

基线与容量是DBA运维系统工作中所必须面临的问题。今天由【DBA+社群】联合发起人白鳝老师为大家揭晓他眼中的基线和容量。先举个例子简单介绍下基线大致是什么:
前阵子刚买了一个SURFACE PRO4,开机后要求升级系统,点了’YES’接受升级请求后,SURFACE就不断的在更新,微软的系统升级大家都经历过,没有百分比,也没有在干嘛的 提示,10分钟,20分钟,30分钟过去了,界面还是这样。当时我就有点犯傻,到底这种情况是否正常呢?问了一个用过SURFACE的朋友,他说有时候升 级确实需要半小时甚至更多。于是我就放心了。这其实就是一种基线。如果你不了解第一次开机的升级需要多长时间这个基线,那么性急的朋友可能要强制关机重启 了,那你的SURFACE变砖的机会就很高了。
实际上今天老白要介绍的基线和传统的基线在本质上是一样的,不过在对基线这两个字的理解上会有较大的不同。
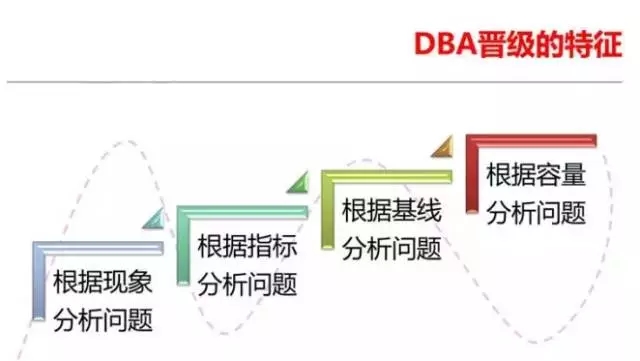
谈基线之前我们先来看看DBA晋级的几个特征,这也是老白自己定义的DBA的几个能力阶段。最初级的DBA往往是根据现象分析问题;第二级别的DBA除了根 据现象分析问题外,还可以根据一些运行指标来分析问题,比如DB CACHE命中率,TOP 5 事件等;如果你不仅仅根据指标来分析问题,还可以根据基线来分析问题了,那么恭喜你,你晋级为第三等级,也就是较为高级的DBA了;而能够成为真正高手的 DBA,除了能够通过基线来分析问题外,还了解各种IT组件和业务的容量。
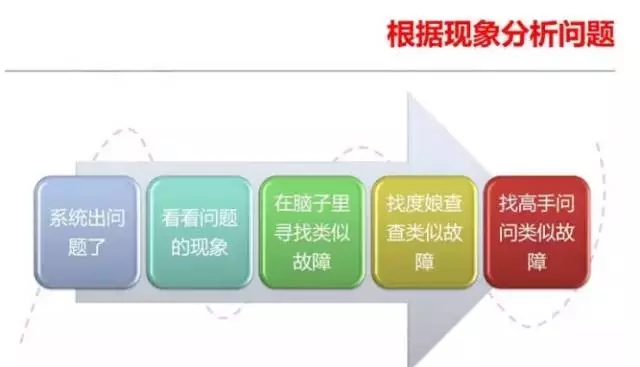
刚刚入门的DBA处理为你的时候往往是根据问题的表面现象,问题所表现出来的最为表层的东西去分析问题,比如从日志中发现一条信息,前台的一个告警等等。然 后根据这些信息在脑子里搜索,以前是否遇到过类似的问题,如果脑子里找不到,就会去百度搜索,或者到处打电话问别人。这种处理方式,问题被第一时间正确处 理的比例较低,不过偶尔也会瞎猫碰到死老鼠,很风光的解决几个问题。

随着DBA自身能力的提升,学会了采集操作系统和数据库的一些运行指标信息,学会了简单的阅读AWR报告,于是再遇到问题,分析问题的思路也随之有了很大的 提升。如果发现某个数据库比较慢了,会先从AWR报告上去查找系统可能存在什么问题,比如某些命中率指标是否偏低,某些争用是否有点严重,某些等待事件是 否比较异常等等。然后再到百度或者MOS上去查找某些指标异常,可能是什么引起的。
由于有第一手的数据,并且学会了分析指标,学会了看AWR里的LOAD PROFILE和TOP EVENTS等,DBA处理问题的成功率也有了较大的提升。这个阶段的DBA基本上能够独立分析较为复杂的系统问题了,老白也把这类DBA定位为中级DBA。
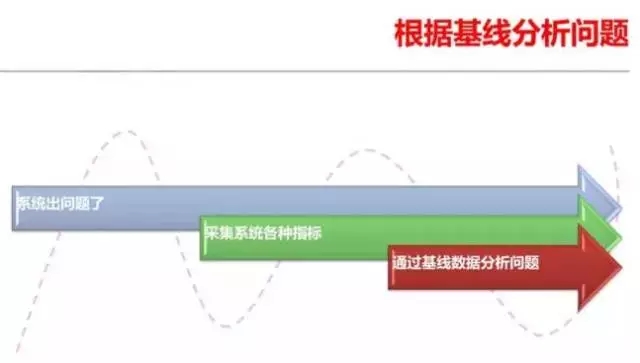
有时候我们还无法简单的从某些指标发现问题,因为每个系统的指标都会有所不同。经常有朋友问我,我的系统的DB CACHE命中率只有95%,正常不正常,我的系统单块读响应时间6毫秒,正常吗?说实在的我比较难以回答他的问题,因为在不同的系统中,这些指标差异相 当大。这些指标只有和横向对比,才比较容易搞清楚。比如某个指标正常不正常,最简单的方法是把系统正常时的这个指标拿出来,和当前的指标比较一下。 Oracle有个awrddrpt就可以实现把两个时间段的AWR指标放在一个报告里进行比对。我们可以通过同一个指标的直接比较得到我们所需要的答案。
这种分析方法,老白就称之为基线分析,而真正掌握了基线分析的DBA,就一只脚迈进了高手的行列了。

基线和容量很容易混淆,我们还是先通过一个例子来区分基线和容量。如果我们在维护一套自己熟悉的系统,那么我们很容易通过基线对比来判断,但是如果遇到一套 系统是我们以前不熟悉的,不仅仅系统不熟悉,连系统所跑的业务不熟悉。这个时候如果要我们来分析问题,那么我们总不能和客户说让我先熟悉一阵子再来分析吧。
如果是10多年前,那么很多系统出现问题往往伴随的是系统瓶颈,比如老白的《DBA优化日记》里所说的沈阳和海尔的案例,都是不同程度出现了系统资源瓶颈导 致的问题。那种系统在AWR报告或者OS采集的数据中,很容易就能发现一些异常的指标。而现在的绝大多数系统并没有出现资源瓶颈,所以很多指标在表现上并 没有出现极端的现象,作为一个资深的DBA,虽然不清楚这个系统以往的历史指标是怎么样的,但是根据其历史经验以及他对某个it组件的容量,可以较为准确 的判断哪些指标可能存在不合理的现象。这些判断取决于DBA能够掌握某些IT组件的总体负载能力,比如一台IBM P750小型机,在CPU满配的情况下,大体上每秒能处理多少OLTP并发交易。
DBA如果能够掌握一些容量数据,就可以通过容量模型的管理来考虑信息系统长期可持续发展的问题,从而使运维水平提高一个层次。所以老白认为,掌握容量是DBA进阶为系统架构师路上的必进之路。

在正式介绍基线之前,我们还需要通过一个例子来加深认识。比如近期老白遇到了一个系统性能问题,这是一台4路PC SERVER,32核的,上面跑了一个ORACLE 11G的数据库,从8月2日一早开始,某个系统就出现了问题,CPU使用率基本上处于100%,而平时的时候,这套系统的CPU最高使用率不超过40%。 8月3日起,系统又恢复正常。这一天到底出了什么问题,导致了CPU资源突然增长这么多呢?从现在的情况看,可能出问题的点很多,包括:
应用出了问题?
共享池争用?
某个SQL出现问题?
存储系统出现问题?
服务器出现问题?
……
到底问题出在哪里呢?不同层级的DBA会有不同的怀疑方向。在看下一张片子之前,大家可以考虑下,等会我们来揭晓答案,同时大家也可以自己心里测算下,按照老白的四级划分,你目前处于哪个层级。当然这个层级划分不一定合理。

当然了,能从中看出问题的DBA起码也不是刚入门的菜鸟,至少是能够看指标的DBA。根据指标分析的DBA,往往会把关注点放到了TOP 5 EVENTS里面几个和library cache相关的指标上,这两个指标占了系统等待事件的8%左右。根据这个指标,十分有理由怀疑是不是系统的共享池出问题了。
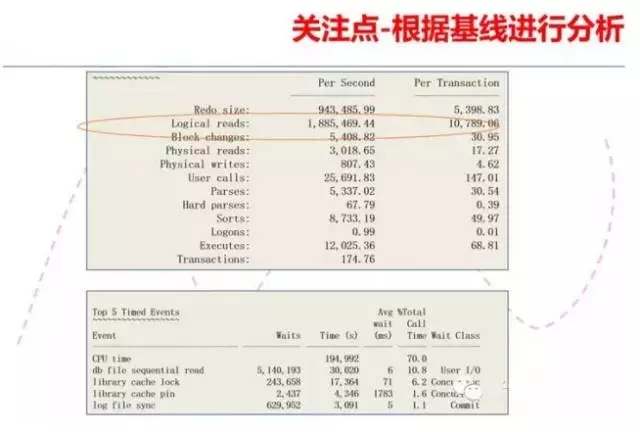
而基于基线分析的DBA可能会把LIBRARY CACHE放到第二位,因为这两个等待加在一起才8%的占比,不至于把系统从40%不到的CPU负载加大一倍多。而经常观察本系统的一些核心指标的DBA 很快会发现Logical reads的指标比平时高很多,并且他也明白逻辑读多了,CPU资源消耗肯定高。
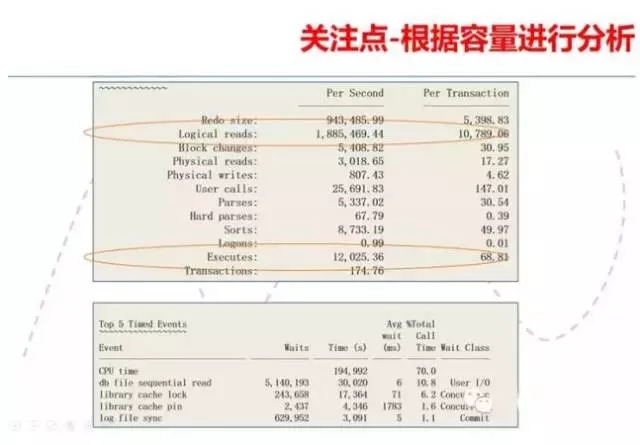
如果你有幸进入了顶级DBA的行列,那么你可能不仅仅会关注到逻辑读过大的问题,对于一台4路32核的老PC SERVER来说,他可能很快就可以看出每秒12025次的执行也是比较高的。因此对于具有容量分析能力的DBA来说,他关注的疑点可能会增加一个,为什 么有那么多的执行数量。当然,对于具有容量分析能力的DBA,可以在不清楚这个系统以前负载指标的情况下,第一时间定位到逻辑读超过180万/秒,执行超 过12000,对于一台4路32核的较老的4路PC SERVER来说,是比较高的。当然最后通过这两个疑点,两类DBA会有两个略微相似的分析路径。基于基线分析的DBA很可能重点先放在逻辑读较高的 SQL上,看看是不是有哪些SQL的执行计划出现了变化。而具有容量分析能力的DBA会先把焦点放到执行数量较多的SQL上。
这三类DBA可能最终都会找出问题的原因,只是他们的分析路径有所不同而已。当然首先关注执行数量的DBA可能会更早的定位到问题。这个问题的最终结果会让 大家都有些意外。是一些开销不大的但是执行频率很高的SQL把存储撑爆了,高峰期RAC两个节点的总的IOPS达到了10万以上,导致该存储的IO响应时 间大幅下降。虽然我们在AWR报告上ka拿到这个存储的db file sequential read的时间是6毫秒,不算差,但是这是一台CACHE很大的高端存储,这个系统正常时候,这个指标是2毫秒。

到这里,大家应该了解到自己处于DBA的那个层级了吧,不过没关系,自己在心里可以盘算,是应该找老板加薪还是默默的把它烂在心里(此处应该有笑声)。下面 我们来总结一下,如果某一天业务部门说某个系统很慢,而你发现系统资源没有瓶颈,数据库也没有什么指标明显异常,那么你该怎么进一步分析呢?这其实是现在 的DBA所面临的常见问题。在老白经常跑现场的时代,问题简单的多,系统出现性能问题无外乎负载太高或者SQL太烂。而现在的DBA面临的挑战要严峻的 多,一个各种指标异常不明显的系统,是较难分析的。这回我们从最佳实践往下看,看看高大上的解决方案一直到IT民工怎么应对这一问题的。
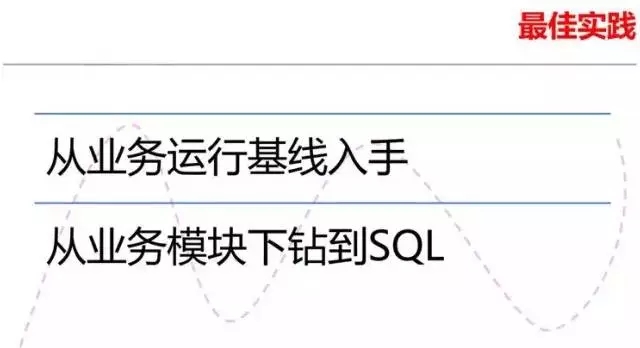
如果系统层面没有发现什么明显的瓶颈,那么至少有一半的可能性是和业务模块本身有关的。因此最好你手头有业务运行的基线,通过这些基线来查找存在异常的业务 模块,然后从这些业务模块入手,通过应用性能监控工具下钻到这个模块调用的类,直到SQL。这种分析方式可以很直观的发现系统可能存在的问题。不过缺点 是,你首先必须部署了应用性能分析工具。这些价格昂贵的工具往往是你无法获得的。

如果不幸的是你没有APM工具,那么作为DBA你可能需要花更多的精力去发现问题。甚至还有一种可能是,压根不是数据库的问题,而是应用服务器出现了问题, 从而导致了系统的问题。这种情况下,DBA需要了解业务部门反馈的较慢的业务都调用了哪些SQL,然后去分析这些SQL的调用基线,执行次数/平均每次 CPU和IO的开销,执行计划是否变化等。如果你很幸运,能找到可对比的基线数据,那么如果是某条SQL出现问题,你也可以很快的定位了。如果很不幸你没 有发现问题,你也可以很轻松的告诉应用和中间件的管理人员,数据库没发现啥异常,你们先查查吧。

轮到IT民工就比较惨了,没有可比对的历史数据,只能埋头苦干。上来先采集一把AWR报告,这是很专业的做法。然后找到TOP SQL,一顿分析,看着几十行的SQL执行计划一阵阵头晕。好不容易分析完了,发现这条SQL和业务没任何关系。也有可能你费尽千辛万苦,最后终于找到了 业务相关的SQL ,通过分析,你发现Oracle没任何问题。这时候中间件管理员笑嘻嘻的走过来,兄弟我已经搞定了问题了,刚才重启了一下应用服务器,现在一切OK。
从这个例子我们可以看到基线的作用是十分巨大的,那么到底什么事基线呢?

上面的几条概念性的东西可能还有点抽象,我们先通过几个例子来看看对于DBA而言什么是基线。
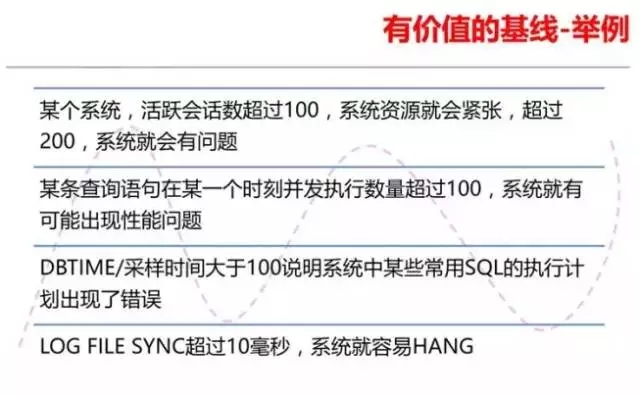
第一个基线的案例是老白在DBA优化日记里面所提到的,当时客户发现平常时候活跃会话数量一般会在100左右,如果超过150,说明系统有问题了,如果超过 200,系统就变得比较卡了,超过300,系统有可能就会HANG死。于是用户定义了一个基线,当系统的活跃会话数接近200就开始杀会话。这样能保持系 统正常运行。靠着这个小技巧,客户把系统维持到了扩容,在这段时间里基本上保证了系统的可用。
第二个基线的案例是某个快递公司,当查单业务的SQL同时有超过100个并发访问的时候,系统资源很快就会出现瓶颈了。于是当DBA发现查单的SQL在V$SESSION中出现超过100的时候,就开始啥查单会话,直到系统恢复正常。
第三个案例是一个运营商客户,他们的某条SQL经常因为统计数据不准确而导致走错执行计划,虽然系统没有因此出现大的问题,运维人员有时候无法及时掌握系统 出现了问题。不过该业务变慢会导致投诉增加,业务部门会用这个考核IT部门。通过这个指标,运维部门可以及时发现有SQL执行计划出现偏差,及时更新统计 数据。
最后一个案例是一个银行,最初时LOG FILE SYNC的平均等待时间是2-3毫秒,突然变成5毫秒了。下一季度巡检时候变成7毫秒了,我们就给客户提出预警,希望他们检查下存储。客户检查了存储,告 知我们,存储一切正常。再下一次巡检时,这个指标变成9毫秒了,我们再次预警,客户还是没发现存储的问题。过了半个月,突然有一天客户的核心业务出现了卡 顿,时间超过5分钟,于是立即要求我们帮助协查。检查结果发现,系统的主要等待事件是LOG FILE SYNC,而该等待的平均响应时间已经超过15毫秒。这回用户真的用心做了排查,发现存储本身没问题,不过有一条同城复制的同步复制链路不稳定,经常切 换,影响了整个存储的写性能。而以前检查的主要是读,发现读的性能都没问题。经过这件事后,客户设定了对LOG FILE SYNC的日常检查,大于10毫秒就要进行细致的存储检查了。
下面我们来看看老白对基线的私家解释,此基线非彼基线,是老白从DBA的角度来看基线。

基线是DBA对系统的看法和经验,这是本次分享的主题观点。从DBA的一个狭隘的视角去看基线,基线是为DBA运维服务的,是DBA本人对系统的看法。虽然 我们能够通过工具采集并保存大量的基线数据,只有被充分理解的基线指标才对DBA的运维有较大的价值。而其他采集的基线指标,仅仅可以作为DBA分析问题 时候所使用的数据而已。
一个DBA在日常工作中,往往会把系统正常情况下的某些指标归纳为基线,供今后分析问题使用。某个系统的基线指标是通过运维过程中出现各种问题后的思考,不断的积累和完善的。

虽然基线的概念很简单,但是基线的管理是不简单的。理论上你可以把所有的系统指标都通过工具采集起来作为基线保存起来。但是这些数据你无法用来进行深度的分 析,并形成有效的分析规则。实际上,只有少量的我们能够充分理解的基线指标对我们的运维才有价值。只有当我们能够明确某些指标出现问题后必然会产生某种后 果,或者出现某种不良后果的概率是大概率,那么我们才能说这个基线对我们的运维是有极大价值的。
如果你管理的是大量的数据库,那么你所需要采集和分析的基线数据是十分巨大的,如果仅仅通过手工手段来进行采集和分析,那么很难持久下去,因此如果要让基线管理常态化,必须借助自动化的手段来进行基线数据的采集分析和管理。
一旦你已经积累了足够量的数据,那么你就可以用来进行趋势分析,发现潜在的问题了。一旦你形成了对基线指标的”看法”,那么你就可以使用基线来进行系统预警了。一旦发现了违背基线规则的事件,你就需要进行闭环的管理,对于每个可疑的事件都进行分析,找到合理的解释。

采集数据库基线可以采用一些手工脚本,也可以使用自动化工具,比如oracle的EM。当然你也可以使用 dbms_workload_repository.create_baseline直接把一个AWR数据保存为基线数据。被标志位基线的SNAP将不会 在清理数据的时候被清除掉,而会长久保留。
如果你对AWR的基表比较了解,那么你也可以直接编写脚本从AWR的基表中去读取数据。当年白鳝的洞穴中的人生如梦就分析过AWR报告生成的所有脚本,并且写了一个文档,大家有兴趣可以去下载。这个文档最初是发在Oracle粉丝网上的。
在一些工具中,包含了大量的基线指标,其中包括Oracle的AWR,以及操作系统层面的NMON,OSW,GLANCE等。

作为DBA我们最关心的肯定是ORACLE数据库的基线数据,既然AWR里面包含了最多的基线指标数据,那么我们应该把AWR数据长期保留下来。如果保留在 生产库里,会导致AWR数据占用过多的空间。因此我们需要把AWR数据从生产库中离线下载下来,然后放到一个专门存储AWR历史数据的数据库中,长期保留 下来。
方法很简单,首先我们可以去找一台服务器,一台2路的PC SERVER就足够用了,甚至你可以使用一台台式机来创建一个数据库。然后使用awrextr.sql脚本从生产库将需要转储的AWR数据导出到一个 DMP文件中(这个脚本存放于?/rdbms/admin目录)。然后在目标数据库,使用awrload.sql将数据导入。一个数据库中可以管理多个数 据库/实例的AWR数据,使用awrrpti脚本我们就可以选择某个数据库生成某个实例的awr报告,当然其他的awr报告生成脚本也有类似的带i的脚 本。同时我们也可以通过自己定义的脚本去分析这些awr数据。
在这里我要再一次提一下当年人生如梦所写的一篇文章,分析awr报告的生成原理。人生如梦也是白鳝的洞穴的第一批成员之一,也是我相交甚厚的小兄弟。当年他 要做这个分析的时候,我还冷嘲热讽,最后在长老和棉花糖的帮助下,历经数月,人生终于完成了对AWR报告生成脚本的全面分析。编写了“AWR报告内容生成 SQL”这篇名字十分清淡但是内容十分详实的文章。在之后的SCN HEADROOM分析这件事里,老白还使用了一些人生如梦这篇文档里的脚本。

和人生如梦交往的那么多年里,第一次看他这么认真的做一件枯燥的事情,这件事做成对他在技术和职场上的成长都十分有价值,我想每个DBA都会经历这样的阶段,做成一件这样的事情,今后对你来说就没有什么困难的事情了。

基线采集之后就是使用了,基线的使用场景十分广泛,用于故障分析可以通过基线来缩小故障分析的范围,快速定位问题。而基线数据采集的数量到达一定量以后,基 线就可以用于趋势分析了。趋势分析可以以周/月/年的周期来进行,这些分析可以让DBA和IT决策者了解信息系统的运行势态,资源的使用趋势等。对于一些 持续恶化的指标,可以进行重点的针对性分析。
另外一个用处就是预警,当基线数据采集到一定数量的时候,我们可以总结出基线变化的规则,并在监控系统中针对某些指标设置预警规则。对于违背基线规则,监控 系统将主动推送报警信息。而对于违反规则的基线预警,IT部门需要组织相关技术人员进行分析,查找可能存在的疑点。对每个违反基线规则的事件,都必须找到 合理的解释,做到闭环管理。

对于基线预警事件的分析基于某些监控规则,最为简单的监控规则就是阈值,而阈值的设置需要根据每个系统的实际特点去设定。不过阈值只是一种十分简单的以单一 指标为监控对象的预警方法,而实际的生产系统相当复杂,某个指标出现变化的因素十分复杂,完全不能简单的用阈值来评判。
曾经有一些DBA试图通过复杂的规则引擎来设置更为复杂的基线预警规则,经过大量实践后发现,这些基于规则引擎的分析往往很难实现完全的人工智能,从本质上 说,只是一些更为复杂的阈值而已,其准确度也十分难以保证。因此到目前为止,基线预警的最好方法还是阈值预警,人工分析的组合。超出规则定义范围外的基线 指标都会触动报警,这样可以让每个疑点都会被运维人员第一时间捕获。
虽然阈值预警可以使用最为简单的方法,但是数据分析过程并不简单。指标数据的分析不能仅仅依靠某个指标的值来进行,很多指标之间是相关联的。比如共享池的问 题,需要分析共享池使用率、平均每秒SQL解析的总量、硬解析比例、每秒SQL执行的数量、和共享吃相关的闩锁的丢失率、SGA是否发生过RESIZE、 library cache和字典缓冲的整体指标,以及执行和解析比较高的SQL的情况,才能有一个较为准确的判断。整个判断是十分复杂的,只能抽取出少量的可验证的规 则,无法覆盖故障的较大范围。
我举个例子,我遇到过一个用户,他们的系统负载很高,每天一上班CPU使用率就超过90%,告警系统天天告警,搞得他们都无法工作,后来我们分析了一下他们 的系统,其实有时候CPU使用率超过90%,系统并没有出现什么瓶颈,操作系统的R队列数量只是略微超过了CPU线程数。于是我就建议他们取消CPU使用 率阈值报警,转而采用R队列阈值报警。当R队列超出CPU线程数2倍的时候开始报警,超出3倍严重报警。通过这样调整阈值报警,使阈值报警的有效性大大的 提升了。

最后我们要来强调几点对基线预警的应用经验。虽然我们可以使用自动化工具来使基线的采集/分析/预警自动化,但是无目的的分析效果不佳。如果我们管理十多套 系统,甚至几十套系统,每个系统每天都有1-2个违背基线的事件发生,那么我们所说的防患于未然或者闭环管理是否能够得到很好的落实呢?对于一般的DBA 来说,每天处理2-3个基线预警事件还是可以接受的,如果我们每天面临数十个基线预警事件,那么我想对于绝大多数DBA来说,只能是虱子多了不愁,干脆不 管了事。
因此说,基线的采集和预警不能贪多,只需要把能够充分认识的基线纳入预警范围就行了,不要追求量。正确的做法是开始时候仅仅设置能够分析道德基线指标的跟踪,随着对系统认识的加深,逐渐加入你发现的心指标。应该循序渐进,不要过分追多追全。

我们已经初步弄清楚了日常运维的系统的基线问题,那么新的问题又来了,对于没有历史积累的系统,我们该怎么办?

对于一套我们以前没有接触过的系统,如果需要我们去分析哪些指标是正常的,哪些指标是不正常的,那么我们就需要考虑很多的问题。比如我们了解一个类似的系统 是IBM P750 32核的,这套系统的大体处理能力是我们掌握的,但是我目前面对的是一台4路的PC SERVER,也是32核的,它的处理能力相当于P750的几分之几?这就涉及到不同CPU之间的容量模型问题,如果我们已经了解不同CPU之间的容量差 异,那么我们很容易对这个案例进行类推,通过类推虽然不能很准确的掌握一些指标,但是大体可以推算出一个初略的指标。
DBA 也经常会遇到这样的问题,一个新上线的存储,领导问你这个存储大体上能提供多大的处理能力,这件事虽说很复杂,但是也不是没有办法,我们可以通过 fio,vdbench,或者orion等测试工具对划好的Lun进行测试,从而得到一个大体的指标。但是如果这件事放在设备采购之前,IT部门需要了解 我们配什么样的存储才能满足业务系统的需求,那我们该怎么办呢?如果我们去看存储设备厂商标称的性能指标,那么我们就可能吃大苦头了。存储厂商的标称容量 都基本上是实验室的极限容量,需要配备满配的存储机头及磁盘扩展柜,这种配置往往和我们采购的配置是完全不同的。在这种情况下,需要我们根据每块盘的 IOPS能力以及盘的数量,CACHE命中率等去初步推算采购存储的IO处理能力,同时考虑到机头、前端接口的带宽和处理能力,考虑配置机头和前端通道的 数量。
如果我们的存储系统升级后,业务反而慢了,我们该如何去分析呢?这里分享一个案例,有个客户,存储换了新的存储,标称的性能远远高于原来的老存储,盘的数量 也配备的比原来多,按理说存储割接后系统性能会有较大的提升。没想到存储更换后,所有核心业务模块都慢了30-50%。到底是什么引起的呢?老白分析了 下,发现SQL的执行计划和buffer gets都没啥变化,但是IO等待时间变长了。为什么会这样呢?通过仔细比对发现,老存储使用的是600G的3.5寸的15000rpm sas盘,而新存储使用的是900G的2.5寸10000rpm sas盘。虽然存储厂商宣称2.5寸的10000rpm的SAS盘的IO延时与3.5寸的15000 rpm的SAS盘性能相当,但是实际上这两种盘的IO延时是有差异的,10000rpm的盘IO延时要多30%左右。如果你了解这些盘之间的性能差异,你 就很容易找到问题的根本原因,否则你可能要陷入四处推诿的不利局面中。

上面列的是一些对于DBA来说很有用的系统级容量基线,比如一块15000rpm的SAS盘的IOPS指标我们可以估算为150-200;而这样一块SAS 盘的IO延时大约为3毫秒左右,考虑到CACHE和IO路径延时,我们认为一块物理磁盘的IO延时大约在2-5毫秒之间,当然15000rpm的盘的IO 延时要比10000rpm的IO延时低一些。
我们在估算存储的IOPS指标的时候,需要考虑CACHE的命中率,而这个命中率指标对于OLTP系统来说,大约是60-70%之间,我们可以根据乐观值和悲观值来选择一个合适的值。
另外在RAC INTERCONNECT方面,在千兆网络环境下,流量最高可以达到80M/秒,在万兆环境下,可以达到850M/秒,当然达到这个指标的情况下,RAC 已经出现了较为严重的GCS/GES等待。一般情况下,千兆网络下RAC INTERCONNECT超过60M/秒就是较为危险的了。

下面我们来看一组数据库容量的基线。对于OLTP系统来说,一般来说DB CACHE的命中率会在95%以上,而目前随着内存容量越来越大,一般的OLTP系统的DB CACHE命中率都在98%以上,甚至高达99%以上,对于低于99%的CACHE命中率的系统,你就可以看看是否存在加大DB CACHE,进一步提高CACHE命中率的优化可能。
而对于一般的OLTP系统而言,db file sequential read等待事件占总的等待的比例应该超过50%,甚至更高。而事实上,我们看到的绝大多数系统的CPU TIME都占了较大的比重,这是因为我们的系统中存在大量长时间执行的SQL。而单块读的平均响应时间应该在4毫秒左右,对于负载不是特别高,存储系统性 能很好的系统,这个指标可能在2毫秒左右,甚至更低。对于一般系统而言,如果该指标小于10毫秒就可以认为基本正常,超过20毫秒会对系统产生较大影响。
Log file sync指标对于系统的写入操作性能十分关键,正常情况下,该指标在4毫秒左右。对于一些高端存储,由于写缓冲很大,所以这个指标可能相当小,可以达到1毫秒,甚至小于1毫秒。这个指标如果变得很差的话,可能会导致整个数据库的性能下降。
Ave global cache get time(ms)指标能够直接反映出RAC节点之间数据交换的性能。这个指标一般也是1-4毫秒,业务高峰期的平均指标如果超出20毫秒,那么说明RAC INTERCONNECT的性能存在较为严重的问题。

除了了解系统级的指标外,我们还需要了解SQL的容量基线。某类常见SQL在不同并发情况下,可能消耗的CPU资源等都是我们需要去研究的。比如图中是某个 用户的一个典型的统计操作的SQL,在不同并发用户下的CPU资源开销。通过这个SQL可以推算某个模块可能的CPU资源消耗。除了这种典型的业务SQL 外,我们还需要充分掌握某些典型特征的SQL的容量基线。比如通过主键访问某张表的,通过范围扫描访问的、插入数据的,修改数据的,等等等等。
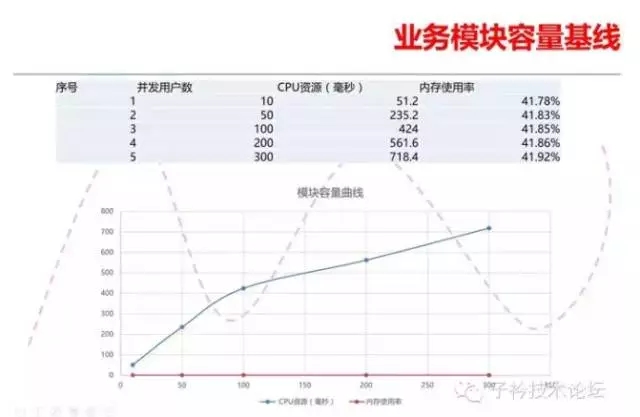
掌握业务模块的容量基线也有助于我们今后进行容量的估算,作为企业级用户,也需要建立自己的企业典型模块的容量字典。
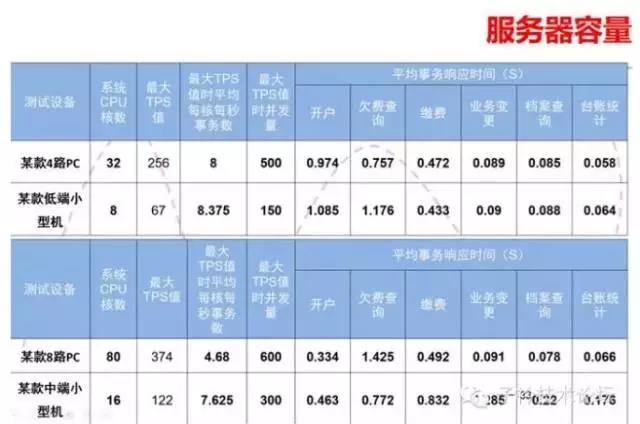
这张片子显示了不同类型的服务器的容量模型,从这里我们可以看出某8路服务器和某中端小型机之间的性能对比情况。通过这些数据我们可以建立起不同服务器CPU容量模型的数据,今后对于我们进行服务器容量估算是十分有帮助的。

看着老白罗列的各种数据,似乎系统级的容量基线采集也不是什么难事。不过不同类型的应用系统,在容量级基线上可能有较大的表现差异,而对于SQL容量模型, 一些复杂SQL的容量基线是较难采集的和相互推算的。比如sql的单次执行消耗的CPU是否超过一个CPU周期,可能在采集的结果数据上会有较大的差异。
所以说,较为准确的系统级基线是需要日积月累,甚至需要经过实验室的严格的科学分析才能获得的。这些数据都是企业最为宝贵的财富之一。
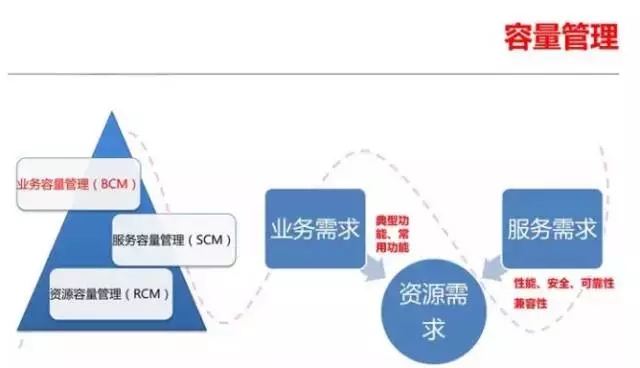
基于我们积累的系统级容量基线以及业务容量基线,我们可以建立企业级的容量模型。容量管理的原理很简单,就是根据业务容量推算服务容量,根据服务容量推算资源容量。基于完善的字典,我们甚至可以直接从业务需求跳过服务需求,直接推算资源容量。

对于一个企业来说,可以从系统的非功能性需求推算每个业务模块的并发访问需求,从而通过业务模块访问的SQL去推算各种资源的消耗。这是一种最为朴素的容量 评估方法,从原理上可行,不过从实际操作上看,难度较大,并且需要消耗大量的资源去进行分析。因此对于企业级的容量管理来说,建立各种容量字典至关重要。
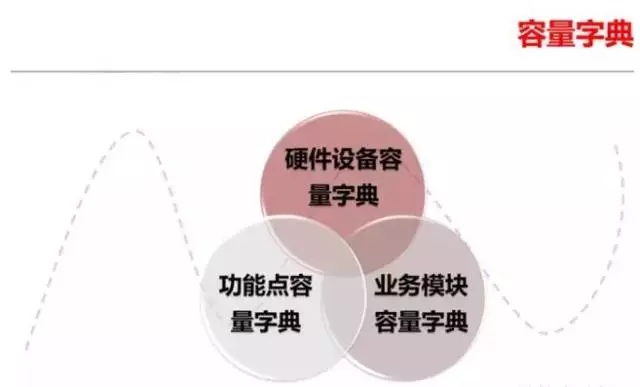
一个企业需要掌握的容量字典包括硬件设备容量,功能点容量,业务模块容量。如果有了这三种容量字典,我们就可以较为轻松的使用它来推算企业的容量需求了。
今天和大家分享了一个DBA管理中的中高级的问题,就是基线管理与容量管理的一些基本的概念。基线与容量是普适性的概念,对于DBA/系统管理员/软件开发 人员,他们对这两个概念的理解会有所不同。老白从一个DBA的狭隘的角度认为只有充分理解的基线指标才对日常工作有至关重要的帮助。因此作为日常运维的 DBA来说,把更多的精力放在这些能理解的基线指标的总结和发现上,会更加有价值。当然平时你能保留更多的细节数据当然是更好的事情,但是不要追求多,而 要追求有价值。这也是一个老DBA在这些年工作中的一点感受。
作者介绍:徐戟(白鳝)
“DBA+社群”联合发起人
从事应用开发、Oracle数据库、性能优化工作超过20年,一直从事IT咨询服务和系统优化工作。
曾供职于DEC、赛格集团、长天集团、联想集团等国内外知名企业,现任南瑞集团信息系统集成分公司/子衿技术团队 CTO/首席架构师。
1999年起致力于Oracle数据库性能优化等方面的研究,参与了大量性能优化项目,积累了大量的实际工作案例。著有《ORACLE 优化日记》、《ORACLE RAC日记》和《DBA的思想天空》。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看黎君原《扒一扒Oracle数据库迁移中的各种坑》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看楼方鑫《数据库中间层,这样定制可能更好》;
回复019,看王佩《基于Docker的mysql mha 的集群环境构建实践》;
回复020,看王津银《互联网运维的整体理念与最佳实践》









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721