
目录
运维能力是什么
实现交付能力方法
影响持续交付的因素
一个团队和一个公司的价值核心部分就是交付。你交付某种服务/交付产品是运维的价值所在,在你越接近客户的市场里,你的交付输出就越重要。 当然交付delivery和发布release有着很大的不同,在互联网企业里,很强调持续交付的能力,是面向用户的产品和特性交付能力。而发布是面向版本的发布能力,是发布过程一部分。今天不基于持续集成过程讲持续交付,我觉得还需要更大范围的讲。
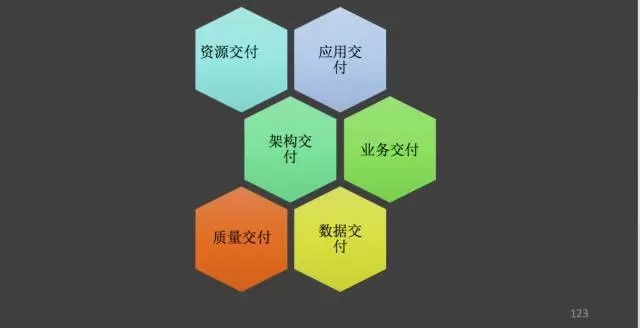
我自己做了一个分类。其实说到能力,在ITIL里面有一个核心流程叫能力管理,它就把IT服务的资源能力和业务能力做了匹配和映射,因此在ITIL里面给分了三个层次,资源能力层/服务能力层/业务能力层。这个概念其实是非常清晰的,但我觉得这个还是没法让人理解运维能力是什么,是不是让资源越充足越好?在有限的资源下提供有限的业务能力?在互联网业务形态下,都在强调能力的最大化输出。因此更多的是考虑如何让运维能力交付的时候更有效率,更有质量。因此我总结了如下的交付能力。
资源交付:面向底层资源的交付能力,常见基础架构类资源,比如说服务器/网络/虚拟机等都属于这个范畴。
应用交付:面向应用层的能力交付,常见版本发布升级等等,对应到持续集成和持续部署链上。
架构交付:这个属于技术架构部分,PAAS平台的核心,我之前和大家讲架构服务化的时候,也是从这个维度重点强调的。
业务交付:有了以上的基础,可以完成一个整体业务的交付了。
质量交付:是让运维确保业务质量,这个地方就需要很多的措施来保证,比如说标准化的能力/规范化的能力/流程的能力/架构设计的能力/监控的能力等等。
数据交付:让IT运营的数据可视化出来,使之变成一个有价值的产品,让运维有决策意义的数据运营能力。
安全交付:把安全变成一种能力直接提供给客户,比如说代码安全/数据安全/主机级安全/移动安全/应用安全/网络安全等等,一般很多公司由安全团队来完成。
有了底层资源/架构服务资源以及业务应用的交付能力,就可以完成一个完整业务的交付了。数据非常重要,我个人觉得,自动化平台能力很好构建,构建完成之后,其实就是数据化的运营能力。
大家会问应用交付和业务交付有什么不同?其实这个是分布式架构里不同粒度的交付。应用是一个程序/服务级别,而业务是由多个应用组成的。这个地方要特别提的一点,docker有点打破了以上边界的感觉,把资源交付能力和应用交付能力整合在一起,提高了交付的效率。
我自己也总结了一些方法论,确保交付能力的落地。比如说基于角色的能力交付/基于服务能力的分层划分/面向场景的交付整合等等。
基于角色的能力交付
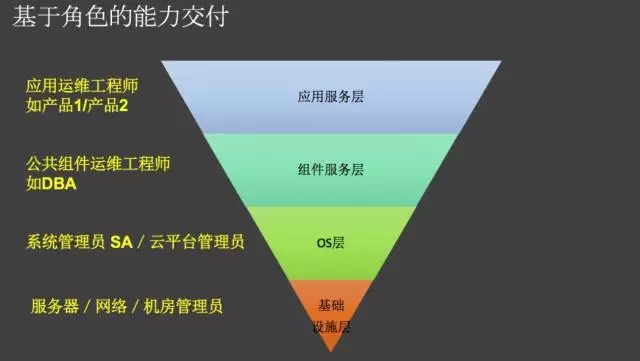
这个在我昨天的能力闭环体系里面着重讲道了它,不理清角色,你的交付平台建设一定是混乱的。云平台的监控能力和应用层的监控能力肯定是不同的。
在一个运维组织里面有很多个运维角色。传统的运维角色设定是根据资源对象划分的,但是这样的划分虽然确保了资源交付能力,但是彼此隔离。
基于服务能力的分层划分
互联网运维摸索出来的一个重大变化就是应用运维角色的出现,google 叫SRE,网站可靠性工程师,职能差不多。这个角色的出现有个好处,把过去面向资源的交付模式变成了面向业务的交付模式,服务化能力更强了。
我理解一种垂直的职能模式,变成横向的事业部模式,跨职能了。
针对每一层角色都应该考虑设计一个交付系统的时候,基于角色+资源对象的管理需求,一定需要平台化/服务化/webconsole化交付。下面给一个详细的图。
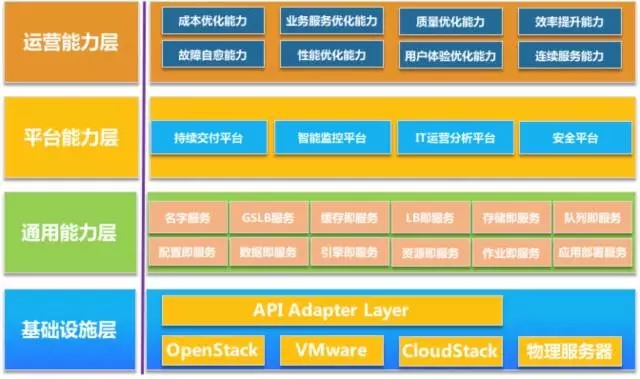
这一张图就把底层的能力到上层的运营能力打通了。
1、基础设施层。随着IaaS或虚拟化能力的逐渐普及,资源池的动态提供能力不断加强,不像物理服务器的资源池化能力。云平台能力可以通过API的能力交付出来(现在各家公有云都有相应的资源变更接口,没有资源池的概念),和物理服务器的资提供可以通过cmdb的接口获取到(cmdb的资源池)。
2、通用能力层。通用能力层是基于基础设施之上封装的公共服务能力,这层架构的能力分成两部分:一部分是面向业务技术架构的,另一部分是面向运维服务架构的。图中列的服务只是其中的部分,这个也是我经常和交流者强调能力建设的核心,不能把这个问题留给下面资源能力层,也不能交给上层平台能力层。
3、平台能力层。平台能力是指基于底层平台构建起来的运维自动化/数据化(监控+分析)/安全的能力平台,这层能力实现了底层能力的组合与封装,屏蔽底层各个专业子平台的实现细节,是面向业务运维场景的,比如说应用交付/资源交付/业务交付/持续反馈等等。
4、运营能力层。运营能力层暴露出来的是运维面向运维的支撑能力,是让业务看到运营价值的能力输出。面向业务的质量优化,面向用户体验的油画能力,连续的服务保障能力等等。该层已经超越了产品形式,更需要有迭代式的运营方法,里面需要体现数据运营的能力。比如说业务质量优化,运维需要构建业务质量模型,质量的数据来源,质量的问题发现,质量的改进措施,质量的持续改进机制,类似PDCA机制。
这个地方把面向业务技术架构的交付能力抽离出来说一下。
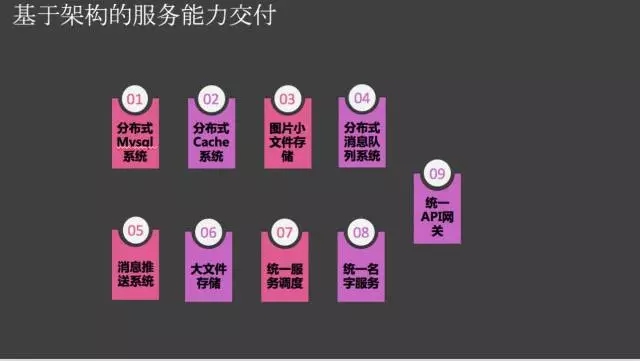
我在UC把技术架构服务能力公共化/抽象化出来。
对于一个技术架构来说,其中的技术组件可以简化和标准的。在这个图中,各层online的技术服务实现透明交付,解耦,通过名字服务,通过proxy网关,通过api网关等等,这个整体架构的交付能力就很强了。一个标准化/服务化的架构直接影响运维交付的能力。
可以形成标准的技术服务栈供用户选型!
前不久UC机房整体搬迁,几十个应用,几百台服务器,10天左右就搬迁过去了,整个数据层的迁移都是对应用透明的,无需研发和业务运维参与的,更多的是DBA运维的工作。
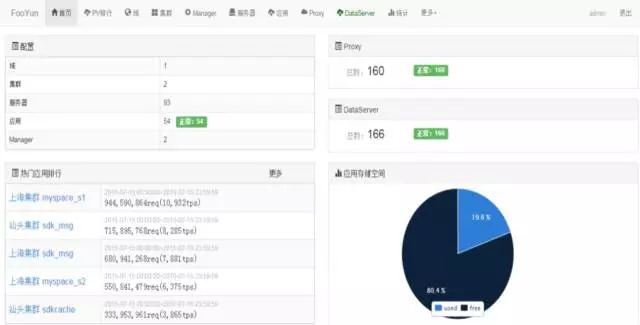
这个是之前UC的一个分布式cache系统。
在平台中可以看到对应资源的整体使用状况/应用的资源使用状况(左下角),以及在平台中提供了应用对应多种资源的管理(集群/服务器/proxy/data节点)等等。同时在mananger提供服务的变更能力以及服务的在线故障实时检测的功能。 所以我做运维的时候,对研发提的要求是,一方面要使用公共化组件,否则不予运维;其次公共组件必须提供平台化/webconsole化的管理能力给到运维,否则就是公共组件研发运维的人自己运维。
在技术架构中谈另外一个架构透明交付的例子--名字服务。大家在分布式系统中要完成这一实践,现在docker结合etcd实现了名字服务,但我觉得力度还不是太细,真正的名字服务可以到接口级别。
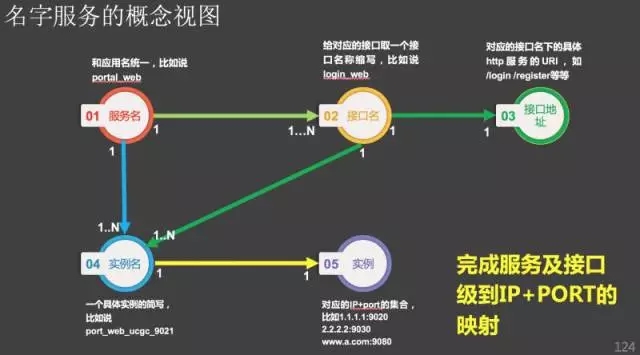
这个能力实现之后,刚刚说的服务之间的解耦就完成。特别忌讳服务之间的调用依赖配置文件中的配置完成的,这是一种hardcode。
架构化的透明服务交付就讲着么多,其实这个和paas平台有直接的映射。我的paas化平台思路也和过去的*AE有些不同,在此不展开了。
面向场景的交付整合
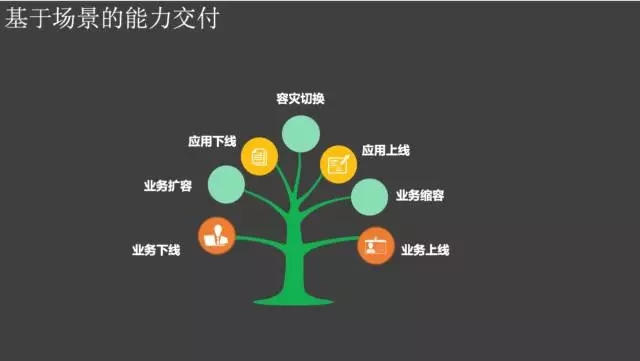
所有的交付能力都是为业务服务的,核心便是场景了。
在这层的交付能力完整实现已经打破了组织的职能边界和运维系统边界,提升了自动化能力水平等等。
这个地方举两个例子:
1、自动化测试能力。一个服务要大批量上线,此时所有的运维环境已经部署完成,此时进入测试阶段。但传统的测试模式基于手工的,此时大大的影响上线效率。这个时候就需要测试部把测试能力服务化,在工具层面上进行对接就好了。10年我们运维农牧场业务的时候,每次扩容几百台服务器,肯定不能依赖人工,就实践的是这种方式。
2、GSLB调度服务。传统企业的DNS服务,有些是基于F5 GTM来实现,有些是基于windows的DNSserver实现,这两者的能力自动化水平明显不足,为了更快的支撑业务变更,此时则需要对这些服务的自动化能力封装,使之API化。

我自己总结了有四点
1、业务信息管理平台。为了体现和cmdb的差别,这块我取名叫业务信息管理平台,偏向是OS之上的业务信息/资源/配置的管理。业务的运维管理平台是以应用为核心来构造运维的信息管理,方便后面实现跨平台的整合。把后段的服务当作附加资源管理,实现服务关联。
2、一体化的运维平台设计和规划。这个很多运维组织的通病,原因有很多种:第一、运维研发不懂全局运维;第二、运维研发很多都是运维转型而来,不知道软件设计的方法论等等。特别是中小公司的运维研发团队更明显。
3、应用运维+运维为核心的组织设计。缺少面向业务运维的团队设置,让运维面相业务的交付能力变得割裂了。其次运维研发才是实现运维能力持续/快速/高质量交付的保障。
4、Dev/Ops没有楚河汉界。开发要考虑运维的交付实现,运维要把服务化的交付能力提供给研发。
我感觉还有个要素,完善的文档。可能是和我的运维经历有关系,文档的更新远远落后于程序的更新。所以我宁愿不要文档,不要文档怎么实现运维呢?代码定义/配置定义架构好了。部署能力在线化协作,也不要文档来文档去。
Q1:能否谈谈日志在运维里的重要性?
A1 : 日志应该是故障定位和数据分析的核心数据来源了。从故障处理的角度来看的话,我把他分成三个阶段:故障发现/故障定位/故障解决。其实故障发现和故障定位都很强的依赖日志,但是很不幸运的是很多团队把故障发现的能力也移交给日志了,比如说关键字监控/日志增长速度等等。更好的做法其实应该把故障定位的能力 依赖在日志数据的采集和分析上。
再到第二个点,数据分析。从日志里面能采集到大量的有价值数据,无论是业务的指标数据还是技术指标的数据。典型的 webserver访问日志,这个里面可以分析用户的来源,访问体验,流量分析,请求性能分析等等。我现在的做法是把一些应用性能的日志分析行为转移到一个接口数据上,通过接口数据来简化日志的输出,我们称之为接口间性能数据。
Q2 : 一般领导都会着重开发,优先业务先上线,运维风险暂时就难以顾及了,这时标准化的要求并不起作用,不知道您是否遇到过这种情况,请问该如何跟领导沟通解决这个问题的?
A2 : 这个场景是有的。这种思维在运维团队里面都存在。我的通常做法是和研发leader沟通业务运维的重要性,达成共识。另外一个做法是每个阶段把自己的运维规划和业务部门沟通,让他们意识到我下一步要做什么。最后一点就是运维一定要有价值的输出给研发,比如说你的数据分析平台, 端到端的数据整合平台等等,对方看到我们有价值的输出,后续的合作和信任也便有了。很多时候问题都是由于研发不了解运维,运维者没有让研发足够了解导致的。
Q3: 请谈谈APM在运维里的重要性。
A3: APM的确很重要,应用性能管理可以拆解为接口性能和服务性能。接口性能可以通过一些规范约束来实现,而服务性能其实可以通过一些标准的容器来统计达到的。
在一个海量分布式系统,我更支持研发标准规范的植入来实现apm的能力,这个就是我之前基于名字服务和统一调度把所有的服务调用链染色了。差不多也是apm的能力
Q4:没有完善的文档对于工作交接的影响大吗?
A4 : 其实如果很多能力平台化之后,很多工作的交接就非常简单了。不需要文档。
优维科技公司创办人,07年进入腾讯公司接触运维,经历服务器从百到万的运维历程,先后在YY和UC参与不同业务形态的运维,期间带过多种运维团队。
讲师介绍:王津银
优维科技公司创办人。
07年进入腾讯公司接触运维,经历服务器从百到万的运维历程,先后在YY和UC参与不同业务形态的运维,期间带过多种运维团队。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看陈科《memcached&redis等分布式缓存的实现原理》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看郑晓辉《存储和数据库不得不说的故事》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看杨建荣《立等可取:工具定制让Oracle优化变得更简单快捷》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看徐桂林《以应用为中心的企业混合云管理》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721