
由于HBase团队的组织架构变动,使得去年双11的备战重责落在了几杆稚嫩的小枪身上了,不是双11运维、开发新人就是应届毕业生。备战过程的『点』,若从DB集群老核心业务整合开始算起,战役从去年5月就打响了第一枪。备战过程的『面』,涉及支付宝、安全部、菜鸟、天猫、淘宝技术部、共享业务事业部、航旅、阿里云等几乎所有BU。在此我想从HBase系统层面和业务层面两个大方向谈谈整个备战过程,进行一次较为全面的总结。
系统层面,经历了从3u5.5至3u7.5.1的发展,磨砺出了七剑,为HBase系统的性能、稳定性、高可用、单元化保驾护航。所谓开发团队制造弹药,PE团队落地优化。有了这些利剑和神兵,我们才能披荆斩棘所向披靡。
ExploringCompaction成为默认选举算法
Replication的优化
单元化及Diamond整合
MTTR1期
限制大scan请求的资源使用
混合存储
基于虚拟节点的跨ZK集群切库

七剑之莫问:
ExploringCompaction成为默认选举算法
HBase本身有非常多的业务是以BulkLoad的方式进行离线数据写入的,对应的在云端插件为HBaseBulkWriter,优点为对线上影响小(不占用服务端线程池),代价为丢失本地化率及带来部分IO毛刺。3u5.5之前的版本采用的默认文件选择策略,在BulkLoad的场景下存在缺陷,会导致compaction积压(IO不能有效地去做文件合并),文件数无法控制,影响在线实时读性能。3u5.5彻底完成了社区的Exploring选举算法的引入,极大优化了该场景甚至是泛化场景下的文件compaction。
HBase是采用LSM树作为存储引擎的,compaction的目的是减少文件数和删除无用的数据,优化读性能,准则是用最小的IO代价去减少最多的文件数。Compaction有2个原则:
所有StoreFile按照顺序进行排列(此顺序为:老文件在前,新文件在后。BulkLoad进来的文件总是排在HBase内部生成的文件之前。详细的顺序排列参考Store#sortAndClone);
参与compaction的文件必须是连续的。
先来看看默认的选举算法RatioBasedCompaction:
从Storefile列表中,从老到新(即队列中从头到尾),挑选起始的那个StoreFile,挑选的依据是: 文件大小不能超过配置中的max size(默认2GB),并且文件大小不能超过后面文件的大小sum*ratio(默认为1.2倍);
决定终止的StoreFile,一般就是列表中的最后一个文件,但是要求参与compaction的文件数不能超过配置的max files数目,默认为10个,如果超过10个了,那么终止的StoreFile为 起始位置+max files ;
BulkLoad的场景下,会产生很多小文件。举个例子,典型的会有如下的file list(ratio=1):300MB(BulkLoad), 5MB(BulkLoad), 1GB, 23MB, 12MB, 12MB。那么默认的ratio算法会选择:5MB, 1GB, 23MB, 12MB, 12MB,这样我们的IO代价大,收效甚微(打开5个文件句柄,读1076MB,写1076MB,减少4个文件)。其实这样的情况下,我们最想要得到的是: 23MB, 12MB, 12 MB。因为这样是以最小的IO代价(打开4个句柄,读47MB、写47MB),减少2个文件。再举个例子,flie list为:20MB(BulkLoad), 20MB(BulkLoad), 1GB, 4MB, 3MB, 2MB, 1MB,默认算法会选择:20MB, 20MB, 1GB, 4MB, 3MB, 2MB, 1MB,打开8个句柄,读1074MB、写1074MB,减少6个文件;但是我们想要的选择是: 4MB, 3MB, 2MB, 1MB,打开5个句柄,读10MB、写10MB,减少3个文件。
因此ExploringCompaction算法就非常适合我们,检查Storefile列表的每一个子队列,从中找出一个最优子队列,参与compaction:
队列中的每一个文件符合ratio准则;
1条件下拥有更多的文件数目 ;
1, 2 条件下拥有更小的文件大小。
相较于默认的算法,Exploring更为『智能』,是七剑中的莫问。
七剑之游龙:Replication的优化
Replication是HBase实现集群内部同步的重要组件,是业务高可用、单元化的基础,2015年我们主要在优化同步积压和积压影响组级别隔离两方面做了努力。
主线程shipEdits多线程化。Alimonitor是双11需要P1级别保障的业务,它的历史监控绘图数据存储在HBase,日常是有主备实时同步进行高可用保障的,主库主要有宕机或者1分钟以上的抖动,就会立刻执行切库,保障系统的稳定。但是2015年年初,有一个问题困扰我们,就是alimonitor因为业务特性,存在和时间序列相关的持续热点,这个热点也不是很热,大约就是其他节点的+10%。主备库同步经常积压,造成即使可以切库,也会有大量监控绘图有断图的现象。于是我们对Replication进行了改造,用多线程的方式,将这些数据推送(shipEdits)到备集群的多台regionserver。即shipEdits动作,由单线程改为多线程,而hlog的read动作,仍然保持单线程。受益的业务不仅包括Alimonitor,也涉及到依赖中美同步的广大AE和ICBU的同胞们、以及所有单元化、高可用架构用户。似七剑游龙,攻势凶猛,分分钟消化同步积压,为主备库高可用保驾护航。
积压影响组级别隔离。HBase早在2013年就开始了大集群运维策略,一个业务或一个BU的业务隔离出一个分组,底层HDFS可以共享IO,并且可以容易地进行资源调度。引入了Replication后有一个问题,就是GroupA的同步产生了积压,会导致备库所有业务的同步数据积压。因此,我们对其进行了改造,在选择备库代理发出put请求的服务器时,指定在和主库group name一致分组下的机器中进行选择。这样即使GroupA的同步积压,也不会波及其他『无辜』的业务分组了。
七剑之天瀑:单元化及diamond整合
异地多活、单元化等关键词充斥着2015上半年,HBase也有部分业务涉及单元化的一中心、多单元的部署架构需求。3u7版本前的HBase只支持主主(Peer To Peer)同步备份,无法支持单元化。
实现单元化过程中的主要通过数据打标的办法解决了数据环路问题,并且开发出了一套可视化的运维控制台。Replication的单元化功能上线后,可以支持如下图的复杂部署,满足单元化的需求:
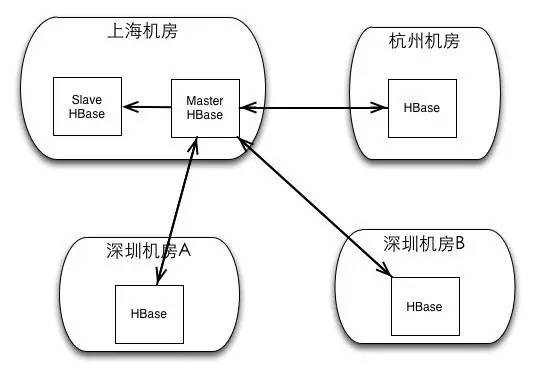
并且,用户可以选择使用diamond的方式访问HBase集群,利用diamond进行数据源地址推送,和单元化分流。多Peer+diamond使得HBase似七剑天瀑,转易颠倒,意到随成,数据做到真正的任意流转,业务做到真正的异地多活。
七剑之青干:MTTR一期
对于分布式数据库,单个节点宕机(服务宕机、物理宕机)是一个可能会发生的常态。3u7版本前的HBase只要跪一台regionserver,就会引起业务抖动近18分钟。MTTR优化一期,主要关注的是单台RS宕机后的恢复过程优化和改进。单台regionserver宕机的failover过程可以参看:http://blog.csdn.net/hljlzc2007/article/details/10963425。拿集团TT这样体量的业务来说,MTTR一期优化后,单台物理宕机恢复时间缩短至了7分钟。整个MTTR似七剑青干,象征“防守&迅捷”,快速恢复。其中,我们主要做了以下四项优化(数据只是测试数据):
| 场景 | 改进前 | 改进后 |
| split-log过程中过滤已flush的entry | 耗时18 min | 耗时5 min |
| 普通RS和服务Meta的RS先后宕机,优先恢复Meta Region | 耗时4 min | 耗时35 sec |
| recoverLease机制优化 | 由worker进行lease recover | 由master进行lease recover |
| 避免HDFS故障导致的RS宕机 | HDFS故障后1分钟内RS abort | HDFS故障后RS不abort,且可继续提供不涉及HDFS操作的读写服务 |
Split hlog时过滤过时的edits/entry
该优化点主要是在split-log过程中生成recovered.edits时skip掉已经flush的entry,从而加速整个split过程。线上环境通常配置HBase.regionserver.maxlogs为96,也就是说hlog总大小为96*256MB,而Memstore总大小通常不超过10GB,从这个角度看该特性应该可以在split-log时过滤掉一半以上数据。
宕机时优先恢复Meta region
该优化点针对的情况是当有两台RS先后宕机,后宕机的RS上服务meta region且宕机前存在建表/删表操作的情况下,加速meta region上线速度。优化后,我们会在每次处理掉一个split log task之后动态获取任务列表(之前是静态),并且优先处理meta region的相关的task。
recoverLease机制优化
该优化点主要针对split-log产生大量recovered.edits文件导致HDFS性能缓慢情况下recoverLease长期无法完成拖慢整体log split速度的问题,改进split-log过程中recoverLease的机制,加速failover。
HDFS故障导致的RS宕机
3u7之前,当HDFS出现问题时(例如网络问题,进入safemode,或者整个hdfs集群宕机等),RegionServer会很快检测到(flush/hlog_roll都会触发对filesystem的检查)并abort,这样带来的最大问题是HDFS恢复后会有大量的split-log发生,导致非常长的恢复时间。实际上,当HDFS出现问题时,可以捕捉相关异常,并死等HDFS恢复,在此期间读写仍可进行直至触发HDFS操作。同时由于不触发server abort,不会导致split-log,因此可大大缩短恢复时间。实测效果显示,HDFS故障1小时后恢复仍然可以保证HBase恢复并保证数据一致性,这大大降低了HDFS故障的影响,并在最差情况下可以通过重启HDFS来解决故障,而不用担心split-log及恢复时间过长的问题。
七剑之舍神:
限制大scan请求的资源使用
2015年,支付宝消费记录去了MySQL,把所有实时查询都搬上了HBase,是历史以来责任最重的双11,试想当你们支付宝支付完成之后,看不到消费转账记录是何等的心情。但是,在年初的时候,消费记录的HBase集群,会经常遇到单台regionserver handler(线程池)打爆,LOAD飙高至不可接受导致服务宕机的问题。消费记录是一个从MYSQL迁移过来的应用,查询场景包含了大量scan+filter,并且skip的kv异常多,查询范围广。但凡有跨N多datablock的查询,服务端总会把资源消耗在这种大查询之上,导致阻塞后续的查询。大请求(bigcall)的定义:对系统资源消耗特别大的请求,典型的例子就是带有filter的scan,这个filter过滤掉了大量的数据,导致一个next操作会访问成百上千个block。当block大部分都在内存时,这种scan就会消耗大量资源。当多个大请求并发访问服务器时,会造成load飙高,吞吐量下降。在实际的问题中,大请求可能几个小时都执行不完。
因此我们针对性的对bigcall进行了截流,实现了BigCallThrottle。限制大请求的资源消耗,让正常的请求可以获取资源。通过sleep达到目的。中断掉对客户端来说已经超时的请求,这种请求继续运行没有意义。中断请求释放资源。优化似七剑舍神,使得服务端具有强烈的生命力。经过优化,消费记录在之后的历次大促和双11中,系统非常稳定,没有出现过因大请求导致的服务宕机,业务抖动。
七剑之日月:混合存储
混合存储是2015年强推的一个大优化,似七剑日月,是最耀眼的优化。随着集团HBase承接业务范围的扩大,越来越多实时性要求高(99.9% 200ms内)、数据海量(往往超过几十TB)的业务在硬件选择上遇到了难题:
选择SATA?高毛刺高RT,低下的IOPS能力,肯定不行。
选择SSD?高昂的资源开销,这个也承受不住,并且存储空间也还是问题。
选择混合存储机型的SSD做二级缓存?不同的业务具有不同的命中率,无法提升命中率则一旦抖到SATA盘上还是然并卵。我们是要做一种通用的解决方案,这也不行。
在寻求硬件开销&性能&存储空间的tradeoff中,我们想到了真正的混合存储:12个硬盘slot中有3个是SSD,其余9个是SATA。数据写入的时候,可以指定写入1份SSD还是3份,抑或不写,读取的时候可以选择是否优先走SSD读。这个功能一上线,太多太多的业务都争先恐后上去,目前集团+支付宝已经有30%的机器被替换成了混合存储,在预算持平的情况下,读RT从99% 200ms优化至99.9% 200ms,用户体验上升。
七剑之竞星:
基于虚拟节点的跨ZK集群切库
3u7.1之前的HBase客户端只能进行同ZK集群下基于虚拟节点的切库。但是有几个问题需要解决:
老集群业务平滑迁移,即使客户端改造为虚拟节点的方式连接ZK,仍不能保证过程透明;
单元没有提供2:2:1部署ZK集群条件的,必须进行跨ZK集群多单元部署的情况;
基于diamond的高可用架构下,但凡diamond本身无法保障高可用的情况。
基于以上三种场景,我们需要基于虚拟节点的跨ZK集群切库这一功能。这在正如衣服内短小的竞星剑,非必要时刻不出手,出手时迅雷不及掩耳。
经平台同意授权转载
来源:云栖社区
作者:中间件那珂
近期活动:
Gdevops全球敏捷运维峰会北京站

峰会官网:www.gdevops.com
DAMS第二届中国数据资产管理峰会

峰会官网:www.dams.org.cn









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721