

朱贤文,超过17年IT经验,曾为 SYMANTEC/VERITAS, ORACLE, IBM 和 HP 工作,精通PostgreSQL,Oracle/RAC/ASM, VERITAS Storage Foundation(VCS,SFRAC etc)。拥有广泛的行业经验,包括银行,电信,保险及政府行业。目前在创业,专注于提供PostgreSQL数据库服务和配套解决方案,推动PostgreSQL数据库在中国的普及与应用。
根据与许多客户的沟通,客户往往最容易忽略掉的环节就是存储系统,而存储系统里面,文件系统被关注是最少的。
本次技术分享的关注点就是存放数据库的文件系统,将简单描述文件系统及其缓存大概的架构,基本的工作原理,使用文件系统需要注意的事项,在设计和使用不同的数据库的存储子系统的时候有更全面的考虑。
本图片涉及到的原理图只为示意,不是工作原理的精确表达,请见谅。
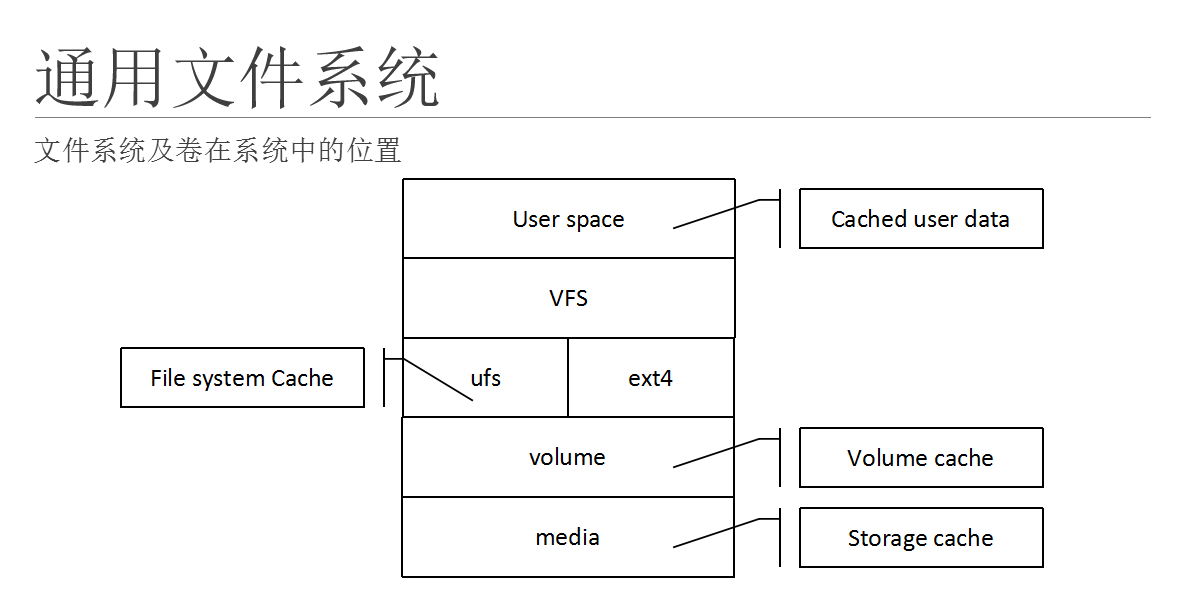
这个页面粗略地描述了文件系统跟存储的架构,文件系统,卷,跟存储在操作系统中的位置。
操作系统里面的内存分为两个基本的部分:用户空间和内核空间,内核空间主要存放操作系统自身的软件代码和数据,如驱动程序,任务调度,内存分配和管理的程序。
用户空间用以存放用户自己的应用程序;数据库系统对于操作系统来说是一个比较大的应用程序,所以数据库的进程以及这些进程涉及到的内存空间都被分配到了用户空间;所以像oracle的sga;PostgreSQL的shared_buffers等内存使用的空间都被安排在用户空间。
数据库需要将数据永久的保存起来,所以它就需要跟下层的存储系统打交道;存放数据的存储系统大概分为几类,裸设备,通用文件系统,专用文件系统等。
在访问文件系统的时候,经过的路径大概是:user space à vfs à fs à vm à storage media。在很多层面,都有自己的缓存管理机制;比如用户空间内,应用程序有自己的缓存管理机制,oracle:sga;postgresql:shared_buffers/xxxx ; 文件系统自己有自己的数据老化算法;如ext4,jfs,ntfs等;再往下面走,就是卷管里程序,比如vxvm,lvm等,它也有自己的缓存管理机制,再往下就是存储介质,比如sata磁盘;磁盘阵列划分到主机上的lun。磁盘有自己的磁盘缓存,lun的后端也有很大的缓存。
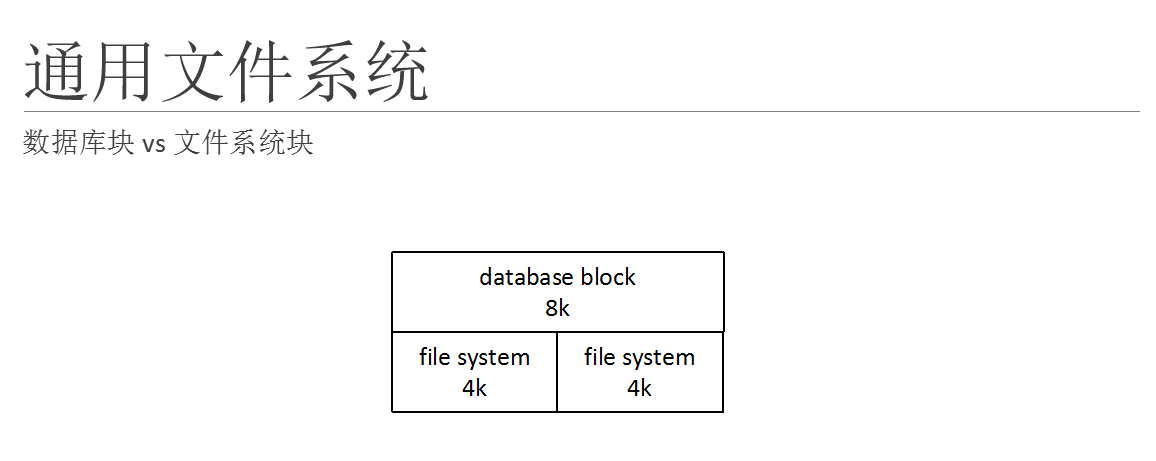
介绍完文件系统和存储的基本架构后,接下来讨论一下数据库的块跟文件系统的对应关系。数据库跟文件系统一样,最小的存储物理单位是一个block,根据不一样的数据库,这个block的大小不同;informix默认的块大小是4k,oracle的默认块大小是8k,postgresql也是一样,默认情况下是8k。
但是在文件系统层面,绝大多数文件系统支持4k,(除了vxfs和zfs)。vxfs支持最大64k,可以设置成512byte,1k,2k,4k,8k,16k,32k,64k。
zfs是一个特殊的怪物;数据块是动态的,也就是说写入多少数据,zfs上那块存放数据的块就有那么大。传统上是支持动态的512byte到128k。
oracle的solaris版本的zfs支持512byte~4M动态分配块的大小。去年我在社区里面跟matt一起做了最新的zfs的特性,可以动态支持块的大小为512byte~16M。
对于数据库应用来说,需要清楚的知道每个数据库块所对应的文件系统块的大小。
这一点非常重要,在pg早期的时候,没有一个参数来控制写对其,会导致潜在的data corruption,就是因为这个原因导致wal在写入的时候没有要求full page write(8k)导致的数据存坏。因为wal不做这个限制,比如写入4k到文件系统,在文件系统的角度来看是一个完整的4k;这时候发生意外,需要做恢复,那么文件系统的层面可以恢复最后写入的4k数据,但是对于pg来说,最后的那个8k是坏的;因为它每次读取的数据至少是8k,而实际上文件系统只能提供4k数据,部分能提供完整的8k数据。所以pg就会认为那块数据是顺坏的。
如果使用oracle,这些细节已经在oracle里面处理好了,所以dba是感受不到的。但是如果使用其它数据库,比如mysql,好像是16k每个块,就应该要注意这个块的问题。
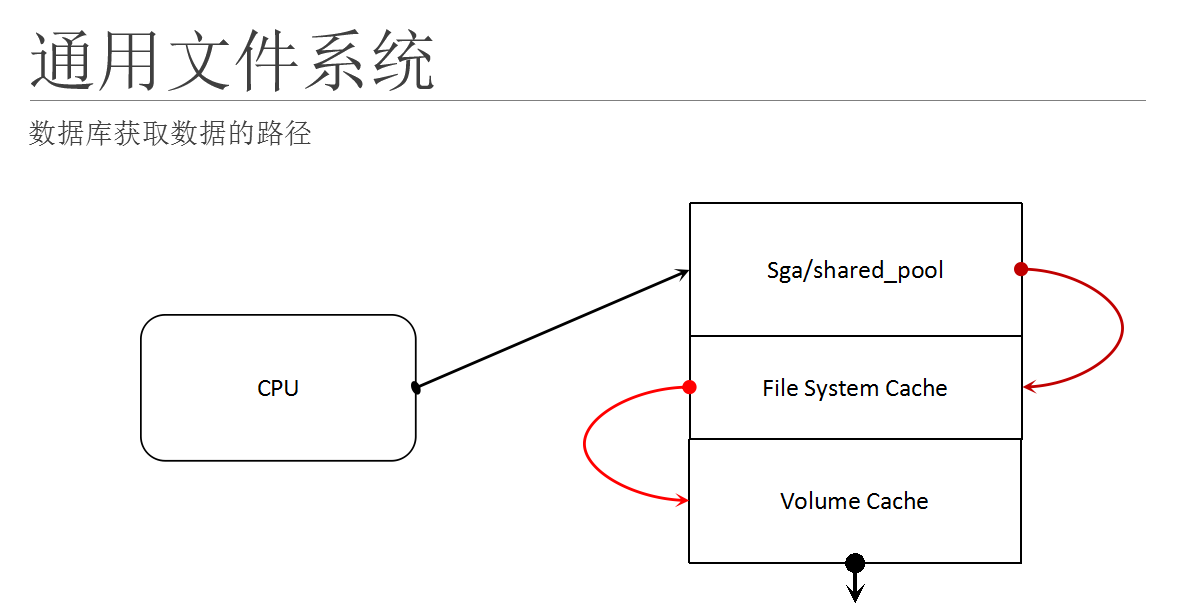
这个图是一个数据查找的路径,说明double cache的原理。
当cpu需要获取数据库的数据的时候,那么它会先到数据库的缓存里面去查找,就是我们的sga/shared_buffers(pg),其他数据库也有类似的缓存区;
如果在该缓存去查找到了数据,那么数据会被装载入cpu,进行运算;如果数不在缓冲区,那么数据库就会向存储系统系统(实际上是文件系统)发出获取数据的请求;文件系统也有自己的缓存,所以类似的操作,文件系统要先看看被查找的数据是否在缓存里面,如果在缓存里面,那么就向数据库返回该数据,如果不在文件系统的缓存内,那么文件系统就要向卷管理程序发出请求,要求提供该数据;在卷管理程序也会做类似的操作。
所以在这个路径上面,就会经过很多层面的缓存,这个现象叫double cache;double cache对于数据库应用来说典型的就是使查找效率降低,同时使得cpu用量提高。所以在数据库应用中需要避免double cache。
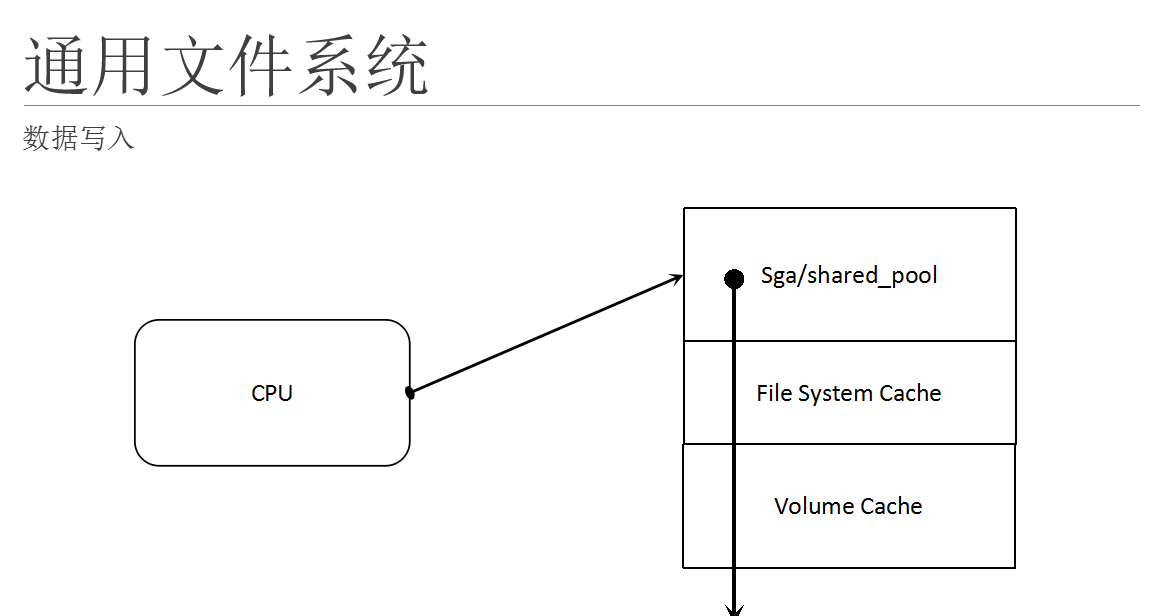
这个图描述了写入数据的路径。正常情况下,我们希望写入的数据能够可靠正确地写入存储介质,同时要求尽快的相应/返回;但是因为文件系统有很多选项,就决定了写入的很多行为。
第一种就是回写,就是数据库将脏数据写给文件系统,文件系统正确的接收到,并且将写入的数据缓存在文件系统的缓存里面,就向数据库返回写入成功,实际上这些数据还在文件系统的缓存里面,还没有可靠的写入存储介质。
第二种就是透写,就是数据库将脏数据写入文件系统,文件系统收到数据库立即向存储介质写入数据,当文件系统得到存储介质报告完全写入成功后,才认为本次写入成功,所以才向数据库返回。
这两种写入方式对于数据库来说,一种方式能够提供非常高的写入性能,一种是提供非常高的可靠性。所以需要了解其基本的原理。
在存储介质这个层面,还有一层缓存,比如磁盘有一颗32M或者64M的缓存,对于上层应的写入,写入到这个缓存,上层的应用就认为写入永久存储介质了,而实际上这个数据还没有完全写入到磁盘的盘片,我们的真正的介质上去;如果这个时候发生突然掉电,那么一样会发生数据丢失;所以当使用磁盘直接存放数据的时候也需要注意这个问题。
当对每个层面的缓存了解后,根据数据库的情况,可以灵活地控制如何使用这些缓存,需要高性能?还是高可靠性?可以灵活的控制。
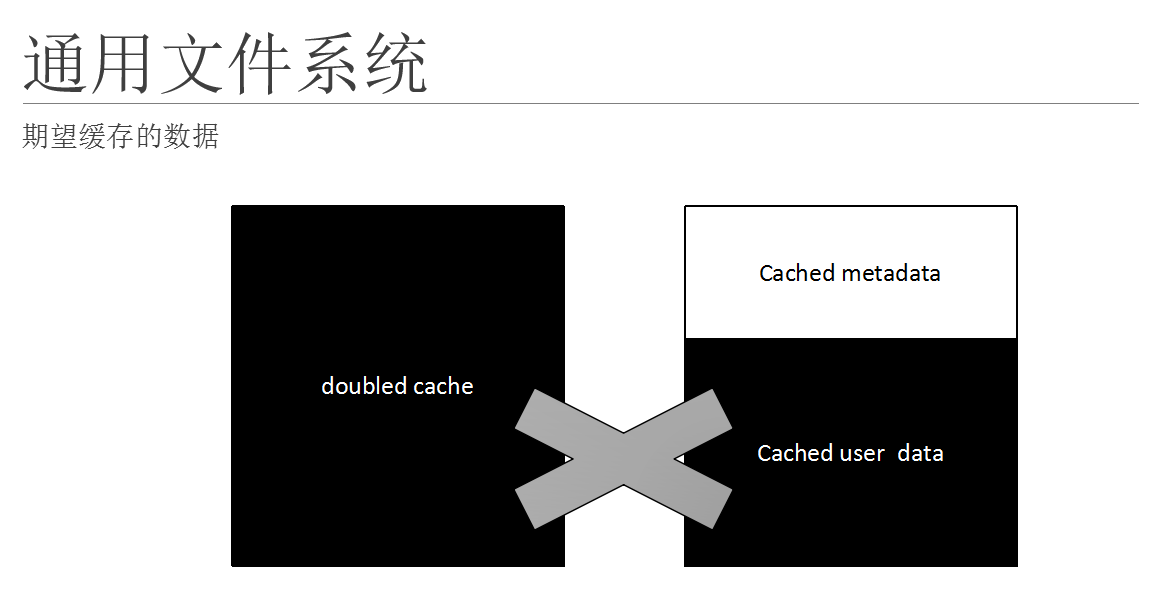
这个图对于有自己缓存系统的应用程序,比如数据库有自己的缓存管理系统,那么我们应该尽量避免double cache的出现;对于文件系统,理想的配合数据库使用的文件系统,我们希望它的缓存只限制于文件系统自身的meta data的管理和缓存,不去缓存用户数据。
对于像数据库这种有自己的内存区和内存管理的应用程序。应该避免double引起的性能衰减;同时用户的数据尽量要避免缓存到文件系统上。
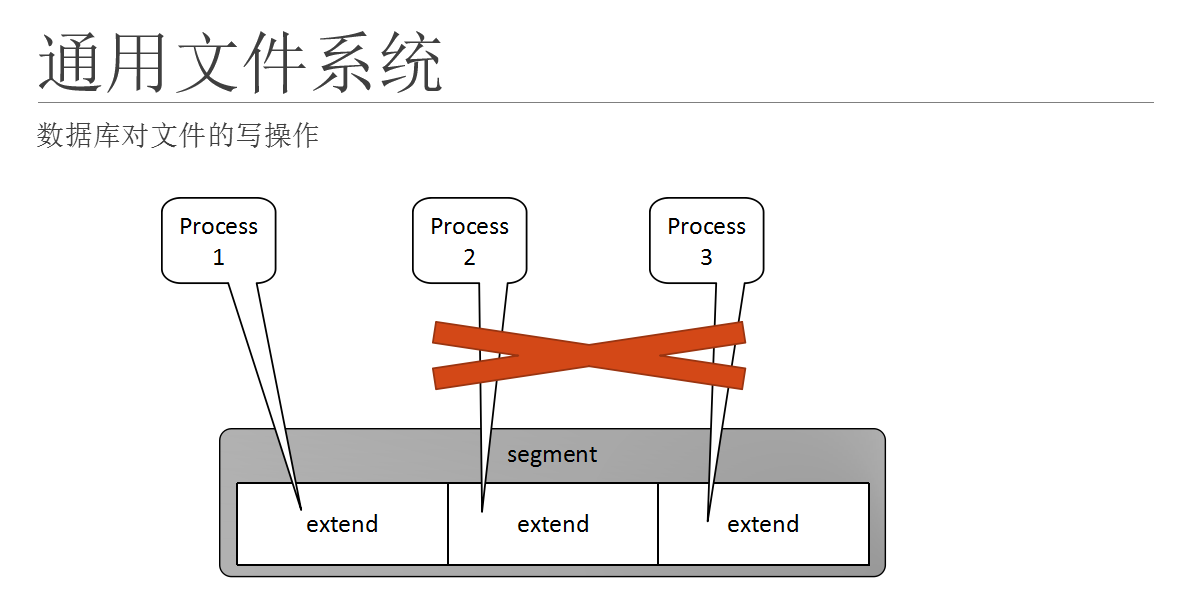
数据库内,一个表分布在多个segment上;而组成segment的单位是我们的extend。Segment在文件系统层面来看就是一个数据文件。
数据库在操作一个表的时候,有很多情况下,活着说发生这样的几率;不同的数据库进程需要操作的数据块在同一个文件里面,但是在文件的不同位置(extend),由于文件系统需要保证自己的acid;所以这些进程需要通过锁的机制来决定谁先操作,谁后操作。
如图所示,当这些进程操作数据时,只有抢到x锁(排他锁)的进程才能对自己要操作的数据块进行操作,当完成后,将x锁释放;其它进程再抢x锁;如此进行。也就是说只能串行写入,影响性能。而实际情况是,数据库已经保证了acid,这些数据本身没有冲突;这些进程之间的操作可以同时进行而不相互影响。
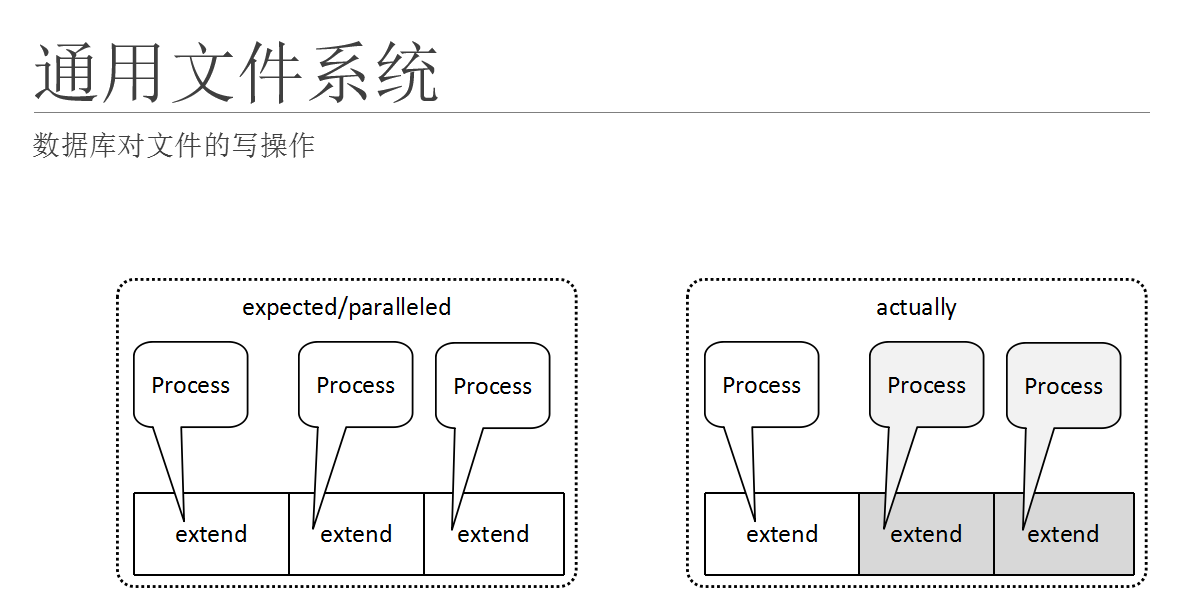
所以对于数据库来说,它希望向左边这个图这样工作,而实际情况是右边这种情况(使用文件系统存放数据库)。在示意图上,左边是数据库应用,我们希望的操作数据的行为,即使在同一个文件里面,因为数据库已尽保证了acid这些东西,不会在下层的存储层面冲突。所以希望只要不在相同的数据块上面,这些数据操作都可以并行进行。
右面是使用一般的文件系统的行为,具体情况以及在上一页描述过了,进程之间不得不去抢文件的x锁,更新完成之后将所释放,流给后面的进程做同样的事情。从而引起本来可以避免的性能问题。

为了解决前三页的这些问题,业界就数据库应用开发了专用的文件系统,比如oracle的asm(只能运行oracle数据库),veritas的vxfs,vxfs文件系统有非常高级和强大的功能,同时提供各种应用场合强大的性能特性;支持oracle,db2, Informix, Sybase, postgresql等数据库。
在asm和vxfs里面,能做到高性能的根本原因就是允许对同一个文件并行写入。(传统的文件系统只允许对同一个文件同时读取,但是不允许并行写入),写入的(用户)数据的一致性完全由数据库控制和保障,存储层面只需要保证meta data一致。
存储的缓存只负责缓存最基本的元数据meta data,用户数据不会被缓存起来,这样又能有效避免double cache引起的副作用。
所以运行数据库,比较理想的文件系统应该是:运行对一个文件并行写入,同时不缓存用户的数据。现在市场上可选的只有asm跟vxfs文件系统是比较好的选择。当然还有ZFS,绝对的利器。
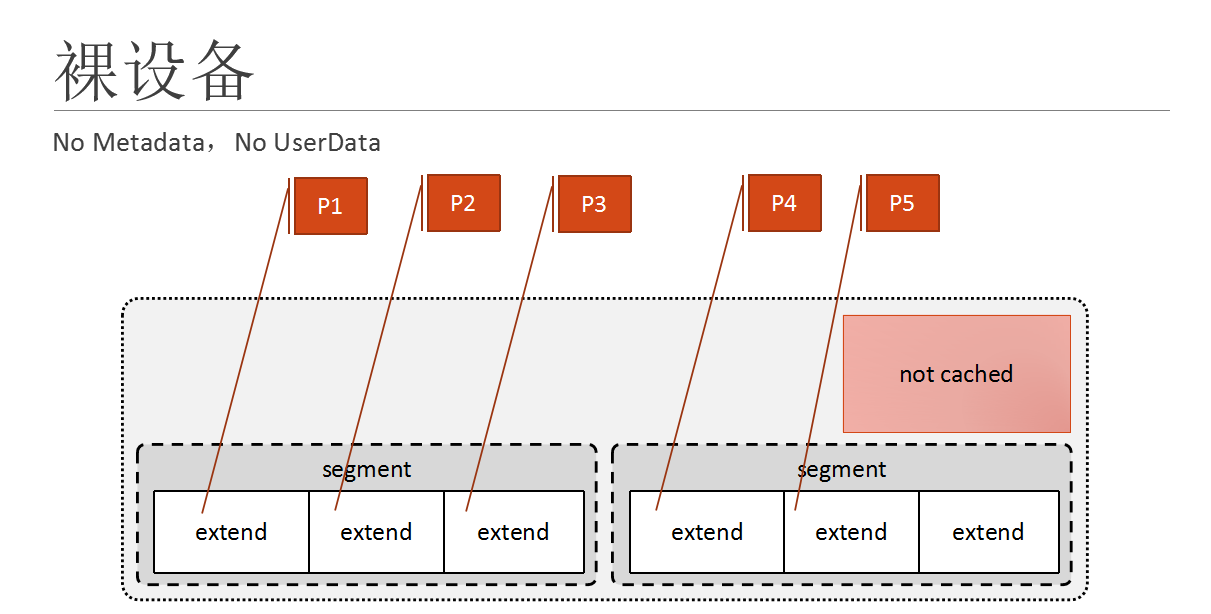
接下来就会说裸设备,很多人接触和使用过裸设备,也有很多数据库页支持裸设备,但是oracle最近的版本将不建议使用裸设备,后面的版本就直接不支持了其原因就在于:
裸设备,因为是裸设备,所以没有繁琐的缓存机制,那么用户写入的数据就直接写入到介质上;同时避免了double cache;裸设备不仅不缓存用户数据,也不缓存基本的metadata;因为使用裸设备的高性能,曾经一度比较流行使用裸设备。
由于裸设备的性质决定了它不能提供任何缓存,也不对数据做任何保证,对数据的安全要全权由用户跟数据库管理系统来保证,所以当使用裸设备发生断电的时候,最容易造成数据库崩溃,数据损坏等不可控的情况出现。所以裸设备正在被遭到抛弃,ORACLE数据库最近几个版本已经不再支持罗设备了。
我们也不建议使用裸设备,因为不安全,不可靠。

这张表,以时钟频率为3.3G的cpu为例,说明cpu这个角度来看时间跨度。
如果将cpu的时间看成是我们生活中的1秒;cpu在一级缓存取一次数据的时间需要3秒;在内存里面去一次数据需要的时间是6分钟;在PCIe SSD里面去一次数据的时间大概是两天半,如果在本级磁盘存储一次数据,需要的时间跨度就非常大,如果按照5毫秒计算,对于cpu来说就花了半年多时间;如果稍微慢一点,变成10毫秒,对于cpu来说就花费了1年多时间。
这个表的目的就是要理解cpu的时间跨度,在设计存储子系统的时候有个参考。有了这个基本的概念,我们再继续聊下面的内容。
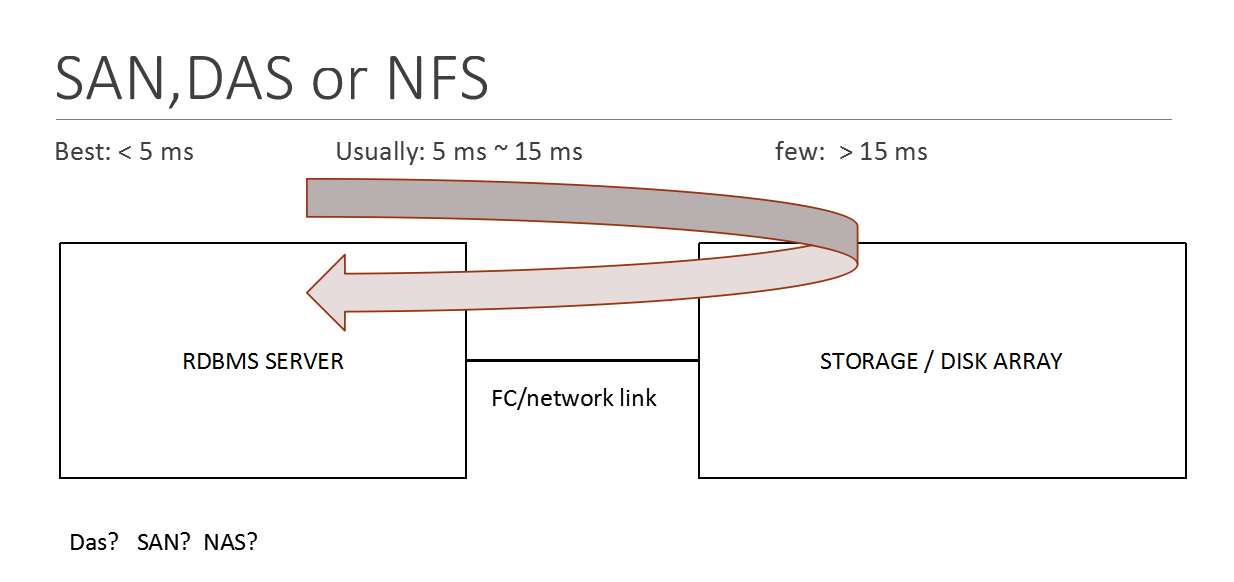
这张图比较粗略地描述了数据库服务器跟存储之间的连接关系和数据流向。
一个专业的存储,可以抽象地看作是一个挂载了非常多磁盘的计算机,这部特殊的计算机,要么通过网络将自己的存储资源共享,一般是nas;要么通过光纤共享,一般是san。也可以在自己的计算机上挂在磁盘。
数据库应用如果采用专门的存储,查找数据的流程如示意图所示,先要在本机查找,本机没有找到数据的情况下,向存储服务器查找,如果数据在存储的缓存里面,那么可以很快的返回,如果数据不在存储的缓存里面,还需要走类似的流程到存储自己的硬盘上面去取数据,然后再将数据送回。
如果数据在存储的缓存里面,一般需要5毫秒左右;在我们看来,这个时间延迟非常满意,但是在计算机的看来,以及等了半年了。
如果因为存储响应不及时,或者它还要到自己的磁盘上面去取数据;那么一年半载的很容易就过去了。
这个流程大家都知道,也能够理解。但是站在cpu的角度来看时间的跨度,可能很少有人这样来思考这个问题,而这一点恰好是我们需要关注的。
作为数据库应用来说,应当是IOPS,也就是响应时间要越短越好,而存储往往是这个环节的主要矛盾。所以大家在设计数据库应用的时候,要多关注存储部分的响应时间。

如何正确的使用存储,尤其是正确的使用文件系统。首先要正确地选择存储介质,san? 本地ssd? nas?要看自己的需求是带宽还是iops。
然后就是要规划好存储,比如对齐,文件系统跟卷;卷跟下层的磁盘/LUN;随机数据/顺序数据;永久数据/零时数据。需要将不同的io通过存储字系统的设计进行隔离。
其次是要正确地利用好缓存,不是缓存越多越好;要根据数据库里面经常被访问到的热点数据而确定缓存的大小。
最后就是要确保所有的数据要安全可靠地写入永久存储介质。
[问题1]有没有试过通过设置oracle数据库的IO方面的参数来绕过文件系统的缓存?
[问题2]oltp系统和oltp系统在选择存储上是有区别的,那么应该如何区别呢?
答:很明显oltp跟olap的应用,在io行为上是明显不同的。对于存储的选择;因为olap是带宽需求型,对iops的消耗很小。所以olap的应用,如果带宽足够宽,那么nas(eg: over 10GB)也是可以考虑的。设计的目的就是需要将带宽耗尽,也就是说要尽最大可能向应用提供最大的带宽。
如果用文件系统,我会建议ZFS,因为一个IO可以给你4M数据(oracle)或者16M数据(我们的版本)。对于OLAP,主要目的就是要尽量提高吞吐量,降低IO的开销。
oltp的情况,如果用oracle,我会推荐asm或者vxfs,因为vxfs能提供非常高的性能。pg跟mysql ,如果在Linux平台上面,ext4根xfs都是 比较好的选择。但是要注意一些mount参数,数据库里面写数据的方式,一定要full_page_write,并且要fsync的方式写盘,保证数据是写入到存储介质了;如果使用sata,要确保sata的缓存是关闭的,目的就是要确保数据被可靠地写入到存储介质上了。
【问题3】vxfs比asm好在哪些地方?
【问题4】mha的日志分支问题一般有什么好的解决方法?
【问题5】请问我们有套文档管理系统,存放实体文件的服务器上的文件很大,但是都是很多很小的文件组成的,这样的话怎么选存储合适?
答:这种应用,建议采用zfs,或者vxfs,ext4也是可以考虑的。我会强烈推荐用zfs (可以下载我们的操作系统自带的原生的zfs http://pan.baidu.com/s/1eQznX8e#path=%252FXianOS.Install.Image)。
【问题6】请问同一个阵列,采用asm结构,扩展一个102G的数据文件用时约15分钟。改成vxfs文件系统后,扩展同样大小的数据文件用时约50分钟。性能为什么会下降这么厉害?
【问题7】我们这边使用的服务器大部分都自动十几块4T硬盘,这样的服务器是不是影响存储性能和数据库的性能?
【问题8】Oracle rac集群在企业生产上除了使用ASM,企业使用的还有哪些?
【问题9】asm是文件系统吗?
【问题10】共享文件系统有哪些?哪个比较稳定?
答:真正意义上的共享文件系统有IBM的GPFS,VERITAS的cfs;GPFS在某些场合下不适用,比如高并发条件下的小块数据访问。我推荐用CFS 。
【问题11】对于DBA来说需要掌握的外围知识逐渐增多,当然包括今天讨论的话题,那么,我们对存储了解到什么深度能满足DBA工作的需要?另外有什么好的书可推荐么?
【问题12】数据库本身提供了一些可扩展的方案,但很多厂家都还在做自己的分布式访问中间件或分布式DB,请问您怎么看这两者后续的发展?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721