

转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
目录
什么时候触发行溢出
行溢出的存储结构
行溢出的整体逻辑结构图
总结
本文以SQL Server为例聊聊行溢出的存储结构。
SQL Server的行溢出数据只会发生在变长字段上,变长列的长度不能超过标准变长列最大值8000个字节的限制,而且还要满足:
包括行头系统信息和所有定长列和变长系统信息的所有长度不能超过8060字节,要想存储8000字节以上的数据,应该使用LOB(text、ntext或者image)或者MAX数据类型;
变长列的实际长度一定要超过24个字节(因为行溢出需要额外的24个字节行溢出指针,如果变长字段值不超过24个字节,完全没有必要把它作为行溢出数据存储);
变长列不能是聚集索引键的一部分(如果行溢出是聚集索引键的一部分,那么表的查询性能会是一个噩梦);
为了了解Overflow的结构,我们创建表HeapPage_Overflow,并插入测试数据:

查看这行记录对于Page的内容:
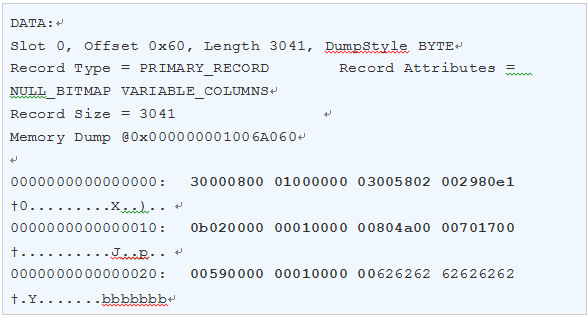
上面Page数据中的一行记录可以格式化为下图所示:

图1:堆表HeapPage_Overflow记录结构
其中几个重要部分结构解释如下:
0x2980这是包含后面指向存储行溢出的变长字段偏移量。把0x2980逆序成0x8029,再把0x8029转换为二进制1000000000101001,去除高2位(也就是粗体部分),取101001,转换为十进制就是41,高2位的目的其实只是一个标识,为了跟普通记录的变长字段偏移量进行区分。
第一个变长字段偏移量41是由17个字节系统信息加上24个字节的行溢出指针共同组成,计算公式为:41=17+24,下面对这24个字节的行溢出指针进行结构分析:
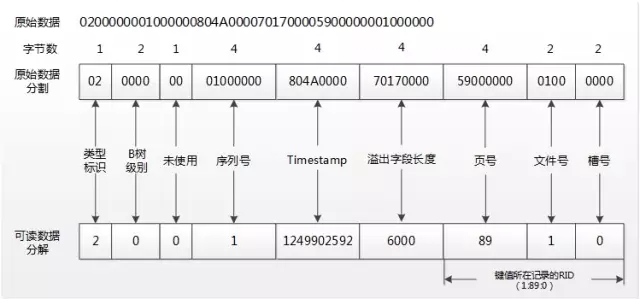
图2:堆表HeapPage_Overflow的行溢出指针结构
0x02,特殊字段的类型,0x02表示行溢出数据;
0x0000,表示B树中的层级,行溢出的记录,这个值为始终为0,在LOB记录的ROOT记录中这个值为0x0100;
0x00,暂时未使用;
0x01000000,一个序列号,每次行溢出或LOB数据被更新时这个值加1,并在乐观并发控制为游标使用;
0x804A0000,Timestamp值,用于使用DBCC CHECKTABLE检查表索引、行内、LOB 以及行溢出数据页是否已正确链接。在LOB的行内数据、LOB的ROOT指针以及存储LOB的数据结构中都存储了这个值,而且他们的值都是一样的。0x804A0000逆序之后是0x0004A80,再向0x0004A80后面追加4个0得到0x0004A800000,转换为十进制为1249902592;要验证这个标识值的算法,可以使用工具Winhex修改0x804A0000值并使用DBCC PAGE(Overflow,1,93,3) 查看Timestamp值。
0x70170000,溢出字段长度,0x70170000逆序之后是0x00001770,用十进制表示是6000,这个跟前面插入记录时字段的大小完全吻合;
0x5900000001000000表示一个8个字节的RID地址,指向行溢出字段VarCol存储6000字节所在数据页的RID地址为:(1:89:0)。
上面已经分析了在行内数据中存储的行溢出指针的结构,接下来将分析存储行溢出数据的物理结构。
查看行溢出存储Page的内容:
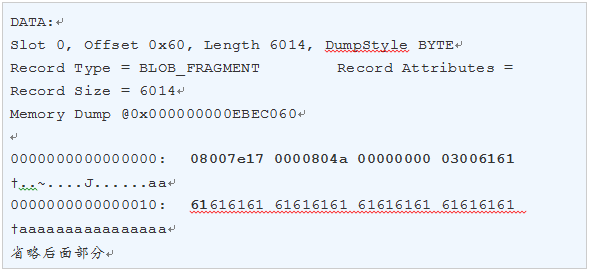
上面Page数据中的一行记录可以格式化为下图所示:
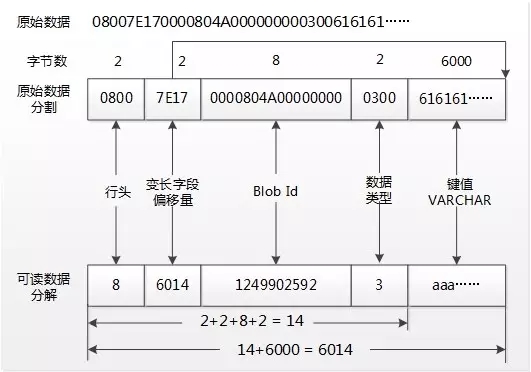
图3:堆表HeapPage_Overflow的行溢出数据结构
0x0800是这一行记录的行头数据,分解为Byte#0的十六进制是0x08和Byte#1的十六进制是0x00,0x08转换为二进制是:00001000,各个bit表示的含义如下:
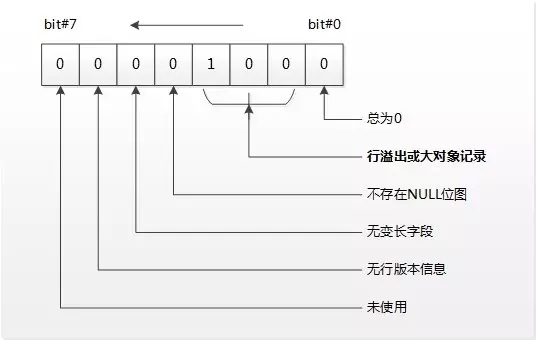
图4:堆表HeapPage_Overflow的行溢出行头结构
0x7E17是变长偏移量,经过逆序之后是0x177E,用十进制表示是6014,这个偏移量包含了14个字节的行溢出系统数据和6000个字节的行溢出字段值;
0x0000804A00000000是Blob Id值,跟IN_ROW_DATA记录中24个字节的行溢出指针的Timestamp值是相等的。要验证这个标识值的算法,可以使用工具Winhex修改0x0000804A00000000的值并使用DBCC PAGE(Overflow,1,89,3)查看这个Blob Id值。如果不相等,虽然SELECT一样能查询数据,但是在进行DBCC CHECKDB将会报引用不匹配的错误信息。
0x0300是数据类型,转换为十进制是3,Type=3表示DATA,即表示这行记录是用于存储数据的。
根据上面对行记录存储结构的分析,行溢出的逻辑可以通过下面的图来表示:
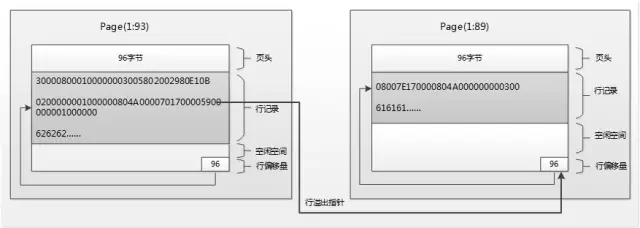
图5:堆表HeapPage_Forward第一行记录行溢出后的存储结构示意图
上文以堆表的行溢出数据为例讲解它的存储结构,从结构来看一行记录的存储跨越了两个Page,相比于一条记录存储在一个Page里,查询的时候增加了1个IO,当表比较大的时候,随机IO将会猛增,将会出现性能上的问题,一般建议控制好变长字段的大小,或者使用其它数据类型避免行溢出,也可以考虑表的垂直拆分。
更多关于SQL Server存储结构请参考《SQL Server性能调优实战》
作者介绍:陈畅亮
【DBA+社群】广州联合发起人
微软SQL Server方向最有价值专家(MVP),《SQL Server性能调优实战》作者,《Windows PowerShell实战指南(第2版)》译者。
主要研究MySQL、SQL Server、NoSQL,以及分布式环境下海量数据存储的设计与开发。
2015年DTCC大会演讲嘉宾
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看陈科《memcached&redis等分布式缓存的实现原理》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看郑晓辉《存储和数据库不得不说的故事》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看李海翔《MySQL优化案例:半连接(semi join)优化方式导致的查询性能低下》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看徐桂林《以应用为中心的企业混合云管理》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721