
本文根据DBAplus社群第89期线上分享整理而成。
张真
宜信技术研发中心高级架构师
目前负责金融基础服务、微服务架构演进/计算平台、DevOps平台等。
曾任IBM,负责云计算、应用服务器等,拥有多个国际专利。开源社区活跃贡献者。
主题简介:
服务流及微服务架构下服务流构建的挑战
自动化构建(微)服务流
自动化构建服务流的应用场景
先谈谈这个话题的早期背景,作为一个发展了十年的企业,我们公司内部存在大量的系统,这些系统可能包括多种架构,多种技术栈,它们互相关联,互相作用成就了复杂的业务体系。随着业务演变,人员更迭,系统演进等诸多因素的叠加,公司级系统的关联关系与状态逐步变得难以精确梳理,难以精细维护。
基于这样的痛点,便产生了这个话题的思考:能否使用技术手段自动地、精确地、具现化地勾勒公司级的应用/服务关联图谱?
1服务流以及微服务架构下面临的挑战
描述关联关系会让人联想到一个词“拓扑”。拓扑是源于数学的一门方法论,它是研究与大小,形状无关的点、线关系的方法。在计算机领域,拓扑是一组计算机相关的抽象点,以及点之间联线构成的图形。
大家最熟悉的是网络拓扑,它是把计算机和通信设备抽象为一个点,把传输介质抽象为一条线,由点和线组成的几何图形,是对物理网络环境的描述。网络拓扑的核心标识是IP地址,所以每个点就是一个IP地址的抽象,而点与点之间的连线代表网线,光纤或无线连接。这个图形描绘了物理网络的静态结构。
网络拓扑举例:
(注:图源自网络)
在APM(应用性能管理)领域,提供了应用拓扑。它是将终端(用户),中间件(包含应用),数据库等抽象成点,用有向的连线来描述访问关系(数据交流传输的路径)。它强调端到端的流程绘制。
应用拓扑举例:
(注:图源自网络)
说说今天的话题,什么是服务流?它与前面二者的区别与联系是什么?
服务流(Service Exchanging Topology)是描述服务与服务的静态拓扑和运行时特性的图谱。之所以称为服务“流”,是强调它更加动态,它涵盖应用拓扑的内容,比应用拓扑提供更加深入的抽象粒度,也提供更加丰富的运行时状态。同时它不强调应用的概念,但兼容不同架构下的应用概念。
在说明服务流如何抽象节点之前,先简单梳理一下服务,应用以及进程的概念:
进程:提供运行资源的载体,这些资源包括CPU,内存,网络,IO等。
应用:符合某种IT工业标准的,可独立部署的单元,比如JEE应用通常包括WAR包,EAR包,EBA包等。
服务:提供某种处理或计算能力的代码集合。
通常我们会面对3种架构:单体架构,SOA架构和微服务架构。
单体架构并不强调服务的概念,所以可能有服务,也可能无服务,而同一个进程中可能包含多个应用,比如Tomcat启动后,是一个进程,允许部署多个应用。如下图:
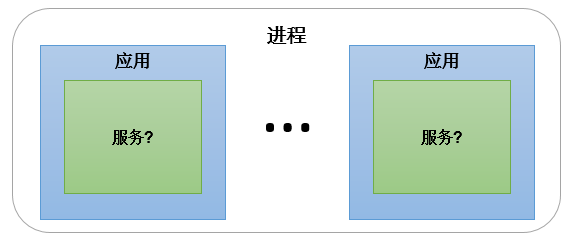
单体架构中三者的关系
从SOA开始,服务开始作为应用的必须单元,一个应用中可能包含多个服务。同时随着服务思想的发展,进程被建议部署单个应用(当然多应用也被允许),服务之间通过服务总线进行交互。如下图:
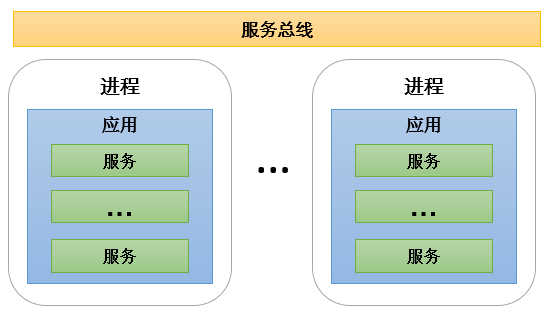
SOA架构中三者的关系
微服务架构进一步强化服务的概念,要求服务成为可独立部署的单元,所以从部署形态上出现了两种基本模式:
一进程一应用一服务,例如一个tomcat里面部署一个war应用,这个应用只包含一个服务
一进程无应用一服务,例如SpringBoot取代了传统的war部署,直接实现服务部署。
同时微服务之间基于服务发现进行直连交互,而对外部交互通过服务网关进行。如下图:
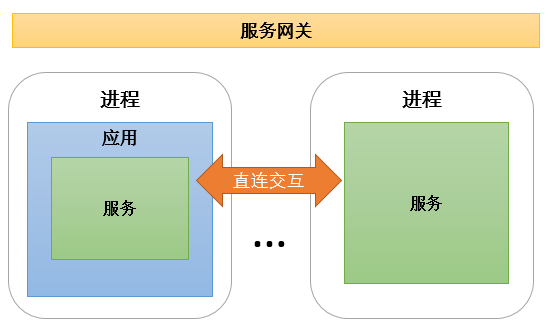
微服务架构中三者的关系
接下来,阐述一下服务流提出的静态拓扑和运行时特性的含义。
1、静态拓扑:是描绘服务本体,服务之间的关联。
服务本体是对以下四种类型服务的抽象:
业务服务:就是业务代码集合,提供业务逻辑和流程,是服务流主要的抽象存在。
数据源服务:提供数据存储和查询,比如关系型数据库MySQL,缓存Redis,非关系型数据库MongoDB等。
代理服务:提供访问代理,比如服务网关,Nginx,Haproxy等。
消息传输服务:提供同步或异步消息通道,比如RabbitMQ,Kafka等。
分类的标准是按照服务之间的关联特性来确定的:
业务服务可以是输入入口(有向连线的终点),也可以是输出出口(有向连线的起点)。
数据源服务只能是输入入口。
代理服务尽管不处理任何逻辑,但可以是输入入口,也可以是输出出口。
消息传输服务只能是输入入口,但值得注意的是它的入口类型(客户端)包括两种:消息生产者和消息消费者,这是需要区别开的。
2、运行时特性: 主要是描述服务过程以及调用过程的一系列监控指标。
服务过程指标:被访问地址,操作方法,请求/响应内容,响应时间,吞吐量,错误数,访问时间戳等。
调用过程指标:调用地址,操作方法,请求/响应内容,异常/错误数,响应时间,调用量,调用时间戳,调用服务的特征(服务类型,是否集群,版本,用户/权限)等。
之所以能够提供更深入的粒度是因为服务流使用了服务画像数据和客户端画像数据,第二部分会详述。所以从领域来看服务流、应用拓扑、网络拓扑又分别对应服务监控、APM、机房监控这三个领域(如下图):
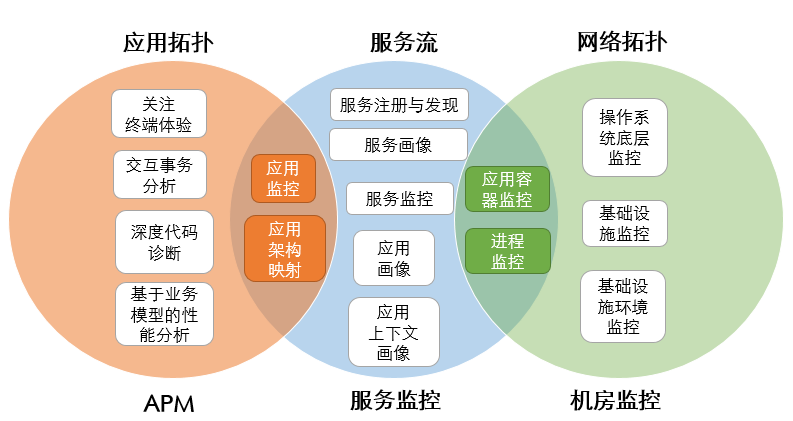
在微服务架构下,服务流的绘制存在如下挑战:
1) 微服务架构在实现服务独立部署的同时,也带来服务节点规模的大幅增长,导致关联关系更加复杂。依靠人工收集变得难以落地;如果依赖Zookeeper,etcd等建立服务注册中心,虽然可以收集到服务本体的一些信息,但没有服务的关联信息,且如何更新维护依然是问题。
2) 服务更加多样化,变更更频繁,且不同步。由于服务会被拆分得很细腻(有助于更加灵活的编排和独立运维),所以服务的种类自然增长,且由于可能是不同团队维护这些服务,服务的上线,变更等运维过程变得极大的不同步。
3) 微服务的部署形态有多样性。例如传统JEE应用是由应用服务器提供一个端口接收访问(一进程一应用一服务);而新的部署形态可能由服务对外提供一个或多个端口接收访问(一进程无应用一服务),如果是多个端口时,可以把这个服务看出一个聚合服务也可以将每个端口抽象成一个服务,从服务流的角度这种服务抽象需要具备聚合和分散的特性。
4) 在一个复杂生产环境下,还要考虑与单体架构,SOA架构的兼容问题。例如单体架构下需要识别“服务组件”或被抽象成一个“大服务”;SOA下同一应用下可能存在多个服务,也需要被识别出来,并被分别抽象。
2自动化构建(微)服务流
对于服务流的构建,我们仍然采用了微智能的思想,希望服务流的构建过程形成完全反馈闭环。
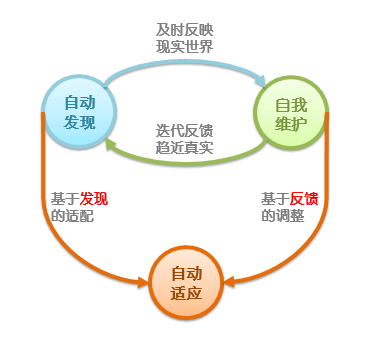
微智能设计思想的三观
关于微智能设计思想的详述,请参考DBAplus社群的《微服务架构下,如何打造别具一格的服务治理体验?》。
首先,构建服务流主要依赖两种数据:
1) 服务画像
是描述服务本体的信息,包括应用唯一标识(AppID)(兼容单体架构,SOA架构),服务名(Service ID),服务实例的URI,服务接口的URI,服务接口的元数据(类,方法,入参出参,注解,部署描述符)。
服务端的抽象就是服务本体,但关联线的对象是服务接口,如果服务本体包含n(n>0)个服务接口,则关联线类型就有n种,关联线条数=S[1]+S[2]+S[3]+...+S[n](S[k]代表某个服务接口的实际关联线个数,S[k]>=0,1<=k<=n)
2) 客户端画像
是描述调用服务行为的信息,是服务关联抽象的基础。包括应用唯一标识(AppID)(兼容单体架构、SOA架构),所在服务名(Service ID),访问的URI,操作的元数据(操作,方法,入参出参)。
从抽象的角度,客户端抽象是以访问的URI(关联线)为区分的:
同类型的客户端有多个实例,都访问同一个服务URI,是一个客户端抽象
同类型的客户端有多个实例,访问n(n>1)个不同的服务URI,则应有n个客户端抽象
不同类型的客户端有若干实例,都访问同一个服务URI,是一个客户端抽象
不同类型的客户端有若干实例,访问n(n>1)个不同的服务URI,则应有n个客户端抽象
那么实践微智能思想,自动化构建服务流,采用以下技术来捕获这两种数据:
1)中间件劫持技术
这里的中间件是一个广泛的服务运行时的代称,它可能是应用服务器(例如Tomcat),类应用服务器运行时(例如SpringBoot)等。采用劫持技术的目的是希望无侵入的实现服务画像,这里的无侵入是无需研发团队去做代码埋点,也无需在服务代码层面增加任何依赖(比如jar包)。
服务画像的操作是发生在应用/服务启动的阶段,根据工业标准做类扫描和部署描述文件分析提取画像数据。由于每次启动,都会触发画像,所以画像数据一直保持最新的实际状态。
2)客户端劫持技术
客户端劫持是根据客户端实现,清楚分析客户端的编程模型,然后通过编程模型配合客户端实现源代码,定位需要埋入劫持代码的位置。从实现上它是以中间件劫持为基础的,所以也是无侵入的,是对其进行扩展从而实现客户端画像。
客户端画像的操作是发生在调用实际发生的阶段,并不像服务画像可以在启动阶段一次捕获,所以客户端画像的过程是逐步积累的,最终达到完整勾勒。如果服务重启后,客户端画像会重新开始这个过程,同样也保持最新的实际状态。
其次,在实际构建时,还需要一种辅助数据,以达到更准确的拟合效果,这就是溯源数据。
溯源数据是从访问协议中提取的特征数据,用来追溯访问源头以及访问可能经过的路径。
访问协议可能是工业标准协议(http,rmi,soap,smtp等),也可能是自定义协议。一般来说协议载体都分为header和body两个部分,这里主要谈谈header,header存放协议必须的元数据。我们需要从这些元数据中找到可以用来描述访问源的线索。
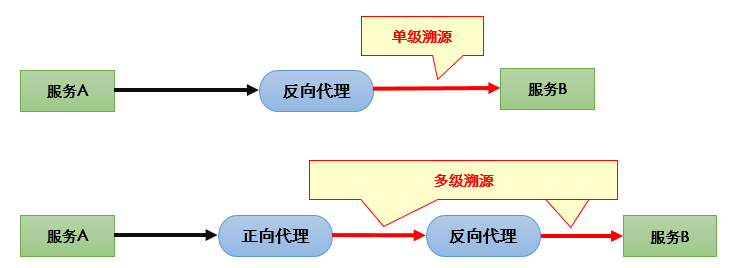
典型场景是两个服务之间可能通过正向或反向代理进行访问,仅仅依靠服务画像和客户端画像是无法真正关联这两个服务(如下图):
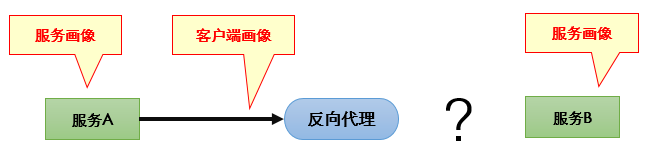
那么通过提取各个代理的IP(溯源数据),就能掌握请求的通过路径,进而关联两个服务(如下图)。
接下来,在获取服务流相关的基础数据后需要进行一个拟合过程。
首先,建立每个服务抽象的IPO模型,IPO是指Input(输入),Process(处理),Output(输出)。
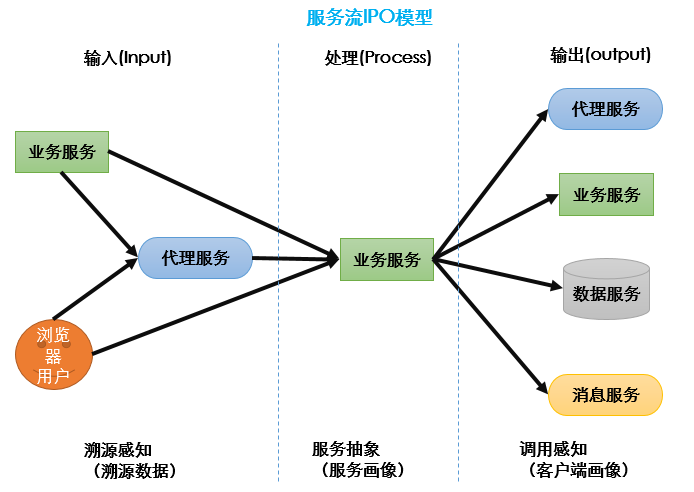
输入是使用溯源数据实现溯源感知。这里补充了浏览器用户这个抽象节点,模型展示了四种基本形态:业务服务直连,业务服务通过代理服务,浏览器用户直连,浏览器用户通过代理服务。
输出是使用客户端画像实现调用感知。模型展现了四种调用目标:代理服务,业务服务,数据服务,消息服务(注意:消息消费者实际也是客户端,从关联角度,并不作为输入)。
处理是使用服务画像实现服务抽象。
接着,当每个服务抽象的IPO模型建立后,就可以进行拟合。拟合的基本算法是离散点的有向图匹配(广度优先better)。在实际生产中,我们还进行了一些优化,因为实际情况复杂得多,而且算法复杂度在万级节点时会有各种瓶颈:
增加了未知服务(可能是第三方系统),未知服务只能出现在溯源感知和调用感知中,它没有IPO模型
已知节点优先原则,它有完整的IPO模型,它的调用和溯源是必然存在的,避免重绘
优先调用关联,后处理溯源关联。调用关联包含其他已知节点(可自动延续绘制),终结点(各种数据源,MQ,无调用无溯源),未知节点(无溯源,可能有调用)
下面以TOMCAT+JEE服务为例,剖析关键实现 。
Java技术栈实现代码劫持是依赖两种常见的AOP技术(Java三板斧之一)。
字节码编程:不同jdk版本可能存在兼容性问题,谨慎使用。推荐javassit,如果需要支持多版本jdk,需要考虑根据不同版本动态加载兼容的javassit。我们是在劫持入口类的方法上使用,在之前或之后增加代码,尽量避免修改代码(减少出错,通用性更强)。
Java原生代理:无接口不代理。多多益善,性能影响小,无兼容问题。
为了获取服务画像和溯源数据,先对Tomcat进行中间件劫持。劫持核心是掌控Tomcat ClassLoader Tree,获得优先加载权,从而可以改变这些行为。尽管各种JEE应用服务器实现不同,但其ClassLoader Tree结构基本类似。通过植入一个ClassLoader来获取优先加载权。通过加载改写后的class,来改变行为。我们把这个ClassLoader称为UAVClassLoader(无人机类加载器):
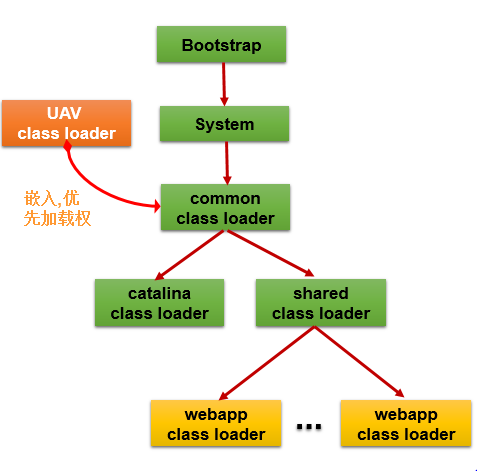
UAVClassLoader算法基本原理
1) UAVClassLoader创建时,将能够读取到的Class文件对应的Class名存储到ClassMap中。
2)将TomcatLoader设置为UAVClassLoader的Parent。
3)将UAVClassLoader设置为TomcatLoader的一个属性。
4)重写TomcatLoader的loadClass方法。
如果UseUAVClassLoaderFlag为true,则使用UAVClassLoader.loadClass;
加载成功则返回Class;
失败则使用TomcatLoader自己的loadClass;
5)UAVClassLoader的LoadClass方法。
如果ClassMap中含有要加载的Class,则使用自己的findClass加载Class
否则,将UseUAVClassLoaderFlag设置为false;
使用TomcatLoader.loadClass(注:这时TomcatLoader会直接用自己的loadClass);
将UsePlusLoader Flag设置为true。
服务画像收集
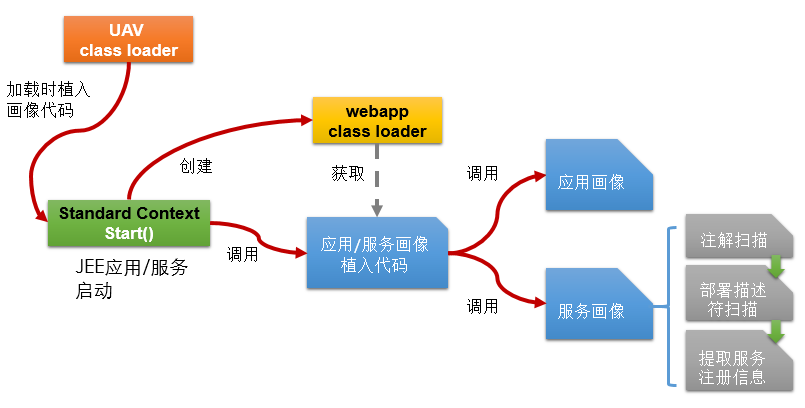
JEE服务启动实际是Web容器的创建过程。在Tomcat中的StandardContext就是Web容器的根类,在其加载的时候,UAVClassLoader会感知,通过改写或字节码手段在其start方法的最后植入代码,完成两个步骤:
1)收集将Web容器的上文信息:包括WebAppClassLoader实例,Context Path,应用名,ServletContext,BasePath(应用实际路径),WorkDir(应用工作目录)等
2)植入应用、服务画像的代码。服务画像是按照技术规范,常见的技术规范:Servlet,JAXWS,JAXRS,Spring,RMI,RPC(Netty,Thrift,Hessian等)。针对每种技术规范从3个方面进行收集:
Class和Method:通过Java的反射方式提取信息,如服务类名,方法名,入参出参。
Annotation:通过注解扫描工具提取具有相关注解的类,然后通过注解API提取注解信息。
部署描述符:通过WebAppClassLoader获取web.xml, spring-config.xml, log4j.xml等部署描述符文件路径,然后使用DOM解析提取关注的tag信息。
溯源数据收集
溯源数据的捕获实际与服务监控数据捕获发生在同一个阶段。运用中间件劫持技术改写Tomcat的CoyoteAdaptor.service()方法,它负责整个Tomcat的请求处理,在方法开头拦截请求,方法结尾拦截响应。这里获取应用服务器,应用,所有的URL的性能指标;同样,运用中间件劫持技术改写Tomcat的StandardWrapper.service()方法,它负责Servlet的请求处理,同上如法炮制,在这里捕获溯源数据即可,同时也获取服务的性能指标。
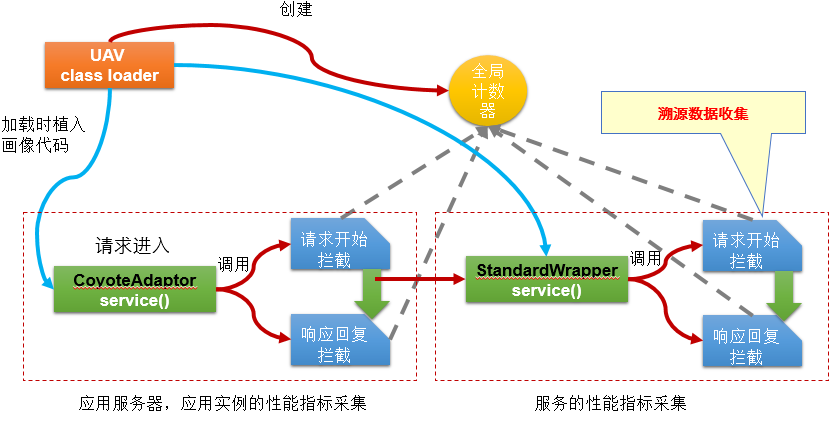
Tomcat是以HTTP协议为基础的。HTTP协议的Header中的字段可以帮助溯源:
Client Address:直连客户端IP地址
X-Forwarded-For: 如果存在,则为代理路由地址链,则直连客户端为代理服务
Host:表明远程主机甚至端口信息,如果直连客户端是代理服务,则Host为代理IP地址和端口
User-Agent:代理描述,可用来区分浏览器还是程序客户端,当然还可以提取很多浏览器终端信息。
同时,还可以提取一些自定义的Header信息帮助拟合,这需要结合客户端劫持,下文会进行说明。
客户端画像收集
首先要标准化客户端画像的元数据体系。调用感知是基于调用地址,访问协议,调用结果的特征提取来确定目标服务的。
1)调用地址:以类URI格式。
http/https服务(业务/代理服务): http://
关系型数据库(数据源服务): jdbc:<数据库类型>://
非关系型数据库或缓存(数据源服务):<数据源类型>://
消息队列(消息服务):mq:<消息中间件类型>://
2)访问协议:某种访问动作。例如HTTP的POST,SQL插入,发送/订阅消息,Redis的hgethashall,MongoDB的Collection操作等。
3)访问结果特征:服务的基础栈类型,是否集群,例如nginx,tomcat,apache等。
接下来,就是通过客户端劫持,以常用的http客户端Apache HttpClient为例,只需两步:
识别org.apache.http.impl.client.InternalHttpClient是Apache同步客户端的核心类
运用字节码改写其doExecute方法,在方法的开头和结尾插入画像代码获取调用感知的特征信息
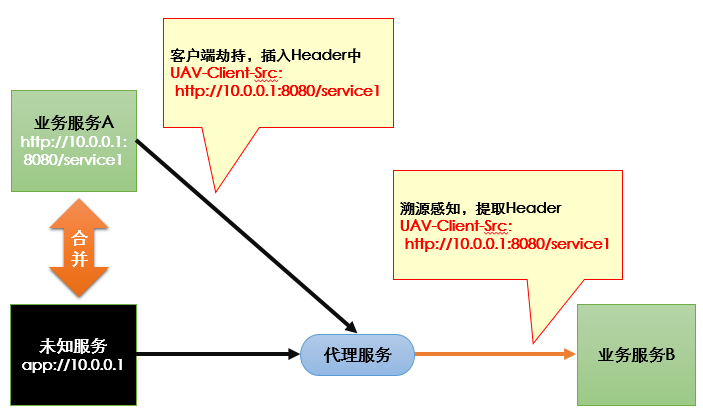
前文还提到为了帮助溯源感知,可以在上游服务的客户端,通过客户端劫持在访问协议的Header中加入自定义的一些信息。
例如为了在拟合时,合并两个通过HTTP代理服务关联的服务,在上游服务客户端调用时,可以添加一个Header字段(比如:UAV-Client-Src),这个字段存放服务抽象的唯一标识;当下游服务提取溯源数据时,可以将该字段取出,作为源头服务的唯一标识,这样就能完成合并。
3服务流的应用场景
场景一:具现化的应用/服务运维
我们的服务监控系统叫无人机,代号UAV。UAV定义了服务流的三种视图:
1)应用/服务级:如果是单体架构或SOA架构,就是应用集群;如果是微服务架构,就是服务集群。集群内每个进程就是一个应用/服务实例。
2)应用/服务组级:这是个逻辑概念,可以根据产品线或业务架构来确定。它由多个不同类型的应用/服务集群组成。
3)全网级:就是整个IDC中心所有应用/服务集群。
在IPO模型基础上定义视图的表现层(如下图):
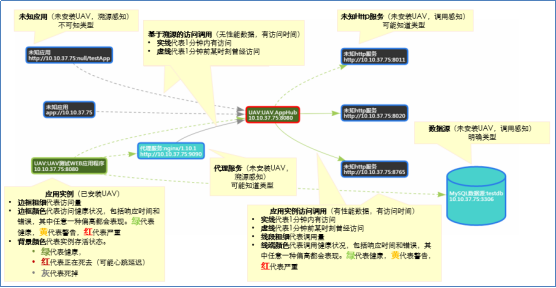
下面是实际系统截图:
应用/服务级视图(App /Service Cluster)
应用/服务组级视图(App/Service Business Group)
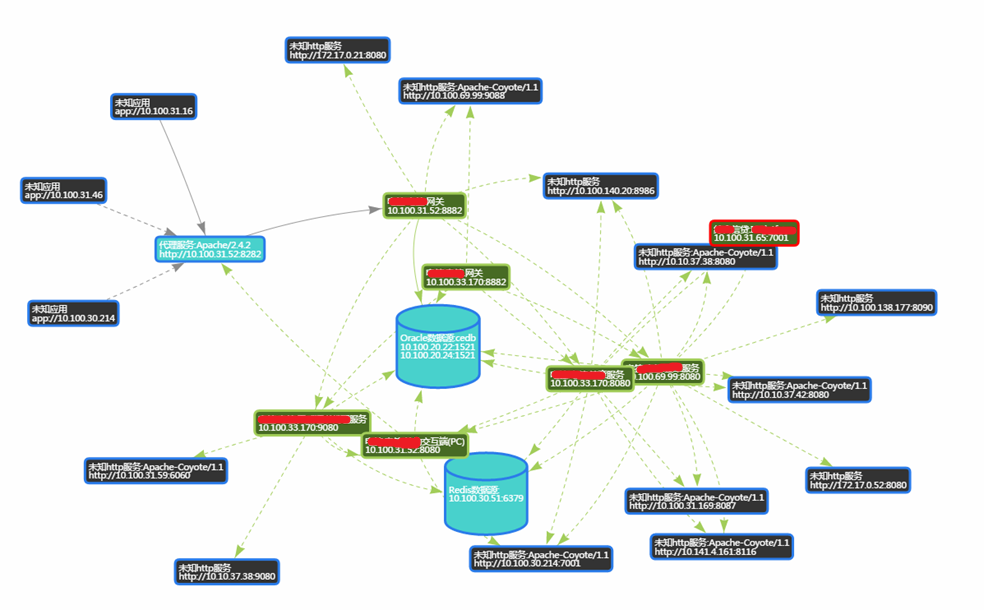
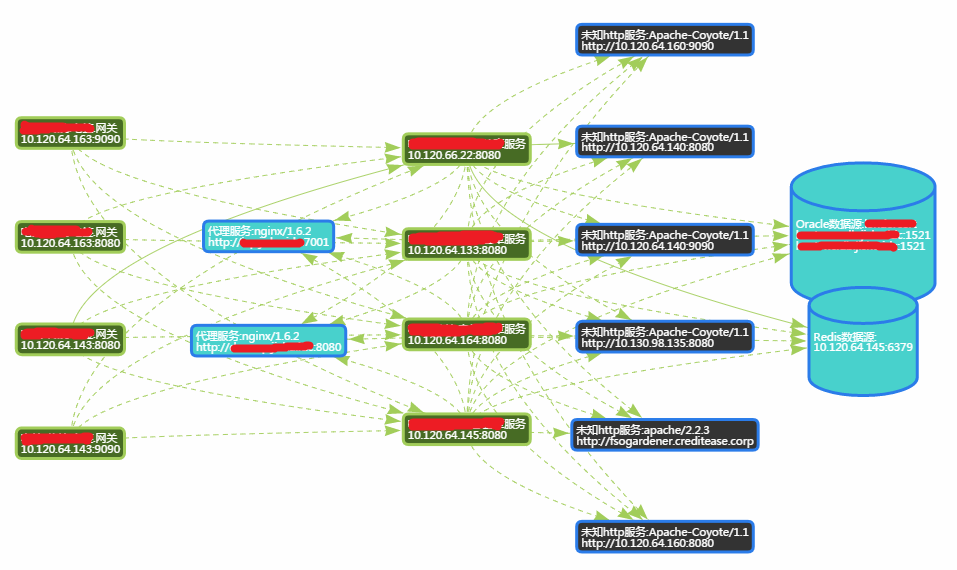
全网服务流视图(Global Service Business Topology)
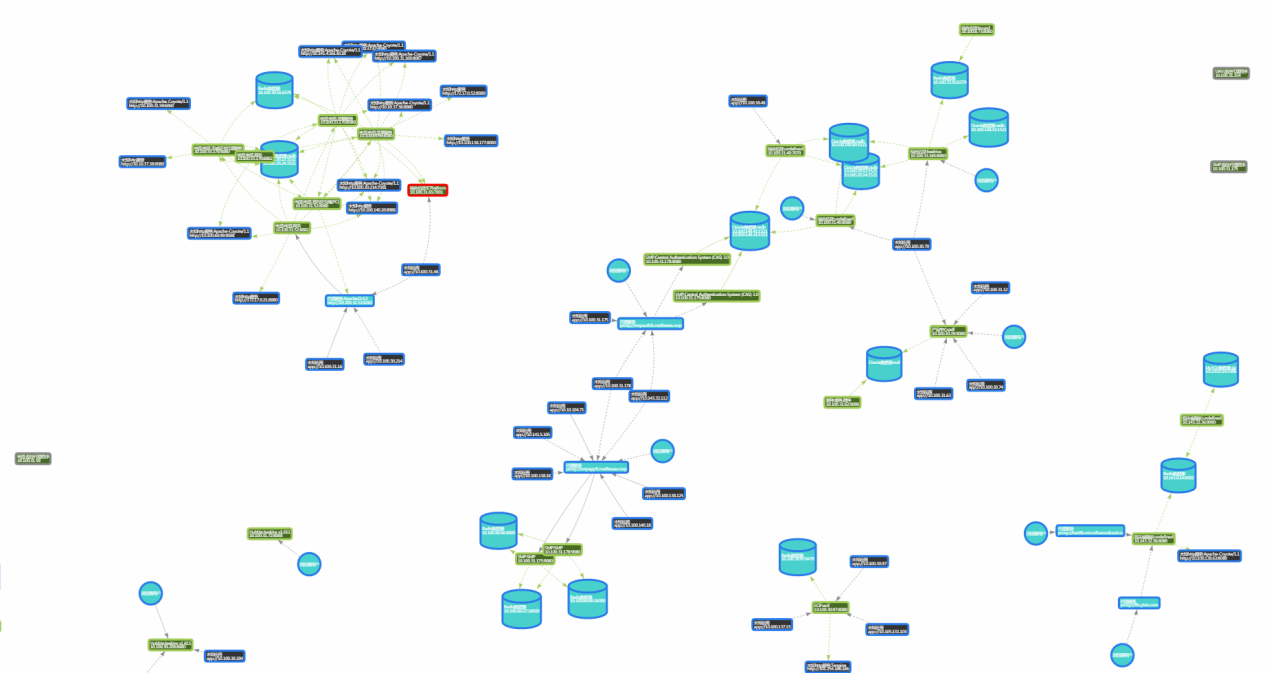
全网视图又叫服务星云,因为上图是缩放后的效果,全网可能如下图:
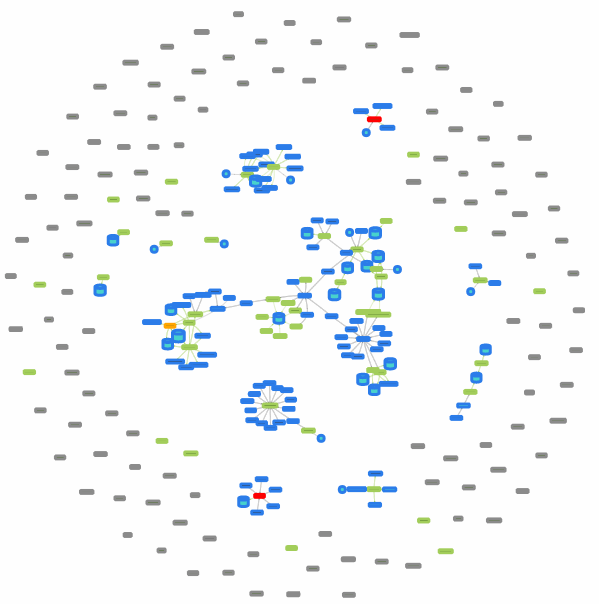
或者:
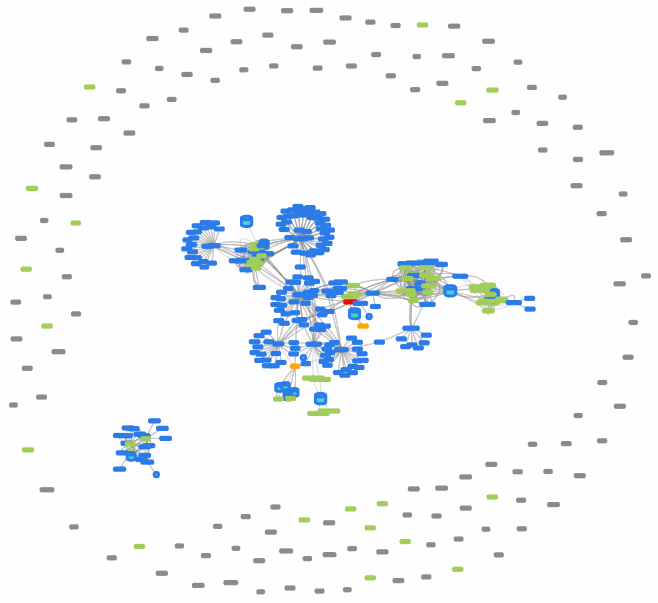
场景二:服务风控与关联分析
这是利用服务的关联,在一个完整业务链路(由一系列的服务组成),当某些服务出现问题(比如很慢)时,可以通过关联分析快速定位问题源并自动的采取某些措施,常用的措施:实时的,自动化及时管控/熔断等;预测整体业务链路风险,提前可控切换或其他预案措施。
场景三:自动化调用链生成
调用链一直是服务治理的热门话题。经典的做法是在业务代码中进行埋点。通过自动化构建服务流之后,可以大量减少埋点工作。通过一个比喻来说明为什么可以达到这样的效果,可以把服务流看成城市间的道路,每个请求的流动可以看成道路上的车辆,当道路已经很清楚的被描绘出来后,每辆车就可以被更自动的追踪了。
基本思路:
1) 通过中间件劫持,在服务画像的位置,产生或继承请求ID;
2) 通过客户端劫持,在客户端画像的位置,产生或继承请求ID;
3) 在单线程模式下,自动传递请求ID;
4) 在跨线程模式下,交换请求ID,此处是唯一需要少量的代码埋点的场景。
由于篇幅的关系,对于场景二,三没有展开说明,希望未来可以和大家分享。
4总结
最后,总结一下。服务流是应用拓扑的扩展,可以更加深入细致的描绘服务的关联关系。可以通过中间件劫持,客户端劫持,溯源数据提取等手段实现服务抽象的拟合,进而自动化的构建服务流。具体落地需要根据实际使用的技术栈来考虑,本文列举了Tomcat+JEE应用的场景下的一种实现方法供大家参考。另外,服务流可以被应用到很多生产场景中去,例如服务监控,服务风控,自动化调用链等。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721