等能力上的建设较为成熟,在代码动态检查、开发文档生成、代码架构分析等能力方面的建设在持续改进提升,这些方面将考虑实际需求和技术实现难度逐步推进。
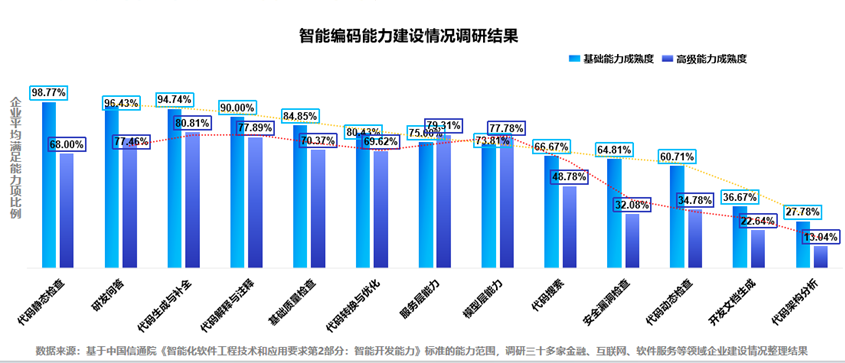
图4 智能编码能力建设情况调研结果
观察四:智能测试成为2024年关注焦点,落地过程诸多挑战亟待突破
一方面大模型的加持,从不同程度上辅助测试领域各环节提升智能化水平。大模型有望重塑测试计划、测试设计、测试执行、测试报告和测试分析等测试领域各环节,大模型擅长文稿生成、单测用例、测试数据和脚本的生成,其他方面有待提升改进。
另一方面当前智能测试面临着模型技术层、工程化层、应用层多方面的挑战。在模型技术上,大模型的理解能力有限,当前大多数模型对多模态的需求文档和复杂的工程架构的理解不够准确,且高质量的私域调优数据准备较为困难。在工程化上,一是基于Agent构建的智能测试方案,目前仅限于一些简单任务和场景,而多样化的测试环境中,Agent受到技术和算法能力的限制,其可落地的具体方向仍有待探索;二是新型智能化能力与已有测试工具的融合问题待突破;三是全面的模型能力评估有待研究;四是模型安全可信仍有待加强。在应用上,存在着生成数据内容关联性差、应用成效的统计缺失、智能化水平的衡量无规范等挑战。
作者简介
秦思思,中国信息通信研究院人工智能研究所高级工程师,主要研究方向为智能化软件工程、大模型工程化、MLOps、MaaS、模型评测等,牵头系列标准的编制(代码大模型和智能开发能力标准已对外发布)、评测、咨询等工作。担任AIIA智能化软件工程(AI4SE)工作组组长。
联系方式:
13488684897
qinsisi@caict.ac.cn
胡慧,中国信息通信研究院人工智能研究所工程师,主要研究方向为智能化软件工程、大模型工程化、MLOps等,重点参与系列标准的编制、评测、咨询等工作。担任AIIA智能化软件工程(AI4SE)工作组联系人。
联系方式:
17371328072
huhui@caict.ac.cn
本文内容源自:CAICT数字化治理







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721