
一、背景
会员购是B站2017年推出的IP消费体验服务平台,在售商品以手办、漫画、JK制服等贴合平台生态的商品为主。随着业务发展,会员购从最开始的预售、现货拓展到全款预售、盲盒、众筹等多种售卖方式,销售渠道也遍布猫耳(现已下线)、QQ小程序、漫画等多个业务渠道,再加上不断增加的营销活动玩法,每年几次大促活动的爆发式流量,对于会员购交易系统来说,无疑是一个巨大的挑战。
二、性能
每年的拜年纪,626(公司周年庆),919(会员购周年庆),会员购都会搞大促活动,运营会挑选一些比较热门的手办进行首发,加上提前发放红包优惠券,各种优惠活动的刺激,每次大促0点开售流量就是几百倍的爆发,早期也因为压力太多出过几次事故,所以如何优化性能、提高交易的吞吐量是首要的。
面临问题:
在最初版的系统中,下单接口有明显的等待时间,用户体验不是很好,能支持的最大qps也有限
如图 2-1 所示 通看分析下单调用链路发现,存在多个接口重复调用,接口全是串行调用的情况,下单接口耗时太长,达到400+ms,已经严重影响系统性能及用户体验。
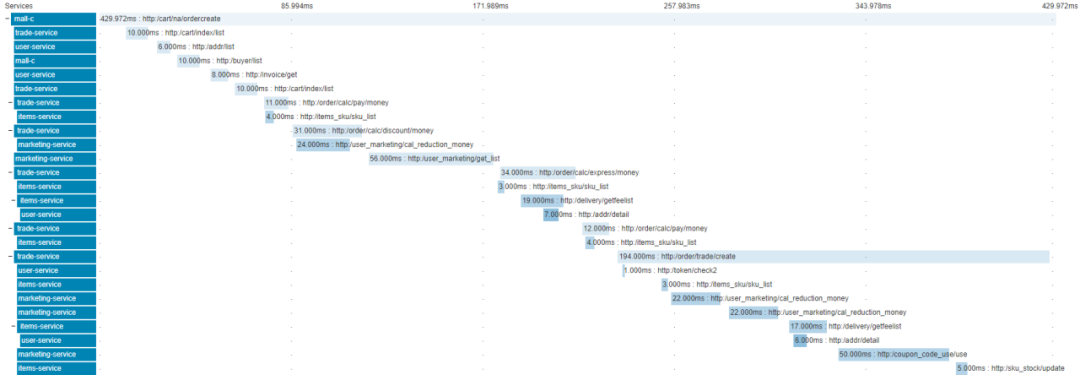
图 2-1 初版下单链路图
从链路上可以看出下单是IO密集型应用,CPU 利用率低,代码串行执行的话同步等待时间较长,为此我们重新梳理下单业务逻辑,对下单流程进行责任链模式改造,如2-2图所示。
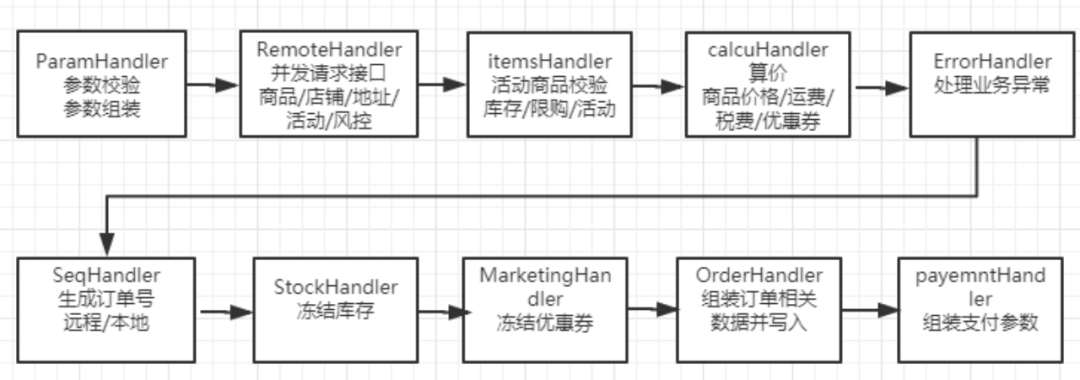 2-2 下单链路简单示意图
2-2 下单链路简单示意图
同时我们对系统做了以下优化:
对没有依赖的服务进行并发调用(商品/店铺/活动/用户信息等一起并发调用),如图2-3所示
优化调用链减少冗余调用,推动下游服务接口改造及合并,保证一次请求下来,每个基础接口只会被调用一次,如图2-3所示
设置合理的超时时间和及连接重试(200ms, 部分接口99分位上浮100%,connect连接重试)
排除事务内的外部调用(服务依赖,mq,缓存)
对弱依赖接口进行mq或异步调用(设置关注/缓存手机号/回滚库存优惠券等)
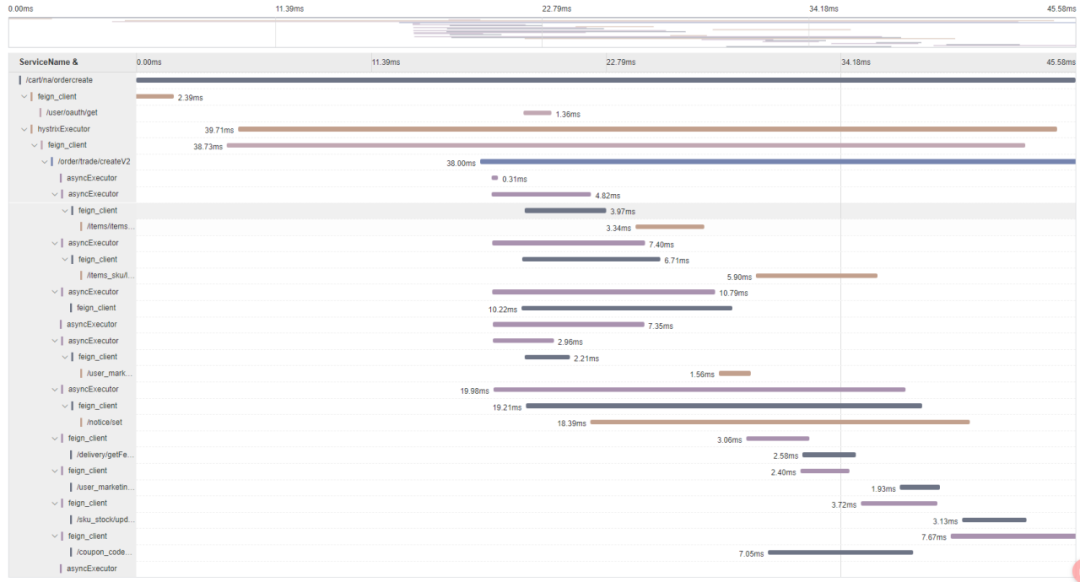
2-3 优化后的调用链路
经过优化后的接口耗时如2-4图所示,从原来300ms降低100ms左右,效果比较显著,用户的下单体验得到较大提升。
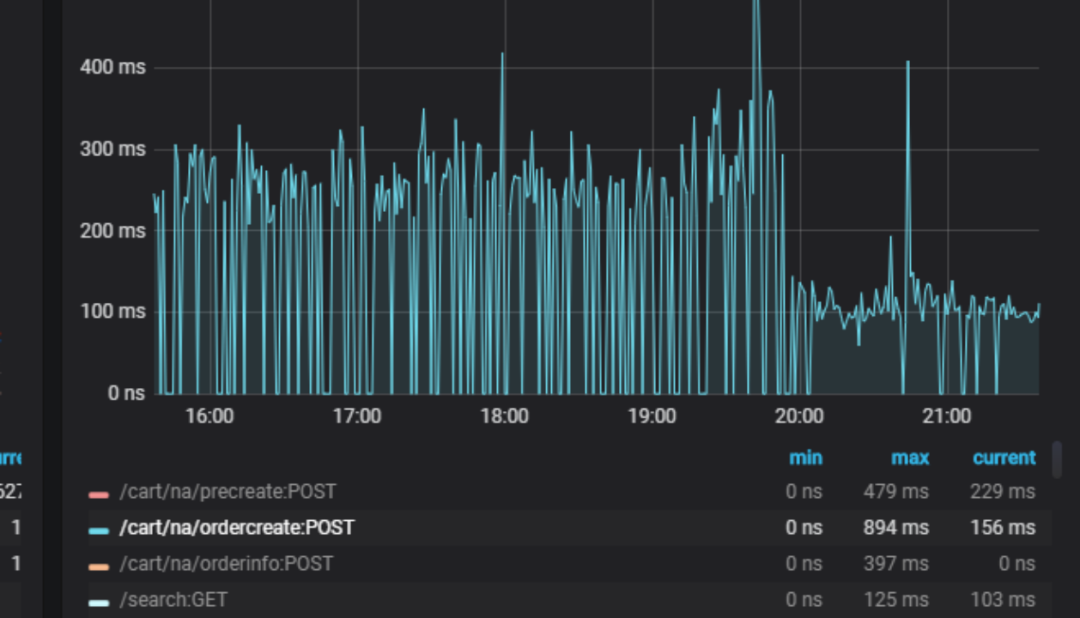
2-4 下单耗时对比图
面临问题:电商活动离不开秒杀场景,通常情况下小库存秒杀做好限流的话问题不大,但拜年祭手办通常有5000个左右的库存,如2-5如图所示,属于大库存秒杀 , 限流值设得太小会严重影响用户体验 ,大库存抢购时下单qps遇到瓶颈 600+qps的时候库存服务行锁比较严重,耗时开始大幅上升,大量数据库操作占用连接数较高。
2-5 拜年纪商品
思考:服务器的处理能力是恒定的,就像早高峰一样,需要错峰限行,这就是我们说的削峰,对流量进行削峰不仅让服务器处理得更加平稳,也节省服务器资源。一般削峰的手段有验证码,排队等方式,这里我们主要是采用异步下单这种排队的做法。
说到排队,最容易想到的就是消息队列,可以通过消息队列把两个系统模块进行解耦,对于抢购场景来说也是非常合适的,可以有效把流量通过队列来承接,然后平滑地进行处理,如图2-6所示。
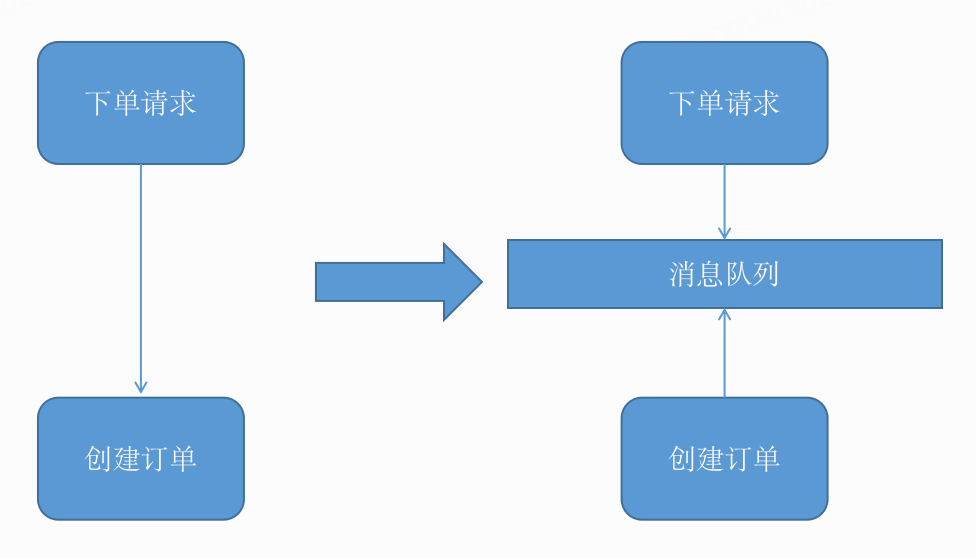
2-6 消息队列解耦
按照消息队列的排队方案,我们把整个下单流程调整为异步批量下单链路(图2-7所示) ,在合法校验过后生成订单号提交到databus消息队列 (图2-8所示),再监听databus批量拉取订单进行合并下单(图2-9所示),目前设置的是最多20个一消费,下单结果会在数据库及redis中保存。
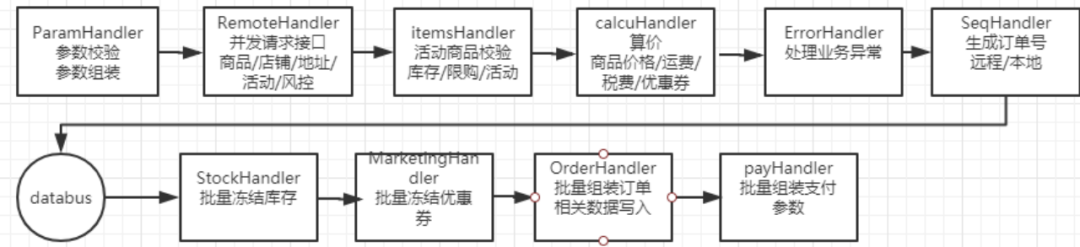
2-7异步下单链路
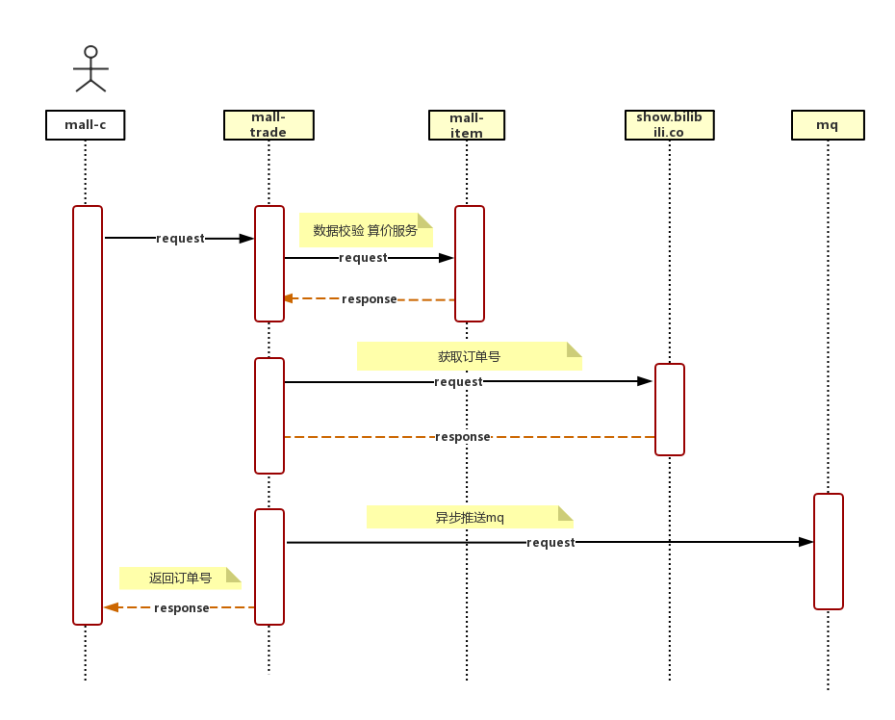
2-8 提交下单请求至mq
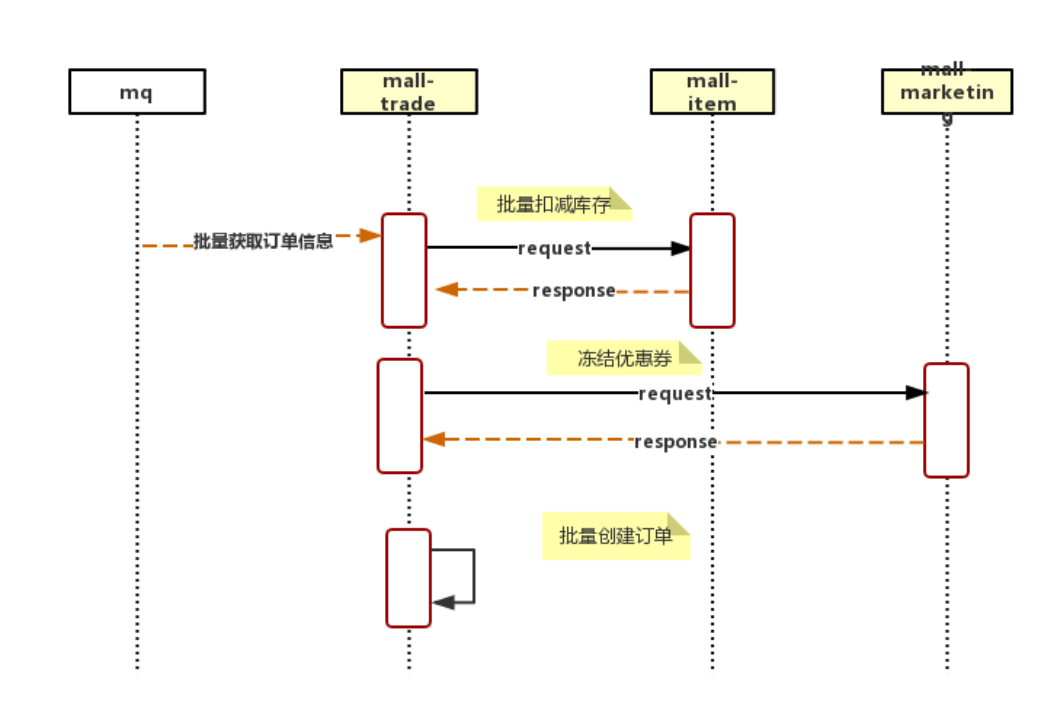
2-9 从mq消费订单消息
如图2-10所示,在进入队列后,前端会提示活动火爆,正在努力下单中 ,同时在0~2秒内随机调用下单结果查询接口,轮询30秒(必须设置最大时间兜底,防止无限查询)。
对于合并的订单进行批量冻结库存,并行冻结优惠券,批量合并sql插入数据库,最大限度上减少性能消耗。
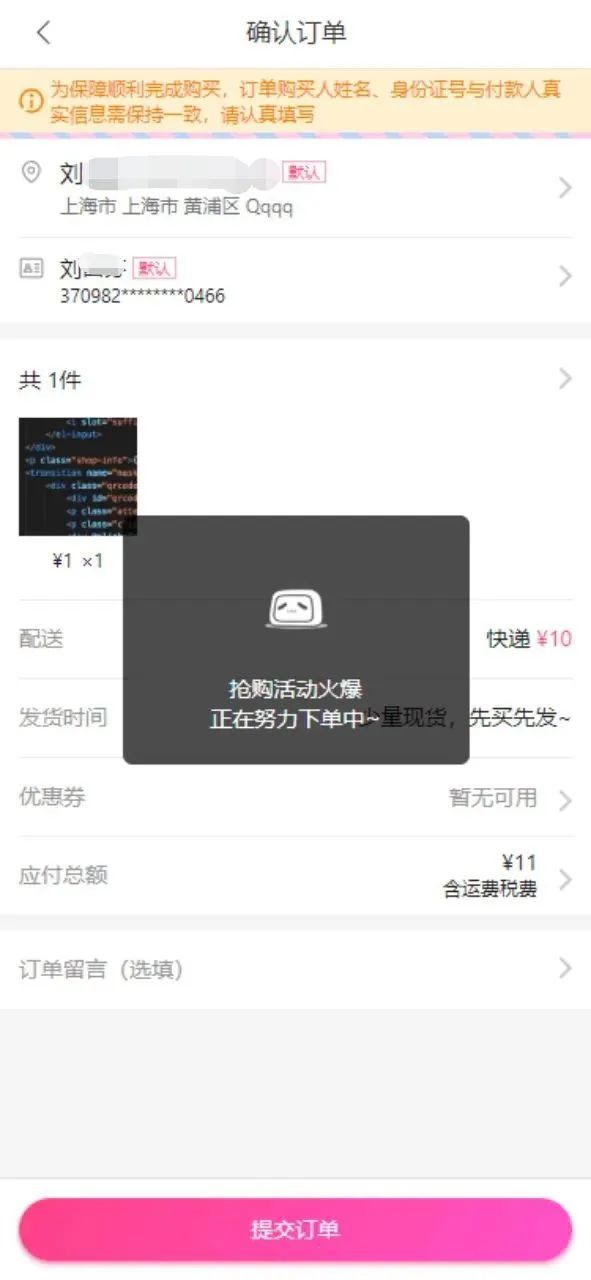
2-10 异步下单示例图
其他优化细节:
下单限频/限流;
其中对于一些弱依赖的操作直接进行降级,比如设置商铺关注,缓存手机号,记录操作日志等;
批量操作异常时(接口超时则fail fast),会分解为单个订单重新进行调用(库存操作会试探单库存扣减 单库存扣减成功 并发请求剩余订单,单库存扣减失败 剩余订单全部置为失败);
下单结果查询走redis,异常情况降级为数据库;
databus异常时,直接降级为同步下单(库存服务也会做限流);
databus消费者会做幂等及超时判断(订单投递时间跟当前时间差值),超过一定时间会自动抛弃,下单失败 。
经过改造,压测下单支持4000+tps,最终也顺利利用异步下单支撑了早期的拜年祭手办抢购,如图2-11所示。
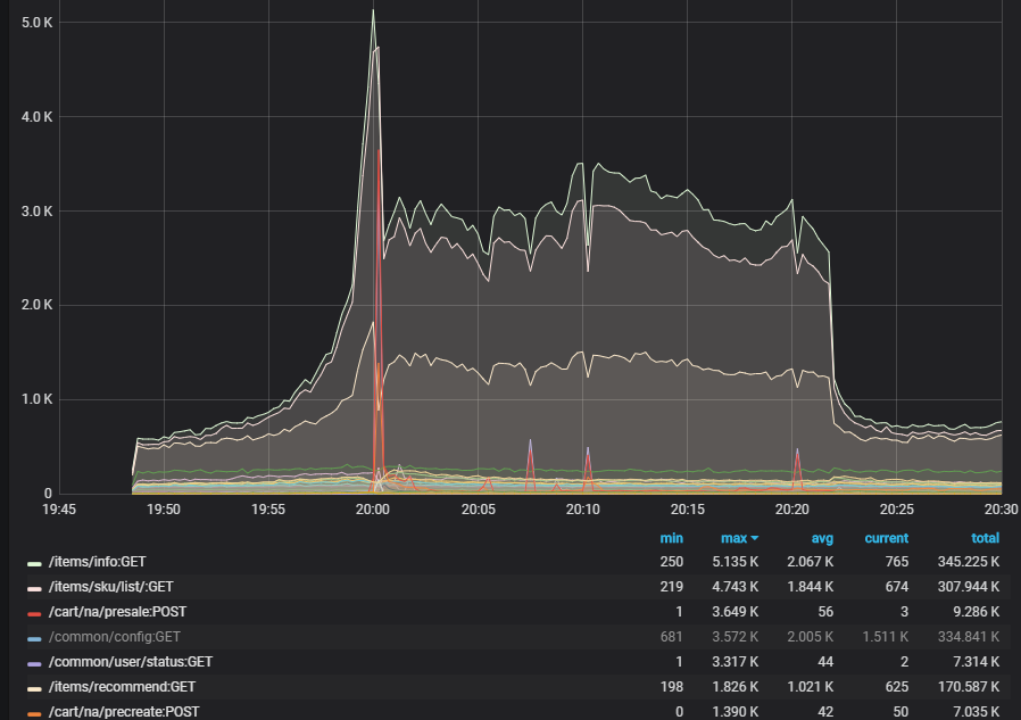
2-11 活动抢购qps图
首先并不是所有表都需要进行切分,主要还是看数据的增长速度。切分后会在某种程度上提升业务的复杂度,避免"过度设计"和"过早优化"。分库分表之前,不要为分而分,先尽力去做力所能及的事情,例如:升级硬件、升级网络、垂直拆分、读写分离、索引优化等等。当数据量达到单表的瓶颈时候,再考虑分库分表。
数据量过大的风险如下:
1)高负载下主从延迟严重,影响用户体验,并且对数据库备份,如果单表太大,备份时需要大量的磁盘IO和网络IO。例如1T的数据,网络传输占50MB时候,需要20000秒才能传输完毕,整个过程的风险都是比较高的
2)对一个很大的表进行DDL修改时,MySQL会锁住全表,这个时间会很长,这段时间业务不能访问此表,影响很大。如果使用pt-online-schema-change,使用过程中会创建触发器和影子表,也需要很长的时间。在此操作过程中,都算为风险时间。将数据表拆分,总量减少,有助于降低这个风险。
3)大表会经常访问与更新,就更有可能出现锁等待,一旦出现慢查询,风险很大,容错性很低。将数据切分,用空间换时间,变相降低访问压力,而且利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高
这里我们明确下分库、分表到底能解决什么问题:
分表:解决单表过大导致的查询效率下降(海量存储,即使索引正确也会很慢) MySQL 为了提高性能,会将表的索引装载到内存中。InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降。当然,这个还与具体的表结构的设计有关,最终导致的问题都是内存限制。这里,增加硬件配置,可能会带来立竿见影的性能提升。
分库:解决Master服务器无法承受读写操作压力(高并发访问,吞吐量)
在2020年的时候,会员购随着业务发展,订单数据快速增长,基本每半年数据量就会翻倍,所有核心表均达到千万级别大表的DDL,查询效率,健壮性都有问题 ,并且高负载下,会有较为明显的主从延迟,影响到用户体验。
首先是技术选型:
站在巨人的肩膀上能省力很多,目前分库分表已经有一些较为成熟的开源解决方案:
阿里的TDDL,DRDS和cobar
开源社区的sharding-jdbc(3.x开始已经更名为sharding-sphere)
民间组织的MyCAT
360的Atlas
美团的zebra
这么多的分库分表中间件全部可以归结为两大类型:CLIENT模式、PROXY模式。
无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
经过讨论大家更倾向于CLIENT模式,架构简单,性能损耗较小,运维成本低,而且目前部分项目中都已经被引入shardingjdbc,并且部分模块已经在使用其分库分表功能,网上文档丰富,框架比较成熟 。
选择sharding key:
sharding column的选取是很重要的,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。
sharding column的选取跟业务强相关,选择sharding column的方法最主要分析你的API流量,优先考虑流量大的API,将流量比较大的API对应的SQL提取出来,将这些SQL共同的条件作为sharding column 例如一般的OLTP系统都是对用户提供服务,这些API对应的SQL都有条件用户ID,那么,用户ID就是非常好的sharding column。
非sharding column查询该怎么办?
建立非sharding column属性到sharding column的映射关系
双写冗余全量数据(不需要二次查询)
数据异构(TIDB,ES,HIVE等,应对复杂条件查询,近实时或离线查询)
基因融合(比如订单号里融合mid基因,最新的订单号规则:orderId+mid%512 比如4004164057659338)
切分策略:
1)范围切分
比如按照时间区间或ID区间来切分,如图3-1所示,优点:单表大小可控,天然水平扩展。缺点:无法解决集中写入瓶颈的问题。
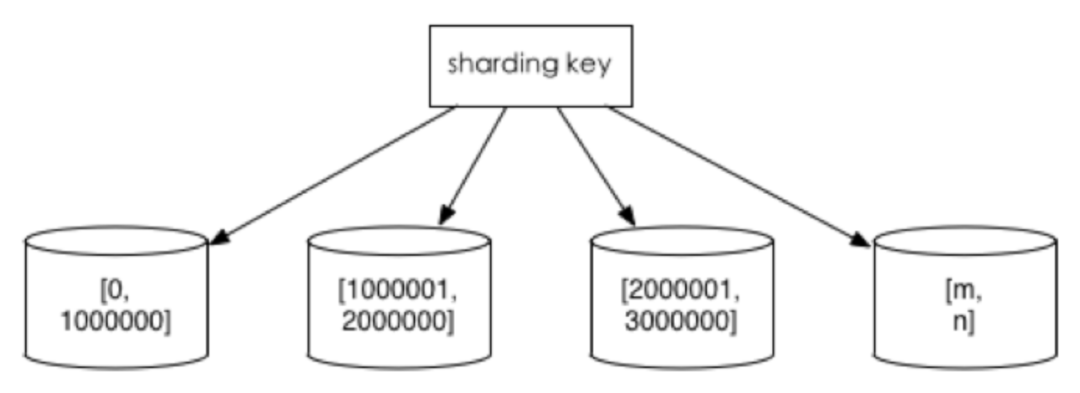
3-1 范围切分
2)Hash切分
如图3-2所示,如果希望一劳永逸或者是易于水平扩展的,还是推荐采用mod 2^n这种一致性Hash 。
3-2 Hash切分
3)会员购交易切分策略
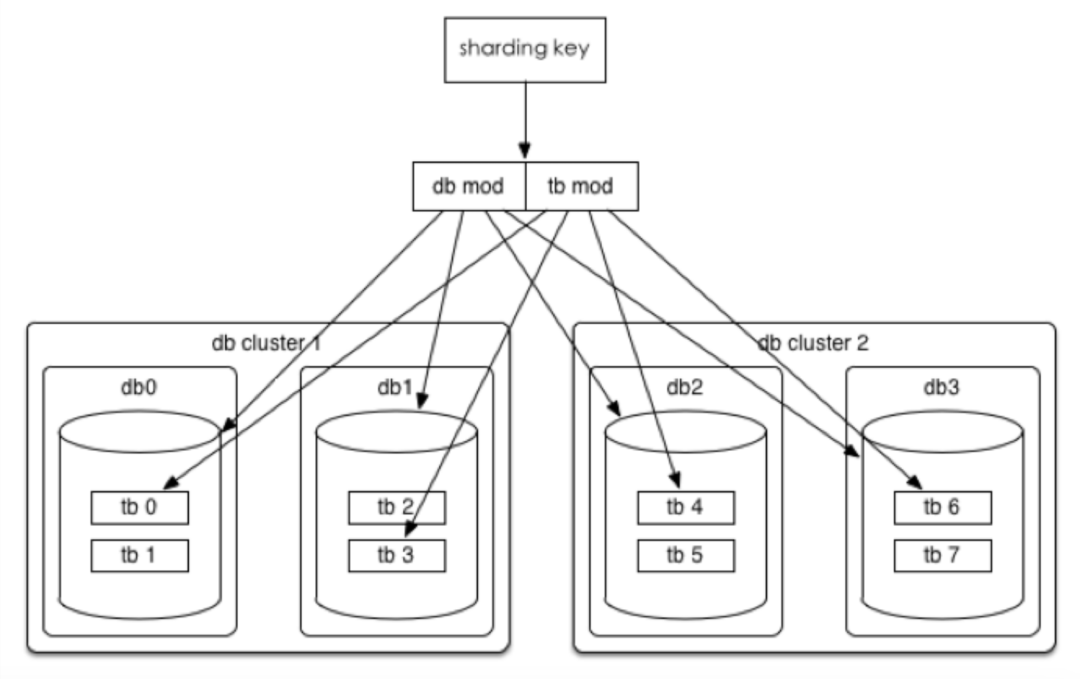
如图3-3所示,切分键选择:mid 和 order_id相关
根据 mid 分表,使用新的orderid 生成规则,orderid 融入(mid%512)
库表数量:4个集群(主从),每个集群4个库,每个库16张表,总计256张表
库路由策略:mid %16
表路由策略:(mid%512)/32
公式:
中间变量 = MID % (库数量*表数量)
库路由 = 中间变量 % 库数量
表路由 = 取整(中间变量 /库数量)
 3-3 库表策略示意图
3-3 库表策略示意图
我们采用的是不清洗老数据的方式,好处是老的订单数据依然走老库,这样能节省一部分清洗数据的工作量。
梳理sql:
项目中的sql有些是不满足分片条件的,所以我们是要提前梳理项目中的sql的。
通过 druid 界面 可以统计到所有运行的 sql
配合静态扫描sql工具
DBA 拉取 SQL
人工查看代码 当梳理出对应所有 SQL
针对没有分片键的SQL进行改造,不确定的SQL进行验证,不支持的SQL给出处理方式
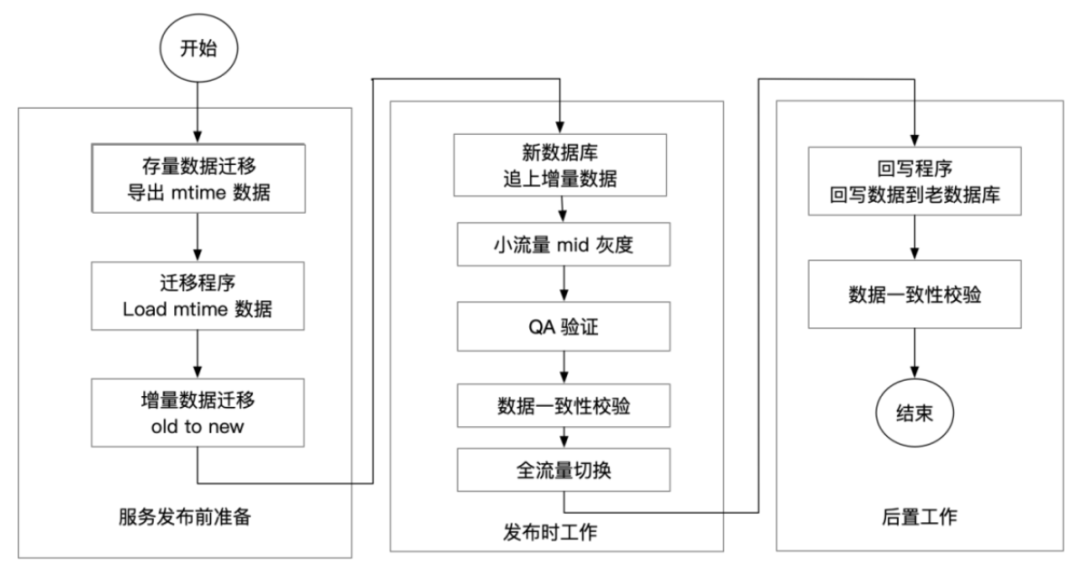
当然如何进行迁移也是很重要的步骤,我们是采用下面的步骤,如图3-4所示
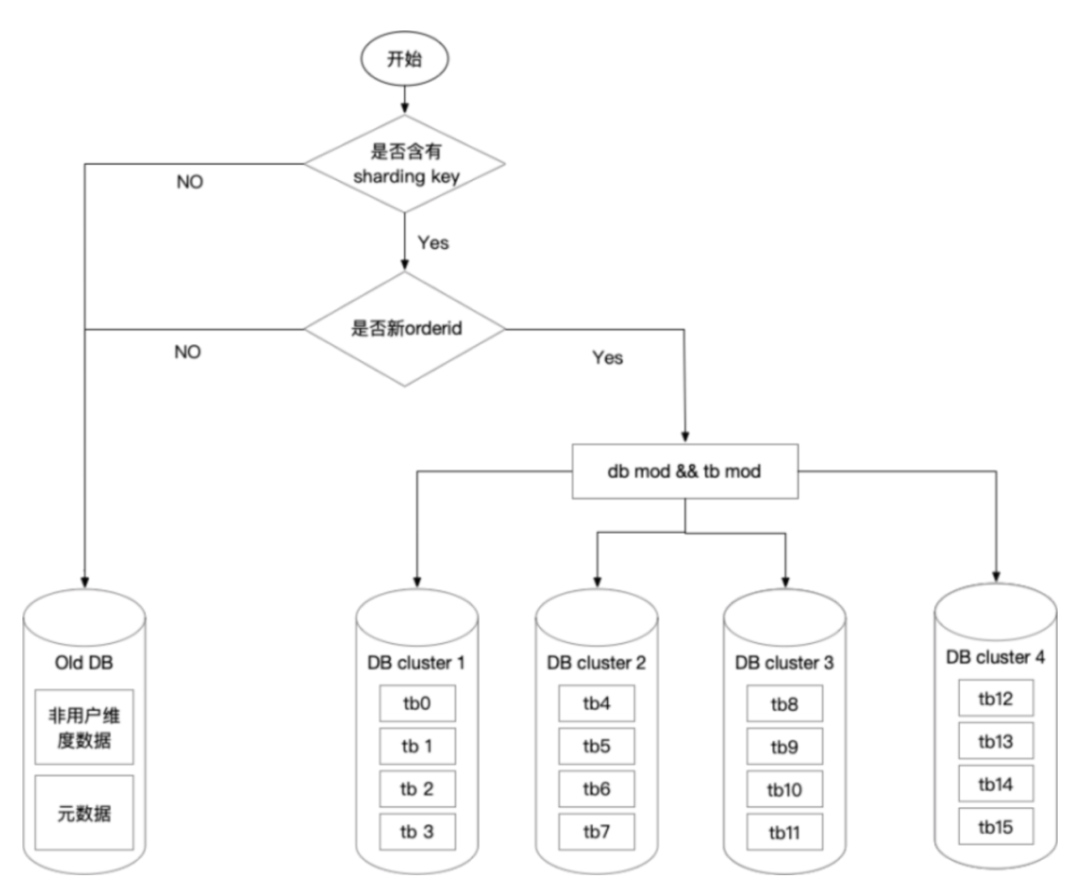
历史数据归档,不做迁移,老数据修改依旧路由到老库
切读写请求,即将读写流量请求引入到新系统中
回写数据,binlog 监听新数据库回写到老系统中,并进行校验 。
3-4 不停机迁移示意图
最后总结下整个分库分表的步骤:
根据容量(当前容量和增长量)评估分库分表个数
选key(均匀)
分表规则(hash或range等)
梳理sql并验证
执行(一般双写)
在整个交易系统完成分库分表后,彻底解决了数据库的瓶颈问题,历经多次大促压测突发流量等场景都没有出问题,保障了整个平台系统的稳定性。
三、总结
在经过调研链路优化、异步下单改造、数据库分库分表后,整个交易系统的性能得到了较大的提升,也较为顺利地支撑了历次大促活动,后续我们也会继续对一些历史系统(比如票务系统)进行改造升级来提升用户体验。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721