
作者介绍
朱祥磊,山东移动BOSS系统架构师,负责业务支撑系统架构规划和建设。获国家级创新奖1项、通信行业级科技进步奖2项、移动集团级业务服务创新奖3项,申请发明专利13项。
一、项目背景
为了更好的保障业务系统运行,提高服务质量,我们先后建立了高可用保障手段、应急容灾系统等保护机制,但仍存在如下矛盾,并越来越突出:
投资大,效益慢:如今年某系统扩容需要约XXXX万TPCC,XXXT存储设备,需要同步对容灾系统扩容。
灾备端平时无法打开:灾备端的资源(尤其是存储)平时无法打开使用,造成资源浪费严重。
切换时间长:一般需要1-2小时以上才能起来。
故障情况下切换决策难:有时切换时间+决策时间>=灾难修复时间,难以决策,期间无法办理业务。
难以找到RTO、RPO都为0的0切换方案。
流程复杂,维护难:系统切换需要一系列管理和技术流程,维护复杂,生产、容灾端都需要维护。
无法做到在线的系统升级迁移和新业务上线。
这种情况下,我们急需探索在核心系统中引入容灾系统双活零切换技术,基于如下考虑:
可以从降低运行风险、提高客户满意度等方面提升业务运营水平。
可以从降低业务停机窗口、降低维护工作量等方面降低系统运维压力。
可以降低系统灾难处理压力、最大限度降低业务中断时间,从而提高客户满意度。
使容灾侧资源平时可用,达到双活。
降低演练测试的业务停顿窗口,提升演练质量。
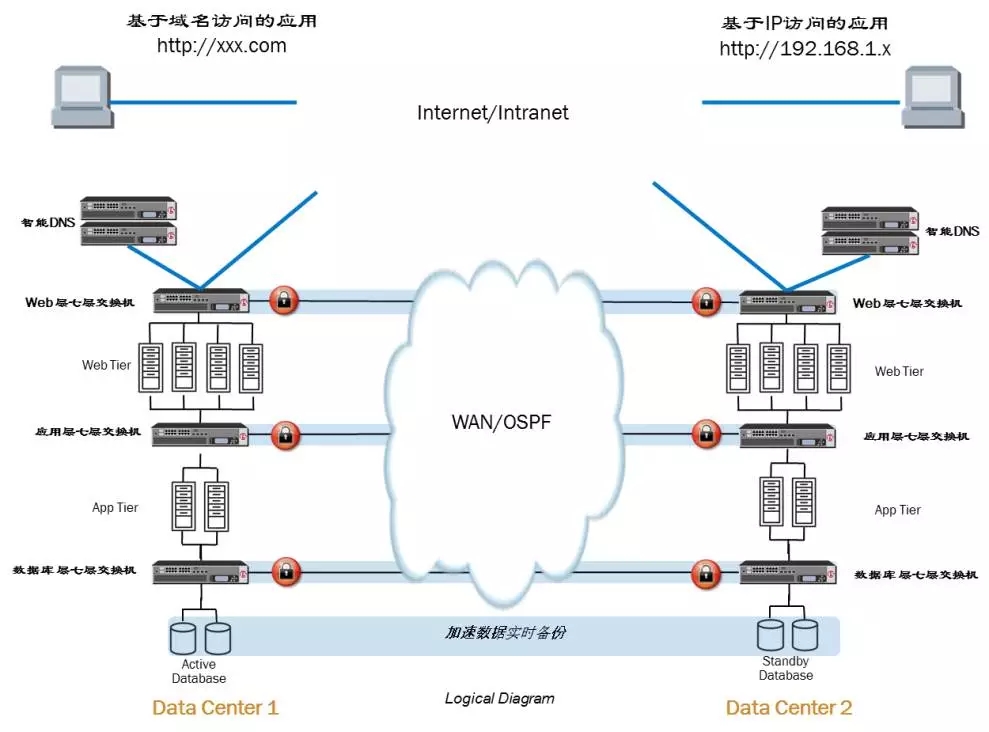
从系统架构上看,容灾方案主要存在如下三种形式:主备模式、双中心互备模式、双活并行模式,而目前各省采用的前两种形式,RTO均不为0,容灾端平时不可用,需要技术、流程保证切换,而双活并行模式,理论上在灾难发生时不影响业务,可以做到”0”切换。
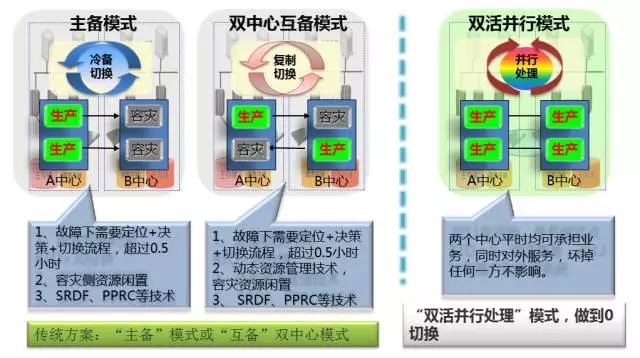
主备模式:在一个中心部署生产系统,另一个中心部署备份容灾系统,通过存储复制或逻辑复制手机实现保护,实现冷备切换,这种情况一般采取存储底层的srdf、pprc复制技术,平时容灾端资源不成在对外应用,数据库不能打开,再出现故障时需要执行定位、切换决策并执行切换流程,故障恢复时间指标RTO至少在半小时,故障恢复点指标RTO可以根据采用的技术不同等于0或接近0。
双中心互备模式:在两个中心机房各自部署一部分应用,既部署生产又部署容灾,互为容灾备份机制,具体每个系统实现机制同主备模式,可以说是主备模式的扩展,是为了解决容灾端资源闲置的临时性方案,生产和容灾同步技术和主备完全相同,计算资源可以通过虚拟化技术实现生产和容灾共享来节约资源,RTO、RPO指标同主备模式。
双活并行模式:一种全新的容灾模式,相同系统在两个中心均能打开使用,承载对外服务,任何一边坏掉不影响业务,灾难情况下可以不需要决策和执行切换,可以实现RTO接近0。
为研究双活架构,2015年根据总部统一部署和规划,多个省份成立联合项目组,结合CRM应急保障体系,试点研究最优的双活技术架构。
方案1:基于数据逻辑复制软件,如dsg、gg、shareplex、触发器等。
方案2:基于数据库自身,如Oracle active Dataguard。
方案3:基于远程卷管理软件(主机虚拟化),如赛门铁克、卷管理、Oracle ASM等。
方案4:基于存储虚拟化设备(SAN虚拟化),如emc vplex,IBM svc,华为vis等。
方案5:基于存储自身(存储虚拟化),如HDS、HP等(刚发布)。
方案6:基于存储HA机制,如IBM powerswap,日立HA等。
二、方案分层介绍
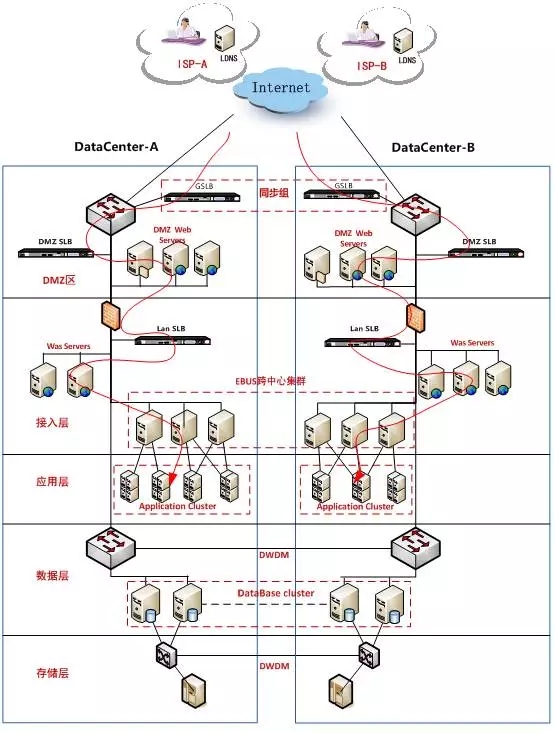
和传统主备方式不同,实现双活需要整个系统架构做改造,即接入层、应用层、数据层、基础架构层等分别考虑:
接入层:需要借助DNS、全局负载均衡等技术实现双活接入和智能路由,流量调配。
应用层:基于互联网化能力开放分布式集群架构,采用ebus服务总线技术对外统一接入。
数据层:需要构建双中心同时可读写的机制,例如Oracle Extend RAC。
基础架构层:网络上对稳定性和带宽吞吐性能要求更高,甚至需要打通跨中心的二层网络。存储方面,则需改变一主一备的读写机制,实现同时可读写。

下面各层进行仔细介绍。
1、双活技术架构
数据库层双活部署目前业界主要有三种方式:A/S(Active-Standby)方式,Oracle RAC集群实(Active-Active)方式和通过第三方数据复制软件方式。
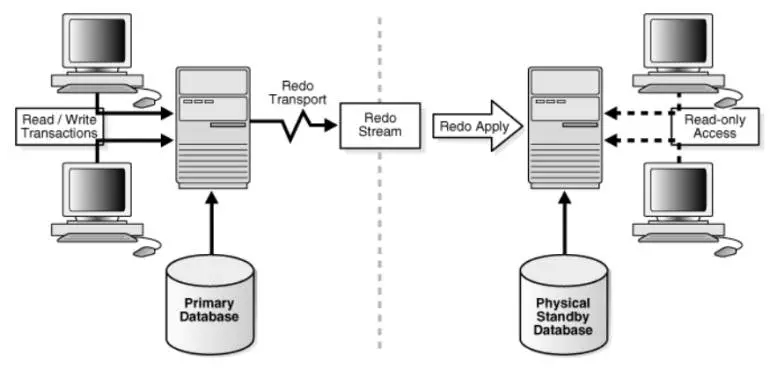
1)Active-Standby方式:基于Oracle ADG技术,采用从主库向备库传输redo日志方式,备库恢复数据过程可以用只读方式打开进行查询操作,实现了部分双活功能,在主节点故障后可以将备节点切为主节点,平实备节点可以提供只读操作。
2)Active-Active方式:通过Oracle Extend RAC实现多个集群节点同时对外提供业务访问。该方式做到故障无缝切换,提升应用系统整体性能。

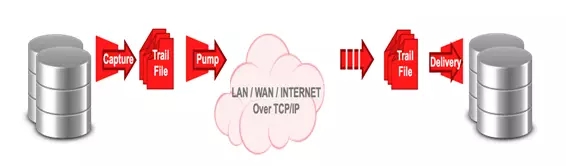
3)数据复制软件方式:通过实时抽取在线日志中的数据变化信息,然后,通过网络将变化信息投递到目标端,最后在目标端还原数据,从而实现源和目标的数据同步。
2、基于数据库-ORACLE ADG
技术特点:
通过网络从生产向容灾传输归档或redo日志,容灾端恢复方式同步数据。
Oracle 11g以后容灾库可打开为只读模式,容灾切换时能快速alter为读写状态。
该方式数据同步效率较高,对硬件资源要求低,支持可以线性扩展而不对生产系统造成影响,且底层存储支持异构,正常情况两边数据延迟不大。

一般启用场景:
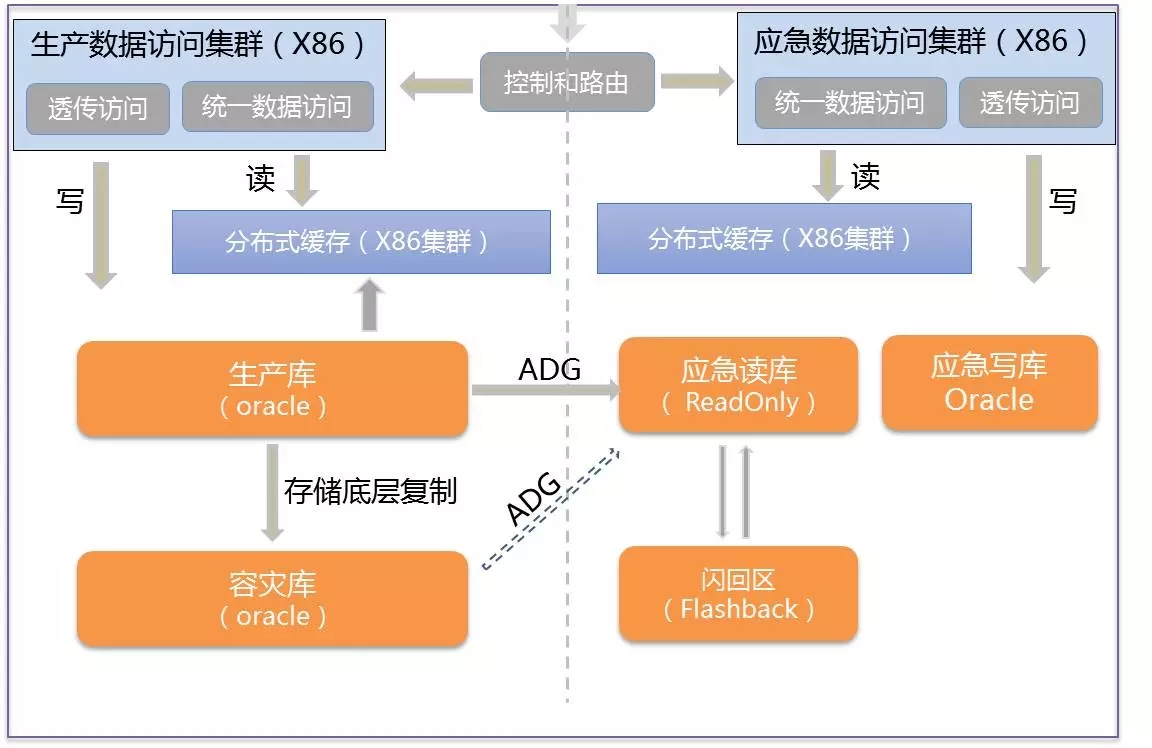
1)作为应急或容灾:只有生产侧可以读写,容灾侧只读,双活读,非双活读写。按照测试,数据库切换时间在30S左右。
2)作为读写分离机制:分摊生产端压力,降低生产负载。
只读查询业务分离(ADG侧平时运行从生产库迁移过来的查询业务)
数据库备份(使用RMAN进行全备和归档备份到带库)
经分数据实时抽取(当前通过BCV抽取非实时数据)
DB变更前数据库快照备份(大版本升级时同步到BCV工作)
承载BCV库功能,可下线BCV库,释放高端存储给生产使用
3)作为数据保护手段:如在ADG库上启用Flash DB特性,需要时可以执行闪回,以恢复误操作等导致的生产库上的数据丢失。
技术特征:
通过dsg、goldengate等逻辑复制技术实现跨中心数据库的相互复制,共同提供对外服务,互为备份。
支持跨异构环境,对系统负载影响很低,对交易型数据做实时抓取、路由、转换和传递
支持多线程,提供旁路顺流模式,不影响生产库性能
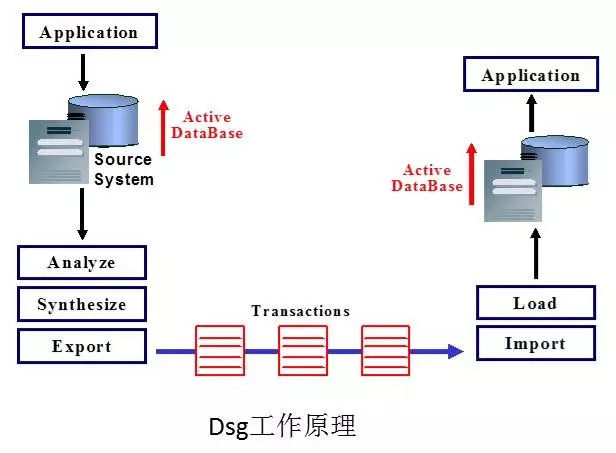
其中:
两个数据中心各建一套数据库,物理独立
基于数据库日志准实时复制数据
ROWID映射表机制(对应源数据库和目标数据库的数据记录),通过ROWID来实现记录的定为,在数据装载效率方面有提升
需手工干预故障
3、对于ADG和数据复制双活方案对比

4、基于Oracle Extended RAC双活架构
技术特征:
Oracle Extended RAC以跨中心共享存储为基础,通过共享存储资源和Oracle Clusterware数据库集群管理,实现各个中心节点对数据库并行访问。
共享存储可以采用存储自身数据复制技术,存储虚拟网关或远程卷管理等技术,下图是采用的Oracle ASM存储管理,实现数据的双向实时复制。
ASM支持对本地磁盘的优先读取,避免跨数据中心的数据读取,从而提高I/O性能并减少网络流量;
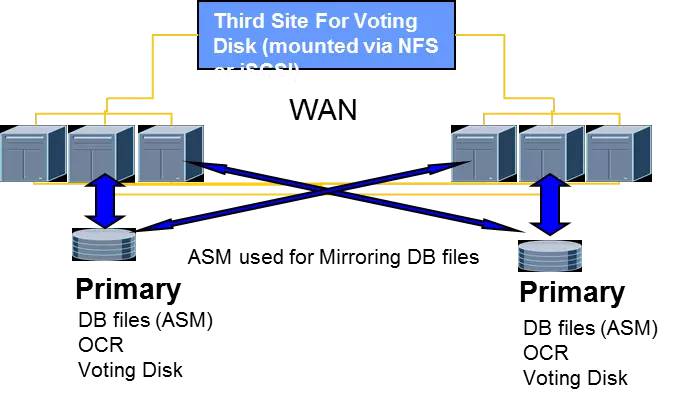
关键实施要点:
两个数据中心分别部署一套存储,各提供一套LUN设备给全部数据库主机。
存储的SAN网络和RAC心跳网络需使用低延迟、高带宽的DWDM光纤链路。
配置ASM磁盘组。每个磁盘组配置两个失效组,每个失效组对应来自一套存储的LUN设备。
在第三个站点部署用于RAC的第3个投票盘,使用NFS的方式挂载到所有数据库主机。
与管理普通的RAC系统类似,需要重点加强对站点间光纤链路情况的监控与应急。
一般启用场景:
由于在两个数据中心部署了两套存储和主机设备,因此能够提供对数据中心级别故障的全方位容灾,比如停电、地震等。
出现故障时恢复时间极短,理论上可以达到RTO和RPO为零。
作为同城容灾的解决方案,并具有最高效的资源使用率。

5、内存数据库双活技术实现
技术特征:
将数据常驻在内存中直接操作的数据库。相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能,目前在BOSS系统内存库已被广泛用于实时计费,主要厂商有Oracle Times Ten,Altibase等。内存库集群部署主要有HA主备模式,双活模式,线性拆分和分布式集群四种模式。
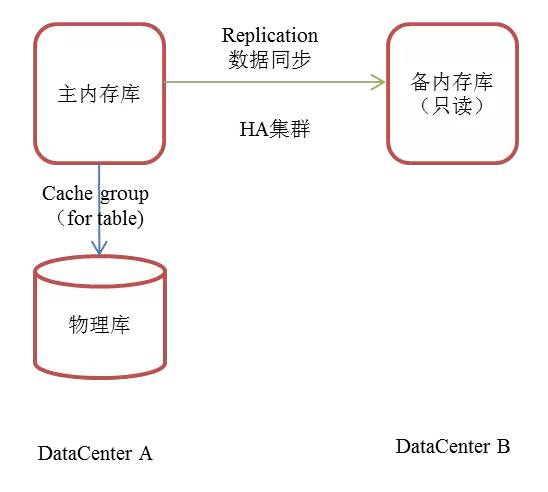
1)HA模式:
在两个数据中心,备库只读,具备故障转移和容灾备份功能。
主备之间日志同步或异步同步,数据同步延迟比较严重。
适合物理库较小,内存容量不大非关键业务场景
扩展性差
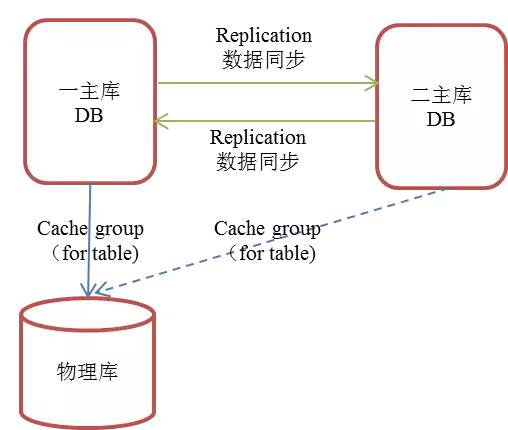
2)双活模式:
两套内存库部署在两个数据中心,支持双读写,具备故障转移和容灾备份功能。
数据库之间基于日志采用同步或异步相互同步,但相互之间数据同步存在冲突问题,造成数据不一致问题。
3)线性拆分模式:
针对物理库较大,受内存容量限制问题,在HA基础上将物理库按地市或业务线性拆分成多套内存库,所有内存库支持同时分片读写,客户端请求都通过前端统一接口路由进行分发和处理。
主备间基于日志同步或异步同步;
系统扩展性较强,但维护难度较大;
支持不同地市或业务双活读写。

4)分布式集群模式:
采用分布式内存库,基于x86分布式集群部署,如:思特奇iDMDB。
主备库基于日志同步或异步同步
支持双活读写(前提数据层和存储层实现双活)
支持分布式自动加载和路由能力
数据自动冗余,RPO=0
支持在线扩展,路由自动调整,便于维护。
开放化,标准化,支持sql92,ODBC,JDBC等
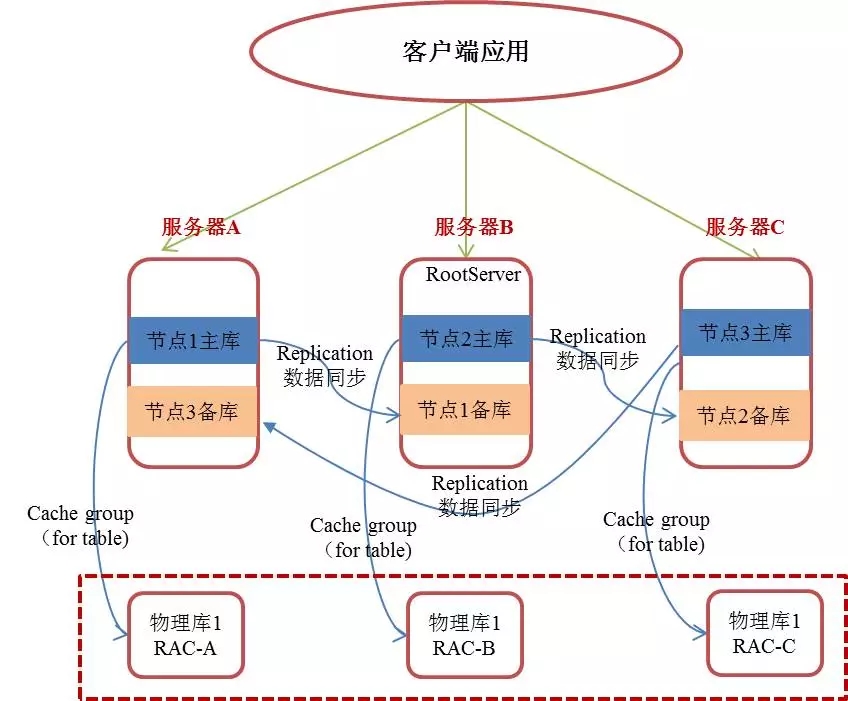
6、双活技术优缺点比较
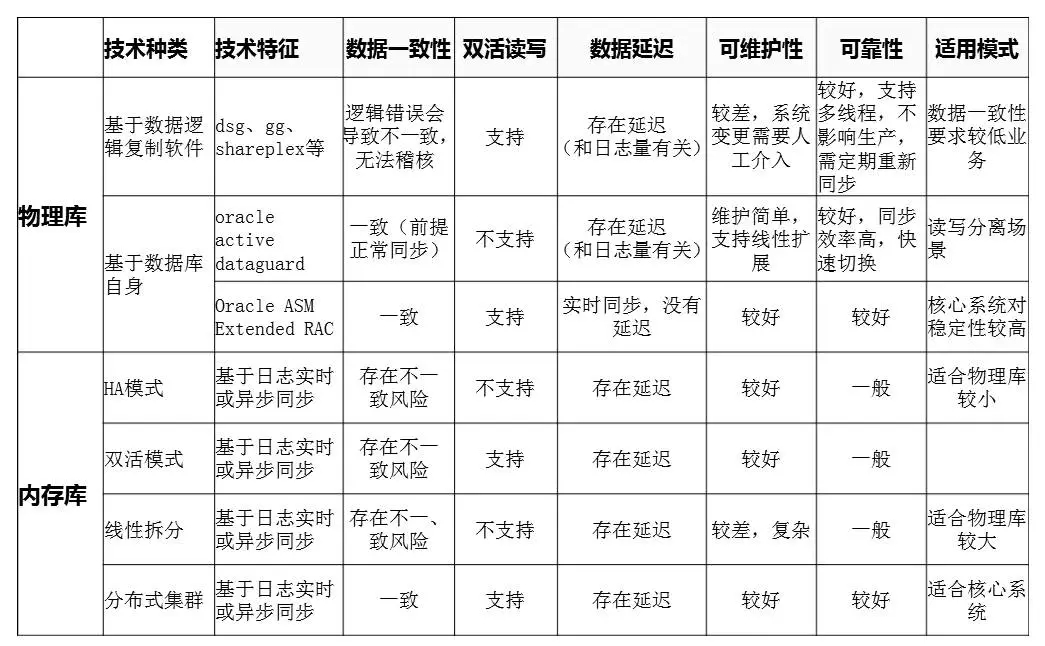
(注:应根据实际情况选择合适的方案,只有Extended RAC为真正的双读双写)
1、双活技术架构
存储层作为整个系统核心基础架构平台,其双活技术在整个架构中起到关键作用,目前基于存储层双活方案主要有下面三种:
基于远程卷管理软件的虚拟化,如:Symantec SF,IBM LVM等
基于存储网关虚拟化,如:EMC vplex, IBM SVC
基于存储自身卷镜像技术,HDS GAD
1)卷管理软件虚拟化:通过安装在主机上卷管理软件的逻辑卷镜像技术实现底层数据逻辑同步。

2)存储网关虚拟化:在每个站点新增存储虚拟化网关设备组成跨站点集群,并对存储卷进重新行封装,对外提供主机I/O访问。
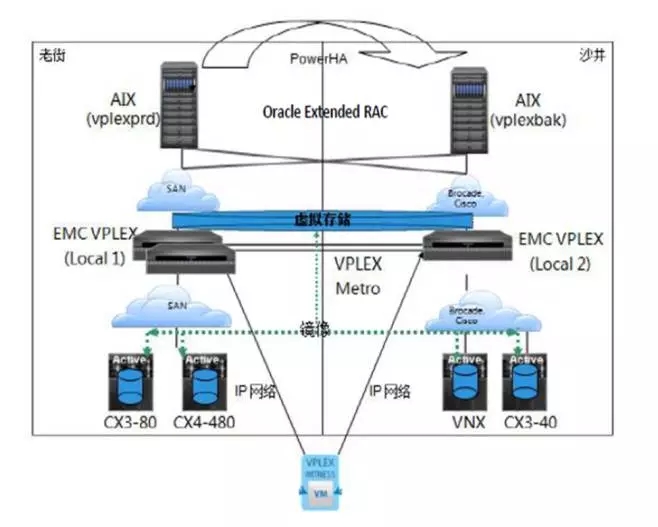
3)存储卷镜像技术:将两套磁盘阵列组成一个集群,两台存储上的LUN被虚拟化为一个虚拟卷,主机写操作通过卷虚拟化镜像技术同时写入两个数据中心的存储设备,保证站点之间数据实时同步。
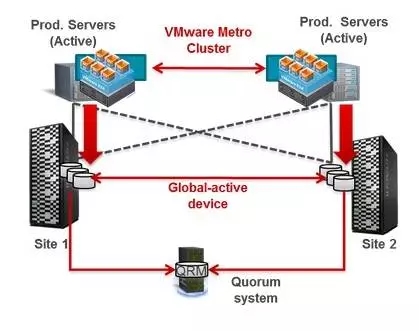
2、基于远程卷管理软件
技术特征:
数据同步:底层数据复制采用远程卷管理软件,如赛门铁克的Torage Foundation(SF)、IBM的GPFS等,通过逻辑卷镜像技术实现底层数据逻辑同步。上层应用采用Oracle Extended RAC方案实现远程4节点RAC,使生产和容灾节点都处于在线状态,应用逻辑访问的是同一个数据库。
数据读写:支持双读写。
数据一致性:完全一致。

远程卷管理软件改造前后变化:
改造前:
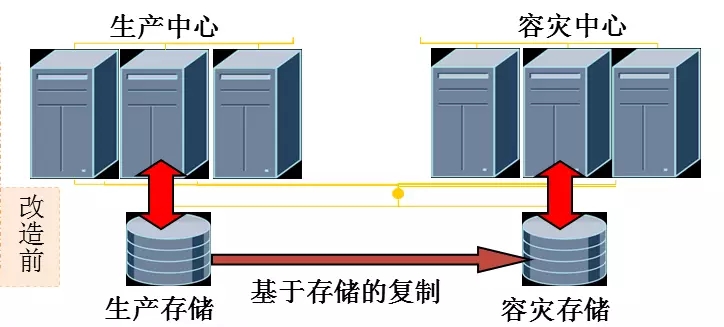
主机只需识别当前中心存储
可使用任意卷管理软件如LVM、ASM等
正常状态下容灾存储只读
IO读写都访问本地存储,数据复制由存储底层完成
改造后:
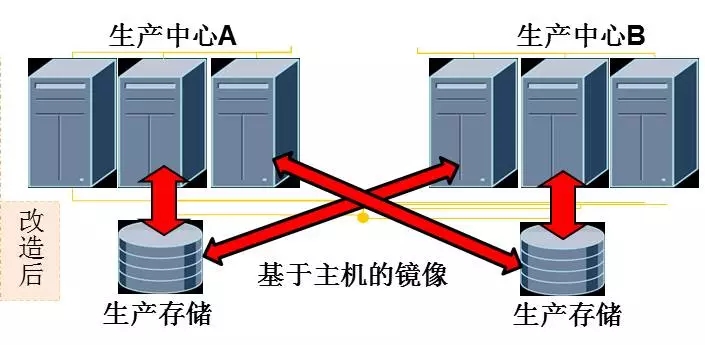
主机需识别当前中心存储和远端存储
只能使用SF的卷管理软件
两地存储都为读写状态
数据复制由主机卷镜像完成,写IO以远端写确认为准,读IO优先本地存储
3、案例分析——某省方案:IBM GPFS+Oracle 11g
应用情况:测试了接近一年,2013年在客服资料数据库上线,基于gpfs+oracle 11g rac。
效果:容灾端资源平时可以对外服务或查询,无需专门切换步骤,故障时只需要检查即可。(注:容灾端数据库实例也可以作为统计分析库)
前提条件:一、跨数据中心大二层网路建立,二、完善的仲裁机制,第三中心最好,建议环状双平面的网络架构,三、中心间需要高带宽,否则会影响性能。
缺点:架构更加复杂;san网络复杂;软件兼容性考虑很多;RTO<=3分钟。
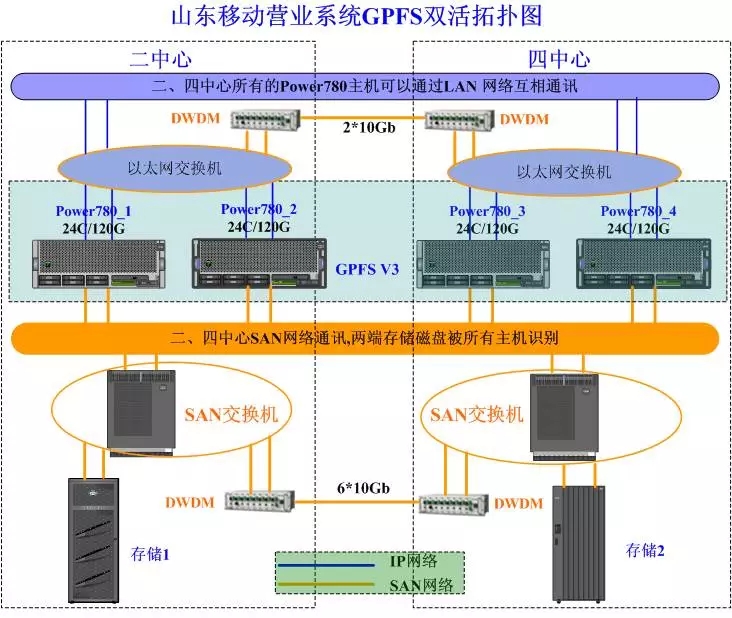
实现要点:
网络改造:需要打通两个中心间大二层网络。
底层存储链路改造:需要认到对端机房存储,带宽要求高。
卷管理软件改造:从现有主机自带LVM迁移到远程卷管理
Oracle extended RAC搭建
提供可靠性较高的二层网络(心跳网络)
提供可靠性较高的共享存储(投票盘)
对底层链路和距离要求高:距离太远会导致响应变慢,官方建议50KM之内。
使用场景:
容灾演练时不需要进行数据库的切换,只需应用切换,甚至不用切换。
可分摊当前生产端压力,降低生产负载
按业务梳理进行压力分摊
数据库备份只需要在单中心进行备份
经分数据可实时从生产抽取(通过BCV抽取非实时数据)
提升系统硬件冗余度,提升了系统高可用能力
4、基于存储网关虚拟化
技术特征:
实现原理:将存储虚拟化技术(EMC的vplex)和Oracle的远程rac技术结合,实现跨中心的数据双活访问。
跨中心的两个存储虚拟成一个对外访问,内部实时同步,保持数据的一致性,平时两边主机分别访问本地存储,故障情况下可跨中心访问对方存储。
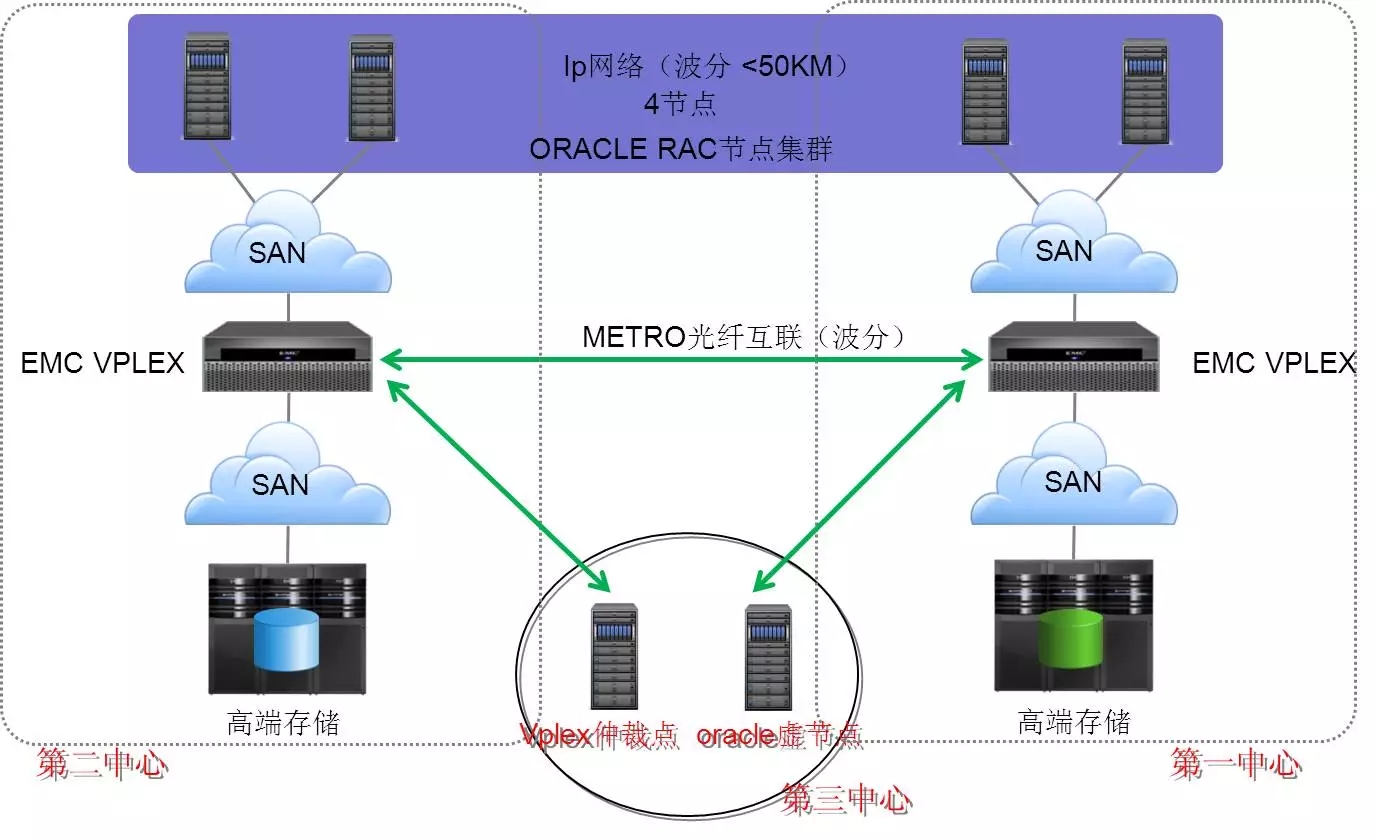
5、基于存储虚拟化设备
VPLEX存储管理机制:
VPLEX对存储卷进行封装后,让主机的I/O通过VPLEX来访问存储。
封装后的VPLEX卷只是指针集,所有数据的访问还是通过这个指针指到后端存储上,原来存储上的卷的各种属性都不会改变
原先存储卷所具有的各种属性,比如raid保护,快照、克隆等在存储内的各种设置对VPLEX透明,VPLEX不感知也不干涉。
被VPLEX接管了的存储卷只能通过VPLEX访问,不能再直接map给其他主机。
对于同一个数据块的读写冲突机制,是由RAC来保证的。
同步中断后所有数据改变信息都会记录在保持活动的VPLEX一端的log卷中,只要log卷不满,就不会发生全同步,都是增量同步;VPLEX在设置的时候会配置log卷,确保不论多长时间都不会发生全同步的。
具备脑裂预防服务器“witness”: witness是VPLEX的仲裁装置;
IBM、华为等也有类似VPLEX的存储网关实现方式,原理有些差异,但因为应用较少,不再介绍。
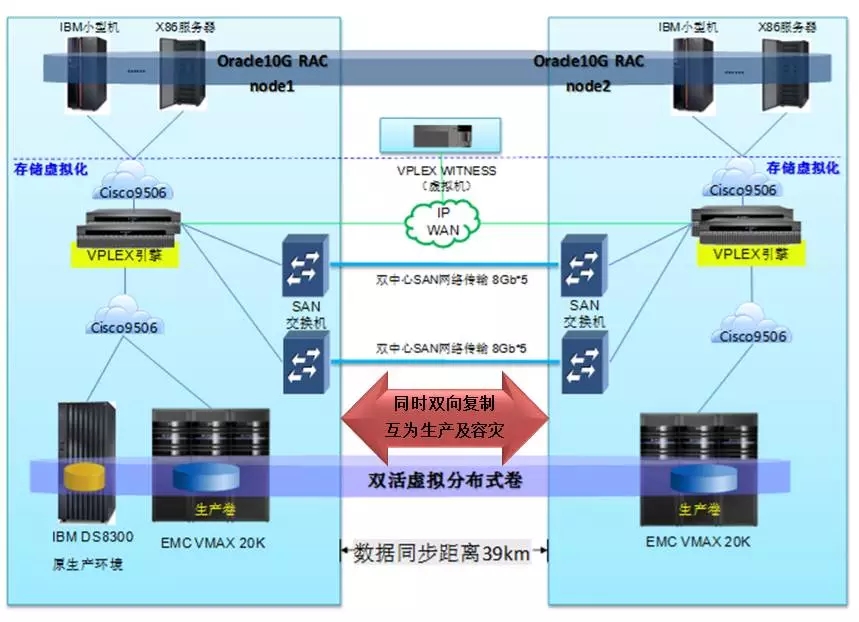
通过VPLEX虚拟化技术实现存储及数据的双活,在两个数据中心同为生产并服务于不同主机,实现双活双中心架构
通过Oracle跨站点集群技术提高应用层面的业务连续性,实现应用及业务的双活
两站点主机各自使用本地存储资源,确保性能和效率,提高资源利用率
双中心心跳网要单独组网,防止脑烈
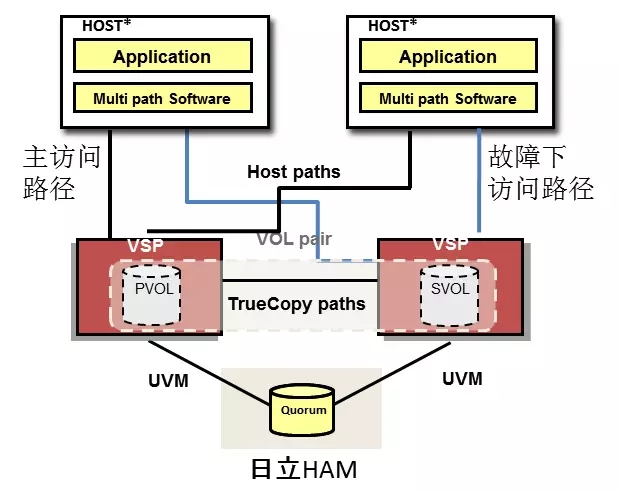
6、基于存储HA机制
未有应用案例,目前有IBM的powerHA HyperSwap、日立的HAM技术等,原理基本一样。
技术特征:
需要采用IBM或日立高端存储设备,利用其虚拟化软件。
主机实现两边并发对外访问,就近原则,存储有一端需要远程读写,效率较低。
上层需要结合Oracle远程rac实现双活
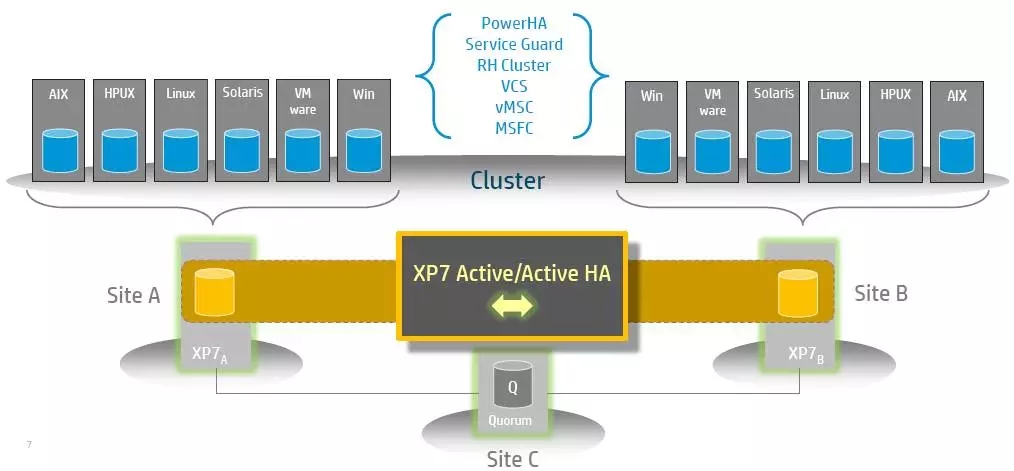
7、基于存储自身卷镜像
目前还未有应用案例,HDS/HP/ Huawei OceanStor V3等刚刚发布不久,完全基于存储自身卷镜像实现。
技术特征:
不需要额外软硬件,需要采用特定高端存储设备,如VSP、XP7以上才可以。
存储架构没有改变,易于实行。
两边存储可以同时读写。
上层需要结合Oracle远程rac实现双活
8、双活方案综合分析
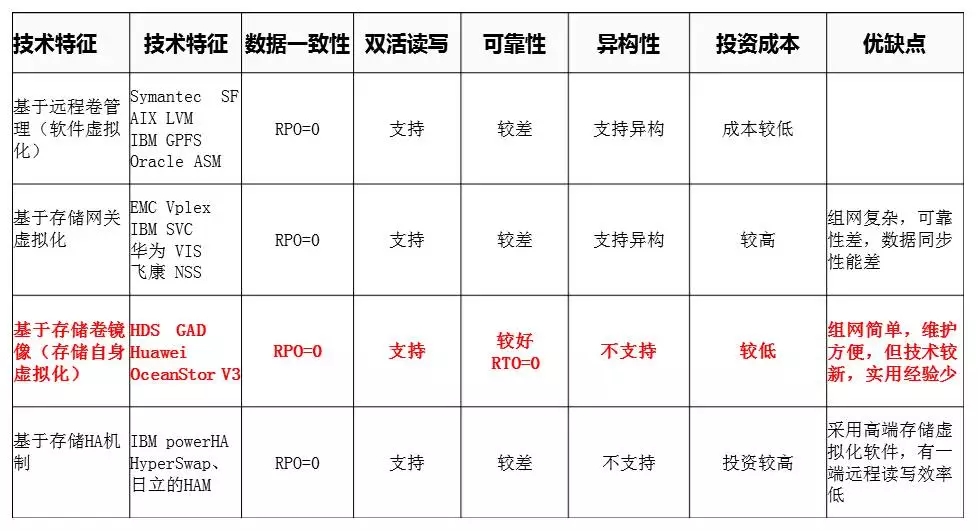
(注:整体看红色为最优方案,但要根据各省实际情况选择,上述方案均需要Extenmd RAC支持)
1、基于DNS+全局负载均衡双活架构
建设背景:
随着对访问质量和用户感知的提升,对支撑系统稳定性和业务连续性提出更高要求,从数据级容灾升级到应用级容灾,如何减少应用层数据中心切换时间,降低RT0----基于DNS+全局负载均衡保障(GSLB)应用层双活保障架构。
应用级双活:当单数据中心出现故障时,可以将请求引导向另一个可用的数据中心,实现双活高可用。
智能流量控制:GSLB根据后端服务器负载和链路状况实现不同站点间流量调配,链路优选,保证用户访问最佳性能服务器,确保访问质量,提升用户感知。
关键技术方案:
面向应用的智能流量控制
互联网业务多中心并行运行
内网基于IP地址发布的业务多中心并行
突发业务流量处理
应用交付设备集群部署
应用优化和安全
应用加速优化
数据库快速复制
七层DDoS和应用层攻击防护
自动化运营
一键备份
数据库的一键切换
1)互联网业务多中心并行模式:通过一组GSLB来对外提供服务,GSLB监控服务的状态,并通知组内其他设备,对于每一个DNS请求返回最佳结果,好的策略选择和配置方式可以最大幅度提高客户体验。
2)内部业务多中心互备模式:对于内网业务通过一组GSLB来提供服务,实现DNS解析,负载分发和故障切换。
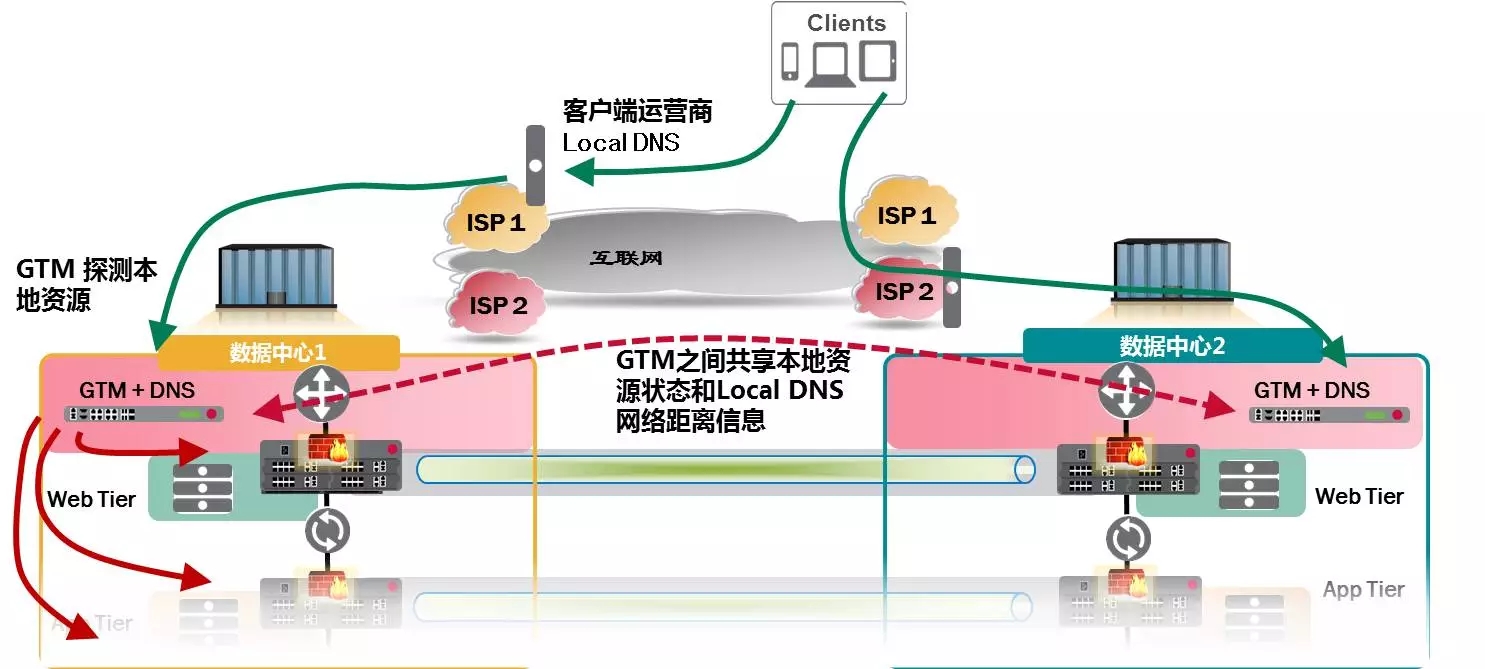
优点:
易于控制,可实现多种流量分布模型,主备、主主或者分应用主备等模型
维护方便,自成系统,与其他设备松耦合
可根据地理位置分布、网络距离或者应用繁忙程度动态调配
缺点:
应用必须采用DNS方式进行访问
切换时间相对较长(取决于TTL时间),通常用于互联网应
用5-10分钟,内网应用30-60秒
1、应用层设计
双活需要从接入、应用层、数据连接等层面考虑实现,才能实现“零”切换。
1)建议构建统一管理的接口层或采用服务总线技术:
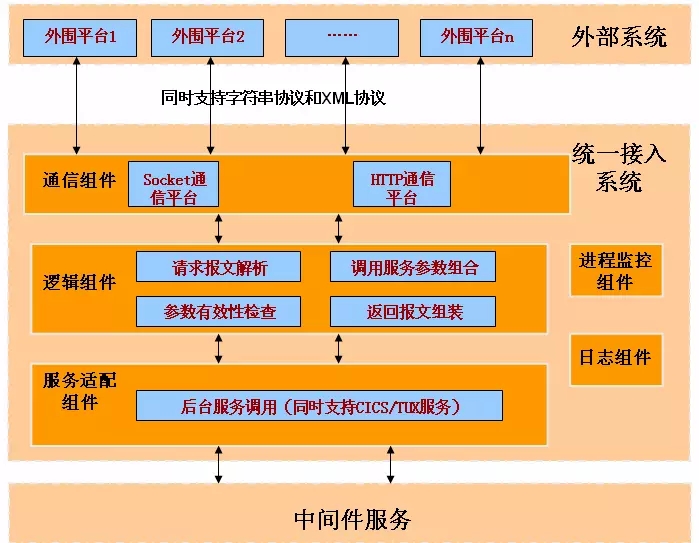
现状:系统使用的协议众多。难以做到每个对外服务接口均支持高可用性,无法实现对外服务的零切换容灾。
网上营业厅、WAP使用 CICS协议;
短信、VC、银行等使用SOCKET协议;
IVR、自助终端使用EASYCICS协议;
一级BOSS 使用HTTP+XML协议。
对此,需要做的是:
建设统一的对外应用接口平台,或使用SOA架构
负责应用路由/服务指向、对外/对内接口协议的封装和适配功能
建议采用多实例负载均衡的部署模式,在多个服务器间分担系统压力
建议实施时在各个中心建设适当数量的服务器和网络链路冗余,实现系统容灾的无缝切换
2)实现应用自动重连机制,确保自动切换,减少人工切换。
3)采用全局负载均衡、DNS等技术实现灵活接入。
4)建议双中心部署相同的应用集群方式。

本文未完待续……
◆ 近期热文 ◆
◆ 专家专栏 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会广州站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721