
本次分享的这个项目通过引入可横向扩展的分布式缓存架构,针对访问频繁的相关表如字典表和三户资料数据,通过应用改造,放到分布式缓存中进行管理,并和数据库互动,大幅降低数据库访问次数,从而达到提高应用效率、降低扩容压力的目的。
项目上线后,实现了应用效率提升和扩容投资降低的目的,实际上线运行情况表明,针对访问最频繁的top 30的表进行缓存处理后,整个数据库访问次数下降30%,关键业务处理性能提升15%。
一
项目实施背景
随着各类业务的发展,对运营商核心OLTP数据库处理能力提出了越来越高的要求,尤其承载核心用户资料数据的crm系统,压力越来越大。传统的性能优化方法,如主机扩容、数据库优化跟不上业务需求压力增长速度,且扩容成本很高,投资巨大。
传统性能优化方法基本基于主机和数据库,但数据库如Oracle方面难以实现横向扩展,扩展能力受限。应用层,可以通过增加服务器数量实现扩容,但是在核心数据库层,由于采取Oracle rac构建,其基于共享存储的机制造成系统io压力越来越集中,io的瓶颈难以通过简单扩容实现,节点数扩展越多,性能下降越明显,同时单台数据库服务器的处理能力也是有限度的,难以无限制的增加,只能通过拆分数据库来进行性能的扩展,但是又增加了数据迁移的难度。
上述背景要求我们寻找一种新的性能优化方法,可以降低核心数据库压力,同时又能实现可扩展的灵活架构方案,从而更好的实现高效低成本。
二
方案做法
通过在应用层引入分布式缓存技术Memcache,实现可灵活横向扩展的基于x86的分布式缓存架构,针对访问频繁的相关表如字典表和三户资料数据,通过应用改造,放到分布式缓存中进行管理,并和数据库互动,大大降低数据库访问次数,从而达到提高应用效率、降低扩容压力的目的。
整体架构如下(简单示意):
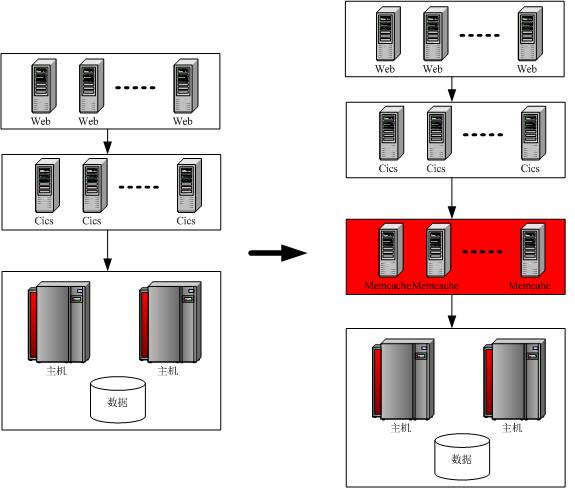
图1 应用架构图
即在现有三层架构,web层->cics层->database层基础上,增加Memcache缓存层(上图红色部分),使在应用访问数据库时,可以将数据缓存在Memcache集群中。
针对TOP N业务进行改造,以山东公司为例,top 10业务占总业务量的80%以上,即仅仅改造10个业务,即可实现性能效果大大大提升。
|
业务 |
一天业务量(笔数) |
|
补卡 |
20686 |
|
产品变更 |
1337704 |
|
活动管理 |
60750 |
|
集团成员管理 |
162785 |
|
缴费 |
2643038 |
|
开户 |
377973 |
|
梦网业务订购 |
184958 |
|
提卡激活 |
140381 |
|
提取发票 |
2611 |
|
资料变更 |
24470 |
Memcached是一个高性能的分布式内存对象缓存系统,用于减轻数据库负载,目前在互联网行业应用较为广泛。它通过在内存中缓存数据和对象来减少读取数据库的次数。本项目采用Memcache实现缓存机制,也可以采用其他缓存软件如redis等实现。
Memcached基于一个存储键/值对的hashmap。其守护进程(daemon)是用C写的,但是客户端可以用任何语言来编写,并通过Memcached协议与守护进程通信。
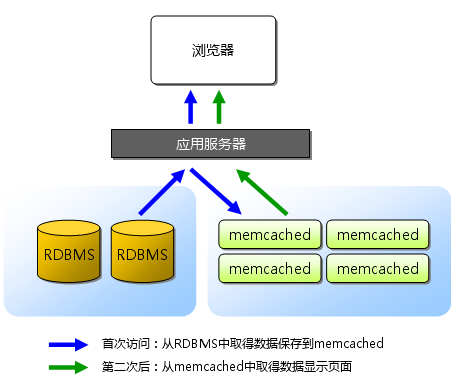
图2 Memcache原理图
增加缓存层后,应用的访问逻辑需要改变,主要表现在,增加缓存前通过直接访问数据库实现,直接写SQL即可,但增加缓存后,需要增加针对缓存的处理,通过应用逻辑实现数据的获取。
应用针对缓存访问方法和步骤如下:
每个会话访问表时,先判断数据是否在缓存中,如是则从缓存取,否则从数据库取,并同时写入缓存;
如有多个缓存,则在缓存前置分发器,根据一定规则分发到不同的缓存处理;
缓存取不到或缓存故障下,直接从数据库中取,前台返回无任何影响;
数据更新时直接更新数据库,并同步触发缓存更新逻辑;
更新缓存时第一份缓存和数据库同步更新,然后触发其他缓存间的同步更新,由于是在缓存间的数据同步操作,性能影响几乎可以忽略不计。
详细数据访问流程如下图引入缓存后的数据读写流程图所示:
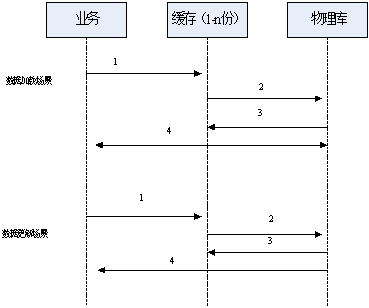
图3 引入缓存后的数据读写流程图
下面分场景介绍缓存访问逻辑:
数据加载场景:
先到分发器分配的一份缓存中查询,数据是否在该缓存中,如果在直接返回;
如果不在,从物理库读数据;
将读取的数据装载到缓存1,同步触发对缓存2…n进行加载。任何一个缓存操作失败,则标记为不可用,后续不再分发业务;
同时把数据结果返回给业务。
数据更新场景:
先到分发器分配的一份缓存查询,更新前的数据是否在缓存中;
先更新物理库;
根据第一步判断如果在缓存,则把物理库的更新变化刷新到缓存,否则启用装载流程,装载到缓存,如有多个缓存同步进行更新,任何一个缓存操作失败,则标记为不可用,后续不再分发业务;
把数据结果返回给业务。
业务连续性保护机制:
IT系统不可避免会出现故障,当Memcache server不可用时,异常处理机制如下,将不影响业务运行:
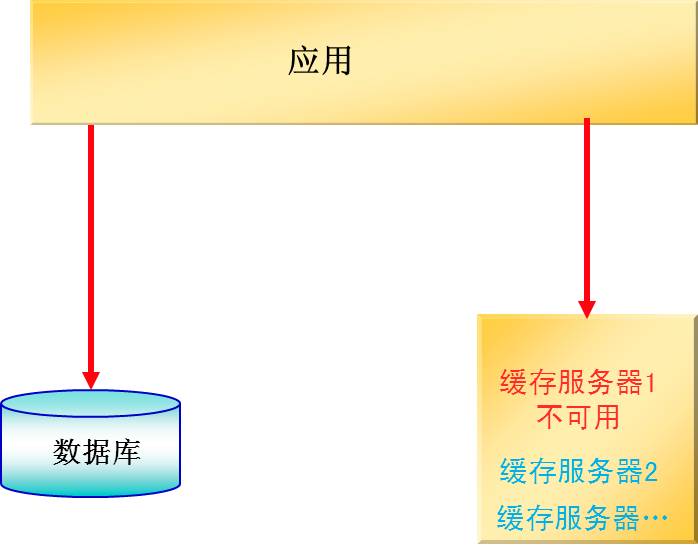
图4 缓存高可用措施流程
当某一台server不可用时,根据key查询MemCached中数据,返回server不可用错误,则执行数据库查询,在配置多套集群情况下,也可从其他集群访问。
当故障的server恢复后,自动按照正常流程访问 。
集群中其他可用的server按照正常流程访问。
三
运行效果
通过将top 10的业务涉及访问最频繁的30个表改造为Memcache访问机制,数据库整体压力降低30%,top 10关键业务平均响应时间降低15%。
1、应用效率提升明显
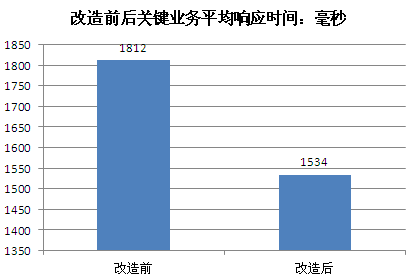
2、成本压力大大降低
数据库压力降低40%,去掉计划内的增长15%,相当于整体下降核心系统25%的扩容能力,经计算可降低扩容成本2000万元。
附:统计的各表访问次数下降情况
|
业务 |
单笔业务 数据库访问次数 |
一天业务量 |
表访问下降次数 |
|
补卡 |
49 |
20686 |
709529.8 |
|
产品变更 |
185 |
1337704 |
173232668 |
|
活动管理 |
134 |
60750 |
5698350 |
|
集团成员管理 |
889 |
162785 |
101301105.5 |
|
缴费 |
181 |
2643038 |
334872914.6 |
|
开户 |
203 |
377973 |
53709963.3 |
|
梦网业务订购 |
55 |
184958 |
7120883 |
|
提卡激活 |
49 |
140381 |
4815068.3 |
|
提取发票 |
29 |
2611 |
53003.3 |
|
资料变更 |
46 |
24470 |
787934 |
|
合计 |
1820 |
4955356 |
682301419.8 |
Q1:对于缓存数据是不是需要业务改造?
A1:是的,需要应用做比较大的改造,以前我们的CRM应用都是直接sql获取数据,现在通过key-value方式,几乎关键业务全部修改了一遍。
Q2:刚才提到“针对访问频繁的相关表如字典表和三户资料数据,通过应用改造,放到分布式缓存中进行管理”,针对更新频繁的表(如受理日志等)是不是不适合通过此类方式改造优化?
A2:针对读多写少的表,非常适合,但是对读写差不多或写多读少的表,效果要差。我们统计过,我们正在改造的核心表,读写比例在8:2以上。
Q3:Memcache选择的什么版本?
A3:版本1.4,比较老。
Q4:根据第一步判断如果在缓存,则把物理库的更新变化刷新到缓存,否则启用装载流程,装载到缓存,如有多个缓存同步进行更新,任何一个缓存操作失败,则标记为不可用,后续不再分发业务。 如何恢复这个故障的缓存节点?
A4:目前还是监控,然后人工恢复。
Q5:能否透露一下Memcache的集群规模?
A5:目前40个x86节点。
Q6:缓存层到DB层需要做哪些设置呢?DB层的缓存是否还有作用?
A6:不需要设置,通过应用负责链接,数据库的缓存仍然起作用,但只是在通过sql获取数据时,然后程序写到Memcache,之后再发生读,则从缓存,不从数据库。
Q7:怎样保持缓存和数据库中的数据实时一致?
A7:主要采取这个逻辑实现:数据更新时直接更新数据库,并同步触发缓存更新逻辑。都需要应用来实现。
Q8:单个节点容量在多少?文中提到的同步,40个节点数据是冗余还是分片的?
A8:单个节点在30G内存,40个节点分了4个集群,集群内是分片。
Q9:缓存前置分发器依据规则分发数据,如果增加新的业务和服务器,这个规则是能自定义并能指向新增加的服务器?
A9:是通过客户端应用来分发的,hash算法,新增服务器,需要进行缓存迁移,因版本较低,还没用到集群,但可以通过预分片设置了大量的分片,新增服务器时可以方便把一些分片迁移到新机器。
Q10:除了Memcache,redis还有其他竞争性方案吗?
A10:其他如MongoDB,也可部分代替缓存功能,还有可以采用内存库,但感觉效率比缓存差一些。
Q11:Oracle的TT能否实现类似的缓存功能?有无可能,因为缓存和数据库的更新没立即同步,导致应用读取了老的缓存里的数据?
A11:TT是关系型内存数据库,不是缓存,适合替代Oracle物理库,二者比较难以实现一致性的同步,我们的场景是由应用同步写物理库和缓存,使二者一致。
Q12:Memcache的集群规模是如何评估的?应用如何选择查询哪个缓存节点?会不会数据存放在节点1,而应用访问节点5以致没找到数据而访问数据库?
A12:目前是按照放到内存的表的实际占用量评估的,目前数据存放在哪个节点是由应用控制的,根据模数放在不同的节点,后续查询也按照这个定位节点。新版本支持集群后会更灵活。
Q13:如何选择要缓存的表?除了根据读多写少,还有哪些评判?
A13:选择要缓存的表,一是需要读多写少,还有要在整个数据库个系统中的读量处于前面的位置,否则优化了用处不大,还有就是尽量delete操作不要太频繁。
Q14:能否举例说明,在实现某个查询功能时,原先没使用缓存时,SQL是怎么写得的?改用缓存功能后?代码改成怎么样了?
A14:没使用缓存:SQL语句即可:select a from tab where b=1; 使用缓存:java语言和数据库语言结合: function get_data($key) { $data = $this->cache->get($key); if($data != null) return $data; else { if($this->cache->getresultcode() == memcached::res_notfound) { //do the databse query here and fetch data $this->cache->set($key,$data_returned_from_database); } else { error_log('no data for key '.$key); } }
Q15:怎样保持缓存和数据库中的数据实时一致?
A15:我们是通过应用逻辑实现,比如在更新数据库时,同步更新缓存,任何时候数据的变化都要先更新数据库,再更新缓存。
Q16:对于缓存数据的业务改造,为什么不考虑直接使用redis?
A16:redis也可以,也是选择之一,我们只是因为有人熟悉Memcache所以才选取了现在的方案。
作者介绍 朱祥磊
山东移动BOSS系统架构师;
负责业务支撑系统架构规划和建设;
获国家级创新奖1项、通信行业级科技进步奖2项、移动集团级业务服务创新奖3项;
申请发明专利13项。
近期活动:
Gdevops全球敏捷运维峰会北京站

峰会官网:www.gdevops.com
DAMS第二届中国数据资产管理峰会

峰会官网:www.dams.org.cn









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721