
一、什么是负载均衡
一台服务器的处理能力,主要受限于服务器自身的可扩展硬件能力。所以,在需要处理大量用户请求的时候,通常都会引入负载均衡器,将多台普通服务器组成一个系统,来完成高并发的请求处理任务。
1996年之后,出现了新的网络负载均衡技术。通过设置虚拟服务地址(IP),将位于同一地域(Region)的多台服务器虚拟成一个高性能、高可用的应用服务池;再根据应用指定的方式,将来自客户端的网络请求分发到服务器池中。网络负载均衡会检查服务器池中后端服务器的健康状态,自动隔离异常状态的后端服务器,从而解决了单台后端服务器的单点问题,同时提高了应用的整体服务能力。
二、负载均衡的演进

网络负载均衡主要有硬件与软件两种实现方式,主流负载均衡解决方案中,硬件厂商以F5为代表,软件主要为NGINX与LVS。但是,无论硬件或软件实现,都逃不出基于四层交互技术的“报文转发”或基于七层协议的“请求代理”这两种方式。 四层的转发模式通常性能会更好,但七层的代理模式可以根据更多的信息做到更智能地分发流量。一般大规模应用中,这两种方式会同时存在。
2007年F5提出了ADC(Application delivery controller)的概念为传统的负载均衡器增加了大量的功能,常用的有:SSL卸载、压缩优化和TCP连接优化。NGINX也支持很多ADC的特性,但F5的中高端型号会通过硬件加速卡来实现SSL卸载、压缩优化这一类CPU密集型的操作,从而可以提供更好的性能。
三、硬件负载均衡的痛点


F5的硬件负载均衡产品又分单机Big IP系列和集群VISRION系列,都是X86架构,配合自研的TMOS(Traffic Management Operating System),再加上硬件加速卡(Cavium提供)处理SSL和压缩等CPU密集型操作。以单机中的中端版本Big IP 4200v为例,从datasheet了解到能支撑每秒30万新建连接数,1000万并发连接数,10G数据吞吐量。而这样的性能实际上LVS是可能在通用服务器上达到的。VIPRION系列本质上通过背板交换将多块刀片服务器集成在一起,通过横向扩展来提升性能。
硬件负载均衡在功能、易用性和可扩展性上都做得不错,但是也有不少缺点。从商业角度来说,硬件负载均衡产品过于昂贵,高端产品动辄五十万甚至数百万的价格对于用户是几乎不可承受的负担。从使用角度来说,硬件负载均衡是黑盒,有BUG需要联系厂商等待解决,时间不可控、新特性迭代缓慢且需资深人员维护升级,也是变相增加昂贵的人力成本。
(一)LVS的痛点

LVS最常用的有NAT、DR以及新的FULL NAT模式。上图比较了几种常见转发模式的优缺点。
我们认为LVS的每种模式都有其优点和缺点,但最大的问题是其复杂性。相信很多朋友看到这三种方式的优缺点、还有F5的单臂模式、双臂模式都会有云里雾里的感觉。
(二)LVS集群的痛点


雪上加霜的是咱们还需要考虑LVS的性能扩展和容灾方法,这使得整个方案更加的复杂。常见的有基于Keepalived的主备方式和ECMP两种。
Keepalived主备模式设备利用率低;不能横向扩展;VRRP协议,有脑裂的风险。而ECMP的方式需要了解动态路由协议,LVS和交换机均需要较复杂配置;交换机的HASH算法一般比较简单,增加删除节点会造成HASH重分布,可能导致当前TCP连接全部中断;部分交换机的ECMP在处理分片包时会有BUG。
四、Vortex负载均衡器的设计理念
可靠性: ECMP+一致性哈希保证连接不中断
当负载均衡器发生变化
当后端服务器发生变化
当两者同时发生变更
可伸缩性
横向扩展:ECMP集群
纵向扩展:DPDK提升单机性能
虚拟化网络中的DR转发模式

用户使用负载均衡器最重要的需求是“High Availability”和“Scalability”,Vortex的架构设计重心就是满足用户需求,提供极致的“可靠性”和“可收缩性”,而在这两者之间我们又把“可靠性”放在更重要的位置。
值得一提的是今年3月举办的第十三届网络系统设计与实现USENIX研讨会(NSDI '16)上, 来自谷歌、加州大学洛杉矶分校、SpaceX公司的工程师们分享了《Maglev:快速、可靠的软件网络负载均衡器》,介绍了从2008年开始在生产环境投入使用的软件负载均衡器。其设计理念和我们非常相似,同样是ECMP + 一致性哈希;同样是Kernel Bypass模式;单机性能也和我们的Vortex非常接近。
(一)Vortex的High Availability实现
四层负载均衡器的主要功能是将收到的数据包转发给不同的后端服务器,但必须保证将五元组相同的数据包发送到同一台后端服务器,否则后端服务器将无法正确处理该数据包。
以常见的HTTP连接为例,如果报文没有被发送到同一台后端服务器,操作系统的TCP协议栈无法找到对应的TCP连接或者是验证TCP序列号错误将会无声无息的丢弃报文,发送端不会得到任何的通知。如果应用层没有超时机制的话,服务将会长期不可用。Vortex的可靠性设计面临的最大问题就是如何在任何情况下避免该情况发生。Vortex通过ECMP集群和一致性哈希来实现极致程度的可靠性。
(二)可靠性: ECMP+一致性哈希保证连接不中断
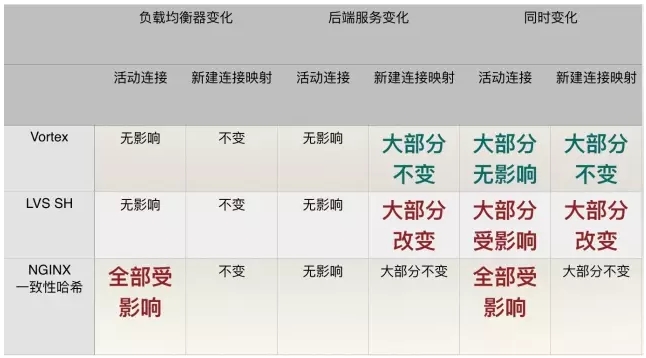
1、可靠性:当负载均衡器发生变化

首先,我们来考察一下负载均衡服务器变化场景。 这种场景下,可能由于负载均衡服务器故障被动触发,也可能由于运维需要主动增加或者减少负载均衡服务器。此时交换机会通过动态路由协议检测负载均衡服务器集群的变化,但除思科的某些型号外大多数交换机都采用简单的取模算法,导致大多数数据包被发送到不同的负载均衡服务器。
Vortex服务器的一致性哈希算法能够保证即使是不同的Vortex服务器收到了数据包,仍然能够将该数据包转发到同一台后端服务器,从而保证客户应用对此类变化无感知,业务不受任何影响。
这种场景下,如果负载均衡器是LVS且采用RR (Round Robin)算法的话,该数据包会被送到错误的后端服务器,且上层应用无法得到任何通知。如果LVS配置了SH(Source Hash)算法的话,该数据包会被送到正确的后端服务器,上层应用对此类变化无感知,业务不受任何影响;如果负载均衡器是NGINX的话,该数据包会被TCP协议栈无声无息地丢弃,上层应用不会得到任何通知。
2、可靠性:后端服务器发生变化


其次,来考察后端服务器变化的场景。 这种场景下,可能由于后端服务器故障由健康检查机制检查出来,也可能由于运维需要主动增加或者减少后端服务器。此时,Vortex服务器会通过连接追踪机制保证当前活动连接的数据包被送往之前选择的服务器,而所有新建连接则会在变化后的服务器集群中进行负载分担。
同时,Vortex一致性哈希算法能保证大部分新建连接与后端服务器的映射关系保持不变,只有最少数量的映射关系发生变化,从而最大限度地减小了对客户端到端的应用层面的影响。这种场景下,如果负载均衡器是LVS且SH算法的话,大部分新建连接与后端服务器的映射关系会发生变化。某些应用,例如缓存服务器,如果发生映射关系的突变,将造成大量的cache miss,从而需要从数据源重新读取内容,由此导致性能的大幅下降。而NGINX在该场景下如果配置了一致性哈希的话可以达到和Vortex一样的效果。
3、可靠性:同时发生变化

最后,让我们来看一下负载均衡服务器和后端服务器集群同时变化的场景。 在这种场景下,Vortex能够保证大多数活动连接不受影响,少数活动连接被送往错误的后端服务器且上层应用不会得到任何通知。并且大多数新建连接与后端服务器的映射关系保持不变,只有最少数量的映射关系发生变化。
如果负载均衡器是LVS且SH算法的话几乎所有活动连接都会被送往错误的后端服务器且上层应用不会得到任何通知。大多数新建连接与后端服务器的映射关系同样也会发生变化。如果是NGINX的话因为交换机将数据包送往不同的NGINX服务器,几乎所有数据包会被无声无息地丢弃,上层应用不会得到任何通知。
4、可靠性:总结
(三)可收缩性:基于ECMP集群的Scaling Out设计

Vortex采用动态路由的方式通过路由器ECMP(Equal-cost multi-path routing)来实现Vortex集群的负载均衡。一般路由机支持至少16或32路ECMP集群,特殊的SDN交换机支持多达256路ECMP集群。而一致性哈希的使用是的ECMP集群的变化对上层应用基本无感知,用户业务不受影响。
1、可收缩性: 基于DPDK的Scaling Up设计
虽然ECMP提供了良好的Scaling Out的能力,但是考虑到网络设备的价格仍然希望单机性能够尽可能的强。例如,转发能力最好是能够达到10G甚至40G的线速,同时能够支持尽可能高的每秒新建连接数。Vortex利用DPDK提供的高性能用户空间 (user space) 网卡驱动、高效无锁数据结构成功的将单机性能提升到转发14M PPS(10G, 64字节线速),新建连接200K CPS以上。
内核不是解决方案,而是问题所在!

从上图可以看到随着高速网络的发展64字节小包线速的要求越来越高,对10G网络来说平均67ns,对40G网络来说只有17ns。而于此同时CPU、内存的速度提升却没有那么多。以2G主频的CPU为例,每次命中L3缓存的读取操作需要约40个CPU周期,而一旦没有命中缓存从主存读取则需要140个CPU周期。
为了达到线速就必须采用多核并发处理、批量数据包处理的方式来摊销单个数据包处理所需要的CPU周期数。此外,即使采用上述方式,如果没有得到充分的优化,发生多次cache miss或者是memory copy都无法达到10G线速的目标。
2、可收缩性: 基于DPDK的Scaling Up设计

像NGINX这样的代理模式,转发程序因为需要TCP协议栈的处理以及至少一次内存复制性能要远低于LVS。而LVS又因为通用Kernel的限制,会考虑节省内存等设计策略,而不会向Vortex一样在一开始就特别注重转发性能。例如LVS缺省的连接追踪HASH表大小为4K,而Vortex直接使用了50%以上的内存作为连接追踪表。

Vortex通过DPDK提供函数库充分利用CPU和网卡的能力从而达到了单机10G线速的转发性能。
用户空间驱动,完全Zero-Copy
采用批处理摊销单个报文处理的成本
充分利用硬件特性
Intel DataDirect I/O Technology (Intel DDIO)
NUMA
Huge Pages,Cache Alignment,Memory channel use
Vortex直接采用多队列10G网卡,通过RSS直接将网卡队列和CPU Core绑定,消除线程的上下文切换带来的开销。Vortex线程间采用高并发无锁的消息队列通信。除此之外,完全不共享状态从而保证转发线程之间不会互相影响。Vortex在设计时尽可能的减少指针的使用、采用连续内存数据结构来降低cache miss。通过这样一系列精心设计的优化措施,Vortex的单机性能远超LVS。
3、可收缩性: 虚拟化网络中的DR转发模式

基于DR转发方式
LVS支持四种转发模式:NAT、DR、TUNNEL和FULLNAT,其实各有利弊。Vortex在设计之初就对四种模式做了评估,最后发现在虚拟化的环境下DR方式在各方面比较平衡,并且符合我们追求极致性能的理念。
DR方式最大的优点是绝佳的性能,只有request需要负载均衡器处理,response可以直接从后端服务器返回客户机,不论是吞吐还是延时都是最好的分发方式。
其次,DR方式不像NAT模式需要复杂的路由设置,而且不像NAT模式当client和后端服务器处于同一个子网就无法正常工作。DR的这个特性使他特别合适作为内网负载均衡。
此外,不像FULLNAT一样需要先修改源IP再使用 TOA 传递源地址,还得在负载均衡器和后端服务器上都编译非主线的Kernel Module,DR可以KISS(Keep It Simple, Stupid)地将源地址传递给后端服务器。
最后,虚拟化环境中已经采用Overlay虚拟网络了,所以TUNNEL的方式变得完全多余。而DR方式最大的缺点:需要LB和后端服务器在同一个二层网络,而这在UCloud的虚拟化网络中完全不是问题。主流的SDN方案追求的正是大二层带来的无缝迁移体验,且早已采用各种优化手段(例如ARP代理)来优化大二层虚拟网络。
Q&A
Q1:请问您对HAProxy有啥看法?
A1:HAProxy其实和Nginx基本功能、性能都差不多。但是HAProxy的社区没有Nginx活跃,而且研发长期就只有1、2个人吧。HAProxy还没有支持http 2.0,这也和他研发人员比较少有关。
Q2:F5负载均衡的时候主要监控注意那几点?
A2:F5负载均衡器,最重要就是并发连接数和CPU的监控了。另外F5的irule很强大,但一定要记住,代价是CPU。
Q3:还有就是遇到过负载均衡的时候有的服务器没有压力,怎么去快快速排查原因?
A3:这个一般就是查看负载均衡器上的健康检查,看服务器的状态了;还有就是要看是不是开启了连接保持模式。
Q4:“四层的问题交给四层去解决”怎么理解?
A4:这个以LVS和Nginx为例,LVS的性能肯定超过Nginx很多,但是特性没Nginx丰富呀。如果是小网站问题不大,单跑Nginx可以,如果流量大了,一般还是会前置四层的负载均衡吧。
Q5:前面提到的10G负载均衡,其实差别很大的,是指哪块?
A5:主要还是和测试方法有关。如果是长连接,每个报文都1500的话,LVS也可以达到10G带宽,可是这时候PPS可能还不到1M,而CPS只有1.
Q6:如果正在转发报文的均衡器发生单点故障,有没有什么机制保证顺利转发?
A6:如果是NGINX的话,无解,因为TCP协议栈就会丢弃不正确的连接;如果是LVS的话,全文也说过用SH算法的可以保持客户连接不中断;也可以用我们ULB。
Q7:Vortex有开源的计划吗?
A7:在开发之初就有考虑开源的,后续有进展会第一时间告知大家!
Q8:Vortex高可用是采用何种方案?
A8:ECMP + 一致性哈希。
Q9:4层和7层应用的主要优缺点是什么?
A9:4层性能好;7层功能丰富;大多数应用场合还是会同时存在。
Q10:想问下对于tcp的优化是指系统层面的参数优化,还是有别的优化情况?
A10:Vortex现在是Bypass Kernel的,他其实完全省去了TCP协议栈。
Q11:可以对不同种类的业务进行分流吗?
A11:四层负载均衡一般是只对不同的目的IP+Port来识别service的;如果你的问题不是这个场景的话,就需要七层负载均衡了。
Q12:后端节点探测提供哪几种方式?
A12:目前TCP是通过syn去探测的,UDP是通过ping去探测的。后期我们也打算开放API,让用户自己去设置。
Q13:如果进行机房灾备建设,该怎么样进行负载?有好的建议吗?
A13:好问题。UCloud即将推出“可用区”的功能,未来我们的负载均衡申请后可以直接在不同可用区部署,从而提供跨机房灾备的能力。
Q14:运营商在负载均衡设计时一般如何考虑?与其他行业有何不同?
A14:运营商有钱,会配置比较高端的F5设备。另外运营商有时会用到一些Content Switching的功能。
Q15:这负载均衡具有分发到后台服务日志记录和是否请求成功记录?
A15:这个功能规划了,这个版本还没实现。因为日志量也比较大,我们规划是写到我们地UFile上的。
作者介绍 徐亮
负责UCloud接入网络的架构设计、开发和运营。拥有15年高可用、大并发和分布式后台开发经验。
先后任职于上海贝尔、腾讯,从事后台开发工作,项目包括中南海党政专网呼叫中心、运营商级别的WAP/HTTP互联网网关;腾讯广告播放系统、微信公众号开发;Hadoop大数据分析、硬件负载均衡器。
目前,主要专注于DPDK开发NFV、SDN以及UniKernel虚拟化。
Tips:关注DBA+社群订阅号:dbaplus,回复“负载均衡”,即可下载“如何构建100G线速负载均衡”PPT。
全球敏捷运维峰会【杭州站】

2016年4月16日,DBA+社群联合Linux中国、三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自IBM、阿里、淘宝、网易、中国移动、新炬网络、百世物流等互联网与传统企业的资深大咖,汇聚500+行业精英,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地等热议话题,全程拒绝无营养的广告,绝对干货,精彩不容错过!
购票优惠
DBA+社群专属门票优惠码:dbaplus001
专属VIP票优惠码:dbaplusvip
报名方式:猛戳“阅读原文”抢票吧!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721