
但很可惜,我没有碰到这样的人,在加入新公司后,带我的人几乎没花时间给我讲项目,也没给我安排可以熟悉项目的任务。
就这样的一个多月时间里,我慢慢靠自己的力量熟悉了大概十个项目,并在过程中总结了一些方法,借此机会记录一下,分享给大家。
首先在这里强调一点,我的策略不是快速了解一个项目的具体业务,因为这个不同项目也不一样,无法总结。我的策略是大体了解整个业务线上的所有项目,大概摸清楚每个项目都是干嘛的,它们之间的关系如何,以便以后不论具体负责哪个项目都不至于找不到方向。
这样等到需要负责具体到细节的业务时,虽然依然需要花时间,但相比整体一头雾水地开始,还是简单许多的。
一、必要条件
我们首先要想的是,有了哪些必要条件后,给你足够的时间,你才能够完全了解整个项目?
这里说的必要条件不是“项目面对的客户是谁”、“项目用的框架是什么”这种,而是真真正正的必要条件,就好比用几条数学公理能推出整个数学体系一样。这里我总结的真正的必要条件只有两点:
源码位置(gitlab或svn);
部署环境(dev/test/online);
所谓项目,其实就是一堆代码放在了一堆机器上而已,所以这些就足够了。
当然,为了更加节约时间,最好还要有wiki、jenkins、页面访问路径、数据库地址。
我之所以说那两个是必要条件,是想说其实项目本质上就是这么简单的一个事,你千万不要想的太复杂。它的业务可以无限复杂,但它的本质却逃不出这些,你千万不可以糊涂。当你无从下手或者什么都不清楚的时候,就主要把源码和环境弄清楚吧,其它的都是附属品。
二、从页面到数据库的线
有了上面的必要条件后,我们就开始了解项目了。由于不只是一个项目,所以千万不能深入具体代码,否则你就越来越烦直到放弃,也不会有好的效果。
对某个具体项目的了解,一定要建立在对整体了解的基础上。这时我们首先为各个项目画出一条线,并标明每一个节点的信息,就像下面的样子:
页面访问路径——前端项目——后台服务——数据库地址
这里的一个前端项目可能对应多个后台服务,所以最终的图应该差不多是这样:
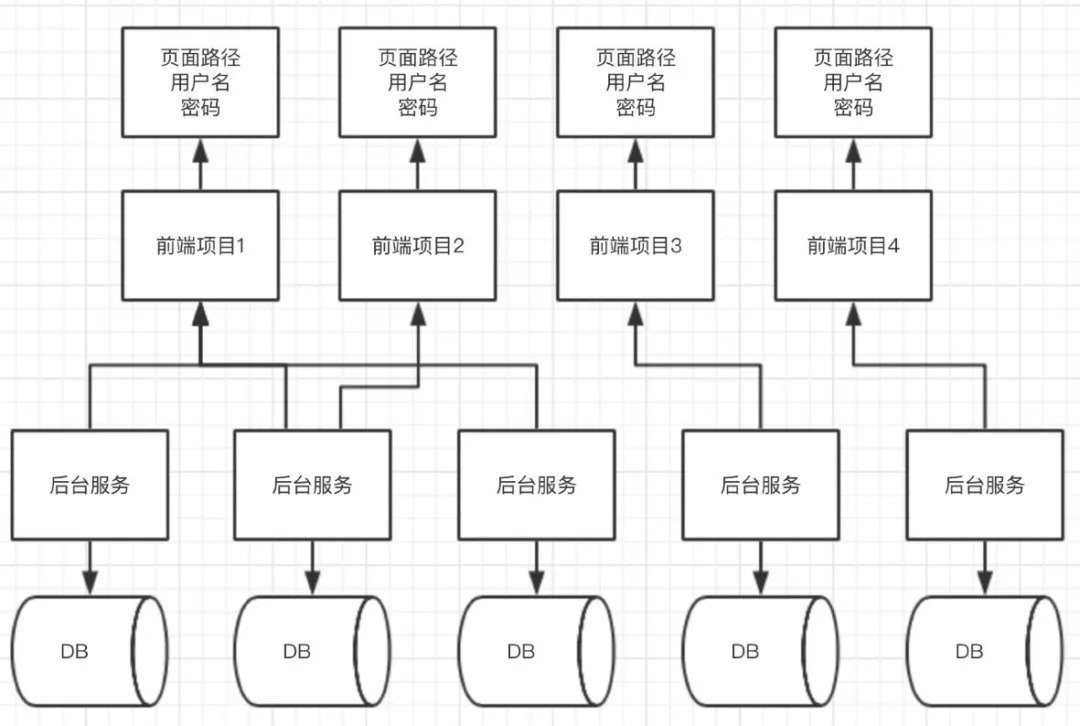
这个整理的过程,主要是让自己梳理清楚,一共有哪些项目,哪些是前端可视的,哪些是后台提供服务的,并且大致了解前端项目分别调用了哪些后台服务。通过后台服务和数据库的名称,我们能从本质上了解到这条业务线提供了什么功能;从前端项目和页面路径,我们能了解到我们需要给用户展示什么。
注意,这个阶段我们只是见名知意,即使点开页面,连接上数据库看看,也千万别花过多的时间,因为这个阶段的重点就是仅仅知道这条业务线提的整体内容。
在此基础之上,这个图可以不断细化,比如项目部署的机器,我们可以标注在项目旁边,或者保存在Xshell里。此外所有非业务相关的,能查到的尽量都记录下来。这个真的为以后找各种东西提供太多方便了。如果不在这一步这样做,别看你现在节约了时间,但等到以后查找相关东西的时候,时间加起来将会是天文数字了。
这里关于整理项目部署的机器还有个小插曲,跟大家分享一下。
由于这部分的信息没人会一个一个地告诉你,就算有也不可能说的特别全。所以我是借助jenkins来整理的。项目部署都需要用到jenkins,只要查看jenkins配置的命令,就可以把部署环境一一整理出来,这个我认为是最全而且最新的。
不要和我说查wiki,如果公司wiki都写的这么全,我估计就没这篇文章什么事了。当时我的jenkins权限特别少,只能看一部分项目,而且还只能执行,不能看配置,带我的人也是抠门,每次问他都给我开通所需要的项目的执行权限,多一点都不给。后来我也懒得问了,由于jenkins机器大家都可以用root权限登陆,所以我进入jenkins的配置文件config.xml,给我自己添加了一个admin权限,重启jenkins,再打开之后屏幕满满的项目都出来了,而且都可以查看和修改,畅通无阻。我就这样通过一个个jenkins的配置,整理了部署的机器,也看了下启动的逻辑。
三、了解项目间的关系
这部分如果有老员工愿意和你说说,那最好还是了解一下。如果没有也没关系,先跳过这段,以后慢慢了解也是可以的。
四、整理数据库表
我们上面都是整理项目的大体框架,还没有涉及到具体的项目细节。这一部分,仍然不去涉及。
如果说站在整个业务的本质上看,业务无非就是一堆代码运行在一堆机器上;那么站在单个项目来看,一个项目无非就是对数据库的增删改查操作而已;或者从使用者的角度看,一个项目就是输入一些参数得到一些返回结果而已。
所以接下来我们要做两件事:一个是整理数据库表,一个是整理Controller层的所有接口。
找核心项目:这里首先要选择一个核心项目去看,众多项目中一定有一个是核心项目,就先从这个开始看起。
筛选核心数据表:如果数据库的表比较少,那我们拿工具导出来表结构,一个个看就行了,这个不难。但如果数据库表特别多,我们首先要将表名全部导出,筛选出那些核心的表。这里导出表名、筛选表以及后面的分析表字段,不妨给自己做个工具,我在遇到一些很麻烦的或者感觉以后还可以通用的事情时,就会做成一个小工具,放在一个我给自己起名为javamate的程序中,这些小工具逐渐积累起来你会发现今后有意想不到的方便。
判断哪些是核心表:不要着急,我们首先排除掉一些没用的。拿我在公司分析的系统来说,一共150多个表,其中有好多copy结尾的是备份,flow结尾的是流水,rel结尾的是中间关联表,statistics结尾的是数据统计表,log结尾的是日志表,config结尾的是配置表,等等。排除掉这些对核心业务理解无影响的表之后,所剩的也就20来张表,再根据它们的名字,可以看出好多表是属于一类的,比如order表就有各种order,按类别再分出来也就四五类,再分析起来就不难了。当然如果是更大的体系结构,那就要再不断做拆解。
找出表之间的关系:在具体分析这些核心表字段之前,还要做一件事就是找出表中间的关系。如果表b中有个字段,比如叫a.id,那么b和a就是一对多的关系;如果两个表有rel中间表,那二者就是多对多的关系,起码从逻辑上讲是这样的。这个分析过程我也是做了个小工具,通过程序来判断的。
到此,你就对整体的数据库结构有所了解了。根据表名也能对表的大致内容有所了解,接下来就是针对具体的表,看里面具体的字段和前人给出的备注,这个过程就没有技巧了,要耐心,要慢慢熬。
五、整理Controller层接口
当对数据库表做了以上的了解后,你基本上对这个系统能提供什么服务了解得差不多了。这个时候不论你的代码长什么样子,数据库摆在那里,能提供的服务差不多就已经出来了,对有经验的人来讲,代码的业务逻辑也大致能猜到个八九分。
我们梳理了大后方,那接下来就是把最前端和别人交互的部分搞清楚,这样掐头去尾,整个项目就解剖的差不多了。
这里我也给自己做了个小工具,扫描出所有的controller层的接口,展示出方法名、路径名、参数列表和返回值等,但可惜没能展示注释,有大神有想法的话也欢迎帮我想想。
和数据库一样,如果接口很少,那么一个个看;如果特别多,还是先找出比较核心的几个方法研究。
这里我用的是postman,把要研究的接口访问保存起来,并且添加访问成功和失败的Example。我推荐自己开发的时候也把postman用起来,越详细越好,postman不只是可以简简单单访问你的接口,还能做批量测试,还可以生成api文档用于和前端交互。这样你不但测试了自己的接口,还省的写文档了。而且postman还有个好处就是可以给自己的接口mock一个服务,这样即使你的接口挂了,或者接口根本就没写好,也可以让前端人员先访问你的mock,完全不影响前端边测试边开发,这才是真正的前后端分离嘛。
六、重新理清项目间的关系
好了,这时候每个项目你已经大致了解,最起码调用的效果,数据库所能提供的服务,你是清楚的。至此,就要重新整理下项目之间的关系了。
根据之前的接口名称,详细了解下项目间的调用关系。理不清的部分去问老员工,这时候你带着自己的了解问,他们也能给出更多的信息。
看看每个项目中用到的中间件,主要是mq服务,看看谁是生产者,谁是消费者,以此来了解关系。
这时你应该已经开了好几轮的周会了,接下来的周会你应该能听懂部分内容。根据每个人的描述和最新的几组需求,逐渐摸清楚现在项目面临的问题,以及哪个项目是核心,哪个项目是辅助,哪个项目是以稳定安全为主的。
到此为止,你对整条业务线就有了大致的了解,接下来就可以结合你具体负责的内容、领导安排你做的方向,去看具体的业务代码了。
虽然之后的步骤依然需要你深入其中,事无巨细地了解具体内容,但此时,你通过前面的努力,已经可以站在一定的高度看每一个项目了,虽然你细节上还是不了解,但这是完全不同的。
在研究具体业务代码的同时,不断地跳出来看整条业务线的框架,修正之前由于不了解具体业务而理解错误的架构。
长此以往,你一定会在某个项目中脱颖而出,让大家认识到你的全局视野,这也是走出老是写增删改查代码怪圈的一个途径。慢慢会有人意识到,你对项目的理解总能站在全局的视野,很多需要跨项目去做的业务,也会自然而然想到你,慢慢地,你会接触到更为核心的东西,成为架构师,或者去转向产品,转向管理。
这就是我总结的了解项目的过程,我工作年限不多,经验上还不够丰富,希望大佬们多多留言指点,提出问题,共同进步。
作者:闪客sun
来源:www.cnblogs.com/flashsun/p/9450066.html
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721