
12月8日,IBM软件工程师胡泽远老师,在DBA+社群DB2用户群进行了一次主题为“Big Data Strategy & Big SQL”的线上分享。小编特别整理出其中精华内容,供大家学习交流。同时,也非常感谢胡泽远老师对DBA+社群给予的大力支持。
胡泽远
毕业于美国威斯康星麦迪逊分校
现任IBM软件工程师,在IBM中国软件研究开发实验室从事Big SQL有关开发
大家好,我是胡泽远。今天由我为大家简单介绍一下IBM BigInsights for Apache Hadoop产品以及旗下的Big SQL模块。

上图为IBM BigInsights产品的整体架构。首先,我们一起来看一下底下浅绿色方框,上面写的是IBM Open Platform with Apache Hadoop(简称IOP)。Open Data Platform是由众多业界领导企业以及Apache Software Foundation牵头,旨在建立促进以Hadoop为平台大数据解决方案生态圈和优化Hadoop技术。这里Hadoop distribution包含了ODP core of Apache Hadoop 2.6 (HDFS, YARN, MapReduce)以及其他众多Apache项目技术。换句话讲,IOP集成了Hadoop及其相关的功能组件,提高稳定性的同时免去用户搭建Hadoop方面的困扰,使用户可以将重心放在Hadoop平台上的使用开发。
参与企业有IBM、Hortonworks、TERADATA等大数据相关知名企业,大家可以通过下面链接去详细了解:http://www.odpi.org/
在IOP的基础上IBM针对不同的客户需求提供了3种不同的解决方案:IBM BigInsights Analyst主要针对analysts(分析员),提供以Hadoop平台为支撑最全面快捷的SQL引擎,也就是我们接下来要讲到的Big SQL,以及以Excel表格的形式让用户更加直接简单地去管理、视觉化、筛选以Hadoop为平台的数据的BigSheets。针对数据科学家,在Big SQL, BigSheets的基础上,IBM推出了BigR。它能直接兼容R语言,并提供丰富强大的机器学习算法库,以及从不规则结构信息中提取有用信息的能力。最后,针对数据管理人员,IBM又推出了IBM BigInsights Enterprise Management模块。这里包含的主要是IBM Spectrum Scale-FPO (也就是之前的IBM General Parallel File System with the File Placement Optimizer (GPFS-FPO))。它可以和所有Hadoop平台应用兼容,并提供Hadoop平台不具备的与其他平台的兼容性。同时模块中的IBM Spectrum Scale Active File Management (AFM)提供跨地域的数据备份及灾难修复。同时IBM Platform Symphony也包含在这个模块之中,让管理员能在Hadoop平台上针对不同的用户组通过数据隔离以及多租户技术来提高数据安全以及资源利用。
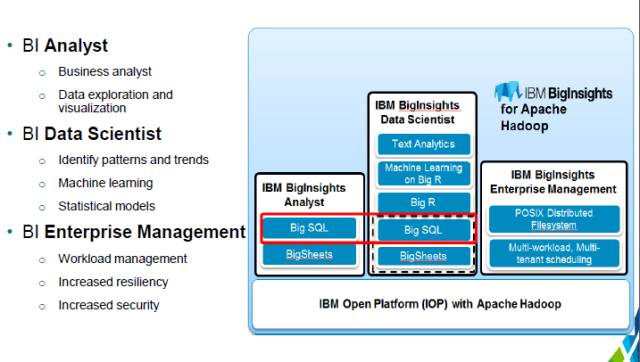
上面的图片为大家简单概述了一下IBM三大模块在IOP平台上的不同作用。从图片上我们又可以看出Big SQL同时出现在了针对分析员以及数据科学家的模块中。可见其重要性,下面重点介绍一下Big SQL。
首先我们需要回答的问题是为什么要在Hadoop平台上支持SQL查询?原因有二。
首先Hadoop平台是以满足各种形式的数据来设计的。因此它在结构上非常灵活。在最底层Hadoop是以API为基础的。也就是说在Hadoop上查询需要非常强的编程能力,入门难度很高。同时,即使最简单的查询操作实现起来也很繁琐。但是现在大多数数据还是以结构数据为主。那么我们为什么不发挥SQL的长处?大家非常熟悉的结构,很丰富的工具生态圈以及无须担心数据是如何获取的。
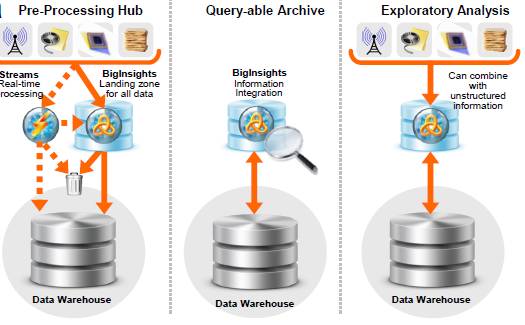
这张图展现的是SQL-on-Hadoop的三种应用,分别是预处理数据,归档查询,以及原因分析。
SQL-on-Hadoop的第二个原因是Map-reduce(MR)等一些技术的局限性。比如说MR对于大规模并且容错的查询处理可能更加适合但是对于需要在几秒甚至几毫秒的互动式查询,恐怕MR就不是很理想了。
业界针对SQL-on-Hadoop有不同的实现形式。第一种是Submit a remote query,这里主要是以Teradata、Oracle、Microsoft为代表。RDBMS向Hadoop发送请求,Hadoop处理完查询并将结果集返回给RDBMS。第二种是以在Hadoop上实现完整的RDBMS。这个主要包含存储层以及查询引擎,并且使用专门的metadata。这种实现方法的代表公司主要有Pivotal和Vertica。最后一种是只提供查询引擎,这个代表公司主要是IBM。
我们首先大体了解一下Big SQL。
Big SQL是一个针对我们前边提及的BigInsights数据,符合业界标准的SQL查询界面。这个以Hadoop为支撑的查询引擎包含了数十年IBM在关系型数据库中的研究成果,比如说并行数据库(database parallelism)以及查询优化(query optimization)。
我们先看一下Big SQL基础架构。

中间长方形的是coordinating node, 用户通过JDBC和ODBC客户端连接至这个节点上,同时这个节点也负责SQL查询语句的compile以及优化,并且生成平行的查询执行计划。一个runtime引擎会将这个执行计划分配给下面一排的worker node并通过他们得到查询结果集。
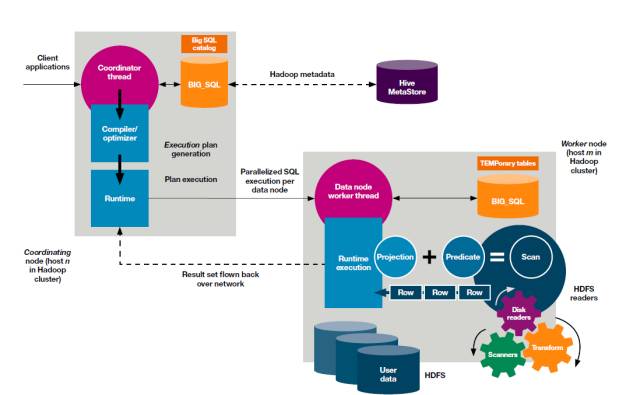
上面这张图描绘的是Big SQL语句执行阶段。当一个worker node接收到一个查询计划时,它会启动进程来读取HDFS上面的数据。同时这些进程会将读取的数据处理成Big SQL接受的格式。这里进行数据处理的目的是可以让Big SQL立刻将已处理好的数据读取到引擎内存进行处理。
下面我们再聊一下Big SQL的一些值得注意的功能。

Big SQL提供丰富标准的SQL支持,提供对不同存储形式的支持。常见的有文本, 序列,RCFile,ORC等。这些数据形式与DFS, Hive, HBase保持一致。举个例子,Big SQL应用Hive的database catalog来获取表定义,位置,储存格式以及输入文件的编码。这就意味着Big SQL不仅仅只能用于通过Big SQL创建的表以及LOAD进来的数据。只要数据定义在Hive Metastore并且可以通过Hadoop cluster获取到,Big SQL就可以对它支持。
最后,Big SQL支持对传统关系型数据库的联邦查询。和DB2相似,用户可以通过Big SQL对不同的远程数据源进行联合查询。
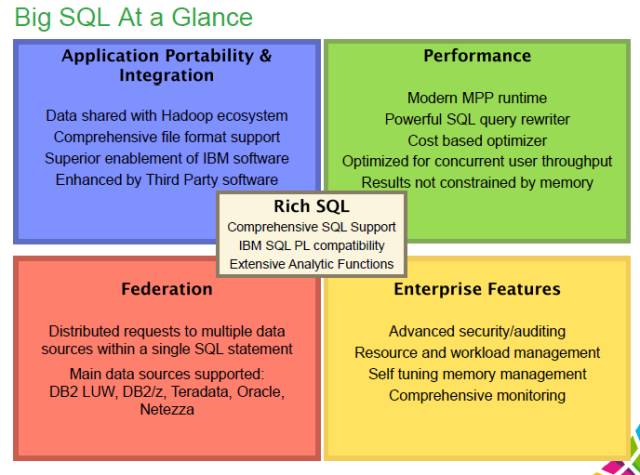
上面这张图简单归纳了一下Big SQL的功能。鉴于时间有限,仅对IBM BigInsights for Apache Hadoop以及Big SQL模块进行基础的介绍。如果有兴趣,大家可以通过下面的链接对IBM BigInsights和Big SQL产品进一步了解。
<进一步了解Big SQL, BigInsights产品架构以及底层技术> http://www.ibm.com/developerworks/data/library/techarticle/dm-1110biginsightsintro/index.html
再次感谢IBM软件工程师胡泽远老师,对DBA+社群活动给予的大力支持!
“DBA+社群”将陆续在各大城市群进行线上专题分享活动,以后每周一、周三晚上为【DBA+专业群】的固定时间,每周二、周四晚上为【DBA+各城市群】的固定时间,每周五晚上为【DAMS架构师精英群】的固定时间,欢迎大家积极加入我们。无论是内容还是形式,有好的建议我们都会积极采纳。
想入群的小伙伴们请关注DBA+社群微信公众号:dbaplus,回复“加群”即可。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复002,看吕海波的《去不去O,谁说了算?》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看周俊《被埋没的SQL优化利器——Oracle SQL monitor》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看郑晓辉《存储和数据库不得不说的故事》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看黎君原《扒一扒Oracle数据库迁移中的各种坑》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721